Azure HDInsight의 Hive Warehouse Connector와 Apache Spark 및 Apache Hive 통합
Apache HWC(Hive Warehouse Connector)는 Apache Spark 및 Apache Hive에서 보다 쉽게 작업할 수 있도록 지원하는 라이브러리입니다. Spark DataFrames와 Hive 테이블 간에 데이터를 이동하는 것과 작업을 지원합니다. 또한 Spark 스트리밍 데이터를 Hive 테이블로 전송합니다. Hive Warehouse Connector는 Spark와 Hive 간의 브리지처럼 작동합니다. 또한 개발을 위한 프로그래밍 언어로 Scala, Java 및 Python을 지원합니다.
Hive Warehouse Connector를 사용하면 Hive 및 Spark의 고유한 기능을 활용하여 강력한 빅 데이터 애플리케이션을 빌드할 수 있습니다.
Apache Hive는 ACID(원자성, 일관성, 격리성 및 내구성)에 해당하는 데이터베이스 트랜잭션을 지원합니다. Hive의 ACID 및 트랜잭션에 대한 자세한 내용은 Hive 트랜잭션을 참조하세요. 또한 Hive는 Apache Spark에서 사용할 수 없는 Apache Ranger 및 LLAP(Low Latency Analytical Processing)를 통해 자세한 보안 제어를 제공합니다.
Apache Spark에는 Apache Hive에서 사용할 수 없는 스트리밍 기능을 제공하는 구조적 스트리밍 API가 있습니다. HDInsight 4.0부터 Apache Spark 2.3.1 이상 및 Apache Hive 3.1.0에는 별도의 메타스토어 카탈로그가 있어 상호 운용이 어려워집니다.
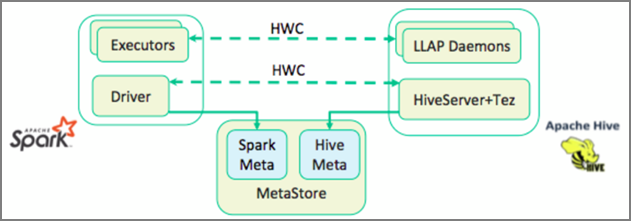
HWC(Hive Warehouse Connector)를 이용하면 좀 더 쉽게 Spark와 Hive를 함께 사용할 수 있습니다. HWC 라이브러리는 LLAP 디먼에서 Spark 실행기로 데이터를 병렬로 로드합니다. 이 프로세스를 통해 Spark에서 Hive로의 표준 JDBC 연결보다 좀 더 효율적이고 편리하게 연결될 수 있습니다. 이렇게 하면 서로 다른 두 가지 HWC 실행 모드가 제공됩니다.
- HiveServer2를 통한 Hive JDBC 모드
- LLAP 디먼을 사용하는 Hive LLAP 모드[권장]
기본적으로 HWC는 Hive LLAP 디먼을 사용하도록 구성됩니다. 해당 API와 함께 위의 모드를 사용하여 Hive 쿼리(읽기/쓰기 모두)를 실행하려면 HWC API를 참조하세요.
Hive Warehouse Connector에서 지원하는 일부 작업은 다음과 같습니다.
- 테이블 설명
- ORC 형식의 데이터에 대한 테이블 만들기
- Hive 데이터 선택 및 DataFrame 검색
- Hive에 DataFrame 일괄 쓰기
- Hive update 문 실행
- Hive에서 테이블 데이터 읽기, Spark에서 데이터 변환 및 새 Hive 테이블에 데이터 쓰기
- HiveStreaming를 사용하여 Hive에 DataFrame 또는 Spark 스트림 쓰기
Hive Warehouse Connector 설정
Important
- Spark 2.4 Enterprise Security Package 클러스터에 설치된 HiveServer2 대화형 인스턴스는 Hive Warehouse Connector에서 사용할 수 없습니다. 대신, HiveServer2 대화형 작업을 호스트하는 별도의 HiveServer2 대화형 클러스터를 구성해야 합니다. 단일 Spark 2.4 클러스터를 활용하는 Hive Warehouse Connector 구성은 지원되지 않습니다.
