자습서: Azure HDInsight에서 판매 인사이트를 파생하는 엔드투엔드 데이터 파이프라인 만들기
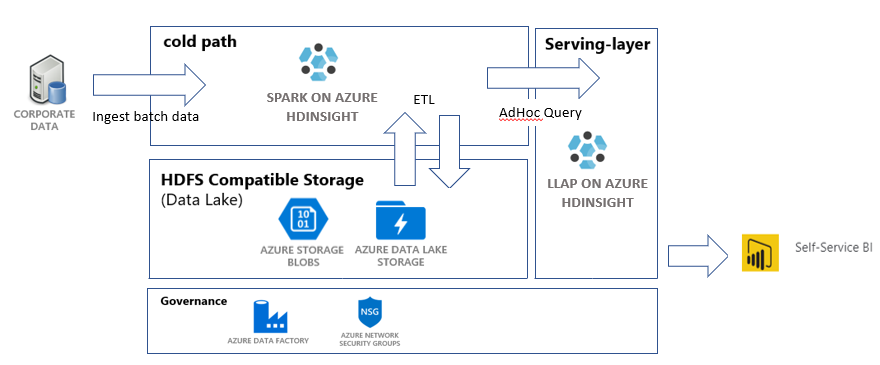
이 자습서에서는 ETL(추출, 변환 및 로드) 작업을 수행하는 엔드투엔드 데이터 파이프라인을 빌드합니다. 이 파이프라인은 Azure HDInsight에서 실행되는 Apache Spark 및 Apache Hive 클러스터를 사용하여 데이터를 쿼리하고 조작합니다. 또한 데이터 스토리지에는 Data Lake Storage Gen2 및 시각화에는 Power BI와 같은 기술을 사용할 수 있습니다.
이 데이터 파이프라인은 다양한 저장소의 데이터를 결합하고, 원치 않는 데이터를 모두 제거하고, 새 데이터를 추가한 다음, 이 모두를 스토리지에 다시 로드하여 비즈니스 인사이트를 시각화합니다. 규모에 맞게 ETL(추출, 변환 및 로드)에서 ETL 파이프라인에 대해 자세히 참조하세요.
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
Azure CLI - 버전 2.2.0 이상. Azure CLI 설치를 참조하세요.
간단한 jq 명령줄 JSON 프로세서. https://stedolan.github.io/jq/을(를) 참조하세요.
PowerShell을 사용하여 Data Factory 파이프라인을 트리거하는 경우 Az Module이 필요합니다.
이 자습서의 끝부분에서 비즈니스 인사이트를 시각화하는 Power BI Desktop
리소스 만들기
스크립트 및 데이터를 사용하여 리포지토리 복제
Azure 구독에 로그인합니다. Azure Cloud Shell을 사용하려는 경우 코드 블록의 오른쪽 위 모서리에 있는 사용해보기를 선택합니다. 그렇지 않은 경우 아래 명령을 입력합니다.
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Azure 역할 소유자의 멤버인지 확인합니다.
user@contoso.com을 사용자 계정으로 바꾸고, 다음 명령을 입력합니다.az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"레코드가 반환되지 않으면 멤버가 아니므로 이 자습서를 완료할 수 없습니다.
HDInsight 판매 인사이트 ETL 리포지토리에서 이 자습서에 사용할 데이터와 스크립트를 다운로드합니다. 다음 명령을 입력합니다.
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlsalesdata scripts templates가 만들어졌는지 확인합니다. 다음 명령을 사용하여 확인합니다.ls
파이프라인에 필요한 Azure 리소스 배포
다음을 입력하여 모든 스크립트에 대한 실행 권한을 추가합니다.
chmod +x scripts/*.sh리소스 그룹에 대한 변수를 설정합니다.
RESOURCE_GROUP_NAME을 기존 또는 새 리소스 그룹의 이름으로 바꾼 후, 다음 명령을 입력합니다.RESOURCE_GROUP="RESOURCE_GROUP_NAME"스크립트를 실행합니다.
LOCATION을 원하는 값으로 바꾼 후, 다음 명령을 입력합니다../scripts/resources.sh $RESOURCE_GROUP LOCATION어떤 지역을 지정할지 확실하지 않으면 az account list-locations 명령을 사용하여 구독에 대해 지원되는 지역 목록을 검색할 수 있습니다.
