Azure Logic Apps에서 제한 문제(429-"너무 많은 요청" 오류) 처리
적용 대상: Azure Logic Apps(사용량 + 표준)
논리 앱 워크플로에서 요청 수가 대상이 특정 시간 동안 처리할 수 있는 속도를 초과할 때 발생하는 제한 상황이 나타날 경우 "HTTP 429 요청이 너무 많음" 오류가 발생합니다. 제한은 데이터 처리 지연, 성능 속도 감소, 지정된 재시도 정책 초과 등의 오류와 같은 문제를 만들 수 있습니다.
예를 들어 소비 워크플로의 다음 SQL Server 작업은 제한 문제를 보고하는 429 오류를 보여 줍니다.
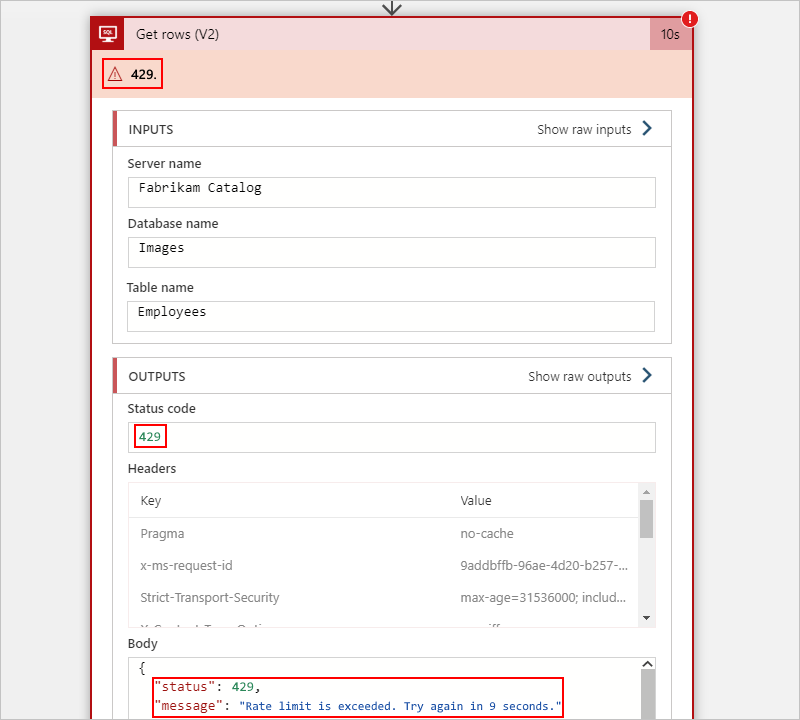
다음 섹션에서는 워크플로에 제한이 발생할 수 있는 일반적인 수준에 대해 설명합니다.
논리 앱 리소스 제한
Azure Logic Apps에는 고유한 처리량 제한이 있습니다. 논리 앱 리소스가 이러한 제한을 초과하는 경우 특정 워크플로 인스턴스나 실행 뿐만 아니라 논리 앱 리소스 또한 제한됩니다.
이 수준에서 제한 이벤트를 찾으려면 다음 단계를 수행합니다.
Azure Portal에서 논리 앱 리소스를 엽니다.
논리 앱 리소스 메뉴에서 모니터링 하의 메트릭을 선택합니다.
차트 제목에서 메트릭 추가를 선택합니다. 그러면 차트에 다른 메트릭 막대가 추가됩니다.
메트릭 목록의 첫 번째 메트릭 표시줄에서 제한된 이벤트 작업을 선택합니다. 집계 목록에서 개수를 선택합니다.
메트릭 목록의 두 번째 메트릭 표시줄에서 제한된 이벤트 트리거를 선택합니다. 집계 목록에서 개수를 선택합니다.
이제 차트에는 논리 앱 워크플로의 작업 및 트리거 모두에 대해 제한된 이벤트가 표시됩니다. 자세한 내용은 Azure Logic Apps에서 워크플로 상태 및 성능에 대한 메트릭 보기를 참조하세요.
