모델(v2)을 튜닝하는 하이퍼 매개 변수
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
SweepJob 형식을 통해 Azure Machine Learning SDK v2 및 CLI v2를 사용하여 효율적인 하이퍼 매개 변수 튜닝을 자동화합니다.
- 평가판에 대한 매개 변수 검색 공간 정의
- 비우기 작업에 대한 샘플링 알고리즘 지정
- 최적화 목표 지정
- 낮은 성능 작업에 대한 조기 종료 정책 지정
- 비우기 작업에 대한 제한 정의
- 정의된 구성을 사용하여 실험 시작
- 학습 작업 시각화
- 모델에 최상의 구성 선택
하이퍼 매개 변수 튜닝이란?
하이퍼 매개 변수는 모델 학습 프로세스를 제어할 수 있게 하는 조정 가능한 매개 변수입니다. 예를 들어 신경망을 사용하여 숨겨진 레이어 수와 각 레이어의 노드 수를 결정합니다. 모델 성능은 하이퍼 매개 변수에 따라 크게 달라집니다.
하이퍼 매개 변수 최적화라고도 하는 하이퍼 매개 변수 튜닝은 최상의 성능을 발휘하는 하이퍼 매개 변수 구성을 찾는 프로세스입니다. 프로세스는 일반적으로 계산 비용이 많이 들고 수동입니다.
Azure Machine Learning을 사용하면 하이퍼 매개 변수 튜닝을 자동화하고 병렬로 실험을 실행하여 하이퍼 매개 변수를 효율적으로 최적화할 수 있습니다.
검색 공간 정의
하이퍼 매개 변수마다 정의된 값의 범위를 탐색하여 하이퍼 매개 변수를 튜닝합니다.
하이퍼 매개 변수는 불연속 또는 연속일 수 있으며 매개 변수 식에서 설명하는 값의 분포를 가집니다.
개별 하이퍼 매개 변수
개별 하이퍼 매개 변수는 불연속 값 중 Choice로 지정됩니다. Choice는 다음이 될 수 있습니다.
- 하나 이상의 쉼표로 구분된 값
range개체- 임의의
list개체
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
이 사례에서 batch_size는 [16, 32, 64, 128] 값 중 하나를, number_of_hidden_layers는 [1, 2, 3, 4] 값 중 하나를 사용합니다.
배포를 사용하여 다음과 같은 고급 불연속 하이퍼 매개 변수도 지정할 수 있습니다.
QUniform(min_value, max_value, q)- round(Uniform(min_value, max_value) / q) * q와 같은 값을 반환합니다.QLogUniform(min_value, max_value, q)- round(exp(Uniform(min_value, max_value)) / q) * q와 같은 값을 반환합니다.QNormal(mu, sigma, q)- round(Normal(mu, sigma) / q) * q와 같은 값을 반환합니다.QLogNormal(mu, sigma, q)- round(exp(Normal(mu, sigma)) / q) * q와 같은 값을 반환합니다.
연속 하이퍼 매개 변수
연속 하이퍼 매개 변수는 연속 값의 범위에 대한 배포로 지정됩니다.
Uniform(min_value, max_value)- min_value와 max_value 간에 균일하게 분산된 값을 반환합니다.LogUniform(min_value, max_value)- 반환 값의 로그가 균일하게 분산되도록 exp(Uniform(min_value, max_value))에 따라 도출된 값을 반환합니다.Normal(mu, sigma)- 평균 mu 및 표준 편차 sigma를 사용하여 일반적으로 배포되는 실제 값 반환LogNormal(mu, sigma)- 반환 값의 로그가 정규 분포되도록 exp(Normal(mu, sigma))에 따라 도출된 값을 반환합니다.
매개 변수 공간 정의의 예제는 다음과 같습니다.
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
이 코드는 learning_rate 및 keep_probability라는 두 개의 매개 변수를 사용하여 검색 공간을 정의합니다. learning_rate는 평균 값 10과 표준 편차 3이 있는 정규 분포를 갖게 됩니다. keep_probability는 최솟값 0.05 및 최댓값 0.1이 있는 균일한 분포를 갖게 됩니다.