- HWC(Hive Warehouse Connector) 라이브러리는 WLM(워크로드 관리) 기능을 사용하도록 설정된 Interactive Query 클러스터에서 사용할 수 없습니다.
Spark 워크로드만을 보유하고 있고 HWC 라이브러리를 사용하려는 경우, Interactive Query 클러스터에서 워크로드 관리 기능을 사용하도록 설정하지 않았음을 확인해야 합니다(hive.server2.tez.interactive.queue구성이 Hive 구성에서 설정되지 않음).
Spark 워크로드(HWC) 및 LLAP 기본 워크로드를 모두 보유하고 있는 시나리오의 경우 공유 메타스토어 데이터베이스를 사용하여 두 개의 개별 Interactive Query 클러스터를 만들어야 합니다. WLM 기능을 필요에 따라 사용하도록 설정할 수 있는 네이티브 LLAP 워크로드용 클러스터 한 개, 그리고 WLM 기능을 구성하지 않아야 하는 HWC 전용 워크로드용 클러스터 한 개를 만듭니다. WLM 리소스 계획이 클러스터 한 개에서만 사용하도록 설정된 경우에도 두 클러스터 모두에서 리소스 계획을 볼 수 있습니다. 다른 클러스터의 WLM 기능에 영향을 줄 수 있으므로 WLM 기능을 사용하지 않도록 설정된 클러스터의 리소스 계획을 변경하지 마세요. - Spark는 데이터 분석을 간소화하기 위해 R 컴퓨팅 언어를 지원하지만, HWC(Hive Warehouse Connector) 라이브러리는 R와 함께 사용하도록 지원되지 않습니다. HWC 워크로드를 실행하려면 Scala, Java, Python만 지원하는 JDBC 스타일 HiveWarehouseSession API를 사용하여 Spark에서 Hive로 쿼리를 실행할 수 있습니다.
- JDBC 모드로 HiveServer2를 통해 쿼리(읽기/쓰기 모두)를 실행하는 것은 배열/구조체/맵 형식과 같은 복잡한 데이터 형식에서 지원되지 않습니다.
- HWC는 ORC 파일 형식으로만 쓰기를 지원합니다. ORC가 아닌 쓰기(예: parquet 및 텍스트 파일 형식)는 HWC를 통해 지원되지 않습니다.
Hive Warehouse Connector에는 Spark 및 Interactive Query 워크로드를 위한 별도의 클러스터가 필요합니다. Azure HDInsight에서 이러한 클러스터를 설정하려면 다음 단계를 수행합니다.
지원되는 클러스터 형식 및 버전
| HWC 버전 | Spark 버전 | InteractiveQuery 버전 |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | 대화형 쿼리 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | 대화형 쿼리 3.1 | HDI 5.0 |
클러스터 만들기
스토리지 계정 및 사용자 지정 Azure Virtual Network를 사용하여 HDInsight Spark 4.0 클러스터를 만듭니다. Azure Virtual Network에서 클러스터를 만드는 방법에 대한 자세한 내용은 기존 가상 네트워크에 HDInsight 추가를 참조하세요.
Spark 클러스터와 동일한 스토리지 계정 및 Azure Virtual Network를 사용하HDInsight Interactive Query(LLAP) 4.0 클러스터를 만듭니다.
HWC 설정 구성
예비 정보 수집
웹 브라우저에서
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE로 이동합니다. 여기서 LLAPCLUSTERNAME은 Interactive Query 클러스터의 이름입니다.요약>HiveServer2 Interactive JDBC URL로 이동하고 값을 적어 둡니다. 값은
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive과 유사할 수 있습니다.구성>고급>고급 hive-site>hive.zookeeper.quorum으로 이동한 후 값을 적어 둡니다. 값은
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181과 유사할 수 있습니다.구성>고급>일반>hive.metastore.uris로 이동한 후 값을 적어 둡니다. 값은
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083과 유사할 수 있습니다.구성>고급>고급 hive-interactive-site>hive.llap.daemon.service.hosts로 이동한 후 값을 적어 둡니다. 값은
@llap0과 유사할 수 있습니다.
