Azure HDInsight의 Apache Phoenix
Apache Phoenix는 Apache HBase에서 구축되는 오픈 소스 대규모 병렬 관계형 데이터베이스 계층입니다. Phoenix를 사용하면 HBase를 통해 SQL 유사 쿼리를 사용할 수 있습니다. Phoenix는 아래의 JDBC 드라이버를 사용하여 사용자가 개별적으로 및 대량으로 SQL 테이블, 인덱스, 뷰 및 시퀀스를 생성, 삭제, 변경하고, 행을 Upsert할 수 있도록 합니다. Phoenix는 MapReduce를 사용하여 쿼리를 컴파일하는 대신, noSQL 네이티브 컴파일을 사용하여 HBase 위에 대기 시간이 짧은 애플리케이션을 만들 수 있도록 합니다. Phoenix는 서버의 주소 공간에서 클라이언트 제공 코드를 실행하도록 지원하는 보조 프로세서를 추가하고, 데이터와 함께 있는 코드를 실행합니다. 이 접근 방법은 클라이언트/서버 데이터 전송을 최소화합니다.
Apache Phoenix는 프로그래밍이 아닌, SQL 유사 구문을 사용할 수 있는 개발자가 아닌 사용자에게 빅 데이터 쿼리를 제공합니다. Phoenix는 Apache Hive 및 Apache Spark SQL 등의 다른 도구와 달리, HBase용으로 고도로 최적화되어 있습니다. 개발자는 훨씬 적은 코드로 고성능 쿼리를 작성할 수 있다는 이점이 있습니다.
SQL 쿼리를 제출하면 Phoenix는 최적화를 위해 쿼리를 HBase 네이티브 호출로 컴파일하는 작업과 검색(또는 계획) 실행 작업을 동시에 진행합니다. 이 추상 계층은 개발자가 MapReduce 작업을 쓰지 않아도 되는 대신, Phoenix의 빅 데이터 스토리지를 중심으로 하는 비즈니스 논리와 애플리케이션 워크플로에 집중할 수 있도록 합니다.
쿼리 성능 최적화 및 기타 기능
Apache Phoenix는 HBase 쿼리에 몇 가지 향상된 성능과 기능을 추가해 줍니다.
보조 인덱스
HBase의 기본 행 키에는 사전순으로 정렬되는 단일 인덱스가 있습니다. 이러한 레코드는 해당 행 키를 통해서만 액세스할 수 있습니다. 해당 행 키 이외의 열을 통해 레코드에 액세스하려면 필요한 필터를 적용하면서 모든 데이터를 검색해야 합니다. 보조 인덱스에서, 인덱싱된 열 또는 식은 대체 행 키를 형성하여 해당 인덱스에 대한 조회 및 범위 검색을 허용합니다.
CREATE INDEX 명령을 사용하여 보조 인덱스를 만듭니다.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
이 방법은 단일 인덱싱 쿼리를 실행하는 것보다 성능을 크게 향상시킬 수 있습니다. 이 유형의 보조 인덱스는 쿼리에 포함된 열을 모두 포함하는 포함 인덱스입니다. 따라서 테이블 조회는 필요하지 않으며 인덱스는 전체 쿼리를 만족합니다.
뷰
Phoenix 보기는 약 100개 이상의 물리적 테이블을 만들면 성능이 저하되기 시작하는 HBase 제한을 극복할 수 있는 방법을 제공합니다. Phoenix 뷰를 사용하면 여러 가상 테이블이 하나의 기본 실제 HBase 테이블을 공유할 수 있습니다.
Phoenix 보기를 만드는 것은 표준 SQL 보기 구문을 사용하는 것과 비슷합니다. 한 가지 차이점은 기본 테이블에 상속되는 열 외에도, 뷰의 열을 정의할 수 있다는 것입니다. 새 KeyValue 열도 추가할 수 있습니다.
예를 들어, 다음과 같은 정의를 사용하고 이름이 product_metrics인 실제 테이블이 있습니다.
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
추가 열을 사용해서 이 테이블에 대한 뷰를 정의합니다.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
나중에 열을 추가하려면 ALTER VIEW 문을 사용합니다.
검색 건너뛰기
검색 건너뛰기는 복합 인덱스의 열 하나 이상을 사용하여 고유 값을 찾습니다. 범위 검색과 달리, 검색 건너뛰기는 행 내 검색을 구현하여 향상된 성능을 제공합니다. 검색하는 동안, 일치하는 첫 번째 값은 다음 값을 찾을 때까지 인덱스와 함께 건너뛰어집니다.
