자동화된 ML 모델에 대한 학습 코드 보기
이 문서에서는 자동화된 Machine Learning 학습 모델에서 생성된 학습 코드를 보는 방법을 알아봅니다.
자동화된 ML 학습된 모델에 대한 코드 생성을 사용하면 자동화된 ML이 특정 실행에 대한 모델을 학습시키고 빌드하는 데 사용하는 다음 세부 정보를 볼 수 있습니다.
- 데이터 전처리
- 알고리즘 선택
- 기능 개발
- 하이퍼 매개 변수
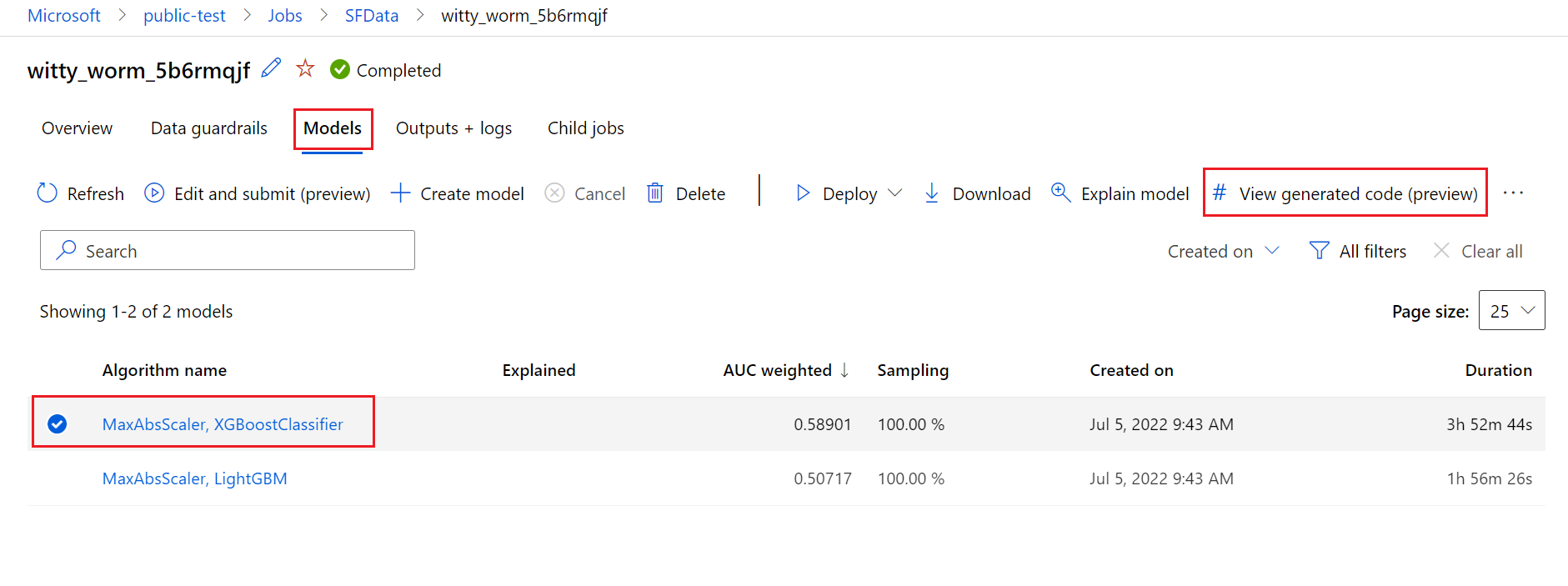
자동화된 ML 학습된 모델, 권장 또는 자식 실행을 선택하고 해당 모델을 만든 생성된 Python 학습 코드를 볼 수 있습니다.
생성된 모델의 학습 코드를 사용하여 다음을 수행할 수 있습니다.
- 모델 알고리즘에서 사용하는 기능화 프로세스 및 하이퍼 매개 변수에 대해 알아봅니다.
- 학습된 모델을 추적/버전 관리/감사합니다. 버전이 지정된 코드를 저장하여 프로덕션에 배포할 모델에서 사용되는 특정 학습 코드를 추적합니다.
- 하이퍼 매개 변수를 변경하거나 ML 및 알고리즘 기술/환경을 적용하여 학습 코드를 사용자 지정하고, 사용자 지정한 코드로 새 모델을 다시 학습시킵니다.
다음 다이어그램에서는 모든 작업 유형을 사용하여 자동화된 ML 실험에 대한 코드를 생성할 수 있음을 보여 줍니다. 먼저 모델을 선택합니다. 선택한 모델이 강조 표시되면 Azure Machine Learning에서 모델을 만드는 데 사용된 코드 파일을 복사하여 Notebooks 공유 폴더에 표시합니다. 여기서 코드를 살펴보고 필요한 대로 사용자 지정할 수 있습니다.
필수 조건
Azure Machine Learning 작업 영역 작업 영역을 만들려면 작업 영역 리소스 만들기를 참조하세요.
이 문서에서는 자동화된 Machine Learning 실험 설정에 어느 정도 익숙한 것으로 가정합니다. 자습서 또는 방법에 따라 기본적인 자동화된 Machine Learning 실험 디자인 패턴을 확인합니다.
자동화된 ML 코드 생성은 원격 Azure Machine Learning 컴퓨팅 대상에서 실행되는 실험에만 사용할 수 있습니다. 로컬 실행에는 코드 생성이 지원되지 않습니다.
Azure Machine Learning Studio, SDKv2 또는 CLIv2를 통해 트리거되는 모든 자동화된 ML 실행에는 코드 생성이 사용하도록 설정됩니다.
생성된 코드 및 모델 아티팩트 가져오기
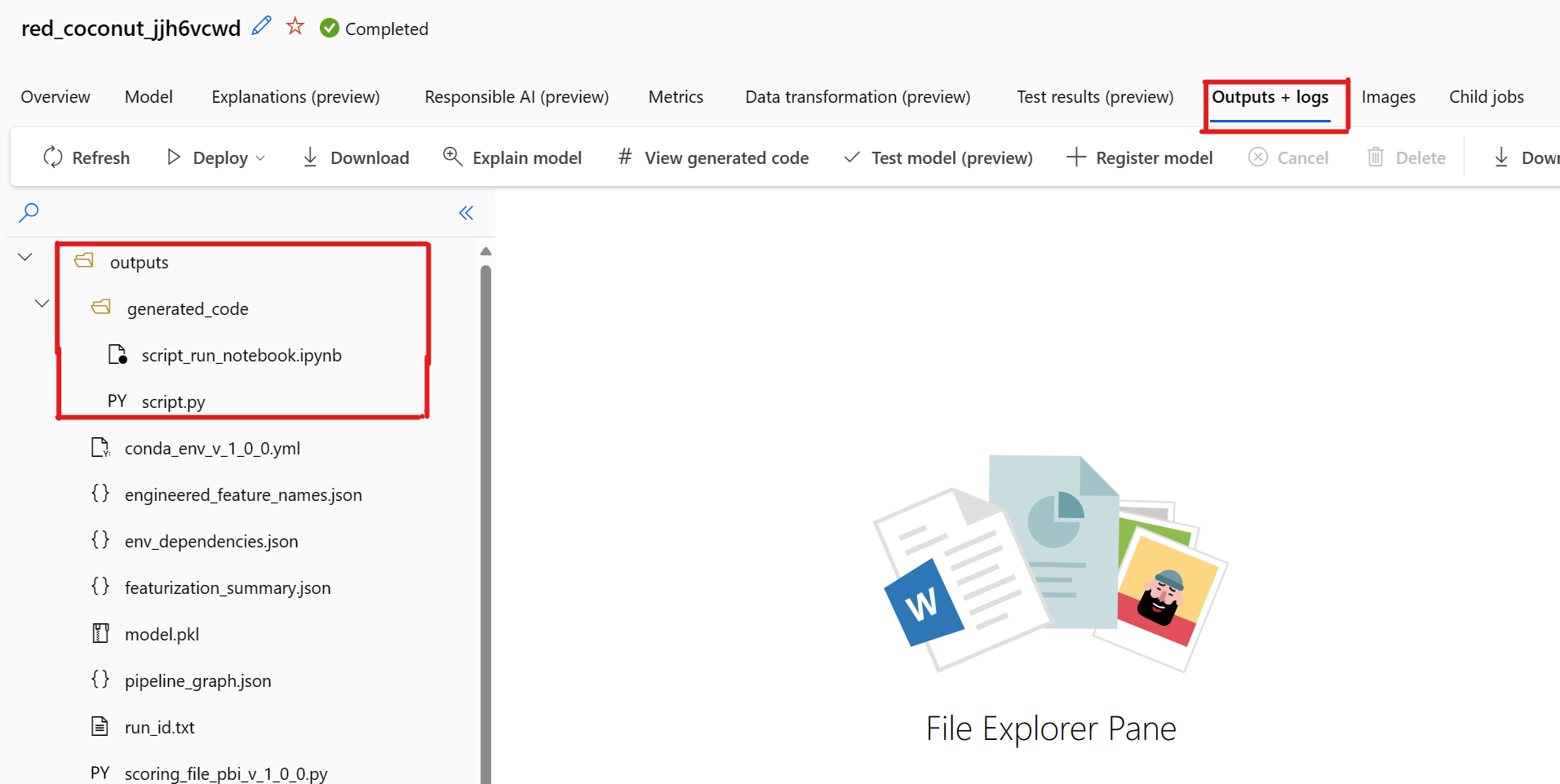
기본적으로 각각의 자동화된 ML 학습된 모델은 학습이 완료된 후 학습 코드를 생성합니다. 자동화된 ML은 이 코드를 해당 모델에 대한 실험의 outputs/generated_code에 저장합니다. 선택한 모델의 출력 + 로그 탭에 있는 Azure Machine Learning 스튜디오 UI에서 볼 수 있습니다.
script.py 기능화 단계, 사용된 특정 알고리즘 및 하이퍼 매개 변수를 사용하여 분석할 가능성이 높은 모델의 학습 코드입니다.
script_run_notebook.ipynb Azure Machine Learning 컴퓨팅에서 Azure Machine Learning SDKv2를 통해 모델의 학습 코드(script.py)를 실행하는 보일러 플레이트 코드가 있는 Notebook
자동화된 ML 학습 실행이 완료되면 Azure Machine Learning 스튜디오 UI를 통해 script.py 및 script_run_notebook.ipynb 파일에 액세스할 수 있습니다.
이렇게 하려면 자동화된 ML 실험 부모 실행 페이지의 모델 탭으로 이동합니다. 학습된 모델 중 하나를 선택한 후 생성된 코드 보기 단추를 선택할 수 있습니다. 이 단추를 선택하면 선택한 모델에 대해 생성된 코드를 살펴보고 편집하고 실행할 수 있는 Notebooks 포털 확장으로 리디렉션됩니다.
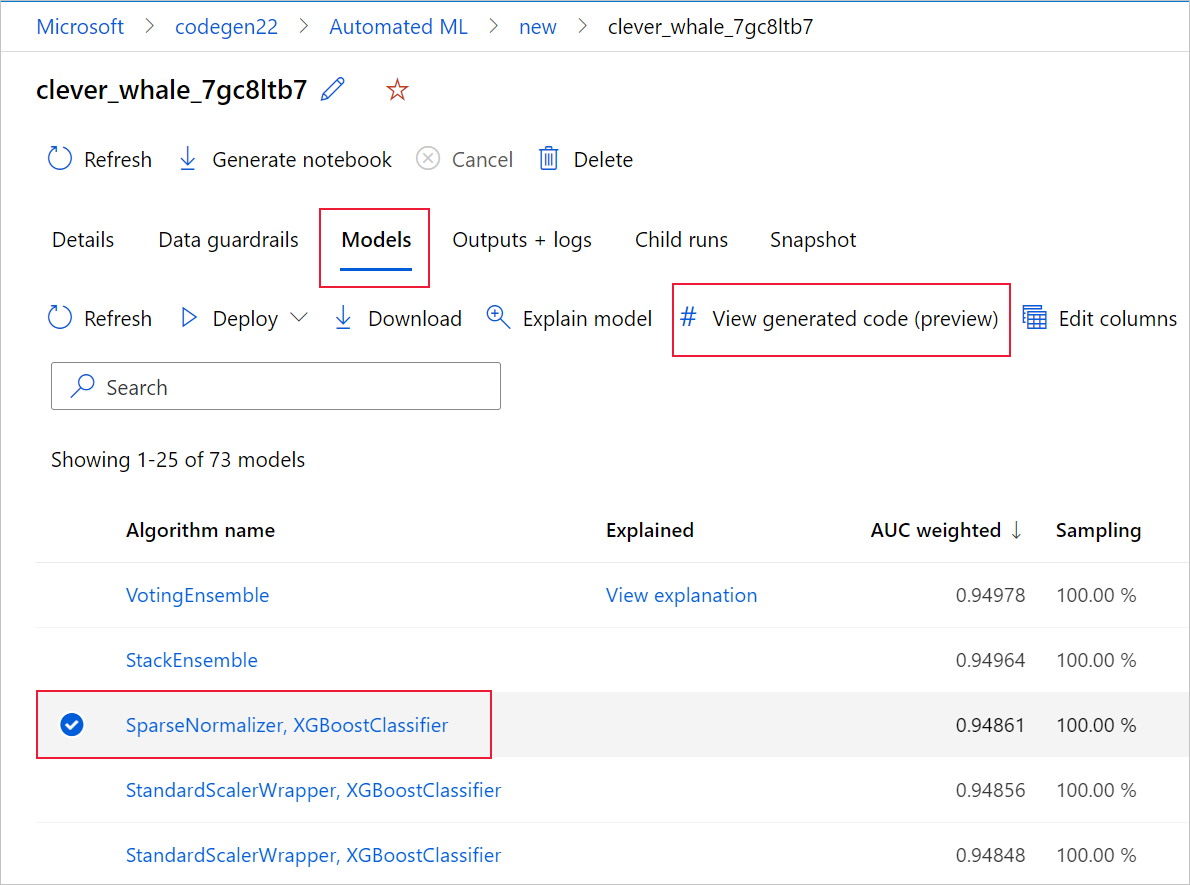
특정 모델의 자식 실행 페이지로 이동한 후에는 자식 실행 페이지의 맨 위에서 모델에 대해 생성된 코드에 액세스할 수도 있습니다.

Python SDKv2를 사용하는 경우 MLFlow 및 결과 아티팩트 다운로드를 통해 최상의 실행을 검색하여 "script.py" 및 "script_run_notebook.ipynb"를 다운로드할 수도 있습니다.
제한 사항
생성된 코드 보기를 선택할 때 알려진 문제가 있습니다. 스토리지가 VNet 뒤에 있는 경우 이 작업은 Notebooks 포털로 리디렉션되지 않습니다. 해결 방법으로 사용자는 출력 outputs>generated_code 폴더 아래의 출력 + 로그 탭으로 이동하여 script.py 및 script_run_notebook.ipynb 파일을 수동으로 다운로드할 수 있습니다. 이러한 파일을 Notebooks 폴더에 수동으로 업로드하여 실행하거나 편집할 수 있습니다. 이 링크를 따라 Azure Machine Learning의 VNet에 대해 자세히 알아보세요.
script.py
script.py 파일에는 이전에 사용한 하이퍼 매개 변수를 사용하여 모델을 학습시키는 데 필요한 핵심 논리가 포함되어 있습니다. Azure Machine Learning 스크립트 실행의 컨텍스트에서 실행되도록 제작되었지만 약간만 수정하면 모델의 학습 코드를 자체 온-프레미스 환경에서 독립 실행형으로 실행할 수도 있습니다.
스크립트는 크게 데이터 로드, 데이터 준비, 데이터 기능화, 전처리기/알고리즘 사양 및 학습과 같은 여러 부분으로 나눌 수 있습니다.
데이터 로드
get_training_dataset() 함수는 이전에 사용된 데이터 세트를 로드합니다. 이 함수는 스크립트가 원래 실험과 동일한 작업 영역에서 실행되는 Azure Machine Learning 스크립트에서 실행된다고 가정합니다.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Run.get_context().experiment.workspace는 스크립트 실행의 일부로 실행할 경우 올바른 작업 영역을 검색합니다. 그러나 이 스크립트가 다른 작업 영역 내에서 실행되거나 로컬로 실행되는 경우 스크립트를 수정하여 적절한 작업 영역을 명시적으로 지정해야 합니다.