CLI의 경우 비우기 작업 YAML 스키마를 사용하여 YAML에서 검색 공간을 정의할 수 있습니다.
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
하이퍼 매개 변수 공간 샘플링
하이퍼 매개 변수 공간을 통해 사용하도록 매개 변수 샘플링 방법을 지정합니다. Azure Machine Learning에서는 다음 방법을 지원합니다.
- 무작위 샘플링
- 그리드 샘플링
- Bayesian 샘플링
무작위 샘플링
무작위 샘플링은 불연속 및 연속 하이퍼 매개 변수를 지원합니다. 낮은 성능 작업의 조기 종료를 지원합니다. 일부 사용자는 무작위 샘플링을 사용하여 초기 검색을 수행한 다음, 검색 공간을 상세 검색하여 결과를 향상시킵니다.
무작위 샘플링에서 하이퍼 매개 변수 값은 정의된 검색 공간에서 임의로 선택됩니다. 명령 작업이 만들어지면 비우기 매개 변수를 사용하여 샘플링 알고리즘을 정의할 수 있습니다.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
sobol
sobol은 비우기 작업 유형에서 지원하는 무작위 샘플링의 한 유형입니다. sobol을 사용하면 시드를 사용하여 결과를 재현하고 검색 공간 분포를 더 균일하게 처리할 수 있습니다.
sobol을 사용하려면 아래 예제와 같이 RandomParameterSampling 클래스를 사용하여 시드 및 규칙을 추가합니다.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
그리드 샘플링
그리드 샘플링은 불연속 하이퍼 매개 변수를 지원합니다. 검색 공간을 철저히 검색하도록 예산을 편성할 수 있는 경우에는 그리드 샘플링을 사용합니다. 낮은 성능 작업의 조기 종료를 지원합니다.
그리드 샘플링은 가능한 모든 값에 간단한 그리드 검색을 수행합니다. choice 하이퍼 매개 변수에서만 그리드 샘플링을 사용할 수 있습니다. 예를 들어 다음 공간에는 샘플이 6개 있습니다.
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Bayesian 샘플링
Bayesian 샘플링은 Bayesian 최적화 알고리즘을 기반으로 합니다. 이전 샘플에서 수행한 방식을 기반으로 샘플을 선택하여 새 샘플이 기본 메트릭을 향상시킵니다.
하이퍼 매개 변수 공간을 탐색하는 데 예산이 충분한 경우에는 Bayesian 샘플링을 사용하는 것이 좋습니다. 최상의 결과를 얻으려면 튜닝되는 하이퍼 매개 변수 수의 20배 이상의 최대 작업 수를 권장합니다.
동시 작업의 수는 튜닝 프로세스의 효율성에 영향을 줍니다. 병렬 처리 수준이 낮을수록 이전에 완료된 작업의 혜택을 받는 작업 수가 증가하므로 동시 작업 수가 적을수록 샘플링 수렴이 향상될 수 있습니다.
Bayesian 샘플링은 검색 공간을 통해 choice, uniform 및 quniform 배포만 지원합니다.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
비우기 목표 지정
하이퍼 매개 변수 튜닝을 최적화하려는 기본 메트릭과 목표를 지정하여 비우기 작업의 목표를 정의합니다. 각 학습 작업은 기본 메트릭에 대해 평가됩니다. 조기 종료 정책은 기본 메트릭을 사용하여 성능이 낮은 작업을 식별합니다.
primary_metric: 기본 메트릭 이름은 학습 스크립트에서 로그한 메트릭의 이름과 정확하게 일치해야 합니다.goal:Maximize또는Minimize일 수 있으며, 작업을 평가할 때 기본 메트릭을 최대화할지 아니면 최소화할지 여부를 결정합니다.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
이 샘플에서는 "정확도"를 극대화합니다.
하이퍼 매개 변수 튜닝에 대한 메트릭 기록
모델에 대한 학습 스크립트는 SweepJob에서 하이퍼 매개 변수 튜닝을 위해 액세스할 수 있도록 동일한 해당 메트릭 이름을 사용하여 모델 학습 중에 기본 메트릭을 로그해야 합니다.
