데이터 분석 파이프라인 운영
데이터 파이프라인은 많은 데이터 분석 솔루션의 토대가 됩니다. 이름에서 알 수 있듯이, 데이터 파이프라인은 원시 데이터를 받고, 정리하고, 필요에 따라 변형한 후 처리된 데이터를 저장하기 전에 계산 또는 집계를 수행합니다. 처리된 데이터는 클라이언트, 보고서 또는 API에서 사용됩니다. 데이터 파이프라인은 일정에 따르든, 새 데이터에 의해 트리거되든, 반복 가능한 결과를 제공해야 합니다.
이 문서에서는 HDInsight Hadoop 클러스터에서 실행되는 Oozie를 사용하여 반복성을 구현하도록 데이터 파이프라인을 운영하는 방법을 설명합니다. 예제 시나리오는 항공기 비행 시계열 데이터를 준비하고 처리하는 데이터 파이프라인을 안내합니다.
다음 시나리오에서 입력 데이터는 1개월 동안의 비행 데이터 배치를 포함하는 플랫 파일입니다. 이 비행 데이터에는 출발 및 도착 공항, 비행 마일, 출발 및 도착 시간 등이 포함됩니다. 이 파이프라인의 목표는 일별 항공사 실적을 요약하는 것입니다. 각 항공사에 대한 매일의 평균 출발 및 도착 시간 지연(분)과 해당 날짜에 비행한 총 마일 수가 행으로 구성됩니다.
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
이 예제 파이프라인은 새로운 시간 간격의 비행 데이터가 도착할 때까지 기다렸다가, 장기적인 분석을 위해 자세한 비행 정보를 Apache Hive 데이터 웨어하우스에 저장합니다. 또한 이 파이프라인은 일별 비행 데이터만 요약하는 훨씬 더 작은 데이터 세트도 만듭니다. 이 일별 비행 요약 데이터는 웹 사이트용과 같은 보고서를 제공하기 위해 SQL Database로 전송됩니다.
아래 다이어그램은 이 예제 파이프라인을 보여 줍니다.
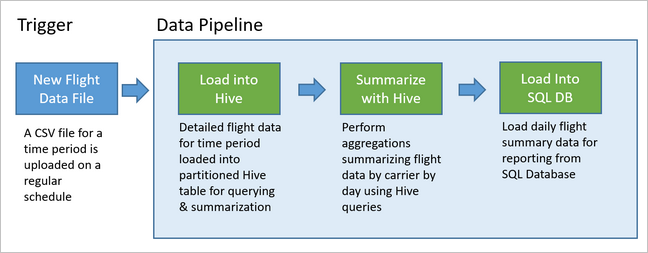
Apache Oozie 솔루션 개요
이 파이프라인은 HDInsight Hadoop 클러스터에서 실행되는 Apache Oozie를 사용합니다.
Oozie는 작업, 워크플로 및 코디네이터의 측면에서 해당 파이프라인을 설명합니다. 작업은 Hive 쿼리 실행과 같이 수행하는 실제 작업을 결정합니다. 워크플로는 작업 시퀀스를 정의합니다. 코디네이터는 워크플로가 실행되는 시기에 대한 일정을 정의합니다. 또한 코디네이터는 워크플로 인스턴스를 시작하기 전에 새 데이터가 사용 가능해질 때까지 대기할 수도 있습니다.
다음 다이어그램에서는 이 예제 Oozie 파이프라인의 개략적인 디자인을 보여 줍니다.
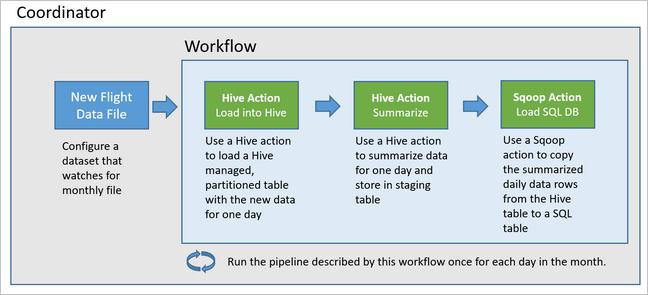
Azure 리소스 프로비전
이 파이프라인에서는 Azure SQL Database와 HDInsight Hadoop 클러스터가 같은 위치에 있어야 합니다. Azure SQL Database는 파이프라인 및 Oozie 메타데이터 저장소에서 생성되는 요약 데이터를 둘 다 저장합니다.
