Python 모델 구성 요소 만들기
이 문서에서는 Azure Machine Learning 디자이너의 구성 요소에 대해 설명합니다.
Python 모델 만들기 구성 요소를 사용하여 Python 스크립트에서 학습되지 않은 모델을 만드는 방법을 알아봅니다. Azure Machine Learning 디자이너 환경의 Python 패키지에 포함된 모든 학습자를 모델의 기반으로 사용할 수 있습니다.
모델을 만든 후에는 모델 학습을 사용하여 Azure Machine Learning의 다른 학습자처럼 데이터 세트에서 모델을 학습할 수 있습니다. 학습된 모델을 모델 점수 매기기에 전달하여 예측에 사용할 수 있습니다. 그런 다음, 학습된 모델을 저장하고 점수 매기기 워크플로를 웹 서비스로 게시할 수 있습니다.
경고
현재 이 구성 요소를 모델 하이퍼 매개 변수 튜닝 구성 요소에 연결하거나 Python 모델의 점수가 매겨진 결과를 모델 평가에 전달할 수는 없습니다. 하이퍼 매개 변수를 튜닝하거나 모델을 평가해야 하는 경우 Python 스크립트 실행 구성 요소를 사용하여 사용자 지정 Python 스크립트를 작성할 수 있습니다.
구성 요소 구성
이 구성 요소를 사용하려면 Python에 대한 중급 또는 전문 지식이 있어야 합니다. 구성 요소는 Azure Machine Learning에서 이미 설치된 Python 패키지에 포함된 모든 학습자의 사용을 지원합니다. Python 스크립트 실행에서 사전 설치된 Python 패키지 목록을 참조하세요.
참고
스크립트를 작성할 때는 매우 주의해야 하며 선언되지 않은 개체나 가져오지 않은 구성 요소 사용과 같은 구문 오류가 없는지 확인하세요.
참고
또한 Python 스크립트 실행의 사전 설치된 구성 요소 목록에 특히 주의합니다. 사전 설치된 구성 요소만 가져옵니다. 이 스크립트에 "pip install xgboost"와 같은 추가 패키지를 설치하지 마십시오. 그렇지 않으면 다운스트림 구성 요소에서 모델을 읽을 때 오류가 발생합니다.
이 문서에서는 간단한 파이프라인에서 Python 모델 만들기를 사용하는 방법을 보여 줍니다. 다음은 파이프라인 다이어그램입니다.
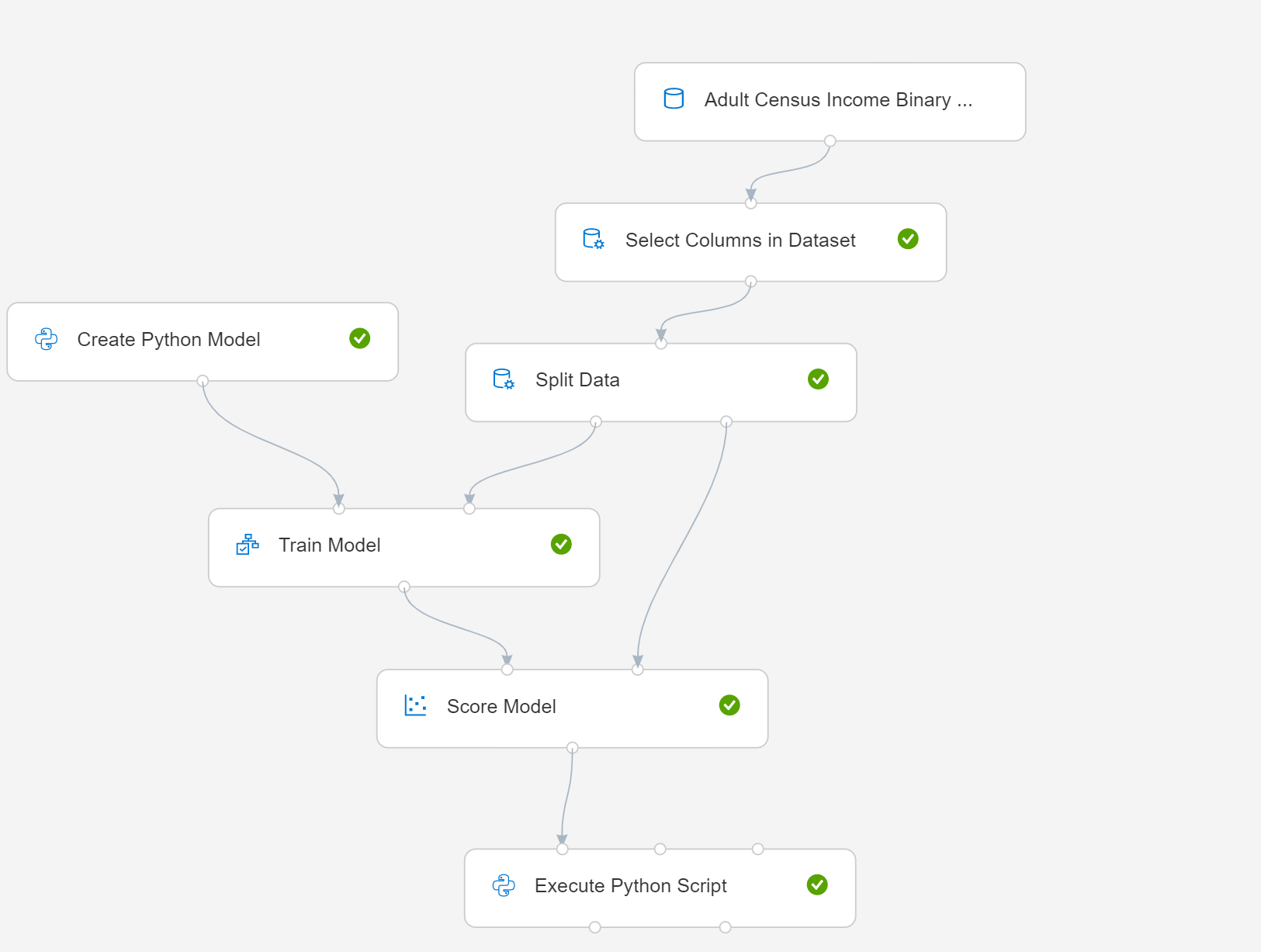
- Python 모델 만들기를 선택하고 스크립트를 편집하여 모델링 또는 데이터 관리 프로세스를 구현합니다. Azure Machine Learning 환경의 Python 패키지에 포함된 모든 학습자를 모델의 기반으로 사용할 수 있습니다.
참고
스크립트 샘플 코드의 주석에 특히 주의하고 스크립트가 클래스 이름, 메서드, 메서드 서명을 비롯한 요구 사항을 엄격하게 준수하는지 확인하세요. 요구 사항을 위반할 시 예외가 발생합니다. Python 모델 만들기는 모델 학습을 사용하여 학습할 sklearn 기반 모델 만들기만 지원합니다.
2클래스 Naive Bayes 분류자의 다음 샘플 코드는 인기 있는 sklearn 패키지를 사용합니다.
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
방금 만든 Python 모델 만들기 구성 요소를 모델 학습 및 모델 점수 매기기에 연결합니다.
모델을 평가해야 하는 경우 Python 스크립트 실행 구성 요소를 추가하고 Python 스크립트를 편집합니다.
다음 스크립트는 샘플 평가 코드입니다.
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.