다음 샘플 코드 조각을 사용하여 학습 스크립트에 기본 메트릭을 로그합니다.
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
학습 스크립트는 val_accuracy를 계산하고 기본 메트릭 "정확도"로 로그합니다. 메트릭이 로그될 때마다 하이퍼 매개 변수 튜닝 서비스에 의해 수신됩니다. 사용자는 보고 빈도를 결정해야 합니다.
학습 작업의 로깅 값에 대한 자세한 내용은 Azure Machine Learning 학습 작업에서 로깅 사용을 참조하세요.
조기 종료 정책 지정
조기 종료 정책을 사용하여 성능이 낮은 작업을 자동으로 종료합니다. 초기 종료는 계산 효율성을 향상시킵니다.
정책이 적용되는 시기를 제어하는 매개 변수를 다음과 같이 구성할 수 있습니다.
evaluation_interval: 정책 적용 빈도입니다. 학습 스크립트에서 기본 메트릭을 기록할 때마다 한 번의 간격으로 계산됩니다. 따라서 1의evaluation_interval은 학습 스크립트에서 기본 메트릭을 보고할 때마다 정책을 적용합니다. 2의evaluation_interval은 다른 모든 시간에 정책을 적용합니다. 지정되지 않는 경우evaluation_interval은 기본적으로 0으로 설정됩니다.delay_evaluation: 지정된 간격 동안 첫 번째 정책 평가를 지연합니다. 이는 모든 구성이 최소 간격 동안 실행되도록 허용하여 학습 작업의 조기 종료를 방지하는 선택적 매개 변수입니다. 지정된 경우 정책은 delay_evaluation보다 크거나 같은 evaluation_interval의 모든 배수마다 적용됩니다. 지정되지 않는 경우delay_evaluation은 기본적으로 0으로 설정됩니다.
Azure Machine Learning은 다음 초기 종료 정책을 지원합니다.
산적 정책
산적 정책은 slack 요소/slack 양 및 평가 간격을 기반으로 합니다. 기본 메트릭이 가장 성공적인 작업의 지정된 slack 요소/slack 양 내에 있지 않으면 산적 정책에서 해당 작업을 종료합니다.
다음 구성 매개 변수를 지정합니다.
slack_factor또는slack_amount: 가장 효율적으로 수행되는 학습 작업과 관련하여 허용되는 slack입니다.slack_factor는 비율로 허용되는 slack을 지정합니다.slack_amount는 비율 대신에 절대 양으로 허용되는 slack을 지정합니다.예를 들어 간격 10에 적용되는 산적 정책을 사용하는 것이 좋습니다. 기본 메트릭을 보고한 10 간격에서 가장 효율적으로 수행되는 작업이 0.8이고 기본 메트릭을 최대화하는 것을 목표로 한다고 가정합니다. 정책에서
slack_factor를 0.2로 지정하면 10 간격에서 최상의 메트릭이 0.66(0.8/(1+slack_factor)) 미만인 모든 학습 작업이 종료됩니다.evaluation_interval: (선택 사항) 정책 적용 빈도입니다.delay_evaluation: (선택 사항) 지정된 간격 동안 첫 번째 정책 평가를 지연합니다.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
이 예제에서는 평가 간격 5에서 시작하여 메트릭이 보고될 때 모든 간격에서 초기 종료 정책이 적용됩니다. 최상의 메트릭이 (1/(1+0.1) 또는 가장 효율적으로 수행되는 작업의 91% 미만인 모든 작업이 종료됩니다.
중앙값 중지 정책
중앙값 중지는 작업에서 보고하는 기본 메트릭의 실행 평균을 기반으로 하는 초기 종료 정책입니다. 이 정책은 모든 학습 작업에서 실행 평균을 계산하고, 기본 메트릭 값이 평균의 중앙값보다 낮은 작업을 중지합니다.
이 정책은 다음 구성 매개 변수를 사용합니다.
evaluation_interval: 정책 적용에 대한 빈도입니다(선택적 매개 변수).delay_evaluation: 지정된 간격 동안 첫 번째 정책 평가를 지연합니다(선택적 매개 변수).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
이 예제에서는 평가 간격 5에서 시작하여 모든 간격에서 초기 종료 정책이 적용됩니다. 최상의 기본 메트릭이 모든 학습 작업에서 1:5 간격에 걸쳐 실행 평균의 중앙값보다 낮은 경우 작업은 5 간격에서 중지됩니다.
잘림 선택 영역 정책
잘림 선택 영역은 각 평가 간격에서 성능이 가장 낮은 작업의 백분율을 취소합니다. 작업은 기본 메트릭을 사용하여 비교됩니다.
이 정책은 다음 구성 매개 변수를 사용합니다.
truncation_percentage: 각 평가 간격에서 종료할 성능이 가장 낮은 작업의 백분율입니다. 1~99 사이의 정수 값입니다.evaluation_interval: (선택 사항) 정책 적용 빈도입니다.delay_evaluation: (선택 사항) 지정된 간격 동안 첫 번째 정책 평가를 지연합니다.exclude_finished_jobs: 정책을 적용할 때 완료된 작업을 제외할지 여부를 지정합니다.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
이 예제에서는 평가 간격 5에서 시작하여 모든 간격에서 초기 종료 정책이 적용됩니다. 5 간격의 성능이 5 간격의 모든 작업 중에서 가장 낮은 20% 성능인 경우 작업은 5 간격에서 종료되고 정책을 적용할 때 완료된 작업은 제외됩니다.
종료 정책 없음(기본값)
지정된 정책이 없으면 하이퍼 매개 변수 튜닝 서비스에서 모든 학습 작업이 완료될 때까지 실행되도록 합니다.
sweep_job.early_termination = None
초기 종료 정책 선택
- 가능성이 높은 작업을 종료하지 않고 비용 절약을 제공하는 보수적인 정책을 원하는 경우
evaluation_interval1 및delay_evaluation5의 중앙값 중지 정책을 사용하는 것이 좋습니다. 이는 일반적인 설정이며, 기본 메트릭에서 손실 없이 약 25%-35% 절감을 제공할 수 있습니다(계산 데이터에 따라). - 더욱 적극적으로 절약하려면 허용 가능한 slack이 더 작은 산적 정책이나 잘림 비율이 더 큰 잘림 선택 정책을 사용합니다.
비우기 작업에 대한 제한 설정
비우기 작업에 대한 제한을 설정하여 리소스 예산을 제어합니다.
max_total_trials: 최대 시험 작업 수입니다. 1~1000 사이의 정수여야 합니다.max_concurrent_trials: (선택 사항) 동시에 실행할 수 있는 최대 시험 작업 수입니다. 지정하지 않으면 max_total_trials는 병렬로 시작하는 작업의 수입니다. 지정하는 경우 1~1000 사이의 정수여야 합니다.timeout: 전체 스윕 작업을 실행할 수 있는 최대 시간(초)입니다. 이 한도에 도달하면 시스템은 모든 평가판을 포함하여 스윕 작업을 취소합니다.trial_timeout: 각 시험 작업을 실행할 수 있는 최대 시간(초)입니다. 이 한도에 도달하면 시스템은 평가판을 취소합니다.
참고 항목
max_total_trials 및 timeout이 모두 지정되는 경우 이러한 두 임계값 중 첫 번째 임계값에 도달하면 하이퍼 매개 변수 튜닝 실험이 종료됩니다.
참고 항목
동시 시험 작업 수는 지정된 컴퓨팅 대상에서 사용할 수 있는 리소스에서 제어됩니다. 원하는 동시성에 사용할 수 있는 리소스가 컴퓨팅 대상에 있는지 확인합니다.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
이 코드는 최대 20개의 총 시험 작업을 사용하도록 하이퍼 매개 변수 튜닝 실험을 구성하고, 전체 비우기 작업에 대한 시간 제한이 1200초인 4개의 시험 작업을 한 번에 실행합니다.
하이퍼 매개 변수 튜닝 실험 구성
하이퍼 매개 변수 튜닝 실험을 구성하려면 다음을 제공합니다.
- 정의된 하이퍼 매개 변수 검색 공간
- 샘플링 알고리즘
- 초기 종료 정책 지정
- 목표
- 리소스 제한
- CommandJob 또는 CommandComponent
- SweepJob
SweepJob은 명령 또는 명령 구성 요소에서 하이퍼 매개 변수 비우기를 실행할 수 있습니다.
참고 항목
sweep_job에서 사용되는 컴퓨팅 대상에는 동시성 수준을 만족할 수 있는 충분한 리소스가 있어야 합니다. 컴퓨팅 대상에 대한 자세한 내용은 컴퓨팅 대상을 참조하세요.
하이퍼 매개 변수 조정 실험 구성
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
command_job은 매개 변수 식을 비우기 입력에 적용할 수 있도록 함수로 호출됩니다. 그러면 sweep 함수가 trial, sampling-algorithm, objective, limits 및 compute로 구성됩니다. 위의 코드 조각은 명령 또는 CommandComponent에서 하이퍼 매개 변수 비우기 실행 샘플 Notebook에서 가져온 것입니다. 이 샘플에서는 learning_rate 및 boosting 매개 변수가 튜닝됩니다. 작업의 조기 중지는 MedianStoppingPolicy에 따라 결정되며, 기본 메트릭 값이 모든 학습 작업의 평균 중앙값보다 낮은 작업을 중지합니다(MedianStoppingPolicy 클래스 참조 참조).
매개 변수 값을 받고, 구문 분석하고, 튜닝되는 학습 스크립트에 전달하는 방법을 알아보려면 이 코드 샘플을 참조하세요.
Important
모든 하이퍼 매개 변수 비우기 작업은 모델 및 모든 데이터 로더 다시 빌드를 포함하여 학습을 처음부터 다시 시작합니다. Azure Machine Learning 파이프라인 또는 수동 프로세스를 사용하여 학습 작업 이전에 최대한 많은 데이터 준비를 수행하면 이 비용을 최소화할 수 있습니다.
하이퍼 매개 변수 튜닝 실험 제출
하이퍼 매개 변수 튜닝 구성을 정의하면 다음과 같이 작업을 제출합니다.
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
하이퍼 매개 변수 튜닝 작업 시각화
Azure Machine Learning 스튜디오에서 모든 하이퍼 매개 변수 튜닝 작업을 시각화할 수 있습니다. 포털에서 실험을 보는 방법에 대한 자세한 내용은 스튜디오에서 작업 레코드 보기를 참조하세요.
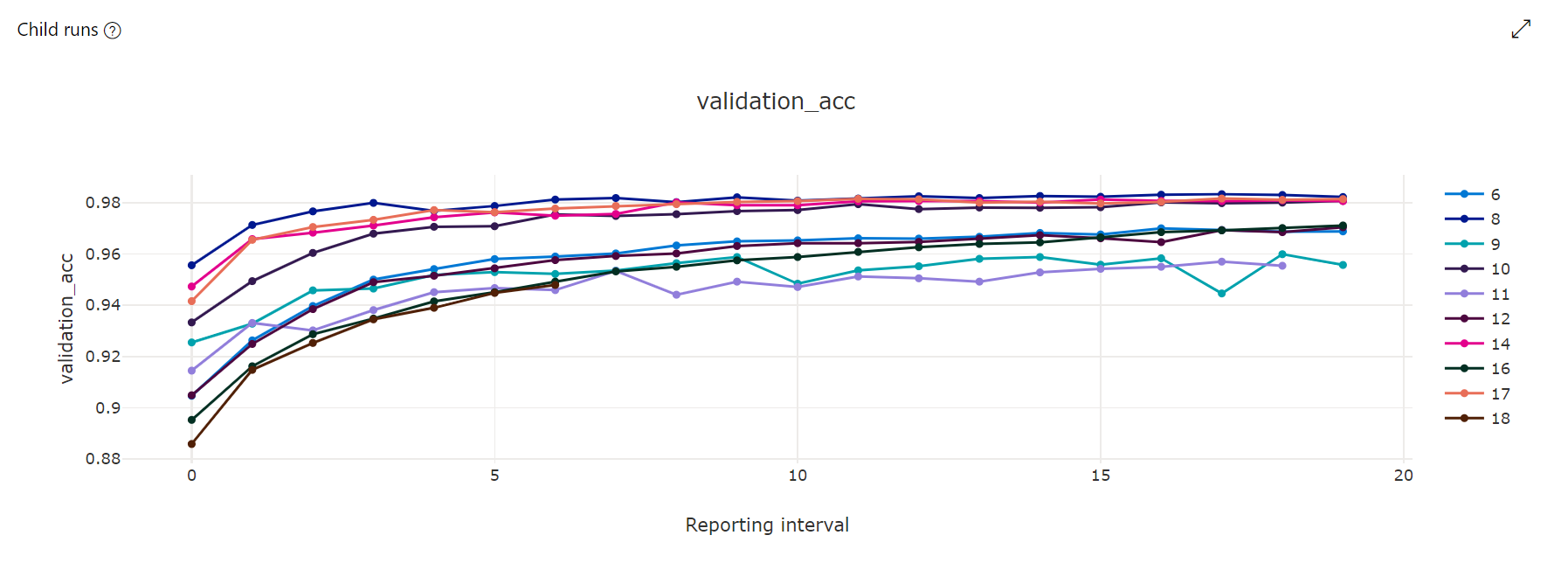
메트릭 차트: 이 시각화는 하이퍼 매개 변수 튜닝 기간 동안 각 HyperDrive 자식 작업에 대해 로그된 메트릭을 추적합니다. 각 줄은 자식 작업을 나타내고, 각 지점은 해당 런타임 반복에서 기본 메트릭 값을 측정합니다.
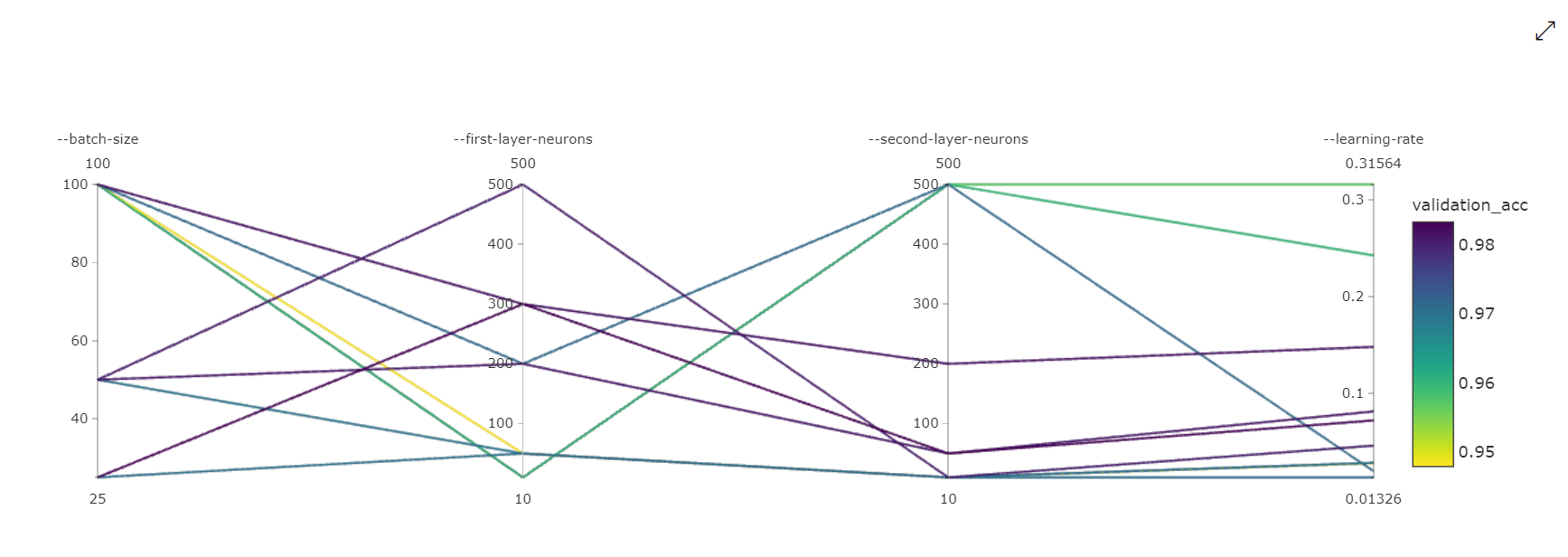
병렬 좌표 차트: 이 시각화에서는 기본 메트릭 성능과 개별 하이퍼 매개변수 값 간의 상관 관계를 보여줍니다. 차트는 축을 이동(클릭하여 축 레이블에 따라 끌기)하고 단일 축에서 값을 강조 표시하는(클릭하여 단일 축을 따라 세로 방향으로 끌어 원하는 값 범위 강조 표시) 대화형 차트입니다. 병렬 좌표 차트의 가장 오른쪽에는 해당 작업 인스턴스에 대해 설정된 하이퍼 매개 변수에 해당하는 최상의 메트릭 값을 그리는 축이 포함됩니다. 이 축은 차트 그라데이션 범례를 보다 읽기 쉬운 방식으로 데이터에 투영하기 위해 제공됩니다.