이 명령을 통해 배포하는 리소스는 다음과 같습니다.
- Azure Blob 스토리지 계정. 이 계정은 회사 판매 데이터를 보관합니다.
- Azure Data Lake Storage Gen2 계정. 이 계정은 두 HDInsight 클러스터 모두의 스토리지 계정으로 사용됩니다. HDInsight 및 Data Lake Storage Gen2에 대해서는 Data Lake Storage Gen2와 Azure HDInsight 연결에서 자세히 알아보세요.
- 사용자가 할당한 관리 ID. 이 계정은 Data Lake Storage Gen2 계정에 대한 액세스 권한을 HDInsight 클러스터에 제공합니다.
- Apache Spark 클러스터. 이 클러스터는 원시 데이터를 정리하고 변환하는 데 사용됩니다.
- Apache Hive Interactive Query 클러스터. 이 클러스터를 사용하면 Power BI를 통해 시각화된 판매 데이터를 쿼리할 수 있습니다.
- NSG(네트워크 보안 그룹) 규칙에서 지원하는 Azure 가상 네트워크. 이 가상 네트워크를 사용하면 클러스터에서 통신하고 해당 통신을 보호할 수 있습니다.
클러스터를 만드는 데 약 20분 정도 걸릴 수 있습니다.
클러스터에 대한 SSH 액세스의 기본 암호는 Thisisapassword1입니다. 암호를 변경하려면 ./templates/resourcesparameters_remainder.json 파일로 이동하여 sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPassword 및 llapsshPassword 매개 변수의 암호를 변경합니다.
배포 확인 및 리소스 정보 수집
배포 상태를 확인하려면 Azure Portal에서 리소스 그룹으로 이동합니다. 설정에서 배포를 선택한 다음, 배포를 선택합니다. 여기서는 성공적으로 배포된 리소스와 아직 진행 중인 리소스를 확인할 수 있습니다.
클러스터 이름을 보려면 다음 명령을 입력합니다.
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEAzure 스토리지 계정 및 액세스 키를 보려면 다음 명령을 입력합니다.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYData Lake Storage Gen2 계정 및 액세스 키를 보려면 다음 명령을 입력합니다.
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
데이터 팩터리 만들기
Azure Data Factory는 Azure Pipelines를 자동화하는 데 도움이 되는 도구입니다. 이러한 작업을 수행할 수 있는 유일한 방법은 아니지만 프로세스를 자동화하는 좋은 방법입니다. Azure Data Factory에 대한 자세한 내용은 Azure Data Factory 설명서를 참조하세요.
이 데이터 팩터리에는 다음 두 가지 활동이 있는 하나의 파이프라인이 있습니다.
- 첫 번째 활동은 데이터를 Azure Blob 스토리지에서 Data Lake Storage Gen 2 스토리지 계정으로 복사하여 데이터 수집을 모방합니다.
- 두 번째 활동은 Spark 클러스터의 데이터를 변환합니다. 스크립트에서 필요하지 않은 열을 제거하여 데이터를 변환합니다. 또한 단일 트랜잭션에서 생성하는 수익을 계산하는 새 열을 추가합니다.
Azure Data Factory 파이프라인을 설정하려면 아래의 명령을 실행합니다. 여전히 hdinsight-sales-insights-etl 디렉터리에 있어야 합니다.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
이 스크립트에서 수행하는 작업은 다음과 같습니다.
- Data Lake Storage Gen2 스토리지 계정에 대한
Storage Blob Data Contributor권한이 있는 서비스 주체를 만듭니다. - Data Lake Storage Gen2 파일 시스템 REST API에 대한 POST 요청에 권한을 부여하기 위한 인증 토큰을 가져옵니다.
- Data Lake Storage Gen2 스토리지 계정의 실제 이름을
sparktransform.py및query.hql파일에 채웁니다. - Data Lake Storage Gen2 및 Blob 스토리지 계정에 대한 스토리지 키를 가져옵니다.
- 연결된 서비스 및 활동을 사용하여 Azure Data Factory 파이프라인을 만드는 다른 리소스 배포를 만듭니다. 연결된 서비스에서 스토리지 계정에 올바르게 액세스할 수 있도록 스토리지 키를 매개 변수로 템플릿 파일에 전달합니다.