이 수준에서 제한을 처리하기 위해 다음 옵션을 사용할 수 있습니다.
동시에 실행할 수 있는 워크플로 인스턴스 수를 제한합니다.
기본적으로 워크플로의 트리거 조건이 동시에 두 번 이상 충족되는 경우, 해당 트리거의 여러 인스턴스가 동시 또는 ‘병렬로’ 실행됩니다. 각 트리거 인스턴스는 이전 워크플로 인스턴스 실행이 완료되기 전에 발생합니다.
동시에 실행할 수 있는 트리거 인스턴스의 기본 수는 무제한이지만, 트리거의 동시성 설정을 활성화하여 이 수를 제한하고, 필요한 경우 기본값 이외의 제한을 선택할 수 있습니다.
높은 처리량 모드 사용
소비 워크플로에는 5분 롤링 간격 동안 실행할 수 있는 작업 수에 대한 기본 제한이 있습니다. 이 제한을 최대 작업 수로 높이려면 논리 앱 리소스에서 높은 처리량 모드를 활성화합니다.
표준 워크플로는 어떤 간격에서도 실행할 수 있는 작업 수에 제한이 없습니다.
트리거에서 배열 분리 또는 "분할 켜기" 동작을 사용하지 않도록 설정합니다.
트리거가 처리할 나머지 워크플로 작업에 대한 배열을 반환하는 경우 트리거의 분할 켜기 설정은 배열 항목을 분할하고 각 배열 항목에 대한 워크플로 인스턴스를 시작합니다. 이 동작은 분할 켜기 제한까지 여러 동시 실행을 효과적으로 트리거합니다.
제한을 제어하려면 트리거의 분할 켜기 동작을 비활성화하고 워크플로가 호출당 단일 항목을 처리하는 대신 단일 호출로 전체 배열을 처리하도록 합니다.
작업을 더 작은 여러 개의 워크플로로 리팩터링합니다.
앞에서 설명한 것처럼, 소비 논리 앱 워크플로는 5분 동안 실행할 수 있는 기본 작업 수로 제한됩니다. 높은 처리량 모드를 사용하도록 설정하여 이 제한을 늘릴 수 있지만, 각 워크플로에서 실행되는 작업의 수가 한도 미만으로 유지되도록 워크플로의 작업을 더 작은 워크플로로 세분화할지 여부를 고려할 수도 있습니다. 이를 통해 단일 워크플로에 대한 부담을 줄이고 여러 워크플로에 부하를 분산할 수 있습니다. 이 솔루션은 대규모 데이터 집합을 처리하거나 동시에 실행되는 작업, 루프 반복 또는 작업 실행 제한을 초과하는 각 루프 반복 내에서 작업을 스핀업하는 것에 더 적합합니다.
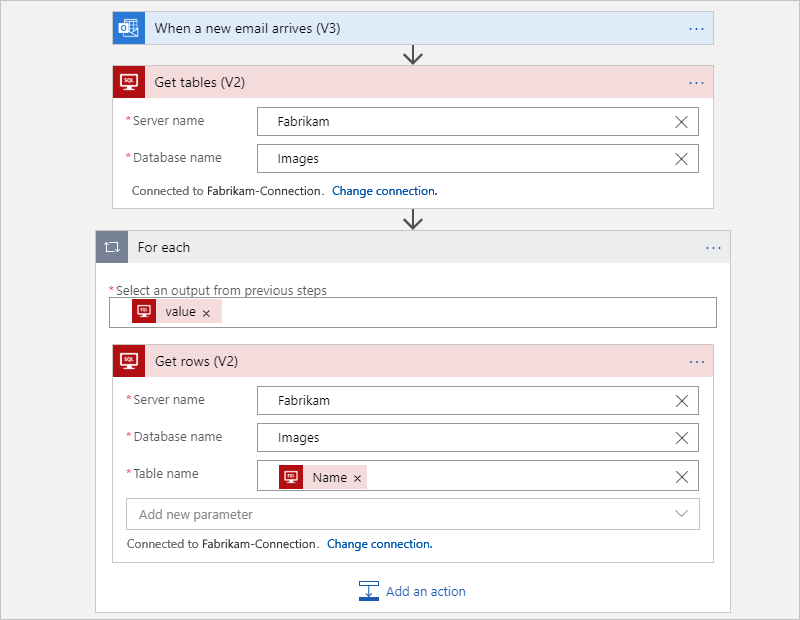
예를 들어 다음 소비 워크플로는 모든 작업을 수행하여 SQL Server 데이터베이스에서 테이블을 가져오고 각 테이블에서 행을 가져옵니다. For each 루프는 각 테이블을 동시에 반복하여 Get rows 작업이 각 테이블에 대한 행을 반환할 수 있도록 합니다. 이러한 테이블의 데이터 양에 따라 이러한 작업은 작업 실행 제한을 초과할 수 있습니다.