Azure SQL Database 프로비전
Azure SQL Database를 만듭니다. Azure Portal에서 Azure SQL 데이터베이스 만들기를 참조하세요.
HDInsight 클러스터가 연결된 Azure SQL Database에 액세스할 수 있도록 하려면 Azure 서비스 및 리소스가 서버에 액세스할 수 있도록 Azure SQL Database 방화벽 규칙을 구성해야 합니다. 서버 방화벽 설정을 선택하고 Azure SQL Database에 대해 Azure 서비스 및 리소스가 이 서버에 액세스할 수 있도록 허용에서 켜짐을 선택하여 이 옵션을 사용하도록 설정합니다. 자세한 내용은 IP 방화벽 규칙 만들기 및 관리를 참조하세요.
쿼리 편집기를 사용하여 파이프라인의 각 실행에서 요약 데이터를 저장하는
dailyflights테이블을 만들도록 다음 SQL 문을 실행합니다.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
이제 Azure SQL Database가 준비되었습니다.
Apache Hadoop 클러스터 프로비저닝
사용자 지정 메타스토어를 사용하여 Apache Hadoop 클러스터를 만듭니다. 포털에서 클러스터를 만드는 동안 스토리지 탭에서 메타스토어 설정에 있는 SQL Database를 선택했는지 확인합니다. 메타스토어를 선택하는 방법에 대한 자세한 내용은 클러스터를 만드는 동안 사용자 지정 메타스토어 선택을 참조하세요. 클러스터 만들기에 대한 자세한 내용은 Linux에서 HDInsight 시작을 참조하세요.
SSH 터널링 설정 확인
Oozie 웹 콘솔을 사용하여 코디네이터 및 워크플로 인스턴스의 상태를 보려면 HDInsight 클러스터에 대한 SSH 터널을 설정합니다. 자세한 내용은 SSH 터널을 참조하세요.
참고 항목
Foxy Proxy 확장에서 Chrome을 사용하여 SSH 터널에서 클러스터의 웹 리소스를 검색할 수도 있습니다. 터널 포트 9876의 호스트 localhost를 통해 모든 요청을 프록시하도록 구성합니다. 이 방법은 Windows 10의 Bash라고도 하는 Linux용 Windows 하위 시스템과 호환됩니다.
클러스터에 SSH 터널을 열려면 다음 명령을 실행합니다. 여기서
CLUSTERNAME은 클러스터의 이름입니다.ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.net다음으로 이동하여 헤드 노드의 Ambari로 이동하여 터널이 작동되는지 확인합니다.
http://headnodehost:8080Ambari에서 Oozie 웹 콘솔에 액세스하려면 Oozie>빠른 링크> [활성 서버] >Oozie 웹 UI로 이동합니다.
Hive 구성
데이터 업로드
1개월 동안의 비행 데이터를 포함하는 예제 CSV 파일을 다운로드합니다. 해당 ZIP 파일
2017-01-FlightData.zip을 HDInsight GitHub 리포지토리에서 다운로드한 후 CSV 파일2017-01-FlightData.csv로 압축을 풉니다.HDInsight 클러스터에 연결된 Azure Storage 계정으로 이 CSV 파일을 복사한 후
/example/data/flights폴더에 배치합니다.SCP를 사용하여 로컬 컴퓨터에서 HDInsight 클러스터 헤드 노드의 로컬 스토리지로 파일을 복사합니다.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvssh command 명령을 사용하여 클러스터에 연결합니다.
CLUSTERNAME을 클러스터의 이름으로 대체하여 아래 명령을 편집한 다음, 다음 명령을 입력합니다.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netssh 세션에서 HDFS 명령을 사용하여 헤드 노드 로컬 스토리지에서 Azure Storage로 파일을 복사합니다.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
테이블 만들기
이제 샘플 데이터를 사용할 수 있습니다. 그러나 파이프라인에는 들어오는 데이터(rawFlights)와 요약된 데이터(flights)를 처리하는 2개의 Hive 테이블이 필요합니다. 다음과 같이 Ambari에 이러한 테이블을 만듭니다.
http://headnodehost:8080으로 이동하여 Ambari로 로그인합니다.서비스 목록에서 Hive를 선택합니다.
Hive View 2.0 레이블 옆의 보기로 이동을 선택합니다.
쿼리 텍스트 영역에서 다음 문을 붙여 넣어
rawFlights테이블을 만듭니다.rawFlights테이블은 Azure Storage의/example/data/flights폴더에 있는 CSV 파일에 대해 스키마 온 리드(schema-on-read)를 제공합니다.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'실행을 선택하여 테이블을 만듭니다.
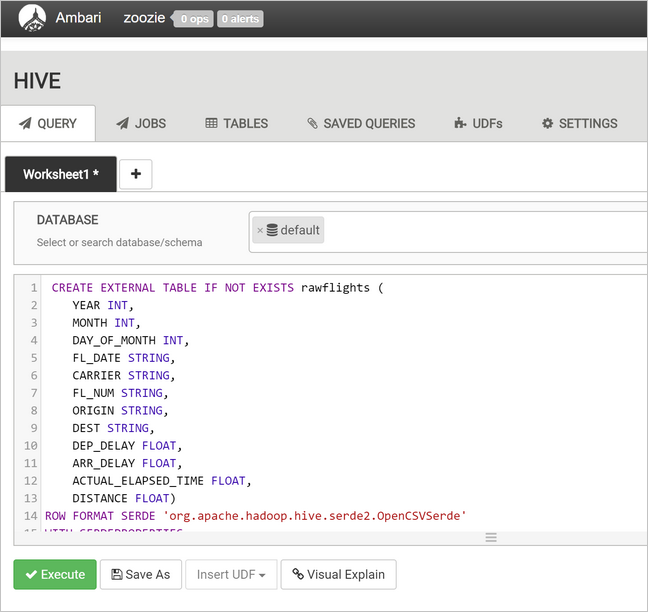
flights테이블을 만들려면 쿼리 텍스트 영역의 텍스트를 다음 문으로 바꿉니다.flights테이블은 로드된 데이터를 년, 월 및 일별로 분할하는 Hive 관리 테이블입니다. 이 테이블에는 모든 기록 비행 데이터가 포함되며, 원본 데이터의 최소 단위가 비행마다 하나의 행에 표시됩니다.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );실행을 선택하여 테이블을 만듭니다.
Oozie 워크플로 만들기
일반적으로 파이프라인은 지정된 시간 간격으로 데이터를 일괄로 처리합니다. 이 경우 파이프라인은 비행 데이터를 일별로 처리합니다. 이 방법을 사용하면 입력 CSV 파일이 일별, 주별, 월별 또는 연별로 도착할 수 있습니다.
샘플 워크플로는 다음 세 가지 주요 단계로 비행 데이터를 일별로 처리합니다.
rawFlights테이블이 나타내는 원본 CSV 파일에서 해당 일의 날짜 범위에 대한 데이터를 추출한 후flights테이블에 삽입하는 Hive 쿼리를 실행합니다.- 일별 및 항공사별로 요약된 비행 데이터의 복사본을 포함하는 해당 일에 대한 준비 테이블을 Hive에 동적으로 만드는 Hive 쿼리를 실행합니다.
- Apache Sqoop를 사용하여 Hive의 일별 준비 테이블의 모든 데이터를 Azure SQL Database의 대상
dailyflights테이블에 복사합니다. Sqoop는 Azure Storage에 있는 Hive 테이블 이면의 데이터에서 원본 행을 읽고, JDBC 연결을 사용하여 SQL Database에 로드합니다.
