Azure AI 검색의 전체 텍스트 검색
전체 텍스트 검색은 인덱스에 저장된 일반 텍스트와 일치하는 정보 검색 방식입니다. 예를 들어, "샌디에이고 해변의 호텔"이라는 쿼리 문자열이 주어지면 검색 엔진은 해당 용어를 기반으로 토큰화된 문자열을 찾습니다. 검사를 보다 효율적으로 수행하기 위해 쿼리 문자열은 어휘 분석을 거칩니다. 즉, 모든 용어를 소문자로 바꾸고, "the"와 같은 불용어를 제거하고, 용어를 기본 어근 형태로 줄입니다. 일치하는 용어가 발견되면 검색 엔진은 문서를 검색하고 관련성 순으로 순위를 매긴 다음 상위 결과를 반환합니다.
쿼리 실행은 복잡할 수 있습니다. 이 문서는 Azure AI 검색에서 전체 텍스트 검색이 작동하는 방식을 더 깊이 이해해야 하는 개발자를 위한 것입니다. 텍스트 쿼리의 경우 Azure AI 검색은 대부분의 시나리오에서 예상된 결과를 원활하게 제공하지만, 가끔은 "예상과 다른" 결과를 얻기도 합니다. 이러한 상황에서는 Lucene 쿼리 실행의 네 단계(쿼리 구문 분석, 어휘 분석, 문서 일치, 점수 매기기)에 대한 배경 지식을 갖고 있으면 쿼리 매개 변수의 특정 변경 내용 또는 원하는 결과를 생산하는 인덱스 구성을 식별하는 데 도움이 될 수 있습니다.
참고 항목
Azure AI 검색은 전체 텍스트 검색에 Apache Lucene을 사용하지만 Lucene이 완전히 통합된 것은 아닙니다. Azure AI 검색에 중요한 시나리오를 지원하도록 Lucene 기능을 선별적으로 노출하고 확장합니다.
아키텍처 개요 및 다이어그램
쿼리 실행은 다음과 같은 네 단계로 구성됩니다.
- 쿼리 구문 분석
- 어휘 분석
- 문서 검색
- 점수 매기기
전체 텍스트 검색 쿼리는 쿼리 텍스트를 구문 분석하여 검색 용어 및 연산자를 추출하는 작업부터 시작합니다. 속도와 복잡성 중에서 선택할 수 있도록 두 개의 파서가 있습니다. 그다음에는 개별 쿼리 용어를 분석하여 새로운 형식으로 재구성하는 분석 단계가 있습니다. 이 단계는 잠재적인 일치로 간주될 수 있는 항목에 대해 더 넓은 범위를 조사하는 데 도움이 됩니다. 그런 다음 검색 엔진은 인덱스를 검사하여 일치하는 용어가 포함된 문서를 찾고 각 일치에 점수를 매깁니다. 그런 다음 각 개별 일치 문서에 할당된 관련성 점수를 기준으로 결과 집합을 정렬합니다. 순위 목록 맨 위에 있는 항목은 호출 애플리케이션으로 반환됩니다.
아래 다이어그램은 검색 요청을 처리하는 데 사용되는 구성 요소를 보여 줍니다.
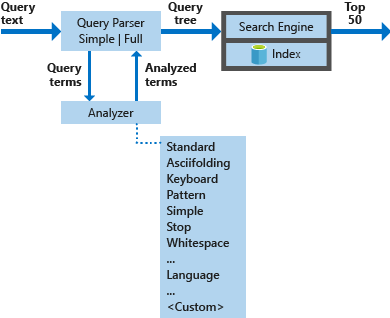
| 핵심 구성 요소 | 기능 설명 |
|---|---|
| 쿼리 파서 | 쿼리 연산자에서 쿼리 용어를 분리하고 검색 엔진에 전송할 쿼리 구조(쿼리 트리)를 만듭니다. |
| 분석기 | 쿼리 용어에 대한 어휘 분석을 수행합니다. 이 프로세스에는 쿼리 용어의 변환, 제거 또는 확장이 포함될 수 있습니다. |
| Index | 인덱싱된 문서에서 추출된 검색 가능한 용어를 저장하고 정리하는 데 사용되는 효율적인 데이터 구조입니다. |
| 검색 엔진 | 반전된 인덱스의 내용을 기준으로 일치하는 문서를 검색하고 점수를 매깁니다. |
검색 요청 분석
검색 요청은 결과 집합에 반환할 완전한 규격입니다. 가장 간단한 형태는 어떠한 조건도 없는 빈 쿼리입니다. 보다 현실적인 예로는 매개 변수 및 몇몇 쿼리 용어가 있습니다. 경우에 따라 검색 범위가 특정 필드로 지정되거나 필터 식과 정렬 규칙을 사용할 수도 있습니다.