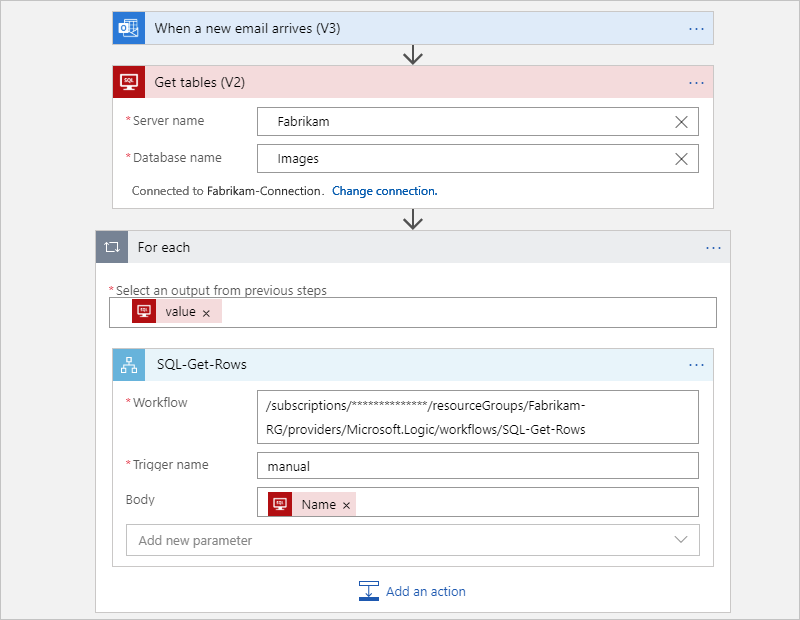
리팩터링 후 원래 워크플로는 부모 워크플로 및 자식 워크플로로 분할됩니다.
다음 상위 워크플로는 SQL Server에서 테이블을 가져온 후 각 테이블에 대한 하위 워크플로를 호출하여 행을 가져옵니다.
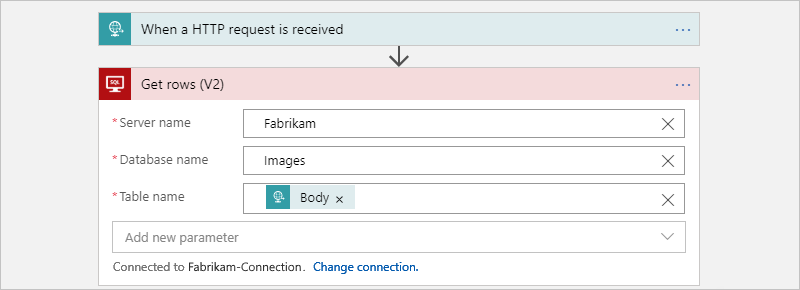
부모 워크플로에서 각 테이블의 행을 가져오기 위해 다음 자식 워크플로를 호출합니다.