Spark 클러스터 설정 구성
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs로 이동합니다. 여기서 CLUSTERNAME은 Apache Spark 클러스터의 이름입니다.사용자 지정 spark2-defaults를 확장합니다.
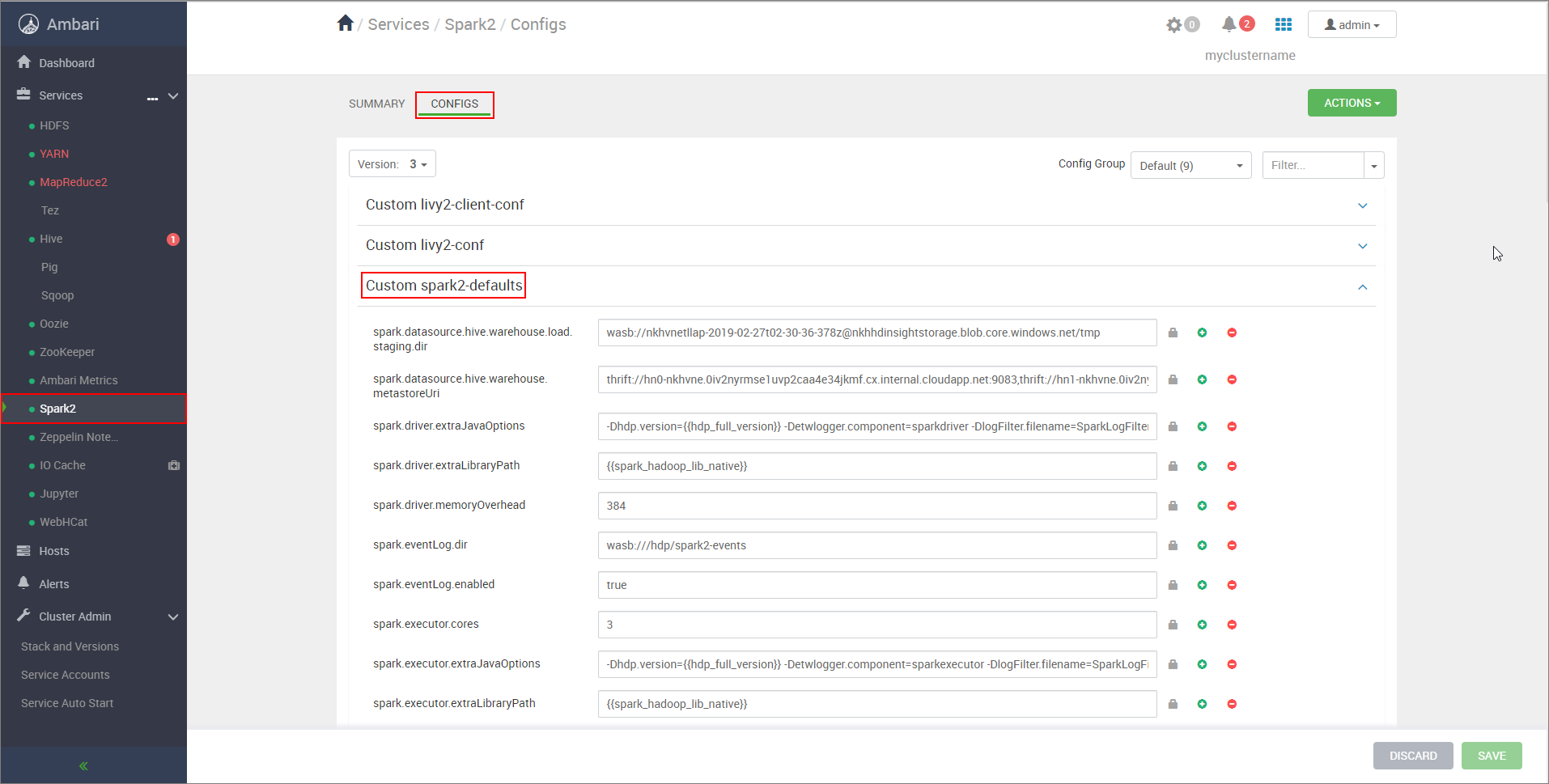
속성 추가...를 선택하여 다음 구성을 추가합니다.
