HDInsight의 Azure Storage 개요
Azure Storage는 HDInsight와 매끄럽게 통합되는 강력한 범용 스토리지 솔루션입니다. HDInsight는 Azure Storage의 Blob 컨테이너를 클러스터의 기본 파일 시스템으로 사용합니다. HDInsight의 모든 구성 요소 집합은 HDFS 인터페이스를 통해 Blob에 저장된 구조적 또는 비구조적 데이터에서 직접 작동할 수 있습니다.
기본 클러스터 스토리지 및 비즈니스 데이터에 별도의 스토리지 컨테이너를 사용하기를 권합니다. 분리는 사용자 고유의 비즈니스 데이터에서 HDInsight 로그 및 임시 파일을 격리하는 것입니다. 또한 스토리지 비용을 줄이기 위해 사용 후에 응용 프로그램 및 시스템 로그를 포함한 기본 Blob 컨테이너를 삭제하는 것이 좋습니다. 컨테이너를 삭제하기 전에 이러한 로그를 검색해야 합니다.
스토리지 계정을 방화벽과 가상 네트워크 제한 사항을 선택한 네트워크에 걸어서 보호하기로 했다면 반드시 신뢰하는 Microsoft 서비스 허용...이라는 예외사항을 허용하세요. 이 예외 사항을 지정해야 HDInsight가 사용자의 스토리지 계정에 액세스할 수 있습니다.
HDInsight 스토리지 아키텍처
다음 다이어그램은 Azure Storage의 HDInsight 아키텍처 추상 보기를 제공합니다.
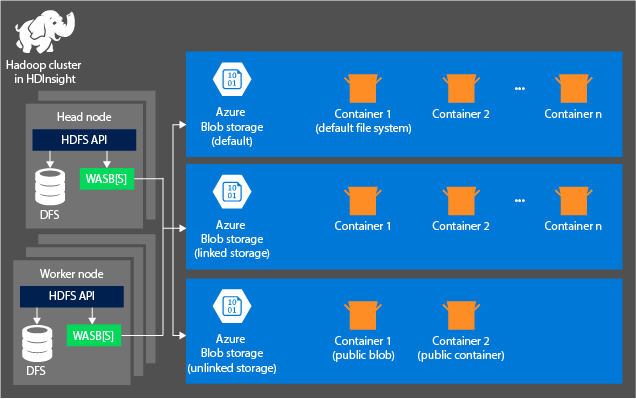
HDInsight는 컴퓨팅 노드에 로컬로 연결된 분산 파일 시스템에 대한 액세스를 제공합니다. 정규화된 URI를 사용하여 이 파일 시스템에 액세스할 수 있습니다. 예를 들면 다음과 같습니다.
hdfs://<namenodehost>/<path>
HDInsight를 통해 Azure Storage의 데이터에 액세스할 수도 있습니다. 구문은 다음과 같습니다.
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
계층 구조 네임스페이스(Azure Data Lake Storage Gen2)가 있는 계정의 경우 구문은 다음과 같습니다.
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
HDInsight 클러스터와 Azure Storage 계정을 사용하는 경우 다음 원칙을 고려하세요.
클러스터에 연결된 스토리지 계정의 컨테이너: 계정 이름과 키는 만들기 중 클러스터와 연결되므로 사용자는 이러한 컨테이너의 Blob에 대한 모든 권한을 보유합니다.
클러스터에 연결되지 않은 스토리지 계정의 공용 컨테이너 또는 공용 Blob: 컨테이너의 Blob에 대한 읽기 전용 권한을 가집니다.
참고 항목
공용 컨테이너를 사용하면 해당 컨테이너에서 사용할 수 있는 모든 Blob 목록 및 컨테이너 메타데이터를 가져올 수 있습니다. 공용 Blob을 사용하면 정확한 URL을 아는 경우에만 Blob에 액세스할 수 있습니다. 자세한 내용은 컨테이너 및 Blob에 대한 익명 읽기 권한 관리를 참조하세요.
클러스터에 연결되지 않은 스토리지 계정의 프라이빗 컨테이너: WebHCat 작업을 제출할 때 스토리지 계정을 정의하지 않으면 컨테이너의 Blob에 액세스할 수 없습니다.
만들기 프로세스에서 정의된 스토리지 계정과 해당 키는 클러스터 노드의 %HADOOP_HOME%/conf/core-site.xml에 저장됩니다. 기본적으로 HDInsight는 core-site.xml 파일에 정의된 스토리지 계정을 사용합니다. Apache Ambari를 사용하여 이 설정을 수정할 수 있습니다. core-site.xml 파일에서 수정하거나 배치할 수 있는 스토리지 계정 설정에 대한 자세한 내용은 다음 문서를 참조하세요.