커넥터 제한
각 커넥터에는 고유한 제한 한도가 있으며, 이는 각 커넥터의 기술 참조 페이지에서 찾을 수 있습니다. 예를 들어 Azure Service Bus 커넥터에는 분당 최대 6000 호출을 허용하는 제한 한도가 있고, SQL Server 커넥터에는 작업 유형에 따라 다른 제한 한도가 있습니다.
HTTP와 같은 일부 트리거 및 작업에는 예외 처리를 구현하기 위해 재시도 정책 제한에 기반하여 사용자 지정할 수 있는 "재시도 정책"이 있습니다. 이 정책은 기존의 요청이 실패하거나 시간 초과되어 408, 429 또는 5xx 응답으로 이어지는 경우 트리거 또는 작업이 요청을 재시도할지 여부 및 빈도를 지정합니다. 따라서 제한이 시작되고 429 오류가 반환되면, Logic Apps는 지원되는 경우 재시도 정책을 따릅니다.
트리거 또는 작업에서 재시도 정책을 지원하는지 확인하려면 트리거 또는 작업의 설정을 확인 합니다. 트리거 또는 작업의 재시도를 보려면 논리 앱의 실행 기록으로 이동하여 검토할 실행을 선택하고, 해당 트리거 또는 작업을 확장하여 입력, 출력 및 재시도에 대한 세부 정보를 확인합니다.
다음 소비 워크플로 예제에서는 HTTP 작업에 대한 이 정보를 찾을 수 있는 위치를 보여 줍니다.
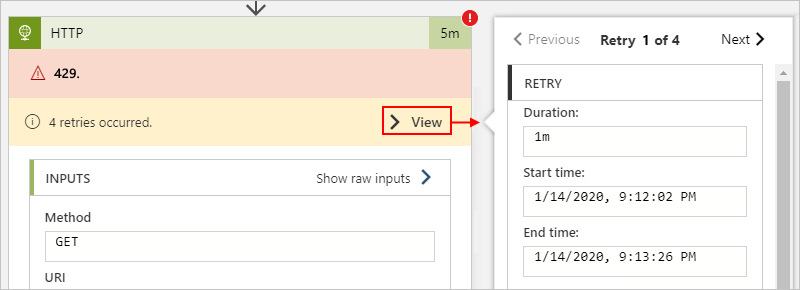
재시도 기록이 오류 정보를 제공하지만, 커넥터 제한과 대상 제한을 구분하는 데는 문제가 있을 수 있습니다. 이 경우 응답의 세부 정보를 검토하거나 일부 제한 간격을 계산하여 원본을 파악해야 할 수 있습니다.
다중 테넌트 Azure Logic Apps의 소비 논리 앱 워크플로의 경우, 제한이 ‘연결’ 수준에서 발생합니다. ISE(통합 서비스 환경)에서 실행되는 논리 앱 워크플로의 경우 다중 테넌트 Azure Logic Apps에서 실행되기 때문에 비 ISE 연결에 대한 제한이 여전히 발생합니다. 그러나 ISE 커넥터에서 만든 ISE 연결은 사용자의 ISE에서 실행되기 때문에 제한되지 않습니다.
이 수준에서 제한을 처리하기 위해 다음 옵션을 사용할 수 있습니다.
워크플로가 처리를 위해 데이터를 분할하도록 단일 작업에 대해 여러 연결을 설정합니다.
동일한 자격 증명을 사용하여 작업의 요청을 동일한 대상에 대한 여러 연결로 나누어 워크로드를 분산할 수 있는지 여부를 고려합니다.
예를 들어 워크플로가 SQL Server 데이터베이스에서 테이블을 가져오고 각 테이블에서 행을 가져온다고 가정합니다. 처리해야 하는 행의 수에 따라 여러 연결 및 여러 For each 루프를 사용하여 총 행 수를 더 작은 집합으로 나누어 처리할 수 있습니다. 이 시나리오에서는 For each 루프 2개를 사용하여 총 행 수를 절반으로 분할합니다. 첫 번째 For each 루프는 첫 절반을 받는 식을 사용합니다. 다른 For each 루프는 두 번째 절반을 얻는 다른 식을 사용합니다. 예를 들면 다음과 같습니다.
