Azure Machine Learning 데이터 세트 버전 지정 및 추적
적용 대상: Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 재현성을 위해 Azure Machine Learning 데이터 세트의 버전을 지정하고 추적하는 방법을 알아봅니다. 데이터 세트 버전 관리에서는 데이터의 특정 상태를 책갈피로 지정하므로 향후 실험을 위해 특정 버전의 데이터 세트를 적용할 수 있습니다.
다음과 같은 일반적인 시나리오에서 Azure Machine Learning 리소스의 버전을 지정할 수 있습니다.
- 재학습에 새 데이터를 사용할 수 있게 되는 경우
- 다른 데이터 준비 또는 기능 엔지니어링 방법을 적용하는 경우
필수 조건
Python용 Azure Machine Learning SDK. 이 SDK에는 azureml-datasets 패키지가 포함됩니다.
Azure Machine Learning 작업 영역 새 작업 영역을 만들거나 이 코드 샘플을 사용하여 기존 작업 영역을 검색합니다.
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
데이터 세트 버전 등록 및 검색
여러 실험 및 동료와 등록된 데이터 세트를 버전 관리, 재사용 및 공유할 수 있습니다. 동일한 이름으로 여러 데이터 세트를 등록하고 이름 및 버전 번호별로 특정 버전을 검색할 수 있습니다.
데이터 세트 버전 등록
이 코드 샘플은 create_new_version 데이터 세트의 매개 변수를 titanic_dsTrue해당 데이터 세트의 새 버전을 등록하도록 설정합니다. 작업 영역에 등록된 기존 titanic_ds 데이터 세트가 없는 경우 코드는 이름으로 titanic_ds새 데이터 세트를 만들고 해당 버전을 1로 설정합니다.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
이름으로 데이터 세트 검색
기본적으로 Dataset 클래스 get_by_name() 메서드는 작업 영역에 등록된 최신 버전의 데이터 세트를 반환합니다.
이 코드는 데이터 세트의 버전 1을 titanic_ds 반환합니다.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
버전 관리 모범 사례
데이터 세트 버전을 만들 때 작업 영역을 사용하여 데이터의 추가 복사본을 만들지 않습니다 . 데이터 세트는 스토리지 서비스의 데이터에 대한 참조이므로 스토리지 서비스에서 관리하는 단일 원본이 있습니다.
Important
데이터 세트에서 참조하는 데이터를 덮어쓰거나 삭제하는 경우 특정 버전의 데이터 세트에 대한 호출은 변경 내용을 되돌리기 않습니다 .
데이터 세트에서 데이터를 로드하면 데이터 세트에서 참조하는 현재 데이터 콘텐츠가 항상 로드됩니다. 각 데이터 세트 버전을 재현할 수 있도록 하려면 데이터 세트 버전에서 참조하는 데이터 콘텐츠를 수정하지 않는 것이 좋습니다. 새 데이터가 들어오면 새 데이터 파일을 별도의 데이터 폴더에 저장한 다음 새 폴더의 데이터를 포함하도록 새 데이터 세트 버전을 만듭니다.
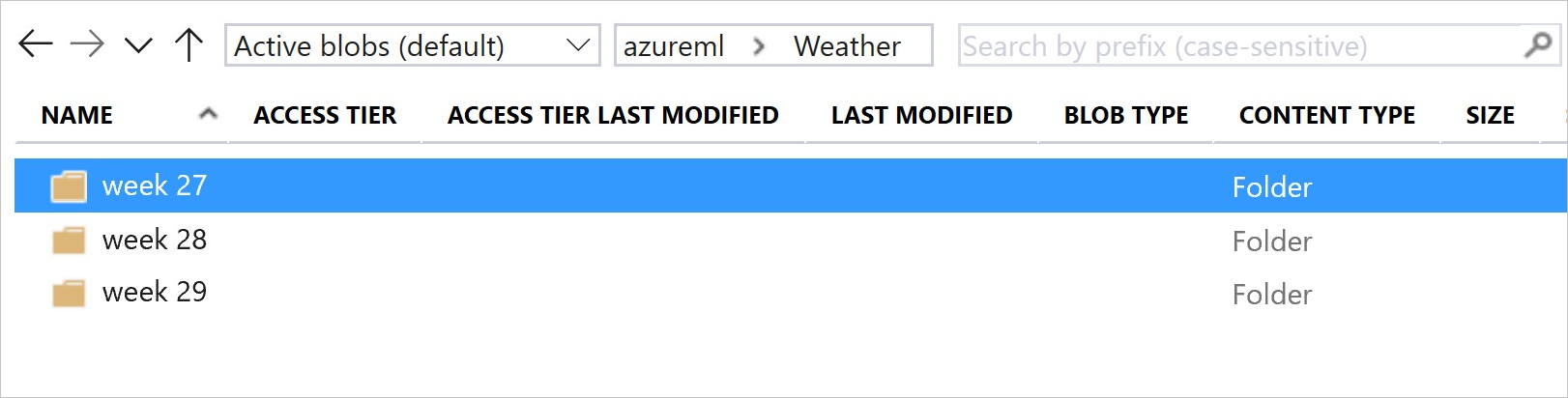
이 이미지 및 샘플 코드는 데이터 폴더를 구조화하고 해당 폴더를 참조하는 데이터 세트 버전을 만드는 데 권장되는 방법을 보여 줍니다.
