자습서: Azure HDInsight의 Apache Spark 클러스터에서 데이터 로드 및 쿼리 실행
이 자습서에서는 csv 파일에서 데이터 프레임을 만드는 방법과 Azure HDInsight의 Apache Spark 클러스터에 대해 대화형 Spark SQL 쿼리를 실행하는 방법을 알아봅니다. Spark에서 데이터 프레임은 명명된 열로 구성된 데이터의 분산된 컬렉션입니다. 데이터 프레임은 관계형 데이터베이스의 테이블이나 R/Python의 데이터 프레임과 개념적으로 동일합니다.
이 자습서에서는 다음 방법에 관해 알아봅니다.
- csv 파일에서 데이터 프레임 만들기
- 데이터 프레임에서 쿼리 실행
필수 조건
HDInsight의 Apache Spark. Apache Spark 클러스터 만들기를 참조하세요.
Jupyter Notebook 만들기
Jupyter Notebook은 다양한 프로그래밍 언어를 지원하는 대화형 Notebook 환경입니다. Notebook을 사용하면 데이터와 상호 작용하고, 코드를 markdown 텍스트와 결합하고, 간단한 시각화를 수행할 수 있습니다.
SPARKCLUSTER를 Spark 클러스터의 이름으로 바꿔 URLhttps://SPARKCLUSTER.azurehdinsight.net/jupyter를 편집합니다. 그런 다음, 웹 브라우저에 편집한 URL을 입력합니다. 메시지가 표시되면 클러스터에 대한 클러스터 로그인 자격 증명을 입력합니다.Jupyter 웹 페이지에서 Spark 2.4 클러스터에 대해 새로 만들기>PySpark를 선택하여 Notebook을 만듭니다. Spark 3.1 릴리스의 경우 Spark 3.1에서 PySpark 커널을 더 이상 사용할 수 없으므로 Notebook을 만들려면 대신 새로 만들기>PySpark3을 선택합니다.
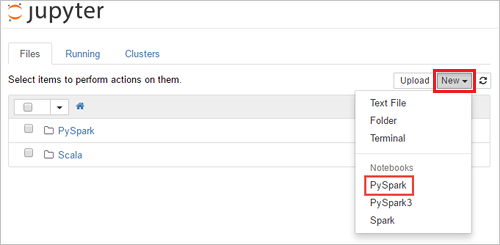
새 노트북이 만들어지고 이름 Untitled(
Untitled.ipynb)로 열립니다.참고 항목
PySpark 또는 PySpark3 커널을 사용하여 Notebook을 만들면 첫 번째 코드 셀을 실행할 때
spark세션이 자동으로 만들어집니다. 세션을 명시적으로 만들 필요가 없습니다.
csv 파일에서 데이터 프레임 만들기
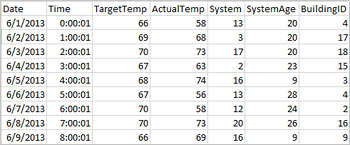
애플리케이션은 Azure Storage, Azure Data Lake Storage 같은 원격 스토리지의 파일 또는 폴더에서, Hive 테이블에서 또는 Spark에서 지원하는 Azure Cosmos DB, Azure SQL DB, DW 등의 기타 데이터 원본에서 직접 데이터 프레임을 만들 수 있습니다. 다음 스크린샷에서는 이 자습서에 사용되는 HVAC.csv 파일의 스냅샷을 보여줍니다. csv 파일에는 모든 HDInsight Spark 클러스터가 함께 제공됩니다. 이 데이터는 건물의 온도 변화를 캡처합니다.
Jupyter Notebook의 빈 셀에 다음 코드를 붙여넣은 다음, SHIFT + ENTER를 눌러 해당 코드를 실행합니다. 코드는 이 시나리오에 필요한 형식을 가져옵니다.
from pyspark.sql import * from pyspark.sql.types import *Jupyter에서 대화형 쿼리를 실행하면 웹 브라우저 창 또는 탭 캡션에 노트북 제목과 함께 (사용 중) 상태가 표시됩니다. 또한 오른쪽 위 모서리에 있는 PySpark 텍스트 옆에 단색 원이 표시됩니다. 작업이 완료되면 속이 빈 원으로 변경됩니다.