구성 값 spark.datasource.hive.warehouse.load.staging.dirADLS Gen2 스토리지 계정을 사용하는 경우 abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp을 사용합니다.
Azure Blob Storage 계정을 사용하는 경우wasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp을 사용합니다.
적절한 HDFS 호환 스테이징 디렉터리로 설정합니다. 다른 두 개의 클러스터가 있는 경우 스테이징 디렉터리는 HiveServer2에서 액세스할 수 있도록 LLAP 클러스터 스토리지 계정의 스테이징 디렉터리에 있는 폴더여야 합니다.STORAGE_ACCOUNT_NAME을 클러스터에서 사용하는 스토리지 계정의 이름으로 바꾸고STORAGE_CONTAINER_NAME을 스토리지 컨테이너의 이름으로 바꿉니다.spark.sql.hive.hiveserver2.jdbc.urlHiveServer2 Interactive JDBC URL에서 이전에 가져온 값입니다. spark.datasource.hive.warehouse.metastoreUri이전에 hive.metastore.uris에서 가져온 값입니다. spark.security.credentials.hiveserver2.enabledYARN 클러스터 모드의 경우 true, YARN 클라이언트 모드의 경우false입니다.spark.hadoop.hive.zookeeper.quorum이전에 hive.zookeeper.quorum에서 가져온 값입니다. spark.hadoop.hive.llap.daemon.service.hosts이전에 hive.llap.daemon.service.hosts에서 가져온 값입니다. 변경 내용을 저장하고 영향을 받는 모든 구성 요소를 다시 시작합니다.
ESP(Enterprise Security Package) 클러스터에 대한 HWC 구성
ESP(Enterprise Security Package)는 Azure HDInsight의 Apache Hadoop 클러스터에 대한 Active Directory 기반 인증, 다중 사용자 지원 및 역할 기반 액세스 제어와 같은 엔터프라이즈급 기능을 제공합니다. ESP에 대한 자세한 내용은 HDInsight에서 Enterprise Security Package 사용을 참조하세요.
이전 섹션에서 설명한 구성과는 별도로 다음 구성을 추가하여 ESP 클러스터에서 HWC를 사용합니다.
Spark 클러스터의 Ambari 웹 UI에서 Spark2>구성>사용자 지정 Spark2-defaults로 이동합니다.
다음 속성을 업데이트합니다.
구성 값 spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary로 이동합니다. 여기서 CLUSTERNAME은 Interactive Query 클러스터의 이름입니다. HiveServer2 Interactive를 클릭합니다. 스크린샷과 같이 LLAP가 실행 중인 헤드 노드의 FQDN(정규화된 도메인 이름)이 보입니다.<llap-headnode>를 이 값으로 바꿉니다.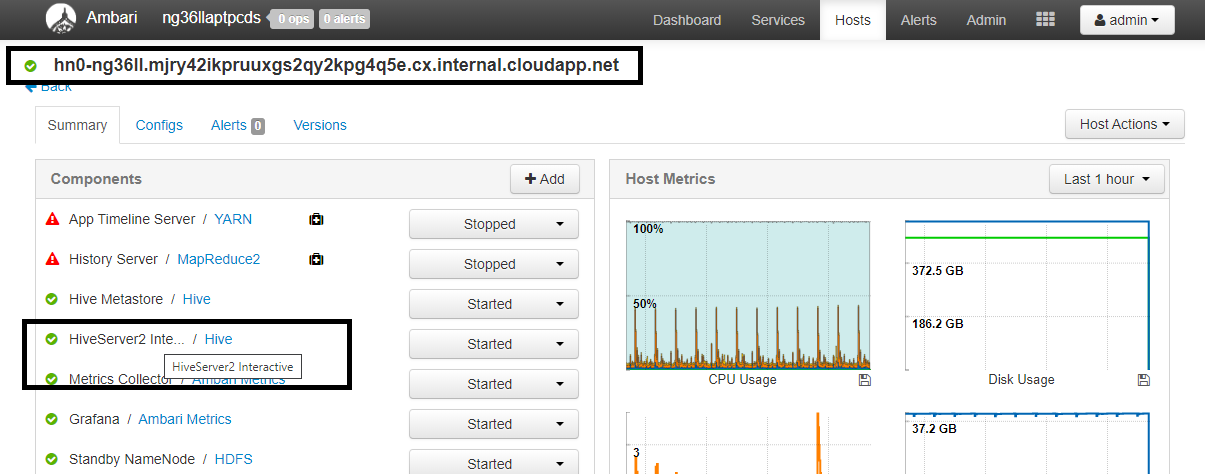
ssh 명령을 사용하여 Interactive Query 클러스터에 연결합니다.