이러한 세 단계가 Oozie 워크플로에 의해 조정됩니다.
로컬 워크스테이션에서
job.properties라는 파일을 만듭니다. 아래 텍스트를 파일의 시작 콘텐츠로 사용합니다. 그런 다음 특정 환경에 대한 값을 업데이트합니다. 텍스트 아래 표에서는 각 속성을 요약하고, 사용자가 자신의 환경에 해당하는 값을 찾을 수 있는 위치를 나타냅니다.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03속성 값 원본 nameNode HDInsight 클러스터에 연결된 Azure Storage Container의 전체 경로입니다. jobTracker 활성 클러스터의 YARN 헤드 노드에 대한 내부 호스트 이름입니다. Ambari 홈 페이지의 서비스 목록에서 YARN을 선택한 다음, Azure Resource Manager를 선택합니다. 호스트 이름 URI가 페이지 위쪽에 표시됩니다. 포트 8050을 추가합니다. queueName Hive 작업을 예약할 때 사용되는 YARN 큐의 이름입니다. 기본값으로 둡니다. oozie.use.system.libpath True로 둡니다. appBase Oozie 워크플로 및 지원 파일을 배포하는 Azure Storage의 하위 폴더 경로입니다. oozie.wf.application.path 실행할 Oozie 워크플로 workflow.xml의 위치입니다.hiveScriptLoadPartition Hive 쿼리 파일 hive-load-flights-partition.hql에 대한 Azure Storage의 경로합니다.hiveScriptCreateDailyTable Hive 쿼리 파일 hive-create-daily-summary-table.hql에 대한 Azure Storage의 경로합니다.hiveDailyTableName 준비 테이블에 사용할 동적으로 생성된 이름입니다. hiveDataFolder 준비 테이블에 포함된 데이터에 대한 Azure Storage 경로입니다. sqlDatabaseConnectionString Azure SQL Database에 대한 JDBC 구문 연결 문자열입니다. sqlDatabaseTableName 요약 행이 삽입되는 Azure SQL Database의 테이블 이름입니다. dailyflights로 둡니다.연도 항공편 요약이 계산되는 날짜의 연도 구성 요소입니다. 있는 그대로 둡니다. 개월 항공편 요약이 계산되는 날짜의 월 구성 요소입니다. 있는 그대로 둡니다. 일 항공편 요약이 계산되는 날짜의 일 구성 요소입니다. 있는 그대로 둡니다. 로컬 워크스테이션에서
hive-load-flights-partition.hql이라는 파일을 만듭니다. 아래 코드를 파일의 콘텐츠로 사용합니다.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie 변수는 구문
${variableName}을 사용합니다. 이러한 변수는job.properties파일에서 설정됩니다. Oozie는 런타임에 실제 값을 대체합니다.로컬 워크스테이션에서
hive-create-daily-summary-table.hql이라는 파일을 만듭니다. 아래 코드를 파일의 콘텐츠로 사용합니다.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};이 쿼리는 하루 동안의 요약된 데이터만 저장하고, 평균 시간 지연 및 항공사가 비행한 거리 합계를 일별로 계산하는 SELECT 문을 작성하는 준비 테이블을 만듭니다. 이 테이블에 삽입된 데이터는 다음 단계에서 Sqoop의 원본으로 사용될 수 있도록, 알려진 위치(hiveDataFolder 변수가 나타내는 경로)에 저장되었습니다.
로컬 워크스테이션에서
workflow.xml이라는 파일을 만듭니다. 아래 코드를 파일의 콘텐츠로 사용합니다. 위의 이러한 단계는 Oozie 워크플로 파일에서 별도의 작업으로 표현됩니다.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
2개의 Hive 쿼리는 Azure Storage에서 해당 경로로 액세스되며, 나머지 변수 값은 다음 job.properties 파일을 통해 제공됩니다. 이 파일은 2017년 1월 3일에 워크플로가 실행되도록 구성합니다.
Oozie 워크플로 배포 및 실행
bash 세션의 SCP를 사용하여 Oozie 워크플로(workflow.xml), Hive 쿼리(hive-load-flights-partition.hql 및 hive-create-daily-summary-table.hql) 및 작업 구성(job.properties)을 배포합니다. Oozie에서는 job.properties 파일만 헤드 노드의 로컬 스토리지에 있을 수 있습니다. 다른 모든 파일은 HDFS(이 경우 Azure Storage)에 저장되어야 합니다. 워크플로에서 사용되는 Sqoop 작업은 SQL Database와 통신하기 위한 JDBC 드라이버에 따라 달라지며, 헤드 노드에서 HDFS로 복사되어야 합니다.
헤드 노드의 로컬 스토리지에 있는 사용자의 경로 아래의
load_flights_by_day하위 폴더를 만듭니다. OpenSSH 세션에서 다음 명령을 실행합니다.mkdir load_flights_by_day현재 디렉터리에 있는 모든 파일(
workflow.xml및job.properties파일)을load_flights_by_day하위 폴더로 복사합니다. 로컬 워크스테이션에서 다음 명령을 실행합니다.scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_day워크플로 파일을 HDFS로 복사합니다. OpenSSH 세션에서 다음 명령을 실행합니다.
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_day로컬 헤드 노드에서 HDFS의 워크플로 폴더로
mssql-jdbc-7.0.0.jre8.jar를 복사합니다. 클러스터에 다른 jar 파일이 포함되어 있는 경우 필요에 따라 명령을 수정합니다. 다른 jar 파일을 반영하기 위해 필요에 따라workflow.xml을 수정합니다. OpenSSH 세션에서 다음 명령을 실행합니다.hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_day워크플로 실행. OpenSSH 세션에서 다음 명령을 실행합니다.
oozie job -config job.properties -runOozie 웹 콘솔을 사용하여 상태를 관찰합니다. Ambar 내에서 Oozie, 빠른 링크, Oozie 웹 콘솔을 차례로 선택합니다. 워크플로 작업 탭 아래에서 모든 작업을 선택합니다.
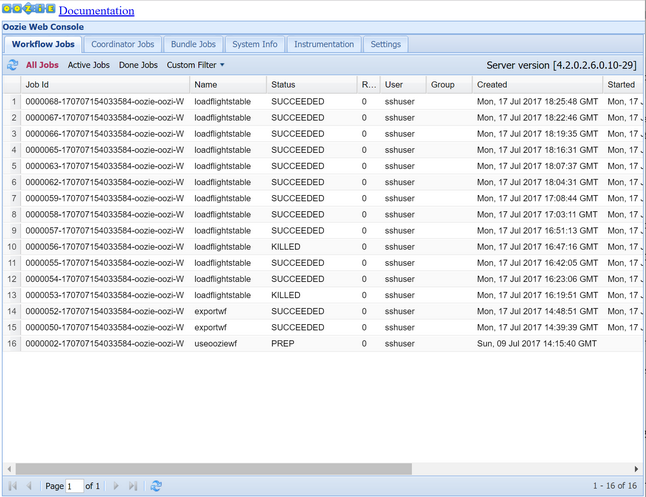
상태가 성공인 경우, SQL Database 테이블을 쿼리하여 삽입된 행을 확인합니다. Azure Portal을 사용하여 SQL Database에 대한 창으로 이동한 후 도구를 선택하고 쿼리 편집기를 엽니다.
SELECT * FROM dailyflights
워크플로가 단일 테스트 일에 대해 실행되므로, 이 워크플로를 매일 실행되도록 예약하는 코디네이터로 래핑할 수 있습니다.
코디네이터를사용하여 워크플로 실행
이 워크플로를 매일(또는 날짜 범위 내의 모든 날짜에) 실행되도록 예약하려면 코디네이터를 사용할 수 있습니다. 코디네이터는 XML 파일(예: coordinator.xml)로 정의됩니다.
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
아시다시피, 대부분의 코디네이터는 구성 정보를 워크플로 인스턴스에 전달하기만 합니다. 그러나 알아두어야 할 몇 가지 중요한 항목이 있습니다.
핵심 사항 1:
coordinator-app요소 자체의start및end특성이 코디네이터가 실행되는 시간 간격을 제어합니다.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>코디네이터는
frequency특성으로 지정된 간격에 따라,start및end데이터 범위 내에서 작업을 예약합니다. 예약된 각 작업은 구성된 대로 워크플로를 다시 실행합니다. 위의 코디네이터 정의에서, 코디네이터는 2017년 1월 1일부터 2017년 1월 5일까지 작업을 실행하도록 구성되어 있습니다. 주기는 Oozie 식 언어 주기 식${coord:days(1)}에 따라 1일로 설정됩니다. 이로 인해 코디네이터는 작업(및 워크플로)이 하루에 1번 실행되도록 예약합니다. 이 예제에서와 같이, 이전 날짜 범위에서는 작업이 지연 없이 실행되도록 예약됩니다. 작업이 실행되도록 예약된 날짜 시작을 명목 시간이라고 합니다. 예를 들어, 2017년 1월 1일의 데이터를 처리하기 위해 코디네이터는 명목 시간 2017-01-01T00:00:00 GMT를 사용해서 작업을 예약합니다.핵심 사항 2: 워크플로의 날짜 범위 내에서
dataset요소는 HDFS에서 특정 날짜 범위의 데이터를 조회할 위치를 지정하고, Oozie가 처리를 위해 해당 데이터를 사용할 수 있는지 여부를 확인하는 방법을 구성합니다.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>HDFS의 데이터 경로는
uri-template요소에 제공된 식에 따라 동적으로 작성됩니다. 이 코디네이터에서, 데이터 세트에도 1일의 주기가 사용됩니다. 코디네이터 요소의 시작 및 종료 날짜가 작업이 예약되는 시간을 제어(및 명목 시간 정의)하지만, 데이터 세트의initial-instance및frequency는uri-template구성에 사용되는 날짜 계산을 제어합니다. 이 경우 초기 인스턴스를 코디네이터 시작 하루 전으로 설정하여 첫날(2017년 1월 1일)의 데이터를 가져오도록 합니다. 데이터 세트의 날짜 계산은 코디네이터가 설정한 명목 시간(첫 번째 작업의 경우 2017-01-01T00:00:00 GMT)을 경과하지 않은 가장 최근 날짜를 찾을 때까지,initial-instance값(12/31/2016)에서 데이터 세트 주기(1일)씩 늘어나면서 롤포워드됩니다.빈
done-flag요소는 Oozie가 지정된 시간에 입력 데이터의 존재 여부를 확인할 때 디렉터리 또는 파일의 존재 여부에 따라 데이터가 사용 가능한지 확인함을 나타냅니다. 이 경우 csv 파일의 존재 여부가 관건입니다. csv 파일이 있으면 Oozie는 데이터가 준비되어 있다고 가정하고, 파일을 처리하는 워크플로 인스턴스를 시작합니다. csv 파일이 없으면 Oozie는 데이터가 아직 준비되지 않았다고 가정하며 워크플로를 실행하면 대기 상태가 됩니다.핵심 사항 3:
data-in요소는 연결된 데이터 세트에 대해uri-template의 값을 바꿀 때 명목 시간으로 사용할 특정 타임스탬프를 지정합니다.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>이 경우 인스턴스를
${coord:current(0)}식으로 설정합니다. 이 식은 코디네이터가 원래 예약한 대로, 작업의 명목 시간을 사용하는 방식으로 전환합니다. 즉, 코디네이터가 명목 시간 01/01/2017에 작업을 실행하도록 예약하면, 01/01/2017을 사용해서 URI 템플릿의 YEAR (2017) 및 MONTH (01) 변수를 바꿉니다. URI 템플릿이 이 인스턴스에 대해 계산되면 Oozie는 예상된 디렉터리 또는 파일을 사용할 수 있는지 여부를 확인하고 그에 따라 워크플로의 다음 실행을 예약합니다.