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
ML 파이프라인 출력 데이터 세트 버전 지정
데이터 세트를 각 ML 파이프라인 단계의 입력 및 출력으로 사용할 수 있습니다. 파이프라인을 다시 실행하면 각 파이프라인 단계의 출력이 새 데이터 세트 버전으로 등록됩니다.
Machine Learning 파이프라인은 파이프라인을 다시 실행할 때마다 각 단계의 출력을 새 폴더로 채웁니다. 그런 다음 버전이 지정된 출력 데이터 세트를 재현할 수 있게 됩니다. 자세한 내용은 파이프라인의 데이터 세트를 방문 하세요.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
실험에서 데이터 추적
Azure Machine Learning은 실험 전반에서 데이터를 입력 및 출력 데이터 세트로 추적합니다. 이러한 시나리오에서 데이터는 입력 데이터 세트로 추적됩니다.
DatasetConsumptionConfig실험 작업을 제출할 때 개체의inputsScriptRunConfig매개 변수 또는arguments매개 변수를 통해 개체로스크립트가 특정 메서드를
get_by_name()호출하는 경우 또는get_by_id()- 예를 들면 다음과 같습니다. 데이터 세트를 작업 영역에 등록할 때 데이터 세트에 할당된 이름은 표시된 이름입니다.
이러한 시나리오에서 데이터는 출력 데이터 세트로 추적됩니다.
OutputFileDatasetConfig실험 작업을 제출할 때 또는arguments매개 변수를outputs통해 개체를 전달합니다.OutputFileDatasetConfig개체는 파이프라인 단계 간에 데이터를 유지할 수도 있습니다. 자세한 내용은 ML 파이프라인 단계 간에 데이터 이동스크립트에 데이터 세트를 등록합니다. 데이터 세트를 작업 영역에 등록할 때 데이터 세트에 할당된 이름은 표시되는 이름입니다. 이 코드 샘플에서는
training_ds표시된 이름입니다.training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )스크립트에서 등록되지 않은 데이터 세트가 있는 자식 작업 제출 이 제출은 익명으로 저장된 데이터 세트를 생성합니다.
실험 작업의 데이터 세트 추적
각 Machine Learning 실험에 대해 실험 개체에 대한 입력 데이터 세트를 추적할 Job 수 있습니다. 이 코드 샘플에서는 get_details() 이 메서드를 사용하여 실험 실행에 사용되는 입력 데이터 세트를 추적합니다.
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
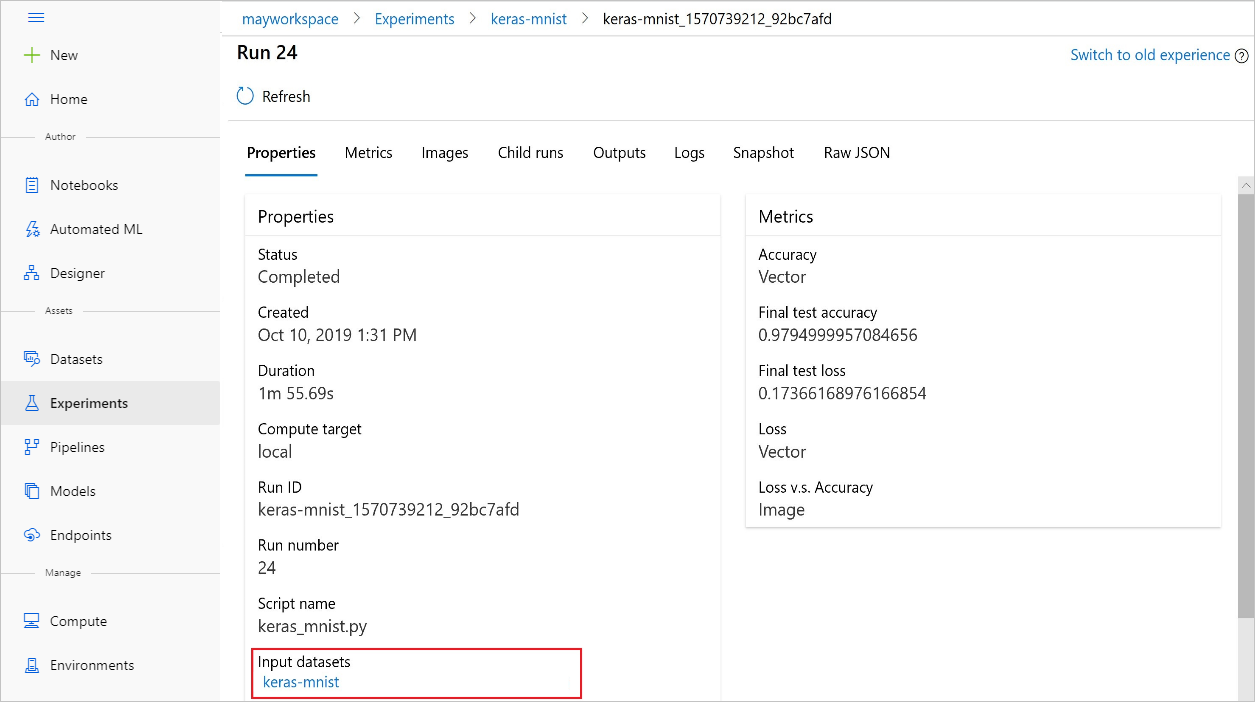
Azure Machine Learning 스튜디오 사용하여 실험에서 찾을 input_datasets 수도 있습니다.