/etc/krb5.conf파일에서default_realm매개 변수를 찾습니다.<AAD-DOMAIN>을 대문자 문자열로 하여 이 값으로 바꿉니다. 그렇지 않으면 자격 증명을 찾을 수 없습니다.
예:
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET
변경 내용을 저장하고 필요하면 구성 요소를 다시 시작합니다.
Hive Warehouse Connector 사용
몇 가지 방법 중 하나를 선택하여 Interactive Query 클러스터에 연결하고 Hive Warehouse Connector를 사용하여 쿼리를 실행할 수 있습니다. 지원되는 방법에는 다음 도구가 포함됩니다.
Spark에서 HWC에 연결하는 몇 가지 예제는 다음과 같습니다.
Spark-shell
이는 수정된 Scala 셸 버전을 통해 대화형으로 Spark를 실행하는 방법입니다.
ssh command 명령을 사용하여 Apache Spark 클러스터에 연결합니다. CLUSTERNAME을 클러스터 이름으로 바꿔서 아래 명령을 편집하고, 다음 명령을 입력합니다.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netssh 세션에서 다음 명령을 실행하여
hive-warehouse-connector-assembly버전을 확인합니다.ls /usr/hdp/current/hive_warehouse_connector위에서 식별된
hive-warehouse-connector-assembly버전을 사용하여 아래 코드를 편집합니다. 그런 다음 명령을 실행하여 Spark 셸을 시작합니다.spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseSpark 셸을 시작한 뒤 다음 명령을 사용하여 Hive Warehouse Connector 인스턴스를 시작할 수 있습니다.
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit은 Spark 클러스터에 모든 Spark 프로그램(또는 작업)을 제출하는 유틸리티입니다.
Spark-submit 작업은 지침에 따라 Spark 및 Hive Warehouse Connector를 설정, 구성하고 이에 전달한 프로그램을 실행한 후 사용 중인 리소스를 완전히 해제합니다.
어셈블리 jar에 대한 종속성에 따라 scala/java 코드를 빌드한 후 아래 명령을 사용하여 Spark 애플리케이션을 시작합니다. <VERSION> 및 <APP_JAR_PATH>를 실제 값으로 바꿉니다.
YARN 클라이언트 모드
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN 클러스터 모드
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
이 유틸리티는 pySpark에서 전체 애플리케이션을 쓰고 .py 파일(Python)로 패키지한 경우에도 사용되므로 실행하기 위해 전체 코드를 Spark 클러스터에 제출할 수 있습니다.
