Machine Learning Studio(클래식)에서 알고리즘을 최적화하는 매개 변수 선택
적용 대상: Machine Learning Studio(클래식)
Machine Learning Studio(클래식)  Azure Machine Learning
Azure Machine Learning
중요
Machine Learning Studio(클래식)에 대한 지원은 2024년 8월 31일에 종료됩니다. 해당 날짜까지 Azure Machine Learning으로 전환하는 것이 좋습니다.
2021년 12월 1일부터 새로운 Machine Learning Studio(클래식) 리소스를 만들 수 없습니다. 2024년 8월 31일까지는 기존 Machine Learning Studio(클래식) 리소스를 계속 사용할 수 있습니다.
- ML Studio(클래식)에서 Azure Machine Learning으로 기계 학습 프로젝트 이동에 대한 정보를 참조하세요.
- Azure Machine Learning에 대해 자세히 알아보세요.
ML Studio(클래식) 설명서는 사용 중지되며 나중에 업데이트되지 않을 수 있습니다.
이 항목에서는 Machine Learning Studio(클래식)에서 알고리즘에 대해 올바른 하이퍼파라미터 집합을 선택하는 방법에 대해 설명합니다. 대부분의 기계 학습 알고리즘은 설정할 매개 변수를 포함하고 있습니다. 모델을 학습할 때 이러한 매개 변수의 값을 제공해야 합니다. 학습된 모델의 효율성은 선택한 모델 매개 변수에 따라 달라집니다. 최적의 매개 변수 집합을 찾는 프로세스를 모델 선택이라고 합니다.
모델 선택 영역을 수행하는 방법은 여러 가지가 있습니다. 기계 학습에서 교차 유효성 검증은 모델 선택에 가장 널리 사용되는 방법 중 하나이며 Machine Learning Studio(클래식)의 기본 모델 선택 메커니즘입니다. Machine Learning Studio(클래식)는 R과 Python을 모두 지원하므로 R 또는 Python을 사용하여 항상 고유한 모델 선택 메커니즘을 구현할 수 있습니다.
최상의 매개 변수 집합을 찾는 프로세스는 4단계로 구성됩니다.
- 매개 변수 공간 정의: 먼저 알고리즘에 대해 고려할 정확한 매개 변수 값을 결정합니다.
- 교차 유효성 검사 설정 정의: 데이터 세트에 대해 교차 유효성 검사 접기를 선택하는 방법을 결정합니다.
- 메트릭 정의: 최상의 매개 변수 집합(예: 정확도, 평균 제곱근 오차, 정밀도, 재현율 또는 f-score)을 결정하는 데 사용할 메트릭을 결정합니다.
- 학습, 평가 및 비교: 매개 변수 값의 각 고유한 조합에 대해 정의한 오류 메트릭을 기반으로 교차 유효성 검사를 수행합니다. 평가 및 비교 후에 최고 성능 모델을 선택할 수 있습니다.
다음 이미지는 Azure Machine Learning Studio(클래식)에서 이 작업을 수행하는 방법을 보여 줍니다.
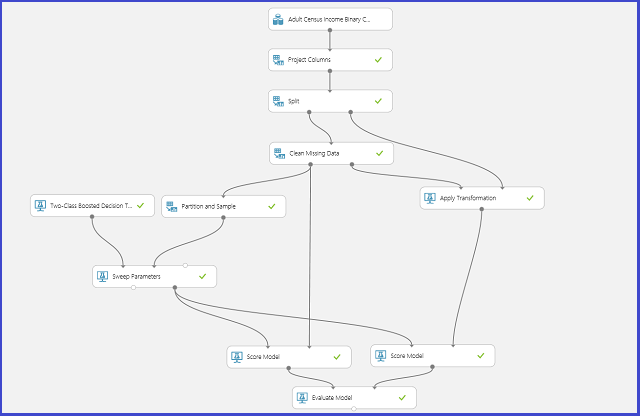
매개 변수 공간 정의
모델 초기화 단계에서 매개 변수 집합을 정의할 수 있습니다. 모든 Machine Learning 알고리즘의 매개 변수 창에는 두 가지 강사 모드(단일 매개 변수 및 매개 변수 범위)가 있습니다. 매개 변수 범위 모드를 선택합니다. 매개 변수 범위 모드에서는 각 매개 변수에 대한 여러 값을 입력할 수 있습니다. 텍스트 상자에서 쉼표로 구분된 값을 입력할 수 있습니다.
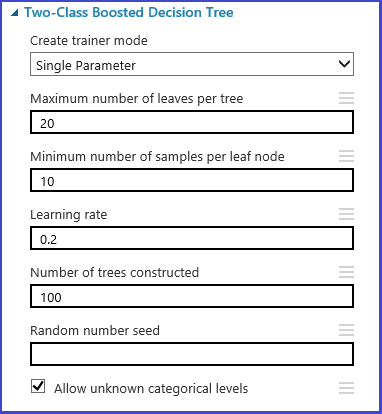
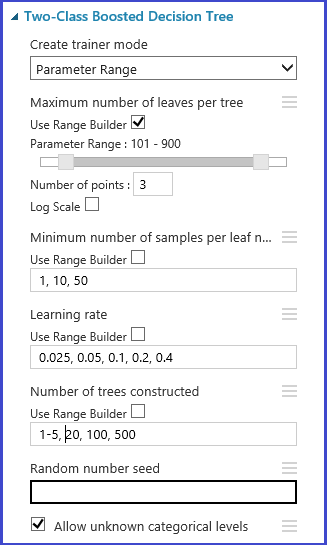
또는 범위 작성기 사용을 사용하여 그리드의 최대 및 최소 요소 수와 생성할 총 요소 수를 정의할 수 있습니다. 기본적으로 매개 변수 값은 선형 눈금으로 생성됩니다. 그러나 로그 규모 상자를 선택한 경우에는 로그 규모에서 값이 생성됩니다(즉, 인접 요소의 비율이 차이가 나지 않고 일정함). 정수 매개 변수의 경우 하이픈을 사용하여 범위를 정의할 수 있습니다. 예를 들어, '1-10'은 1부터 10까지의 모든 정수가 매개 변수 집합을 형성함을 의미합니다. 혼합 모드도 지원됩니다. 예를 들어, '1-10, 20, 50'으로 설정된 매개 변수는 정수 1~10, 20, 50을 포함합니다.