이 스크린샷은 Azure Machine Learning 스튜디오 실험의 입력 데이터 세트를 찾을 수 있는 위치를 보여줍니다. 이 예제에서는 실험 창에서 시작하고 실험의 keras-mnist특정 실행에 대한 속성 탭을 엽니다.
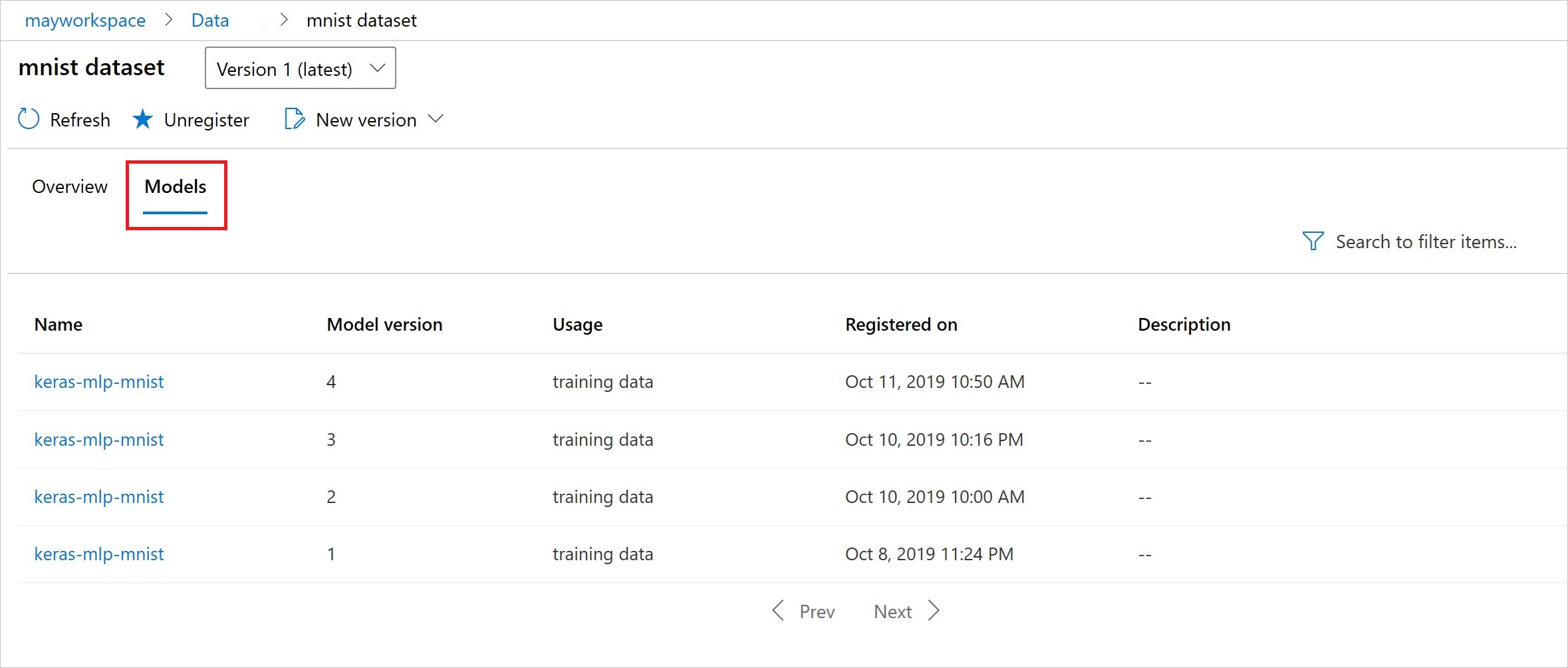
이 코드는 데이터 세트를 사용하여 모델을 등록합니다.
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
등록 후 Python 또는 스튜디오를 사용하여 데이터 세트에 등록된 모델 목록을 볼 수 있습니다.
Thia 스크린샷은 자산 아래의 데이터 세트 창에 있습니다. 데이터 세트를 선택한 다음, 데이터 세트에 등록된 모델 목록에 대한 모델 탭을 선택합니다.