PyTorch 모델 학습
이 문서에서는 Azure Machine Learning 디자이너에서 PyTorch 모델 학습 구성 요소를 사용하여 DenseNet과 같은 PyTorch 모델을 학습시키는 방법을 설명합니다. 모델을 정의하고 매개 변수를 설정한 후에 학습이 수행되며, 학습을 위해서는 레이블이 지정된 데이터가 필요합니다.
현재 PyTorch 모델 학습 구성 요소는 단일 노드 및 분산 학습을 모두 지원합니다.
PyTorch 모델 학습 사용 방법
파이프라인에 PyTorch 모델 학습 구성 요소를 추가합니다. 이 구성 요소는 모델 학습 범주에서 찾을 수 있습니다. 학습을 확장하고 PyTorch 모델 학습 구성 요소를 파이프라인으로 끌어서 놓습니다.
참고
대규모 데이터 세트를 사용하는 경우 PyTorch 모델 학습 구성 요소는 GPU 유형 컴퓨팅에서 더 잘 실행되며, 그렇지 않으면 파이프라인이 실패합니다. 구성 요소의 오른쪽 창에서 다른 컴퓨팅 대상 사용을 설정하여 특정 구성 요소에 대한 컴퓨팅을 선택할 수 있습니다.
왼쪽 입력에서 학습되지 않은 모델을 연결합니다. 학습 데이터 세트 및 유효성 검사 데이터 세트를 PyTorch 모델 학습의 가운데 및 오른쪽 입력에 연결합니다.
학습되지 않은 모델의 경우 DenseNet과 같은 PyTorch 모델이어야 합니다. 그렇지 않으면 'InvalidModelDirectoryError'가 발생합니다.
학습 데이터 세트는 레이블이 지정된 이미지 디렉터리여야 합니다. 레이블이 지정된 이미지 디렉터리를 가져오는 방법은 이미지 디렉터리로 변환을 참조하세요. 레이블이 지정되지 않은 경우 'NotLabeledDatasetError'가 발생합니다.
학습 데이터 세트와 유효성 검사 데이터 세트의 레이블 범주가 동일해야 합니다. 그렇지 않으면 InvalidDatasetError가 발생합니다.
Epoch에 학습시킬 Epoch 수를 지정합니다. 각 Epoch에서 전체 데이터 세트가 반복되며, 기본값은 5입니다.
배치 크기에 배치로 학습시킬 인스턴스 수를 지정합니다(기본값 16).
준비 단계 수에 초기 학습 속도가 수렴을 시작하기에 다소 큰 경우 학습을 준비하려는 Epoch 수를 지정합니다(기본값 0).
학습 속도에 학습 속도 값을 지정합니다(기본값: 0.001). 학습 속도는 모델을 테스트하고 수정할 때마다 sgd와 같은 최적화 프로그램에서 사용되는 단계의 크기를 제어합니다.
속도를 더 낮게 설정하면 모델을 더 자주 테스트할 수 있지만 로컬 정체 상태에 고착될 위험이 있습니다. 속도를 더 높게 설정하면 더 빨리 수렴할 수 있지만 실제 최솟값이 과도해질 위험이 있습니다.
참고
학습 중에 학습 속도가 너무 높아서 학습 손실이 nan이 될 경우 학습 속도를 낮추는 것이 도움이 될 수 있습니다. 분산 학습에서 그라데이션 하강을 안정적으로 유지하기 위해 실제 학습 속도는
lr * torch.distributed.get_world_size()로 계산됩니다. 프로세스 그룹의 일괄 처리 크기는 월드 크기에 단일 프로세스의 크기를 곱한 값이기 때문입니다. 다항식 학습 속도 감소가 적용되며 더 나은 성능의 모델을 만드는 데 도움이 될 수 있습니다.필요한 경우 임의 시드에 시드로 사용할 정수 값을 입력합니다. 각 작업 간에 실험 재현성을 보장하려면 시드를 사용하는 것이 좋습니다.
유효성 검사 손실이 연속적으로 감소하지 않는다면 페이션스에 학습을 조기 중지할 Epoch 수를 지정합니다. 기본값은 3입니다.
인쇄 빈도에 각 Epoch에서 반복할 때의 학습 로그 인쇄 빈도를 지정합니다(기본값 10).
파이프라인을 제출합니다. 데이터 세트의 크기가 더 큰 경우 시간이 걸리므로 GPU 컴퓨팅을 사용하는 것이 좋습니다.
분산 학습
분산 학습에서 모델 학습을 위한 워크로드는 작업자 노드라고 하는 여러 미니 프로세서 사이에 분할되고 공유됩니다. 작업자 노드는 동시에 작동하여 모델 학습 속도를 향상합니다. 현재 디자이너는 PyTorch 모델 학습 구성 요소에 분산 학습을 지원합니다.
