예: Azure Machine Learning을 사용하여 사용자 지정 기술 빌드 및 배포(보관됨)
이 예제는 보관되고 지원되지 않습니다. Azure Machine Learning을 사용하여 사용자 지정 기술을 만들어 리뷰에서 측면 기반 감정을 추출하는 방법을 설명했습니다. 이를 통해 동일한 검토 내에서 긍정적 및 부정적 감정을 직원, 회의실, 로비 또는 수영장과 같은 식별된 엔터티에 올바르게 할당할 수 있었습니다.
Azure Machine Learning에서 양상 기반 감정 모델을 학습하기 위해 nlp 레시피 리포지토리를 사용합니다. 그러면 모델이 Azure Kubernetes 클러스터에 엔드포인트로 배포됩니다. 배포되면 엔드포인트가 Cognitive Search 서비스에서 사용할 수 있도록 AML 기술로 보강 파이프라인에 추가됩니다.
두 가지 데이터 세트가 제공됩니다. 모델을 직접 학습시키려면 hotel_reviews_1000.csv 파일이 필요합니다. 학습 단계를 건너뛰려면 hotel_reviews_100.csv 파일을 다운로드합니다.
- Azure Cognitive Search 인스턴스 만들기
- Azure Machine Learning 작업 영역 만들기(검색 서비스 및 작업 영역은 동일한 구독에 있어야 함)
- 모델을 학습시키고 Azure Kubernetes 클러스터에 배포
- AI 보강 파이프라인을 배포된 모델에 연결
- 배포된 모델의 출력을 사용자 지정 기술로 수집
중요
이 기술은 추가 사용 약관에 따라 퍼블릭 미리 보기 상태입니다. 미리 보기 REST API에서 이 기술을 지원합니다.
필수 구성 요소
- Azure 구독 - 체험판 구독을 다운로드합니다.
- Cognitive Search 서비스
- Cognitive Services 리소스
- Azure Storage 계정)
- Azure Machine Learning 작업 영역
설치 프로그램
- 샘플 리포지토리의 콘텐츠를 복제하거나 다운로드합니다.
- 다운로드 파일이 Zip 파일인 경우 콘텐츠를 추출합니다. 파일이 읽기/쓰기 파일인지 확인합니다.
- Azure 계정과 서비스를 설정하는 동안 쉽게 액세스할 수 있는 텍스트 파일에 이름과 키를 복사합니다. Azure 서비스에 액세스하기 위한 변수가 정의된 노트북의 첫 번째 셀에 이름과 키가 추가됩니다.
- Azure Machine Learning 및 요구 사항에 아직 익숙하지 않은 경우 시작하기 전에 다음 문서를 검토하세요.
- Azure Machine Learning용 개발 환경 구성
- Azure Portal에서 Azure Machine Learning 작업 영역 만들기 및 관리
- Azure Machine Learning 개발 환경을 구성할 때 클라우드 기반 컴퓨팅 인스턴스를 사용하면 더 빠르고 쉽게 시작할 수 있습니다.
- 데이터 세트 파일을 스토리지 계정의 컨테이너에 업로드합니다. 학습 단계를 Notebook에서 수행하려면 더 큰 파일이 필요합니다. 학습 단계를 건너뛰려면 더 작은 파일을 사용하는 것이 좋습니다.
Notebook을 열고 Azure 서비스에 연결
- 첫 번째 셀 내에서 Azure 서비스에 액세스하기 위해 필요한 모든 변수 정보를 입력하고 셀을 실행합니다.
- 두 번째 셀을 실행하면 구독에 대한 검색 서비스에 연결되어 있다는 확인 메시지가 표시됩니다.
- 섹션 1.1-1.5에서는 검색 서비스 데이터 저장소, 기술 세트, 인덱스 및 인덱서를 만듭니다.
지금은 학습 데이터 세트를 만드는 단계와 Azure Machine Learning에서 실험하는 단계를 건너뛰고, GitHub 리포지토리의 모델 폴더에 제공된 두 모델을 등록하는 단계로 넘어갈 수 있습니다. 이러한 단계를 건너뛰면 Notebook에서 섹션 3.5 채점 스크립트 작성으로 건너뛰게 됩니다. 이렇게 하면 시간이 절약됩니다. 데이터 다운로드 및 업로드 단계를 완료하는 데 최대 30분이 걸릴 수 있습니다.
모델 만들기 및 학습
섹션 2에는 nlp 레시피 리포지토리에서 글러브 임베딩 파일을 다운로드하는 6개 셀이 있습니다. 다운로드 후 이 파일은 Azure Machine Learning 데이터 저장소에 업로드됩니다. .zip 파일은 약 2G이며 이 작업을 수행하는 데 다소 시간이 걸립니다. 파일이 업로드된 후에는 학습 데이터가 추출되고 섹션 3을 진행할 수 있습니다.