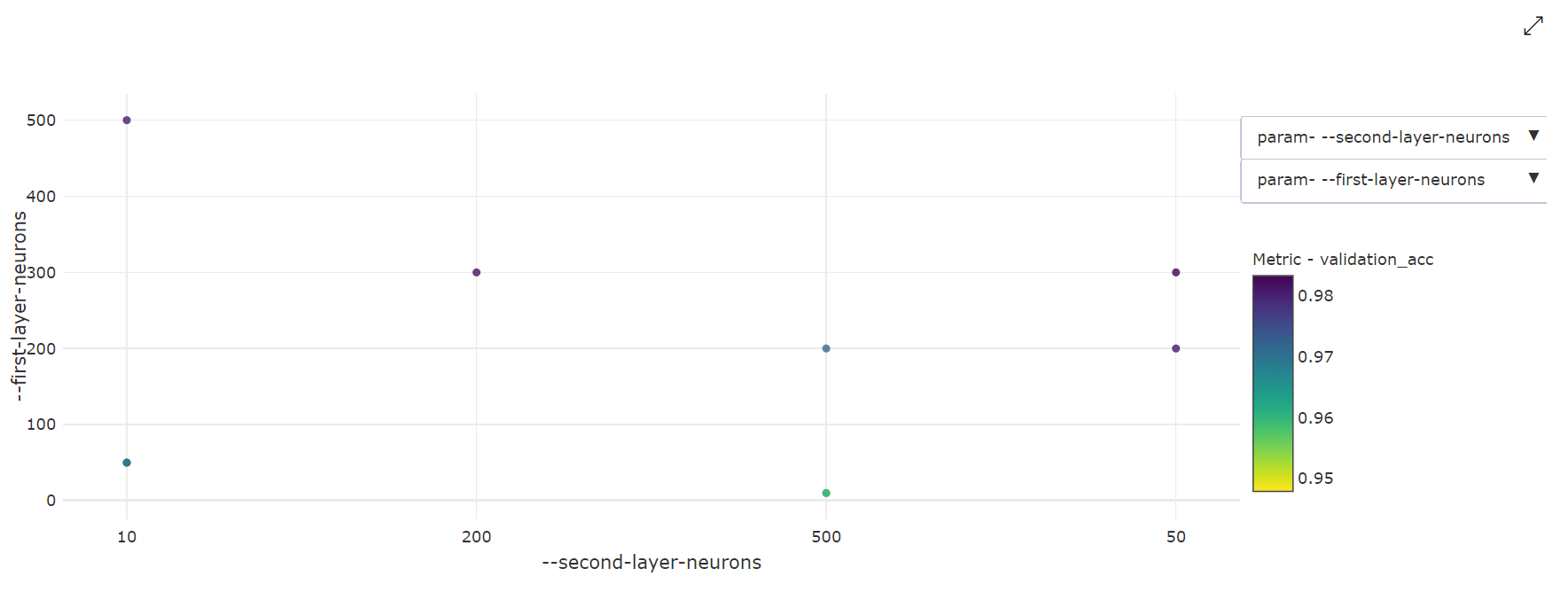
2차원 분산형 차트: 이 시각화에서는 개별 하이퍼 매개 변수 2개와 연결된 기본 메트릭 값 간의 상관 관계를 보여줍니다.