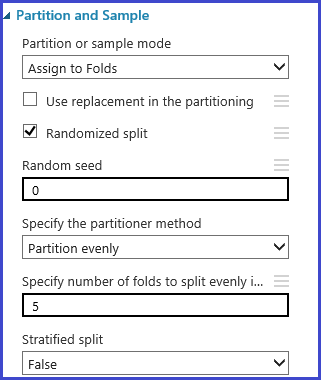
교차 유효성 검사 접기 정의
파티션 및 샘플 모듈을 사용하여 데이터에 접기 수를 임의로 할당할 수 있습니다. 모듈에 대한 다음 샘플 구성에는 다섯 번 접기를 정의하고 샘플 인스턴스에 접기 수를 임의로 할당합니다.
메트릭 정의
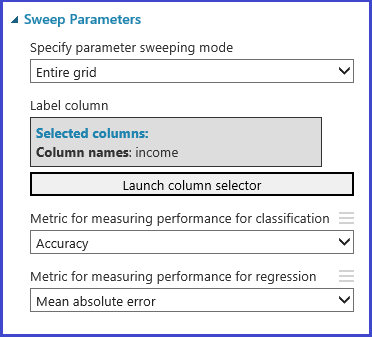
모델 조정 하이퍼 매개 변수 모듈에서는 주어진 알고리즘 및 데이터 세트에 대한 최상의 매개 변수 집합을 경험적으로 선택할 수 있습니다. 이 모듈의 속성 창에는 모델 학습에 관련된 기타 정보 외에 최상의 매개 변수 집합을 결정하는 데 사용할 메트릭이 포함됩니다. 분류 및 회귀 알고리즘 각각에 대한 두 개의 드롭다운 목록 상자가 있습니다. 고려 중인 알고리즘은 분류 알고리즘인 경우에는 회귀 메트릭이 무시되고 그 반대의 경우도 마찬가지입니다. 이 특정 예제에서는 메트릭은 정확도입니다.
학습, 평가 및 비교
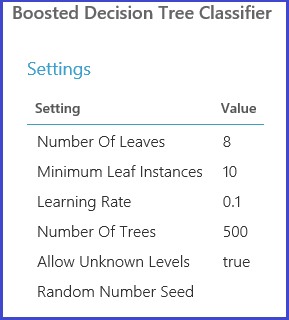
동일한 Tune Model Hyperparameters 모듈이 매개 변수 집합에 해당하는 모든 모델을 학습하고, 여러 메트릭을 평가한 다음, 선택한 메트릭을 기반으로 최상의 학습된 모델을 만듭니다. 이 모듈에는 다음 두 개의 필수 입력이 있습니다.
- 미숙한 학습자
- 데이터 세트
또한 이 모듈은 선택적 데이터 세트 입력을 포함하고 있습니다. 접기 정보가 있는 데이터 세트를 필수 데이터 세트 입력에 연결합니다. 데이터 세트에 접기 정보가 할당되지 않은 경우에는 기본적으로는 10번 접기 교차 유효성 검사가 자동으로 실행됩니다. 접기 할당이 수행되지 않고 유효성 검사 데이터 세트가 최적의 데이터 세트 포트에서 제공된 경우에는 학습 테스트 모드가 선택되고 첫 번째 데이터 세트가 각 매개 변수 조합에 대한 모델의 학습에 사용됩니다.
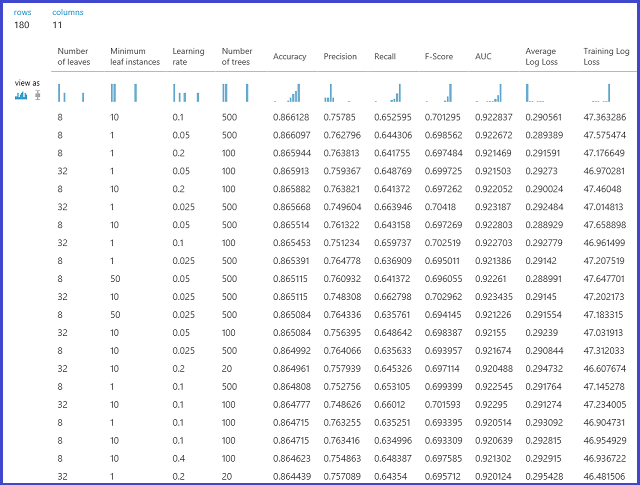
이 모델은 유효성 검사 데이터 세트에서 평가됩니다. 모듈의 왼쪽 출력 포트에는 매개 변수 값 함수로 다양한 메트릭이 표시됩니다. 오른쪽 출력 포트에는 선택한 메트릭(이 예의 경우 정확도)에 따라 최고 성능의 모델에 해당하는 학습된 모델이 제공됩니다.
오른쪽 출력 포트를 시각화하여 선택한 정확한 매개 변수를 확인할 수 있습니다. 이 모델은 테스트 집합을 채점하거나 학습된 모델로 저장한 후 조작 가능한 웹 서비스를 제공하는 데 사용될 수 있습니다.