Python 애플리케이션의 경우 .py 파일을 /<APP_JAR_PATH>/myHwcAppProject.jar 대신 전달하고 --py-files를 사용하여 아래의 구성(Python .zip) 파일을 검색 경로에 추가합니다.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
ESP(Enterprise Security Package) 클러스터에 대해 쿼리 실행
spark-shell 또는 spark-submit을 시작하기 전에 kinit를 사용합니다. USERNAME을 클러스터에 액세스할 수 있는 권한이 있는 도메인 계정의 이름으로 바꾸고 다음 명령을 실행합니다.
kinit USERNAME
Spark ESP 클러스터에서 데이터 보호
다음 명령을 입력하여 몇 가지 샘플 데이터를 포함하는 테이블
demo를 만듭니다.create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');다음 명령을 사용하여 테이블의 내용을 봅니다. 정책을 적용하기 전에
demo표는 전체 열을 표시합니다.hive.executeQuery("SELECT * FROM demo").show()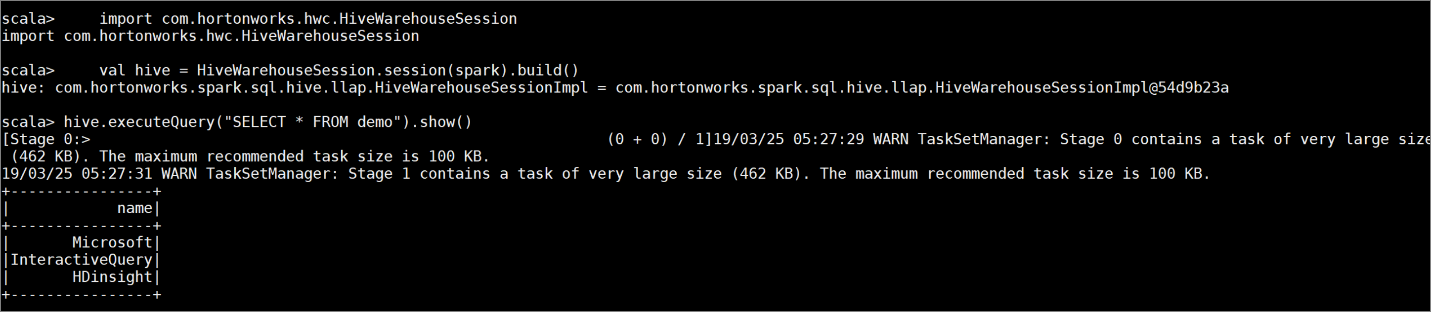
열의 마지막 4자만 표시하는 열 마스킹 정책을 적용합니다.
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/에서 Ranger 관리 UI로 이동합니다.Hive에서 클러스터에 대한 Hive 서비스를 클릭합니다.
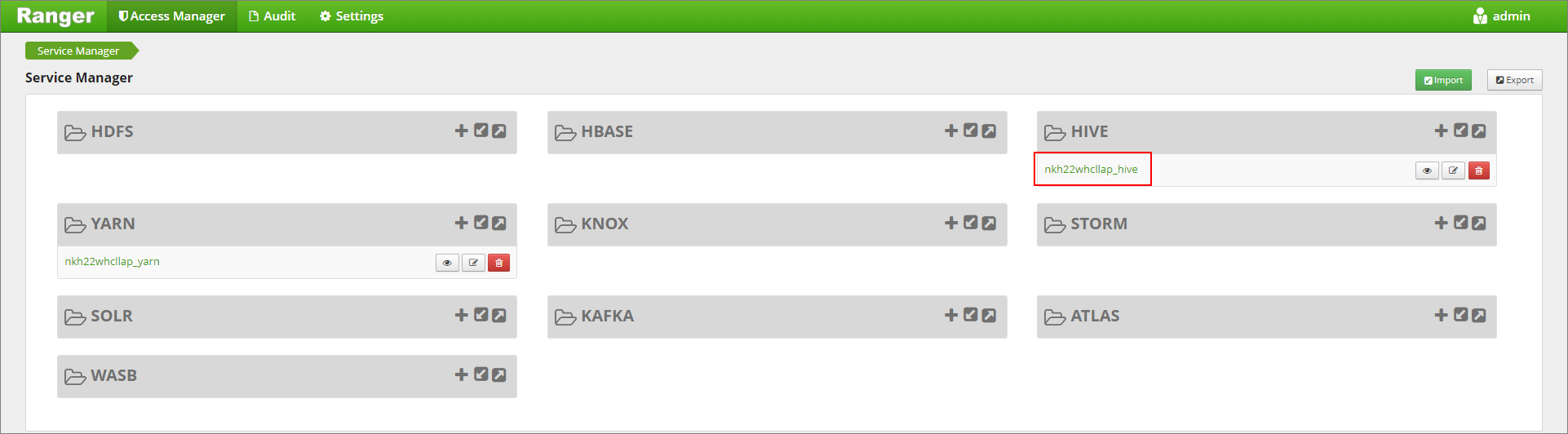
마스킹 탭을 클릭하고 새 정책 추가를 클릭합니다.