위의 세 가지 핵심 사항이 조합되어 코디네이터가 일 단위 방식으로 원본 데이터의 처리를 예약하게 됩니다.
핵심 사항 1: 코디네이터는 명목 날짜 2017-01-01에 시작됩니다.
핵심 사항 2: Oozie는
sourceDataFolder/2017-01-FlightData.csv에서 사용할 수 있는 데이터를 찾습니다.핵심 사항 3: Oozie가 해당 파일을 찾으면 2017년 1월 1일에 대한 데이터를 처리할 워크플로 인스턴스를 예약합니다. 그런 후 Oozie는 2017-01-02에 대한 처리를 계속합니다. 이 평가는 이 기간(2017-01-05 제외)까지 반복됩니다.
워크플로와 마찬가지로, 코디네이터의 구성은 워크플로에 사용되는 설정을 모두 포함하는 job.properties 파일에 정의됩니다.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
이 job.properties 파일에 도입된 유일한 새 속성은 다음과 같습니다.
| 속성 | 값 원본 |
|---|---|
| oozie.coord.application.path | 실행할 Oozie 코디네이터를 포함하는 coordinator.xml 파일의 위치를 나타냅니다. |
| hiveDailyTableNamePrefix | 준비 테이블의 테이블 이름을 동적으로 만들 때 사용되는 접두사입니다. |
| hiveDataFolderPrefix | 모든 준비 테이블을 저장할 경로의 접두사입니다. |
Oozie 코디네이터 배포 및 실행
코디네이터에 대한 파이프라인을 실행하려면, 워크플로를 포함하는 폴더보다 한 수준 위에 있는 폴더에서 작업하는 경우를 제외하고, 워크플로와 비슷한 방식으로 진행합니다. 이 폴더 규칙은 디스크의 워크플로에서 코디네이터를 구분하여, 한 코디네이터를 다른 하위 워크플로에 연결할 수 있도록 합니다.
로컬 컴퓨터의 SCP를 사용하여 클러스터 헤드 노드의 로컬 스토리지로 코디네이터 파일을 복사합니다.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~헤드 노드로 SSH를 수행합니다.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net코디네이터 파일을 HDFS로 복사합니다.
hdfs dfs -put ./* /oozie/코디네이터를 실행합니다.
oozie job -config job.properties -runOozie 웹 콘솔에서 이번에는 코디네이터 작업 탭, 모든 작업을 차례로 선택하여 상태를 확인합니다.
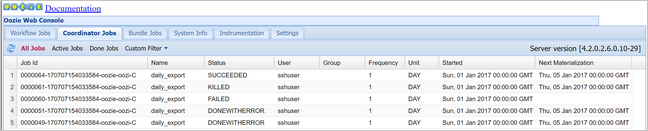
코디네이터 인스턴스를 선택하여 예약된 작업 목록을 표시합니다. 이 경우 2017년 1월 1일부터 2017년 1월 4일까지의 범위에서 명목상 시간을 가지는 4개의 작업이 표시되어야 합니다.
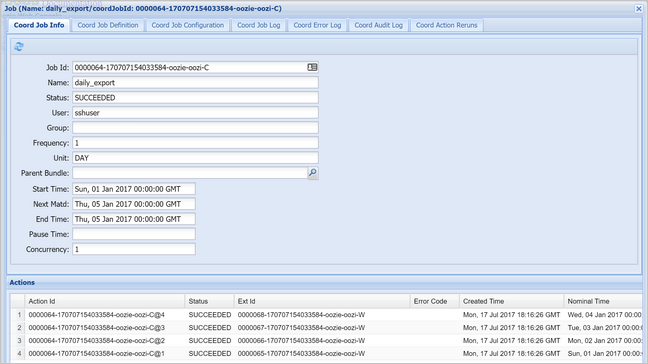
이 목록의 각 작업은 하루 동안의 데이터를 처리하는 워크플로 인스턴스에 해당하며, 해당 일의 시작은 명목 시간으로 표시됩니다.