데이터 파이프라인 실행
Data Factory 활동 트리거
만든 Data Factory 파이프라인의 첫 번째 활동은 데이터를 Blob 스토리지에서 Data Lake Storage Gen2로 이동합니다. 두 번째 활동은 Spark 변환을 데이터에 적용하고, 변환된 .csv 파일을 새 위치에 저장합니다. 전체 파이프라인을 완료하는 데 몇 분 정도 걸릴 수 있습니다.
Data Factory 이름을 검색하려면 다음 명령을 입력합니다.
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
파이프라인을 트리거하려면 다음 중 하나를 수행할 수 있습니다.
PowerShell에서 Data Factory 파이프라인을 트리거합니다.
RESOURCEGROUP및DataFactoryName을 적절한 값으로 바꾼 후, 다음 명령을 실행합니다.# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipeline진행률을 모니터링하는 데 필요한 경우
Get-AzDataFactoryV2PipelineRun을 다시 실행합니다.또는
데이터 팩터리를 열고, 작성자 및 모니터링을 선택합니다. 포털에서
IngestAndTransform파이프라인을 트리거합니다. 포털을 통해 파이프라인을 트리거하는 방법에 대한 내용은 Azure Data Factory를 사용하여 HDInsight에서 주문형 Apache Hadoop 클러스터 만들기를 참조하세요.
파이프라인이 실행되었는지 확인하려면 다음 단계 중 하나를 수행하면 됩니다.
- 포털을 통해 데이터 팩터리의 모니터 섹션으로 이동합니다.
- Azure Storage Explorer에서 Data Lake Storage Gen 2 스토리지 계정으로 이동합니다.
files파일 시스템,transformed폴더로 차례로 이동하고, 해당 내용을 확인하여 파이프라인이 성공했는지 확인합니다.
HDInsight를 사용하여 데이터를 변환하는 다른 방법은 Jupyter Notebook 사용에 대한 이 문서를 확인하세요.
테이블을 대화형 쿼리 클러스터에 만들어 Power BI에서 데이터 보기
SCP를 사용하여
query.hql파일을 LLAP 클러스터에 복사합니다. 명령을 입력합니다.LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/미리 알림: 기본 암호는
Thisisapassword1입니다.SSH를 사용하여 LLAP 클러스터에 액세스합니다. 명령을 입력합니다.
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net다음 명령을 사용하여 스크립트를 실행합니다.
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hql이 스크립트는 Power BI에서 액세스할 수 있는 대화형 쿼리 클러스터에 관리형 테이블을 만듭니다.
판매 데이터에서 Power BI 대시보드 만들기
Power BI Desktop을 실행합니다.
메뉴에서 데이터 가져오기>추가...>Azure>HDInsight 대화형 쿼리로 이동합니다.
연결을 선택합니다.
HDInsight 대화형 쿼리 대화 상자에서 다음을 수행합니다.
- 서버 텍스트 상자에 LLAP 클러스터의 이름을
https://LLAPCLUSTERNAME.azurehdinsight.net형식으로 입력합니다. - 데이터베이스 텍스트 상자에
default를 입력합니다. - 확인을 선택합니다.
- 서버 텍스트 상자에 LLAP 클러스터의 이름을
AzureHive 대화 상자에서 다음을 수행합니다.
- 사용자 이름 텍스트 상자에
admin을 입력합니다. - 암호 텍스트 상자에
Thisisapassword1을 입력합니다. - 연결을 선택합니다.
- 사용자 이름 텍스트 상자에
탐색기에서
sales및/또는sales_raw를 선택하여 데이터를 미리 봅니다. 데이터가 로드되면 만들려는 대시보드를 사용하여 실험할 수 있습니다. Power BI 대시보드를 시작하려면 다음 링크를 참조하세요.
리소스 정리
이 애플리케이션을 계속 사용하지 않을 경우 요금이 청구되지 않도록 다음 명령을 사용하여 모든 리소스를 삭제합니다.
리소스 그룹을 제거하려면 다음 명령을 입력합니다.
az group delete -n $RESOURCE_GROUP서비스 주체를 제거하려면 다음 명령을 입력합니다.
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL