빠른 시작: Azure Databricks를 사용하여 관리형 Apache Spark 클러스터 배포
Apache Cassandra용 Azure Managed Instance는 관리형 오픈 소스 Apache Cassandra 데이터 센터의 자동화된 배포 및 크기 조정 작업을 제공합니다. 이 기능은 하이브리드 시나리오를 가속화하고 지속적인 유지 관리를 줄입니다.
이 빠른 시작에서는 Azure Portal을 사용하여 Apache Cassandra용 Azure Managed Instance 클러스터의 Azure Virtual Network 내부에 완전 관리형 Apache Spark 클러스터를 만드는 방법을 보여줍니다. Azure Databricks에서 Spark 클러스터를 만들 것입니다. 나중에 Notebook을 만들거나 클러스터에 연결하고, 여러 데이터 원본의 데이터를 읽고, 인사이트를 분석할 수 있습니다.
또한 Azure Virtual Network(Virtual Network Injection)에 Azure Databricks 배포 방법에 대한 자세한 지침을 알아볼 수 있습니다.
필수 조건
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
Azure Databricks 클러스터 만들기
다음 단계에 따라 Virtual Network에 Apache Cassandra용 Azure Managed Instance가 있는 Azure Databricks 클러스터를 만듭니다.
Azure Portal에 로그인합니다.
왼쪽의 탐색 창에서 리소스 그룹을 찾습니다. 관리형 인스턴스가 배포된 Virtual Network를 포함하고 있는 리소스 그룹으로 이동합니다.
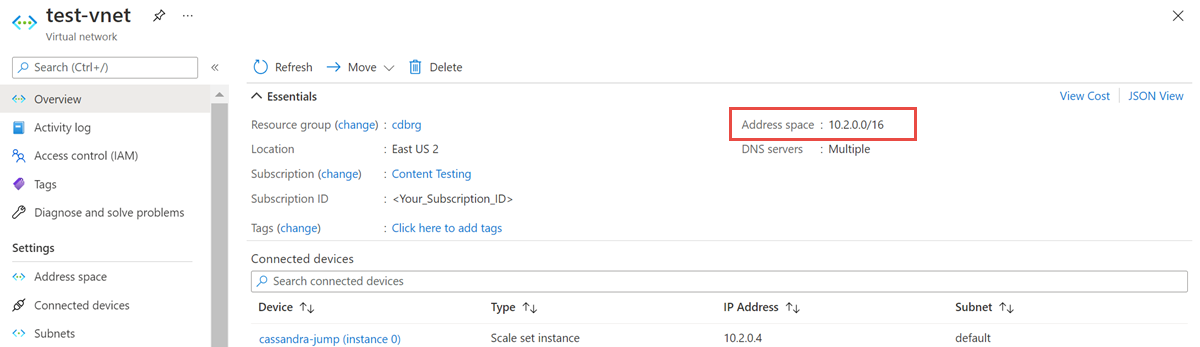
Virtual Network 리소스를 열고 주소 공간을 적어 둡니다.
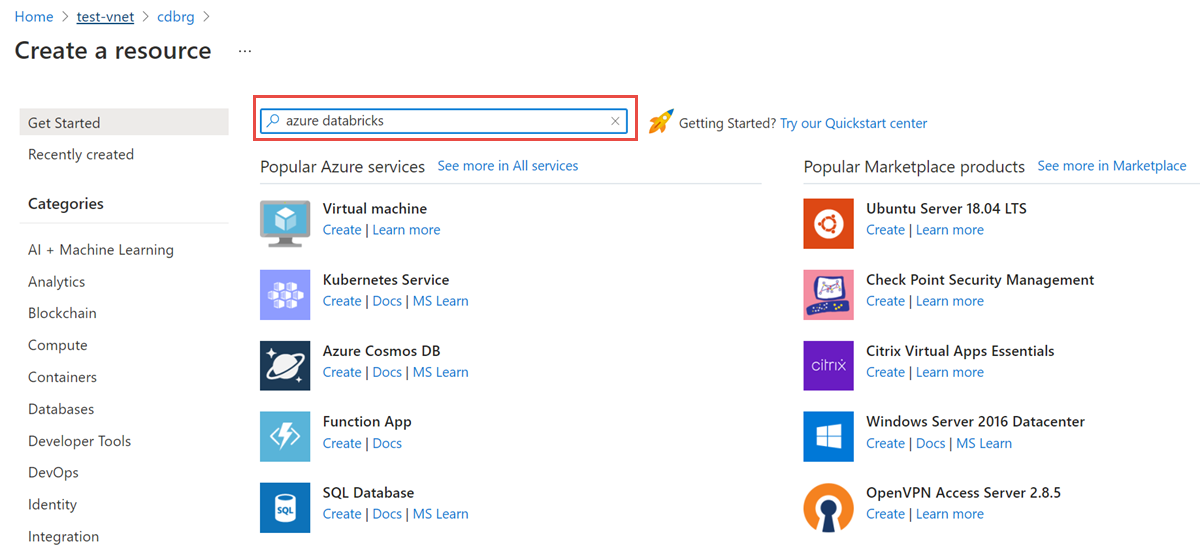
리소스 그룹에서 추가를 선택하고, 검색 필드에서 Azure Databricks를 검색합니다.
만들기를 선택하여 Azure Databricks 계정을 만듭니다.
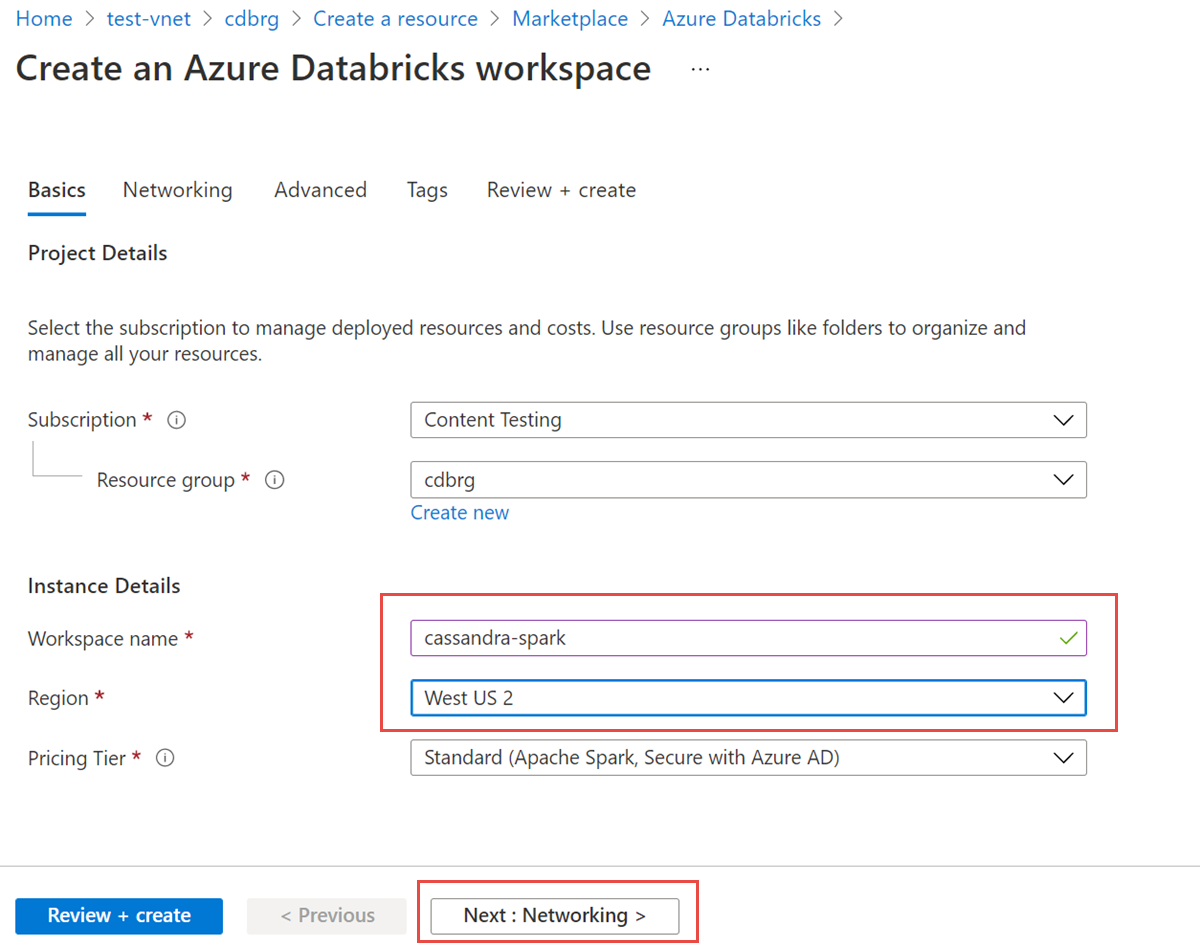
다음 값을 입력합니다.
- 작업 영역 이름 - Databricks 작업 영역의 이름을 입력합니다.
- 지역 - Virtual Network와 동일한 지역을 선택해야 합니다.
- 가격 책정 계층 - 표준, 프리미엄, 평가판 중에 선택합니다. 이러한 계층에 대한 자세한 내용은 Databricks 가격 페이지를 참조하세요.
다음으로 네트워킹 탭을 선택하고 다음 세부 정보를 입력합니다.
- VNet(Virtual Network)에 Azure Databricks 작업 영역 배포 - 예를 선택합니다.
- Virtual Network - 드롭다운에서 관리형 인스턴스가 있는 Virtual Network를 선택합니다.
- 퍼블릭 서브넷 이름 - 퍼블릭 서브넷의 이름을 입력합니다.
- 퍼블릭 서브넷 CIDR 범위 - 퍼블릭 서브넷의 IP 범위를 입력합니다.
- 프라이빗 서브넷 이름 - 프라이빗 서브넷의 이름을 입력합니다.
- 프라이빗 서브넷 CIDR 범위 - 프라이빗 서브넷의 IP 범위를 입력합니다.
범위가 충돌하지 않도록 더 높은 범위를 선택합니다. 필요한 경우 시각적 서브넷 계산기를 사용하여 범위를 나눕니다.
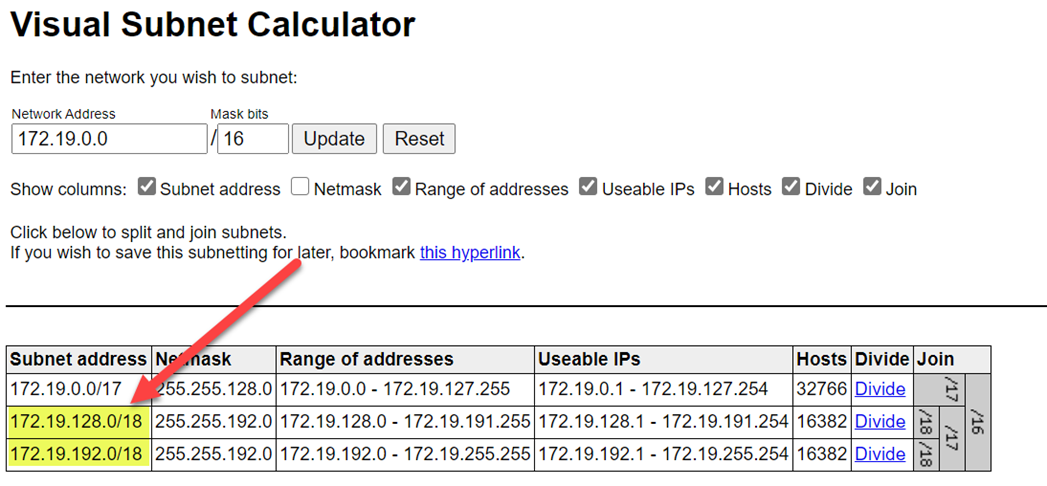
다음 스크린샷에서는 네트워킹 창의 세부 정보 예제를 보여줍니다.
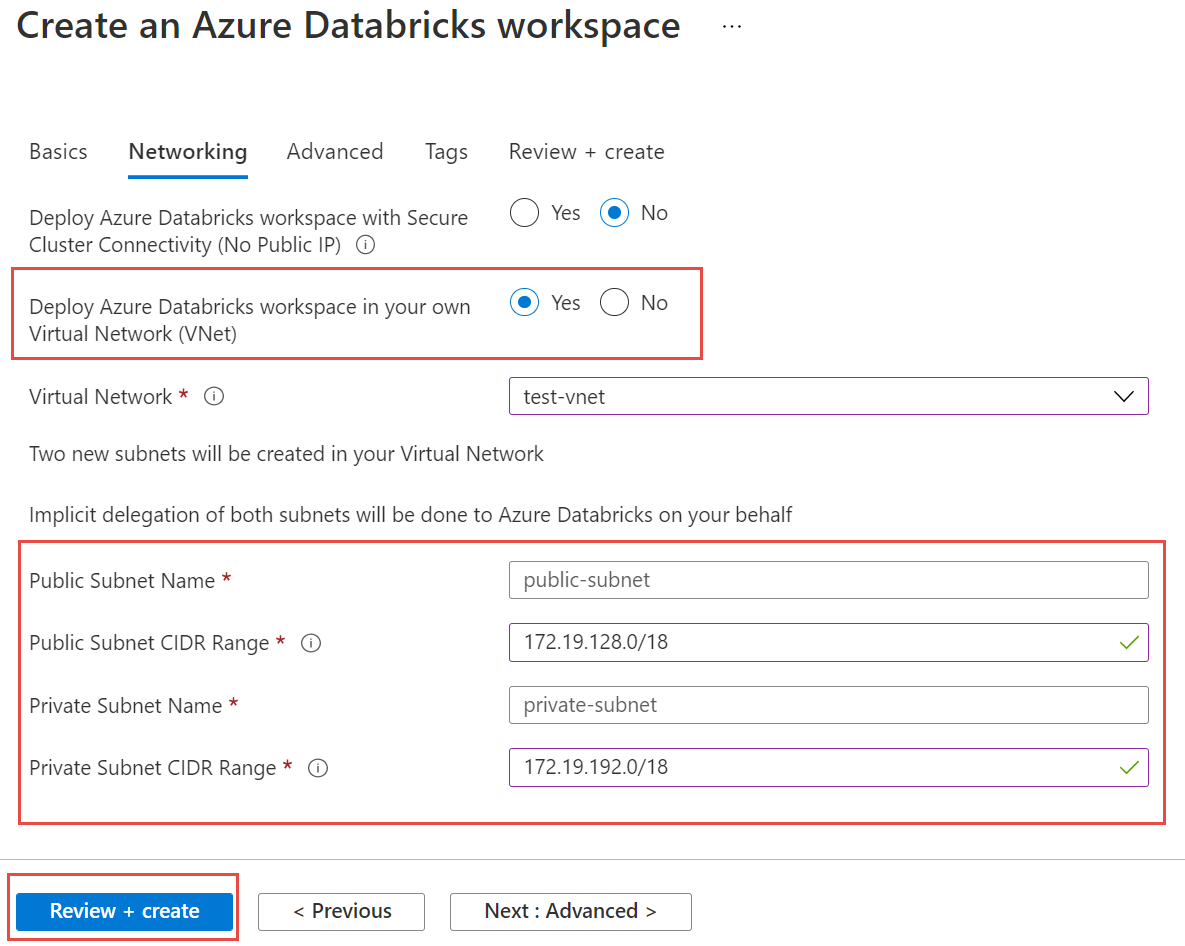
검토 및 만들기를 선택하고 만들기를 선택하여 작업 영역을 배포합니다.