다음 예는 REST API를 사용하여 Azure AI 검색으로 보낼 수 있는 검색 요청입니다.
POST /indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
이 요청의 경우 검색 엔진이 다음 작업을 수행합니다.
가격이 $60 이상 $300 미만인 문서를 찾습니다.
쿼리를 실행합니다. 이 예제의 검색 쿼리는 다음과 같은 구와 용어로 구성되어 있습니다.
"Spacious, air-condition* +\"Ocean view\""(일반적으로는 사용자가 문장 부호를 입력하지 않지만, 이 예에서는 분석기가 문장 부호를 어떻게 처리하는지 설명하기 위해 문장 부호를 포함함).이 쿼리에서 검색 엔진은
"Ocean view"가 포함된 문서를 찾기 위해 “searchFields”에 지정된 설명 및 제목 필드를 검색하고, 추가적으로 용어"spacious"또는 접두사"air-condition"으로 시작하는 용어도 검색합니다. “searchFields” 매개 변수는 용어가 명시적으로 필요하지 않은 경우(+)에 일부 일치(기본값) 또는 전체 일치에 사용됩니다.호텔 검색 결과 집합을 특정 지리적 위치에 가까운 순서대로 정렬한 후 호출 애플리케이션에 결과를 반환합니다.
이 문서의 대부분은 검색 쿼리: "Spacious, air-condition* +\"Ocean view\""의 처리에 대한 내용입니다. 필터링 및 정렬은 본 문서에서 다루지 않습니다. 자세한 내용은 검색 API 참조 문서를 참조하세요.
1단계: 쿼리 구문 분석
앞서 설명했듯이, 쿼리 문자열은 요청의 첫 번째 줄입니다.
"search": "Spacious, air-condition* +\"Ocean view\"",
쿼리 파서는 검색 용어에서 예제의 * 및 + 같은 연산자를 분리하고, 검색 쿼리를 지원되는 유형의 하위 쿼리로 분해합니다.
- 독립 용어(예: spacious)에 대한 용어 쿼리
- 따옴표가 붙은 용어(예: ocean view)에 대한 구 쿼리
- 뒤에
*접두사 연산자가 붙는 용어(예: air-condition)에 대한 접두사 쿼리
지원되는 쿼리 유형의 전체 목록은 Lucene 쿼리 구문을 참조하세요.
하위 쿼리와 관련된 연산자는 문서를 일치 항목으로 간주하려면 쿼리를 "반드시 만족"해야 하는지 아니면 "만족하면 더 좋은지" 여부를 결정합니다. 예를 들어 +"Ocean view"에 + 연산자가 붙었기 때문에 "반드시" 만족되어야 합니다.
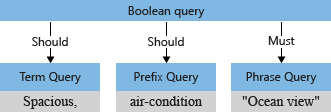
쿼리 파서는 하위 쿼리를 검색 엔진으로 전달하는 쿼리 트리(쿼리를 나타내는 내부 구조)로 재구성합니다. 쿼리 구문 분석의 첫 번째 단계에서는 쿼리 트리가 다음과 같습니다.
지원되는 파서: 단순(simple) 및 전체(full) Lucene
Azure AI 검색은 두 가지 쿼리 언어인 simple(기본값)과 full을 노출합니다. 사용자는 검색 요청에서 queryType 매개 변수를 설정함으로써 쿼리 파서에 어떤 쿼리 언어를 사용하여 연산자와 구문을 해석해야 하는지 알려줍니다.