학습 시간
PyTorch 모델 학습에서 분산 학습을 수행하면 몇 시간 만에 ImageNet(1,000개 클래스, 120만개 이미지) 등 대규모 데이터 세트를 학습시킬 수 있습니다. 다음 표는 다양한 디바이스에서 ImageNet에 대해 Resnet50을 처음부터 50 Epoch 학습시킬 때의 학습 시간과 성능을 보여줍니다.
| 디바이스 | 학습 시간 | 학습 처리량 | 상위 1개 유효성 검사 정확도 | 상위 5개 유효성 검사 정확도 |
|---|---|---|---|---|
| V100 GPU 16개 | 6시간 22분 | ~3,200개 이미지/초 | 68.83% | 88.84% |
| V100 GPU 8개 | 12시간 21분 | ~1,670개 이미지/초 | 68.84% | 88.74% |
이 구성 요소의 ‘메트릭’ 탭을 클릭하고 ‘초당 학습 이미지 수’ 및 ‘상위 1개 정확도’와 같은 학습 메트릭 그래프를 확인합니다.

분산 학습을 사용하도록 설정하는 방법
PyTorch 모델 학습 구성 요소에 분산 학습을 사용하도록 설정하려면 구성 요소의 오른쪽 창에 있는 작업 설정에서 구성하면 됩니다. 분산 학습에는 AML 컴퓨팅 클러스터 만 지원됩니다.
참고
NCCL 백 엔드 PyTorch 모델 학습 구성 요소 사용 시에는 cuda가 필요하기 때문에 분산 학습을 활성화하려면 다중 GPU가 필요합니다.
구성 요소를 선택하고 오른쪽 패널을 엽니다. 작업 설정 섹션을 확장합니다.
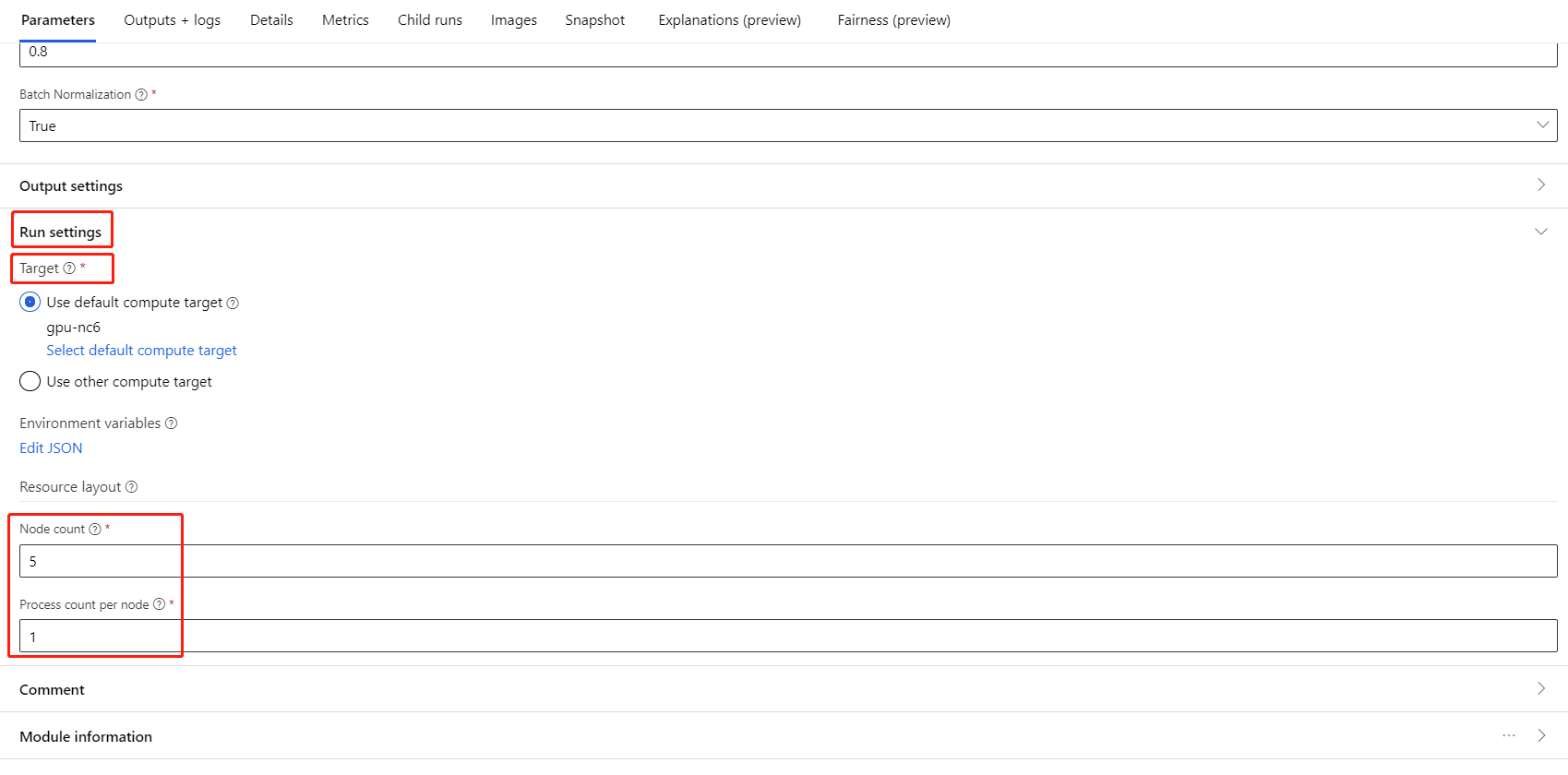
컴퓨팅 대상으로 AML 컴퓨팅을 선택했는지 확인합니다.