식 1:
take()함수는 컬렉션의 전면을 가져옵니다. 자세한 정보는take()함수를 참조하세요.@take(collection-or-array-name, div(length(collection-or-array-name), 2))식 2:
skip()함수는 컬렉션의 전면을 제거하고 다른 기타 항목을 반환합니다. 자세한 정보는skip()함수를 참조하세요.@skip(collection-or-array-name, div(length(collection-or-array-name), 2))다음 소비 워크플로 예제에서는 이러한 식을 사용하는 방법을 보여 줍니다.
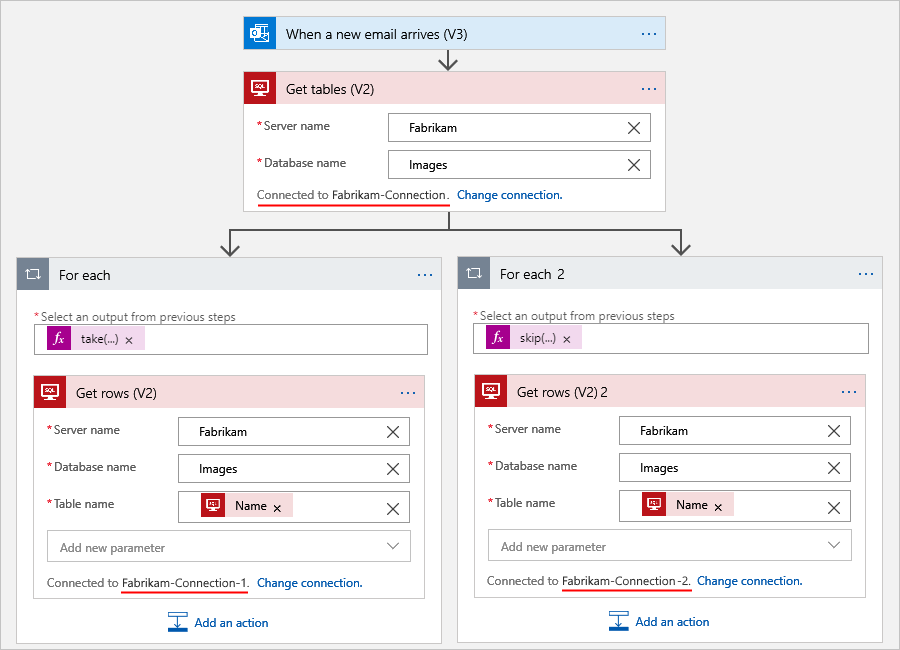
각 작업에 대해 다른 연결을 설정합니다.
작업이 동일한 서비스 또는 시스템에 연결되고 동일한 자격 증명을 사용하는 경우에도 각 작업의 요청을 자체 연결을 통해 분배하여 워크로드를 분산할 수 있는지 여부를 고려합니다.
예를 들어 워크플로가 SQL Server 데이터베이스에서 테이블을 가져오고 각 테이블의 각 행을 가져온다고 가정합니다. 테이블 받기에서 하나의 연결을 사용하면서 각 행 받기에 다른 연결을 사용하도록 별도의 연결을 사용할 수 있습니다.
다음 예제에서는 각 작업에 대해 다른 연결을 만들고 사용하는 소비 워크플로를 보여 줍니다.