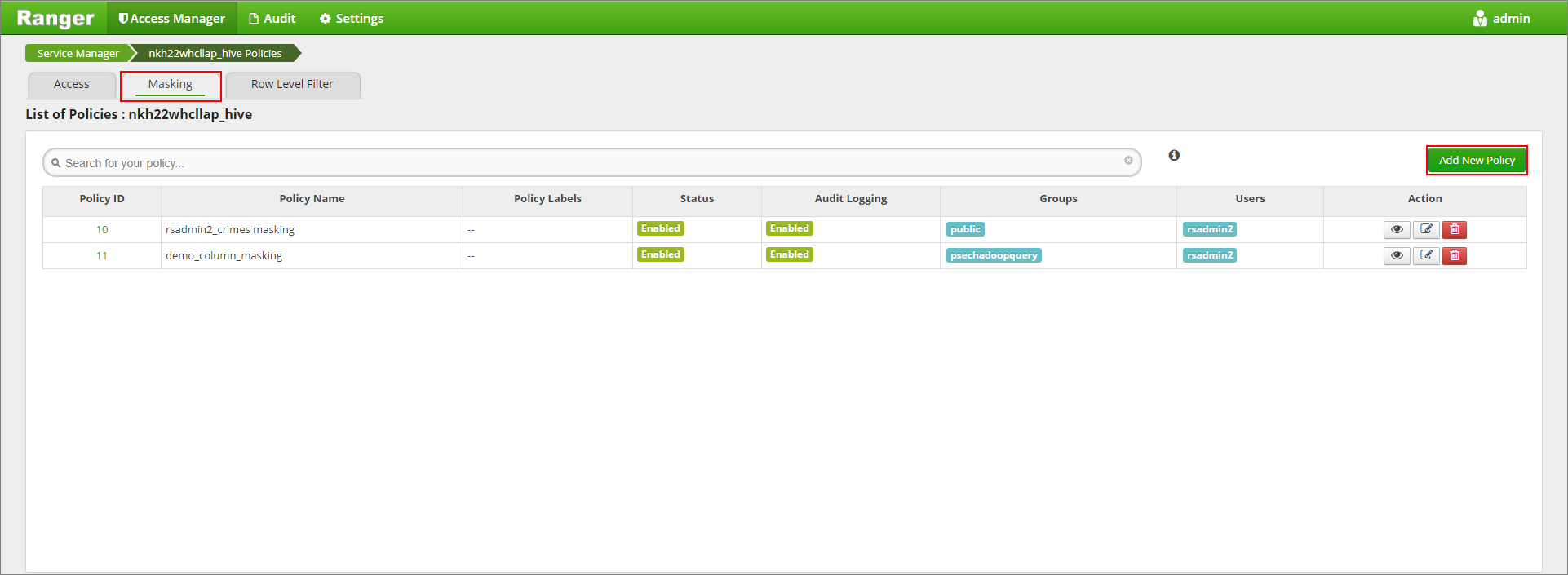
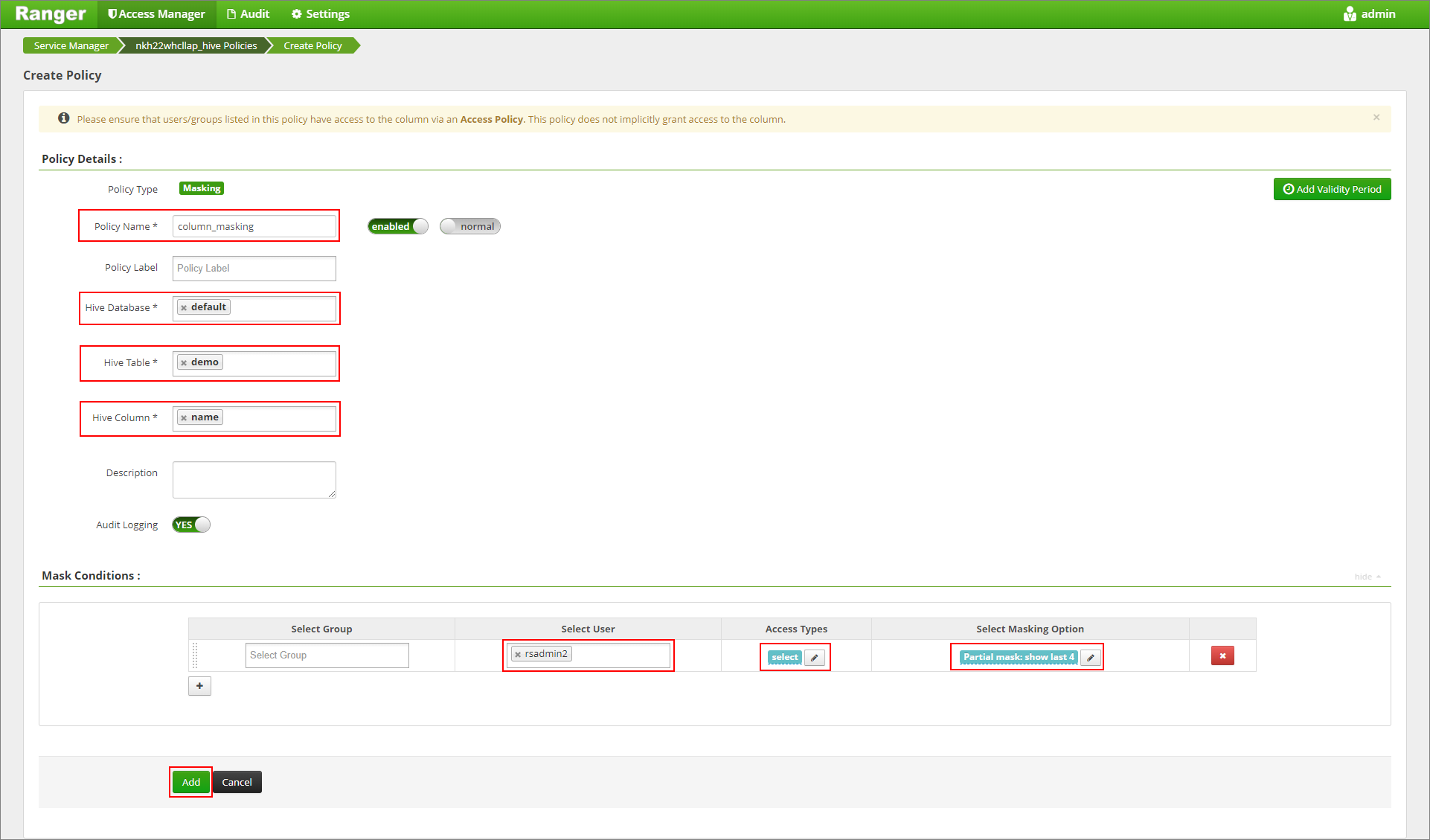
원하는 정책 이름을 제공합니다. 데이터베이스: defalut, Hive 테이블: demo, Hive 열: name, 사용자: rsadmin2, 액세스 형식: select, 마스킹 옵션 선택 메뉴: Partial mask: show last 4를 선택합니다. 추가를 클릭합니다.
테이블의 내용을 다시 봅니다. Ranger 정책을 적용한 후에는 열의 마지막 4자만 볼 수 있습니다.