양상 기반 감정 모델을 학습시키고 엔드포인트 배포
Notebook의 섹션 3에서는 섹션 2에서 만든 모델을 학습시키고, 해당 모델을 등록하고, Azure Kubernetes 클러스터에 엔드포인트로 배포합니다. Azure Kubernetes에 익숙하지 않은 경우 유추 클러스터를 만들기 전에 다음 문서를 검토하는 것이 좋습니다.
- Azure Kubernetes 서비스 개요
- AKS(Azure Kubernetes Service)의 Kubernetes 핵심 개념
- AKS(Azure Kubernetes Service)의 할당량, 가상 머신 크기 제한 및 지역 가용성
유추 클러스터를 만들고 배포하는 데 최대 30분이 걸릴 수 있습니다. 마지막 단계로 넘어가기 전에 웹 서비스를 테스트하고 기술을 업데이트하고 인덱서를 실행하는 것이 좋습니다.
기술 세트 업데이트
Notebook의 섹션 4에는 기술 세트와 인덱서를 업데이트하는 4개의 셀이 있습니다. 또는 포털을 사용하여 새 기술을 선택하고 기술 세트에 적용한 다음, 인덱서를 실행하여 검색 서비스를 업데이트할 수도 있습니다.
포털에서 기술 기술로 이동하여 기술 세트 정의(JSON) 링크를 선택합니다. Notebook의 첫 번째 셀에서 만든 기술 세트의 JSON이 포털에 표시됩니다. 디스플레이 오른쪽에는 기술 정의 템플릿을 선택할 수 있는 드롭다운 메뉴가 있습니다. AML(Azure Machine Learning) 템플릿을 선택합니다. Azure ML 작업 영역의 이름과 유추 클러스터에 배포할 모델의 엔드포인트를 입력합니다. 템플릿이 이 엔드포인트 uri와 키로 업데이트됩니다.
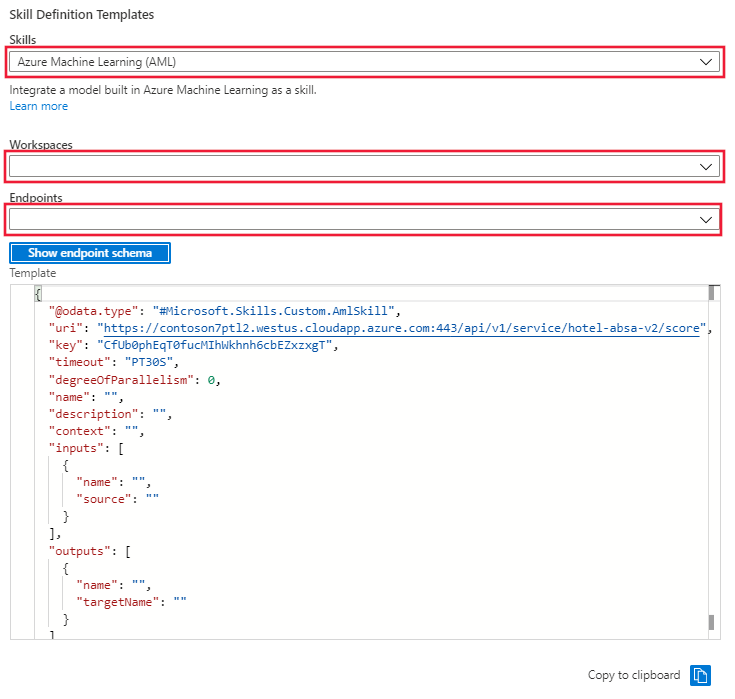
창에서 기술 세트 템플릿을 복사하여 왼쪽의 기술 세트 정의에 붙여넣습니다. 템플릿을 편집하여 누락된 다음 값을 입력합니다.
- Name
- Description
- Context
- '입력' 이름 및 원본
- '출력' 이름 및 targetName
기술 세트를 저장합니다.
기술 세트를 저장한 후에는 인덱서로 이동하여 인덱서 정의(JSON) 링크를 선택합니다. Notebook의 첫 번째 셀에서 만든 인덱서의 JSON이 포털에 표시됩니다. 인덱서가 매핑을 올바르게 처리하고 전달할 수 있도록 출력 필드 매핑을 추가 필드 매핑으로 업데이트해야 합니다. 변경 내용을 저장하고 [실행]을 선택합니다.
리소스 정리
본인 소유의 구독으로 이 모듈을 진행하고 있는 경우에는 프로젝트가 끝날 때 여기서 만든 리소스가 계속 필요한지 확인하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
왼쪽 탐색 창의 모든 리소스 또는 리소스 그룹 링크를 사용하여 포털에서 리소스를 찾고 관리할 수 있습니다.
무료 서비스를 사용하는 경우 인덱스, 인덱서, 데이터 원본 세 개로 제한됩니다. 포털에서 개별 항목을 삭제하여 제한 이하로 유지할 수 있습니다.