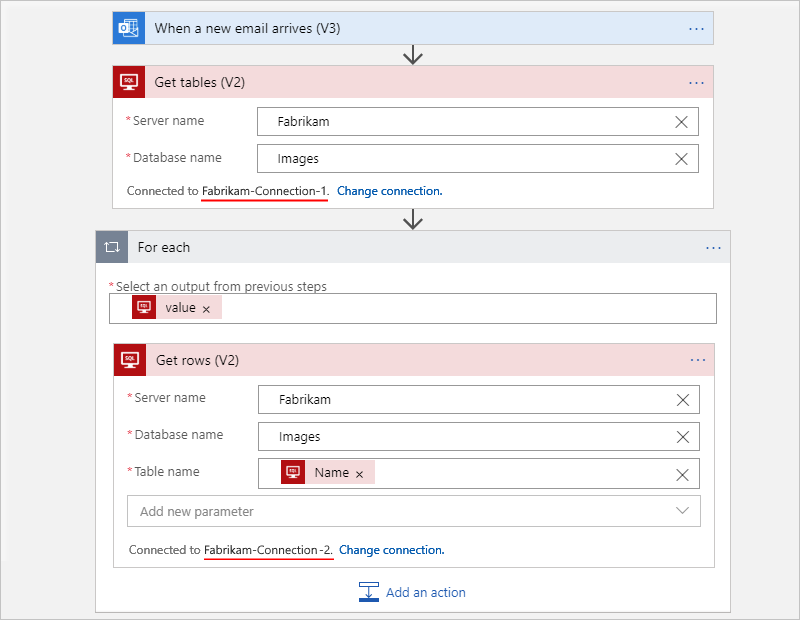
"For each" 루프에서 동시성 또는 병렬을 변경합니다.
기본값으로 "for each" 루프 반복은 동시에 또는 최대 기본 제한까지 실행됩니다. "For each" 루프 내에서 제한되는 커넥터가 있는 경우 병렬로 실행 되는 루프 반복 횟수를 줄일 수 있습니다. 자세한 내용은 다음 설명서를 참조하세요.
대상 서비스 또는 시스템 제한
커넥터에는 자체 제한 한도가 있으며, 커넥터에 의해 호출되는 대상 서비스 또는 시스템에도 제한 제한이 있을 수 있습니다. 예를 들어 Microsoft Exchange Server의 일부 API는 Office 365 Outlook 커넥터에 비해 제한 한도가 더 엄격합니다.
기본값으로 논리 앱 워크플로의 인스턴스 및 해당 인스턴스 내의 루프 또는 분기는 병렬로 실행됩니다. 이 동작은 여러 인스턴스가 동시에 동일한 엔드포인트를 호출할 수 있음을 의미합니다. 각 인스턴스는 기타 인스턴스의 존재를 알지 못합니다. 따라서 실패 한 작업을 재시도하면 여러 호출이 동시에 실행하려고 시도하는 경합 상태를 만들 수 있지만, 성공적으로 실행하려면 제한이 시작되기 전에 대상 서비스 또는 시스템에 해당 호출이 도착해야 합니다.
예를 들어 100개의 항목이 있는 배열이 있다고 가정합니다. "For each" 루프를 사용하여 배열을 반복하고 루프의 동시성 컨트롤을 활성화하여 병렬 반복 수를 20회 또는 현재 기본 제한으로 제한할 수 있습니다. 이 루프 내에서 작업은 배열의 항목을 SQL Server 데이터베이스에 삽입하여 초당 15회의 호출만 허용합니다. 이 시나리오에서는 재시도의 백로그가 작성되고 실행되지 않기 때문에 제한 문제가 발생합니다.
다음 표에서는 작업의 다시 시도 간격이 1초인 경우 루프에서 수행 되는 작업에 대한 타임 라인을 설명합니다.
| 지정 시간 | 실행되는 작업 수 | 실패한 작업 수 | 대기 중인 재시도 수 |
|---|---|---|---|
| T + 0초 | 20회 삽입 | SQL 제한으로 인해 5회 실패 | 5회 재시도 |
| T + 0.5초 | 이전 5회 재시도 대기로 인해 15회 삽입 | 0.5초 동안 이전 SQL 제한이 다시 적용되면서 15회 모두 실패 | 20회 재시도 (이전 5회 + 신규 15회) |
| T + 1초 | 20회 삽입 | SQL 제한으로 인해 5회 실패 및 이전 20회 재시도 | 25회 재시도(이전 20회 + 신규 5회) |
이 수준에서 제한을 처리하기 위해 다음 옵션을 사용할 수 있습니다.