단순 쿼리 언어는 직관적이고 견고하며, 종종 클라이언트 측 처리 없이 사용자 입력을 있는 그대로 해석하는 데 적합합니다. 웹 검색 엔진과 비슷한 쿼리 연산자를 지원합니다.
queryType=full로 설정하면 사용할 수 있는 전체 Lucene 쿼리 언어는 와일드카드, 퍼지, regex, 필드 범위가 지정된 쿼리 등의 추가 연산자 및 쿼리 유형에 대한 지원을 추가하여 기본값인 단순 쿼리 언어를 확장합니다. 예를 들어 단순 쿼리 구문에서 전송되는 정규식은 식이 아닌 쿼리 문자열로 해석됩니다. 이 문서의 요청 예제에서는 전체 Lucene 쿼리 언어를 사용합니다.
searchMode가 파서에 미치는 영향
구문 분석에 영향을 주는 또 다른 검색 요청은 “searchMode” 매개 변수입니다. 이 매개 변수는 부울 쿼리의 기본 연산자인 일부(기본값) 또는 전체를 제어합니다.
기본값인 “searchMode”로 설정된 경우 spacious와 air-condition 사이의 공백 구분 기호는 OR(||)이며, 샘플 쿼리 텍스트는 다음과 같습니다.
Spacious,||air-condition*+"Ocean view"
+"Ocean view"의 + 같은 명시적 연산자는 부울 쿼리 구조에서 모호하지 않습니다(용어가 반드시 일치해야 함). 나머지 용어 spacious와 air-condition을 해석하는 방법은 덜 명확합니다. 검색 엔진이 ocean view 그리고 spacious 그리고 air-condition과 일치하는 항목을 찾아야 합니까? 아니면 ocean view와 나머지 두 용어 중 하나를 찾아야 합니까?
기본값으로(“searchMode=any”) 검색 엔진은 보다 광범위한 해석을 가정합니다. "or" 구문을 반영하여 두 필드 중 하나가 일치해야 합니다. 앞에서 보여드린 두 개의 "should" 연산이 사용된 초기 쿼리 트리는 기본값을 표시합니다.
이제 "searchMode=all"을 설정했다고 가정해보겠습니다. 이 경우 공간이 "and" 연산으로 해석됩니다. 나머지 두 용어가 모두 문서에 있어야만 일치 항목으로 인정됩니다. 결과 샘플 쿼리는 다음과 같이 해석됩니다.
+Spacious,+air-condition*+"Ocean view"
이 쿼리의 수정된 쿼리 트리는 다음과 같으며, 세 하위 쿼리가 교차하는 부분이 바로 일치하는 문서입니다.

참고 항목
“searchMode=all” 대신 “searchMode=any”를 선택하는 것이 대표 쿼리 실행에 의해 도달할 수 있는 최고의 결정입니다. 연산자를 포함할 가능성이 높은 사용자(문서 저장소를 검색할 때 일반적임)는 “searchMode=all”이 부울 쿼리 구문에 영향을 미치는 경우 좀 더 직관적인 결과를 얻을 수도 있습니다. “searchMode” 및 연산자 간의 상호 작용에 대한 자세한 내용은 단순 쿼리 구문을 참조하세요.
2단계: 어휘 분석
어휘 분석기는 쿼리 트리가 구조화된 후 용어 쿼리 및 구 쿼리를 처리합니다. 분석기는 파서에서 제공한 텍스트 입력을 수락하고, 해당 텍스트를 처리한 후 토큰화된 용어를 다시 보내서 쿼리 트리와 통합합니다.
어휘 분석의 가장 일반적인 형태는 지정된 언어와 관련된 규칙을 기반으로 쿼리 용어를 변환하는 *언어 분석입니다.
- 쿼리 용어를 단어의 루트 형식으로 줄이기
- 필수적이지 않은 단어(영어의 "the" 또는 "and" 같은 중지 단어) 제거
- 복합 단어를 구성 요소 부분으로 분리
- 대문자 단어를 소문자로 변환
이 모든 작업은 사용자가 제공한 텍스트 입력과 인덱스에 저장된 용어 사이의 차이점을 없애는 경향이 있습니다. 이러한 작업은 텍스트 처리에서 그치지 않으며 언어 자체에 대한 심도 있는 지식을 필요로 합니다. 이 언어적 인식 계층을 추가하기 위해 Azure AI 검색은 Lucene과 Microsoft의 긴 언어 분석기 목록을 지원합니다.