여러 WebHCat 작업(Apache Hive 포함). Hive, MapReduce, Apache Hadoop 스트리밍 및 Pig를 비롯한 작업은 스토리지 계정 및 메타데이터 설명이 필요합니다. (이 양상은 현재 스토리지 계정이 있는 Pig에는 해당되지만 메타데이터에는 해당되지 않습니다.) 자세한 내용은 대체 스토리지 계정 및 메타스토어와 함께 HDInsight 클러스터 사용을 참조하세요.
구조적 및 비구조적 데이터에 대한 Blob을 사용할 수 있습니다. Blob 컨테이너는 키/값 쌍으로 데이터를 저장하며, 디렉터리 계층 구조는 없습니다. 그러나 파일이 디렉터리 구조 내에 저장된 것처럼 보이도록 키 이름에 슬래시 문자(/)를 포함할 수 있습니다. 예를 들어, Blob 키는 input/log1.txt일 수 있습니다. 실제로 input 디렉터리는 없지만 키 이름에 슬래시 문자가 있으므로 키가 파일 경로처럼 보입니다.
Azure Storage의 이점
함께 배치되지 않은 컴퓨팅 클러스터와 스토리지 리소스는 성능 비용을 초래합니다. 이러한 비용은 컴퓨팅 클러스터를 Azure 지역 내의 스토리지 계정 리소스와 비슷한 방식으로 만들어 완화할 수 있습니다. 이 지역에서 컴퓨팅 노드는 Azure Storage 내의 고속 네트워크를 통해 데이터에 효율적으로 액세스할 수 있습니다.
HDFS 대신 Azure Storage에 데이터를 저장할 때 다음과 같은 몇 가지 이점이 있습니다.
데이터 다시 사용 및 공유: HDFS의 데이터는 컴퓨팅 클러스터 내에 있습니다. 컴퓨팅 클러스터에 액세스할 수 있는 애플리케이션만 HDFS API를 통해 데이터를 사용할 수 있습니다. 반대로, Azure Storage의 데이터는 HDFS API 또는 Blob 스토리지 REST API를 통해 액세스할 수 있습니다. 이러한 정렬 방식 때문에 데이터의 생성과 소비에 더 많은 애플리케이션(기타 HDInsight 클러스터 포함)과 도구를 사용할 수 있습니다.
데이터 아카이빙: 데이터가 Azure Storage에 저장되면 컴퓨팅에 사용된 HDInsight 클러스터 데이터 손실 없이 안전하게 삭제될 수 있습니다.
데이터 스토리지 비용: DFS에 장기간 데이터를 저장하면 Azure Storage에 저장할 때보다 비용이 더 비쌉니다. 계산 클러스터의 비용이 Azure Storage 비용보다 비싸기 때문입니다. 또한 컴퓨팅 클러스터를 생성할 때마다 데이터를 다시 로드할 필요가 없기 때문에 데이터 로드 비용도 절약됩니다.
탄력적인 확장: HDFS는 확장된 파일 시스템을 제공하지만, 확장은 클러스터에 대해 만드는 노드의 수에 의해 결정됩니다. 규모 변경이 Azure Storage에서 자동으로 수행되는 탄력적인 확장 기능보다 더 복잡해질 수 있습니다.
지역에서 복제: Azure Storage를 지역에서 복제할 수 있습니다. 지역에서 복제는 지리적 복구와 데이터 중복 기능을 제공하지만, 지역에서 복제된 위치에 대한 장애 조치(failover)는 성능에 심각한 영향을 미치게 되며 추가 비용을 발생시킬 수 있습니다. 따라서 지역에서 복제 기능은 신중하게 선택해야 하며, 추가 비용을 감수할 만큼 가치 있는 데이터에만 사용하는 것이 좋습니다.
특정 MapReduce 작업과 패키지는 Azure Storage에 전혀 저장하고 싶지 않을 만한 중간 결과를 생성할 수 있습니다. 그런 경우에는 로컬 HDFS에 데이터를 저장하도록 선택할 수 있습니다. HDInsight는 Hive 작업 및 기타 프로세스에서 생성되는 이러한 중간 결과 중 일부에 DFS를 사용합니다.
참고 항목
대부분의 HDFS 명령(예: ls, copyFromLocal 및 mkdir)은 Azure Storage에서 여전히 예상대로 작동합니다. fschk 및 dfsadmin과 같은 기본 HDFS 구현(DFS라고 함)에 해당하는 명령만 Azure Storage에서 다르게 동작합니다.