검색 건너뛰기는 HBase 필터의 SEEK_NEXT_USING_HINT 열거형을 사용합니다. SEEK_NEXT_USING_HINT를 사용할 경우 검색 건너뛰기는 각 열에 대해 검색되는 키 집합 또는 키 범위를 추적합니다. 검색 건너뛰기는 필터 평가 중에 전달된 키를 사용하고 해당 키가 키 조합 중 하나인지를 확인합니다. 그렇지 않으면, 검색 건너뛰기는 건너뛸 다음으로 가장 높은 키를 평가합니다.
트랜잭션
HBase는 행 수준 트랜잭션을 제공하지만, Phoenix는 Tephra와 통합되어 전체 ACID 의미 체계에 대한 행 간 및 테이블 간 트랜잭션 지원을 추가합니다.
전형적인 SQL 트랜잭션과 마찬가지로, Phoenix 트랜잭션 관리자를 통해 제공되는 트랜잭션은 데이터의 원자 단위가 성공적으로 upsert되었는지 확인할 수 있도록 하며, 트랜잭션 지원 테이블에서 upsert 작업이 실패할 경우 트랜잭션을 롤백합니다.
Phoenix 트랜잭션을 사용하도록 설정하려면 Apache Phoenix 트랜잭션 설명서를 참조하세요.
트랜잭션이 사용하도록 설정된 새 테이블을 만들려면 CREATE 문에서 TRANSACTIONAL 속성을 true로 설정합니다.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
기존 테이블을 트랜잭션 방식으로 변경하려면 ALTER 문에서 동일한 속성을 사용합니다.
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
참고 항목
트랜잭션 테이블을 비트랜잭션 방식으로 다시 전환할 수 없습니다.
솔트된 테이블
지역 서버 핫스폿은 HBase에 대한 순차 키를 사용해 레코드를 쓸 때 발생할 수 있습니다. 클러스터에 여러 지역 서버가 있을 수 있지만 쓰기는 모두 한 서버에서만 발생합니다. 이러한 집중을 통해 쓰기 워크로드가 사용 가능한 모든 지역 서버에서 분산되지 않고, 한 서버만 부하를 처리하는 핫스폿 문제가 발생합니다. 각 영역의 최대 크기가 미리 정의되어 있으므로 영역이 해당 크기 제한에 도달하는 경우 두 개의 작은 영역으로 분할됩니다. 이 경우, 이러한 새 지역 중 하나가 모든 새 레코드를 받게 되어 새로운 핫스폿이 됩니다.
이 문제를 완화하고 성능을 향상시키려면 모든 지역 서버가 균일하게 사용되도록 테이블을 미리 분할합니다. Phoenix는 특정 테이블에 대한 행 키에 솔트 바이트를 투명하게 추가하여 솔트된 테이블을 제공합니다. 이 테이블은 테이블의 초기 단계 동안, 지역 서버 간에 부하를 균일하게 분산하기 위해 솔트 바이트 경계에서 미리 분할됩니다. 이 방법은 사용 가능한 모든 지역 서버에서 쓰기 워크로드를 분산하여 쓰기 및 읽기 성능을 향상시킵니다. 테이블을 솔트하려면 테이블이 만들어질 때 SALT_BUCKETS 테이블 속성을 지정합니다.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Apache Ambari에서 Phoenix 사용 및 조정
HDInsight HBase 클러스터에는 구성을 변경하기 위한 Ambari UI가 포함되어 있습니다.
Phoenix를 사용하거나 사용하지 않도록 설정하고, Phoenix의 쿼리 제한 시간 설정을 제어하려면 Hadoop 사용자 자격 증명을 사용하여 Ambari 웹 UI(
https://YOUR_CLUSTER_NAME.azurehdinsight.net)에 로그인합니다.왼쪽 메뉴의 서비스 목록에서 HBase를 선택하고 구성 탭을 선택합니다.
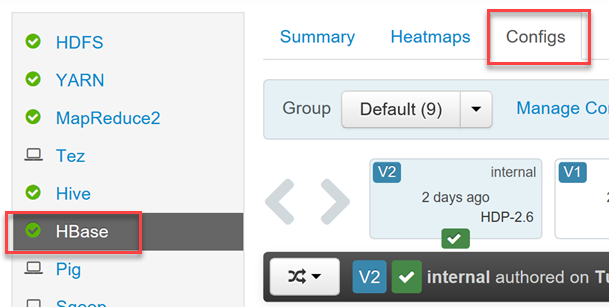
Phoenix SQL 구성 섹션을 찾아 Phoenix를 사용하거나 사용하지 않도록 설정하고, 쿼리 제한 시간을 설정합니다.