리소스 레이아웃 섹션에서 다음 값을 설정해야 합니다.
노드 수: 학습에 사용할 컴퓨팅 대상의 노드 수입니다. 컴퓨팅 클러스터의 최대 노드 수보다 적거나 같아야 합니다. 기본값은 1개로, 단일 노드 작업을 의미합니다.
노드당 프로세스 수: 노드당 트리거되는 프로세스의 수입니다. 컴퓨팅의 처리 단위보다 적거나 같아야 합니다. 기본값은 1개로, 이는 단일 프로세스 작업을 의미합니다.
컴퓨팅 세부 정보 페이지에서 컴퓨팅 이름을 클릭하여 컴퓨팅의 최대 노드 수와 처리 단위를 확인할 수 있습니다.



Azure Machine Learning에서의 분산 학습에 대한 자세한 내용은 여기서 알아볼 수 있습니다.
분산 학습 문제 해결
이 구성 요소에 대해 분산 학습을 사용하도록 설정하면 프로세스별로 드라이버 로그가 생성됩니다. 70_driver_log_0은 마스터 프로세스용입니다. 오른쪽 창의 출력+로그 탭에서 각 프로세스의 오류 세부 정보에 대한 드라이버 로그를 확인할 수 있습니다.

70_driver 로그 없이 구성 요소 사용 분산 학습이 실패하면 70_mpi_log에서 오류 세부 정보를 확인할 수 있습니다.
다음 예제에서는 노드당 프로세스 수가 컴퓨팅의 처리 단위보다 큰 일반적인 오류를 보여줍니다.

구성 요소 문제 해결에 대한 자세한 내용은 이 문서를 참조하세요.
결과
파이프라인 작업이 완료된 후 채점에 모델을 사용하려면 PyTorch 모델 학습을 이미지 모델 채점에 연결하여 새 입력 예제의 값을 예측합니다.
기술 정보
예상 입력
| Name | 형식 | Description |
|---|---|---|
| 학습되지 않은 모델 | UntrainedModelDirectory | 학습되지 않은 모델, PyTorch 필요 |
| 학습 데이터 세트 | ImageDirectory | 학습 데이터 세트 |
| 유효성 검사 데이터 세트 | ImageDirectory | 각 Epoch의 평가를 위한 유효성 검사 데이터 세트 |
구성 요소 매개 변수
| Name | 범위 | Type | 기본값 | Description |
|---|---|---|---|---|
| Epoch | >0 | 정수 | 5 | 레이블 또는 결과 열이 포함된 열을 선택합니다. |
| Batch 크기 | >0 | 정수 | 16 | 일괄 학습할 인스턴스 수 |
| 준비 단계 수 | >=0 | 정수 | 0 | 학습을 준비할 Epoch 수 |
| 학습 속도 | >=double.Epsilon | Float | 0.1 | 추측 기울기 하강 최적화 프로그램의 초기 학습 속도입니다. |
| 무작위 초기값 | 모두 | 정수 | 1 | 모델에서 사용하는 난수 생성기의 초기값입니다. |
| 페이션스 | >0 | 정수 | 3 | 학습을 조기에 중지할 Epoch 수 |
| 인쇄 빈도 | >0 | 정수 | 10 | 각 Epoch에서 반복할 때의 학습 로그 인쇄 빈도 |
출력
| Name | 형식 | Description |
|---|---|---|
| 학습된 모델 | ModelDirectory | 학습된 모델 |
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.