작업 영역이 만들어지면 작업 영역을 시작합니다.
Azure Databricks 포털로 리디렉션됩니다. 포털에서 새 클러스터를 선택합니다.
새 클러스터 창에서 다음 필드를 제외한 모든 필드의 기본값을 그대로 적용합니다.
- 클러스터 이름 - 클러스터 이름을 입력합니다.
- Databricks Runtime 버전 - Spark 3.x 지원을 위해 Databricks 런타임 버전 7.5 이상을 선택하는 것이 좋습니다.

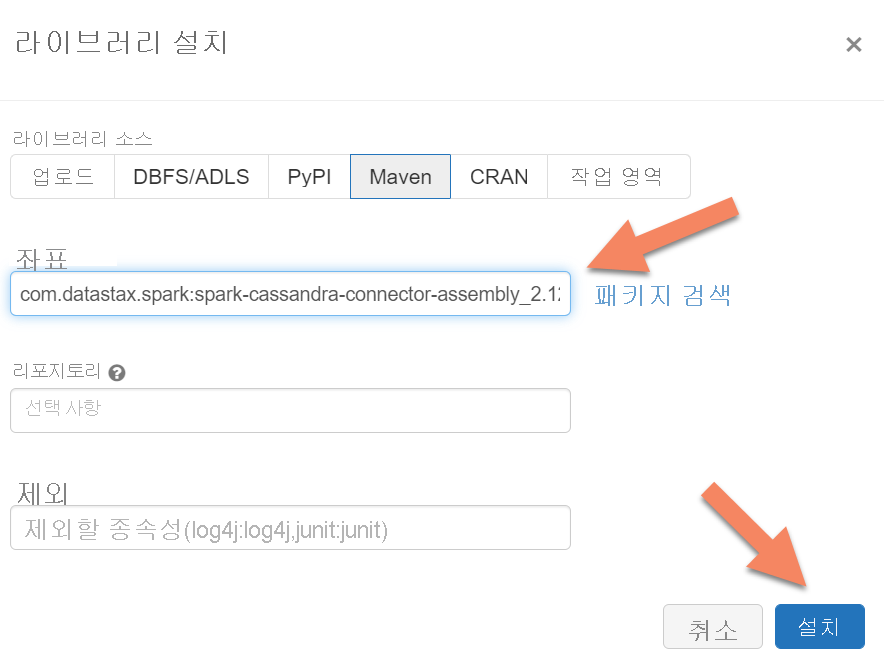
고급 옵션을 확장하고 다음 구성을 추가합니다. 다음과 같이 노드 IP 및 자격 증명을 바꿉니다.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueApache Spark Cassandra 커넥터 라이브러리를 클러스터에 추가하여 네이티브 및 Azure Cosmos DB Cassandra 엔드포인트 모두에 연결합니다. 클러스터에서 라이브러리>새로 설치>Maven을 선택한 다음 Maven 좌표에
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0을 추가합니다.
리소스 정리
이 관리형 인스턴스 클러스터를 더 이상 사용하지 않으려면 다음 단계에 따라 삭제합니다.
- Azure Portal의 왼쪽 메뉴에서 리소스 그룹을 선택합니다.
- 목록에서 이 빠른 시작에서 만든 리소스 그룹을 선택합니다.
- 리소스 그룹 개요 창에서 리소스 그룹 삭제를 선택합니다.
- 새 창에서 삭제할 리소스 그룹의 이름을 입력한 다음, 삭제를 선택합니다.
다음 단계
이 빠른 시작에서는 Apache Cassandra용 Azure Managed Instance 클러스터의 Virtual Network 내부에 완전 관리형 Apache Spark 클러스터를 만드는 방법을 알아보았습니다. 이제 클러스터 및 데이터 센터 리소스를 관리하는 방법을 배울 수 있습니다.