각각이 단일 작업을 처리할 수 있도록 개별 워크플로를 만듭니다.
이 섹션의 예제 SQL Server 시나리오를 계속 진행하면서 배열 항목을 큐에 넣는 Azure Service Bus 큐와 같은 워크플로를 만들 수 있습니다. 그런 다음, 해당 큐의 각 항목에 대해 삽입 작업만 수행하는 다른 워크플로를 만듭니다. 이렇게 하면 특정 시간에 하나의 워크플로 인스턴스만 실행되어 삽입 작업을 완료하고 큐의 다음 항목으로 이동하거나 인스턴스에서 429 오류가 발생합니다. 그러나 비생산적인 재시도를 시도하지 않습니다.
각 작업에 대해 자식 또는 중첩 워크플로를 호출하는 부모 워크플로를 만듭니다. 상위가 상위의 결과에 따라 다른 하위 워크플로를 호출해야 하는 경우 호출할 하위 워크플로를 결정하는 조건 작업 또는 전환 작업을 사용할 수 있습니다. 이 패턴은 호출 또는 작업의 수를 줄이는 데 도움이 될 수 있습니다.
예를 들어 각각 "성공" 또는 "실패"와 같은 특정 주제에 대해 1분마다 메일 계정을 확인하는 폴링 트리거가 있는 두 개의 워크플로가 있다고 가정합니다. 이 설정은 시간당 120회의 호출을 생성합니다. 대신, 1분마다 폴링하지만 주체가 "성공" 또는 "실패" 인지 여부를 기반으로 실행되는 하위 워크플로를 호출하는 단일 상위 워크플로를 만드는 경우, 폴링 검사 수를 절반, 이 경우에는 60회로 줄입니다.
일괄 처리를 설정합니다. (소비 워크플로만 해당)
대상 서비스에서 일괄 처리 작업을 지원하는 경우, 개별이 아닌 그룹 또는 일괄 처리로 항목을 처리하여 제한을 처리할 수 있습니다. 일괄 처리 솔루션을 구현하려면 "일괄 처리 수신자" 논리 앱 워크플로와 "일괄 처리 발신자" 논리 앱 워크플로를 만듭니다. 일괄 처리 발신자는 지정한 조건이 충족될 때까지 메시지나 항목을 수집한 후 해당 메시지 또는 항목을 단일 그룹으로 보냅니다. 일괄 처리 수신자는 해당 그룹을 수락하고 해당 메시지 또는 항목을 처리합니다. 자세한 정보는 그룹의 배치 프로세스 메시지를 참조하세요.
폴링 버전이 아닌 트리거 및 작업에 대한 웹후크 버전을 사용합니다.
이유는 무엇입니까? 폴링 트리거는 특정 간격으로 대상 서비스 또는 시스템을 계속 검사합니다. 1초 간격으로 매우 자주 수행되는 경우에는 제한 문제가 발생할 수 있습니다. 그러나 웹후크 트리거 또는 HTTP webhook과 같은 작업은 대상 서비스 또는 시스템에 대한 단일 호출만 만들며, 이는 구독 시에 발생하고 이벤트가 발생하는 경우에만 대상에서 트리거 또는 작업을 요청합니다. 이렇게 하면 트리거 또는 작업에서 대상을 지속적으로 확인할 필요가 없습니다.
따라서 대상 서비스 또는 시스템이 웹후크를 지원하거나 웹후크 버전이 있는 커넥터를 제공하는 경우 이 옵션이 폴링 버전을 사용 하는 것보다 좋습니다. 웹후크 트리거 및 작업을 식별 하려면
ApiConnectionWebhook형식이 있거나 되풀이를 지정하지 않아도 되는지 확인합니다. 자세한 정보는 APIConnectionWebhook trigger 및 APIConnectionWebhook action항목을 참조하세요.