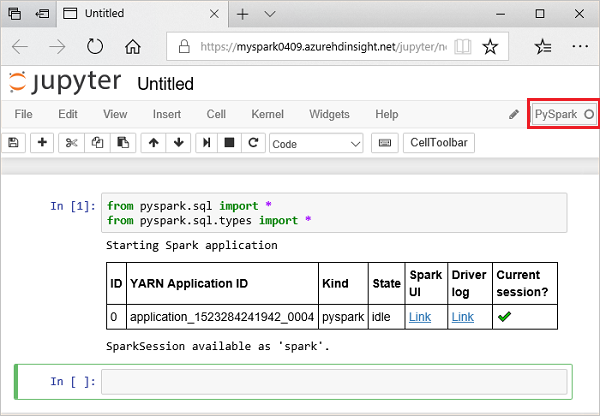
반환된 세션 ID를 확인합니다. 위의 그림에서 세션 ID는 0입니다. 원하는 경우
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statements로 이동하여 세션 세부 정보를 검색할 수 있습니다. 여기서 CLUSTERNAME은 Spark 클러스터의 이름이고 ID는 세션 ID 번호입니다.다음 코드를 실행하여 데이터 프레임 및 임시 테이블(hvac)을 만듭니다.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
데이터 프레임에서 쿼리 실행
테이블이 만들어지면 데이터에 대한 대화형 쿼리를 실행할 수 있습니다.
노트북의 빈 셀에서 다음 코드를 실행합니다.
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"다음과 같은 테이블 형식 출력이 표시됩니다.
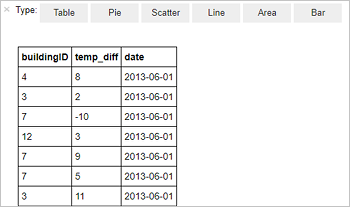
다른 시각화로 결과를 볼 수도 있습니다. 동일한 출력에 대한 영역형 그래프를 보려면 영역을 선택한 다음 표시된 것처럼 다른 값을 설정합니다.
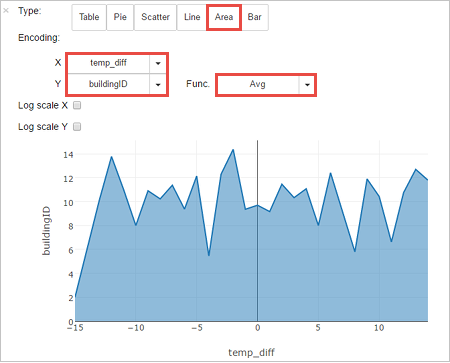
Notebook 메뉴 모음에서 파일>저장 및 검사점으로 이동합니다.
이제 다음 자습서를 시작하는 경우 Notebook을 열어 둡니다. 그렇지 않은 경우 Notebook을 종료하여 클러스터 리소스를 해제합니다. Notebook 메뉴 모음에서 파일>닫기 및 중지로 이동합니다.
리소스 정리
HDInsight를 사용하면 데이터와 Jupyter Notebooks가 Azure Storage 또는 Azure Data Lake Storage에 저장되므로 클러스터를 사용하지 않을 때 안전하게 삭제할 수 있습니다. HDInsight 클러스터를 사용하지 않는 기간에도 요금이 청구됩니다. 클러스터에 대한 요금이 스토리지에 대한 요금보다 몇 배 더 많기 때문에, 클러스터를 사용하지 않을 때는 삭제하는 것이 경제적인 면에서 더 합리적입니다. 다음 자습서의 작업을 바로 수행하려는 경우 클러스터를 유지할 수 있습니다.
Azure Portal에서 클러스터를 열고 삭제를 선택합니다.
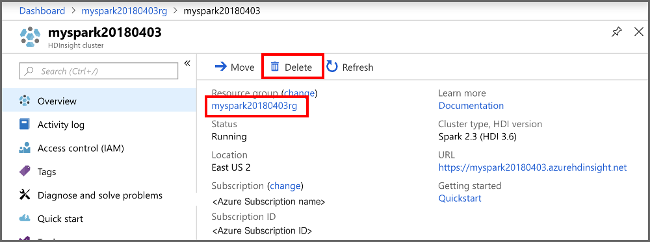
또한 리소스 그룹 이름을 선택하여 리소스 그룹 페이지를 연 다음, 리소스 그룹 삭제를 선택할 수도 있습니다. 리소스 그룹을 삭제하여 HDInsight Spark 클러스터와 기본 스토리지 계정을 삭제합니다.
다음 단계
이 자습서에서는 csv 파일에서 데이터 프레임을 만드는 방법과 Azure HDInsight의 Apache Spark 클러스터에 대해 대화형 Spark SQL 쿼리를 실행하는 방법을 알아보았습니다. 다음 문서로 진행하여 Apache Spark에 등록된 데이터를 Power BI와 같은 BI 분석 도구로 가져오는 방법을 확인하세요.