작업 영역이 검색되면 원래 데이터 세트가 ID로 검색됩니다. 정확히 동일한 구조를 가진 다른 데이터 세트는 각각 get_by_id() 또는 get_by_name()을 사용하여 ID 또는 이름으로 지정할 수도 있습니다. 나중에 다음 코드와 유사한 스크립트 섹션에서 ID를 찾을 수 있습니다.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
이 전체 함수를 사용자 고유의 데이터 로딩 메커니즘으로 바꾸도록 선택할 수도 있습니다. 유일한 제약 조건은 반환 값이 Pandas 데이터 프레임이어야 하고 데이터의 모양이 원래 실험과 동일해야 한다는 것입니다.
데이터 준비 코드
prepare_data() 함수는 데이터를 정리하고, 기능 및 샘플 가중치 열을 분할하고, 학습에 사용할 데이터를 준비합니다.
이 함수는 데이터 세트의 유형과 실험 작업 유형(분류, 회귀, 시계열 예측, 이미지 또는 NLP 작업)에 따라 달라질 수 있습니다.
다음 예제에서는 일반적으로 데이터 로드 단계의 데이터 프레임이 전달되는 것을 보여줍니다. (원래 지정된 경우) 레이블 열 및 샘플 가중치가 추출되고, NaN을 포함하고 있는 행이 입력 데이터에서 삭제됩니다.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
더 많은 데이터 준비를 수행하려는 경우 이 단계에서 사용자 지정 데이터 준비 코드를 추가하면 됩니다.
데이터 기능화 코드
generate_data_transformation_config() 함수는 최종 scikit-learn 파이프라인의 기능화 단계를 지정합니다. 원래 실험의 기능 변환기는 매개 변수와 함께 여기서 재현됩니다.
예를 들어 이 함수에서 발생할 수 있는 데이터 변환은 SimpleImputer() 및 CatImputer()와 같은 imputers 또는 StringCastTransformer() 및 LabelEncoderTransformer()와 같은 변환기를 기반으로 할 수 있습니다.
다음은 열 세트를 변환하는 데 사용할 수 있는 StringCastTransformer() 형식의 변환기입니다. 이 예에서는 세트가 column_names로 표시되었습니다.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
여러 열에 동일한 기능화/변환을 적용해야 하는 경우(예: 여러 열 그룹의 열 50개) 이러한 열은 형식에 따라 그룹화하여 처리됩니다.
다음 예제에서는 각 그룹에 고유한 매퍼가 적용되었습니다. 그런 다음, 이 매퍼가 해당 그룹의 각 열에 적용됩니다.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
이 방법을 사용하면 데이터 세트에 수십 또는 수백 개의 열이 있을 때에도 번거로울 수 있는 각 열에 대한 변환기의 코드 블록이 없으므로 코드가 간소화됩니다.
분류 및 회귀 작업을 사용하면 [FeatureUnion]이 기능 변환기에 사용됩니다.
시계열 예측 모델의 경우 여러 시계열 인식 기능화기가 scikit-learn 파이프라인으로 수집된 다음, TimeSeriesTransformer에 래핑됩니다.
사용자가 시계열 예측 모델에 제공한 기능화는 자동화된 ML이 제공한 모델보다 먼저 발생합니다.
전처리기 사양 코드
generate_preprocessor_config() 함수(있는 경우)는 최종 scikit-learn 파이프라인의 기능화 후에 수행할 전처리 단계를 지정합니다.
일반적으로 이 전처리 단계는 sklearn.preprocessing을 통해 수행된 데이터 표준화/정규화로만 구성됩니다.
자동화된 ML은 비 앙상블 분류 및 회귀 모델에 대한 전처리 단계만 지정합니다.
다음은 생성된 전처리기 코드의 예입니다.
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
알고리즘 및 하이퍼 매개 변수 사양 코드
여러 ML 전문가들이 알고리즘 및 하이퍼 매개 변수 사양 코드에 가장 많은 관심을 보이고 있습니다.
generate_algorithm_config() 함수는 최종 scikit-learn 파이프라인의 마지막 단계로 모델 학습을 위한 실제 알고리즘 및 하이퍼 매개 변수를 지정합니다.
다음 예제에서는 XGBoostClassifier 알고리즘과 특정 하이퍼 매개 변수를 사용합니다.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
생성된 코드는 대부분 OSS(오픈 소스 소프트웨어) 패키지 및 클래스를 사용합니다. 더 복잡한 코드를 단순화하기 위해 중간 래퍼 클래스를 사용하는 경우가 있습니다. 예를 들어 XGBoost 분류자 그리고 LightGBM 또는 Scikit-Learn 알고리즘과 같이 일반적으로 사용되는 기타 라이브러리를 적용할 수 있습니다.