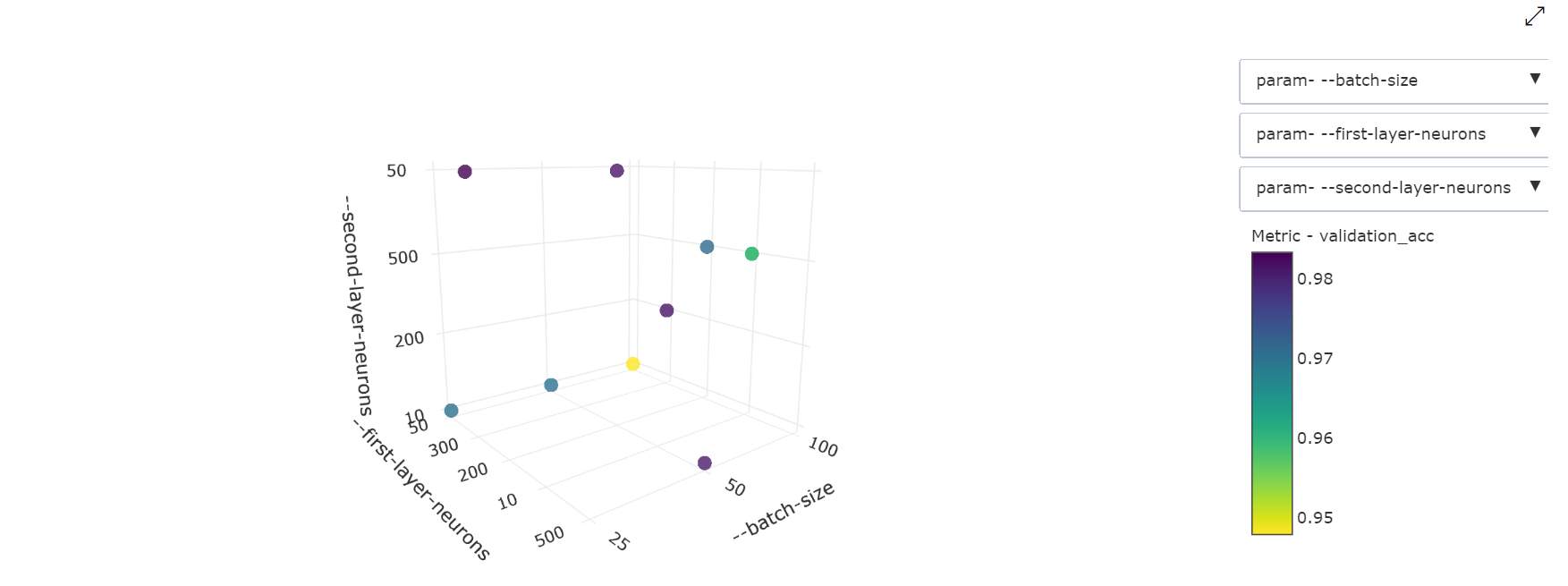
3차원 분산형 차트: 이 시각화는 2D와 동일하지만 기본 메트릭 값과의 상관 관계에 대한 하이퍼 매개 변수 차원 3개를 허용합니다. 3D 공간에서 다른 상관 관계를 보려면 클릭하고 끌어 차트 방향을 바꾸면 됩니다.
최상의 시험 작업 찾기
모든 하이퍼 매개 변수 튜닝 작업이 완료되면 최상의 시험 출력을 검색합니다.
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
CLI를 사용하여 최상의 시험 작업에 대한 모든 기본 및 명명된 출력과 비우기 작업의 로그를 다운로드할 수 있습니다.
az ml job download --name <sweep-job> --all
필요에 따라 최상의 시험 출력만 다운로드합니다.
az ml job download --name <sweep-job> --output-name model