ML 전문가는 해당 알고리즘에 대한 기술과 경험 수준 그리고 직면한 ML 문제에 따라 하이퍼 매개 변수를 필요한 대로 조정하여 해당 알고리즘의 구성 코드를 사용자 지정할 수 있습니다.
앙상블 모델의 경우 generate_preprocessor_config_N()(필요한 경우) 및 generate_algorithm_config_N()이 앙상블 모델의 각 학습자에 대해 정의되며, N은 앙상블 모델 목록에서 각 학습자의 배치를 나타냅니다. 스택 앙상블 모델의 경우 메타 학습자 generate_algorithm_config_meta()가 정의됩니다.
엔드투엔드 학습 코드
코드 생성 시 build_model_pipeline() 및 train_model()을 내보내며, 각각 scikit-learn 파이프라인을 정의하고 파이프라인에서 fit()를 호출하는 데 사용됩니다.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
scikit-learn 파이프라인에는 기능화 단계, 전처리기(사용되는 경우) 및 알고리즘 또는 모델이 포함됩니다.
시계열 예측 모델의 경우 scikit-learn 파이프라인은 적용된 알고리즘에 따라 시계열 데이터를 적절하게 처리하는 데 필요한 몇 가지 추가 논리가 들어 있는 ForecastingPipelineWrapper에 래핑됩니다.
레이블 열을 인코딩해야 하는 경우 모든 작업 유형에 PipelineWithYTransformer를 사용합니다.
scikit-Learn 파이프라인이 생겼으면 모델을 학습시키는 fit() 메서드를 호출하기만 하면 됩니다.
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
train_model()의 반환 값은 입력 데이터에 맞춰진/학습된 모델입니다.
모든 이전 함수를 실행하는 주 코드는 다음과 같습니다.
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
학습된 모델이 있으면 predict() 메서드를 사용하여 예측을 만드는 데 사용할 수 있습니다. 실험이 시계열 모델에 대한 것인 경우 예측에 forecast() 메서드를 사용합니다.
y_pred = model.predict(X)
마지막으로, 다음과 같이 모델이 직렬화되고 "model.pkl"이라는 이름의 .pkl 파일로 저장됩니다.
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
script_run_notebook.ipynb Notebook은 Azure Machine Learning 컴퓨팅에서 쉽게 script.py를 실행할 수 있는 방법입니다.
이 Notebook은 기존의 자동화된 ML 샘플 Notebook과 비슷하지만, 다음 섹션에 설명된 것처럼 몇 가지 결정적인 차이점이 있습니다.
환경
일반적으로 자동화된 ML 실행에 사용되는 학습 환경은 SDK에 의해 자동으로 설정됩니다. 그러나 생성된 코드처럼 사용자 지정 스크립트를 실행하는 경우 자동화된 ML이 더 이상 프로세스를 구동하지 않으므로 명령 작업이 성공하려면 환경을 지정해야 합니다.
코드 생성은 되도록이면 원래 자동화된 ML 실험에서 사용된 환경을 다시 사용합니다. 이렇게 하면 누락된 종속성으로 인해 학습 스크립트 실행이 실패하는 일이 없으며, Docker 이미지를 다시 빌드할 필요가 없으므로 시간과 컴퓨팅 리소스가 절약되는 부가적인 이점이 있습니다.
추가 종속성이 필요하거나 사용자 고유의 환경을 사용해야 하는 script.py에 대한 변경 작업을 수행하면 그에 맞게 script_run_notebook.ipynb에서 환경을 업데이트해야 합니다.
실험 제출
생성된 코드는 더 이상 자동화된 ML 의해 구동되지 않으므로 AutoML 작업을 만들어서 제출하는 대신, Command Job을 만들고 생성된 코드(script.py)를 여기에 제공해야 합니다.
다음 예제는 컴퓨팅, 환경 등과 같은 명령 작업을 실행하는 데 필요한 매개 변수 및 일반 종속성을 포함합니다.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
다음 단계
- 모델 배포 방법 및 위치에 대해 자세히 알아봅니다.
- 특히 자동화된 ML 실험 내에서 해석력 기능을 사용하도록 설정하는 방법을 참조하세요.