참고 항목
분석 요구 사항은 시나리오에 따라 최소한의 수준부터 복잡한 수준까지 달라질 수 있습니다. 미리 정의된 분석기 중 하나를 선택하거나 사용자 지정 분석기를 직접 만들어서 어휘 분석의 복잡성을 제어할 수 있습니다. 분석기는 필드 정의의 일부로 지정되며 분석기의 범위는 검색 가능한 필드입니다. 따라서 필드별로 어휘 분석을 다르게 할 수 있습니다. 분석기를 지정하지 않으면 표준 Lucene 분석기가 사용됩니다.
우리 예제에서는 분석에 앞서 초기 쿼리 트리에 "Spacious,"라는 용어가 있습니다. 대문자 "S"와 쿼리 파서가 쿼리 용어의 일부로 해석하는 쉼표(쉼표는 쿼리 언어 연산자로 간주되지 않음)가 사용되었습니다.
기본 분석기는 이 용어를 처리할 때 "ocean view" 및 "spacious"를 소문자로 변환하고 쉼표 문자를 제거합니다. 수정된 쿼리 트리는 다음과 같습니다.

분석기 동작 테스트
분석 API를 사용하여 분석기의 동작을 테스트할 수 있습니다. 분석하려는 텍스트를 제공하여 특정 분석기가 생성하는 용어를 확인합니다. 예를 들어 표준 분석기가 "air-condition"이라는 텍스트를 어떻게 처리하는지 살펴보려면 다음 요청을 실행하면 됩니다.
{
"text": "air-condition",
"analyzer": "standard"
}
표준 분석기는 입력 텍스트를 다음과 같은 두 토큰으로 분류하고, 위치(구 일치에 사용)뿐 아니라 시작 및 종료 오프셋(적중 항목 강조 표시에 사용) 같은 특성을 사용하여 주석을 답니다.
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
어휘 분석의 예외
어휘 분석은 완전한 용어가 필요한 쿼리 유형, 즉 용어 쿼리 또는 구 쿼리에만 적용됩니다. 불완전한 용어가 사용된 쿼리, 다시 말해서 접두사 쿼리, 와일드 카드 쿼리, regex 쿼리 또는 유사 항목 쿼리에는 적용되지 않습니다. 우리 예제의 air-condition*이라는 용어가 사용된 접두사 쿼리를 포함하여 이러한 쿼리 유형은 분석 단계를 건너뛰고 쿼리 트리에 직접 추가됩니다. 이러한 유형의 쿼리 용어에 수행되는 유일한 변환 작업은 소문자 변환입니다.
3단계: 문서 검색
문서 검색이란 인덱스에서 일치하는 용어가 포함된 문서를 찾는 것을 말합니다. 이 단계는 예를 통해 설명하는 것이 가장 빠릅니다. 다음과 같은 간단한 스키마를 가진 호텔 인덱스로 시작해 보겠습니다.
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
또한 이 인덱스에 다음과 같은 네 개 문서가 포함되어 있다고 가정하겠습니다.
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
용어 인덱싱 방식
인덱싱에 대한 몇 가지 기본 사항을 파악하면 검색을 이해하는 데 도움이 됩니다. 스토리지 단위는 반전된 인덱스이며, 검색 가능한 필드당 하나씩 있습니다. 반전된 인덱스 내에는 모든 문서의 모든 정렬된 용어 목록이 있습니다. 각 용어는 아래 예제처럼 각각 발생하는 문서 목록에 매핑됩니다.
반전된 인덱스에 용어를 생성하기 위해 검색 엔진은 쿼리 처리 중 발생하는 동작과 비슷하게 문서 내용에 대한 어휘 분석을 수행합니다.
- 텍스트 입력은 분석기 구성에 따라 분석기로 전달되고, 소문자로 변환되고, 문장 부호가 제거됩니다.
- 토큰은 어휘 분석의 출력입니다.
- 용어는 인덱스에 추가됩니다.
쿼리 용어가 인덱스 내 용어와 좀 더 비슷하게 보이도록 검색 작업과 인덱싱 작업에 같은 분석기를 사용하는 것이 일반적이지만 필수는 아닙니다.
참고 항목
Azure AI 검색은 추가적인 indexAnalyzer 및 searchAnalyzer 필드 매개 변수를 통해 인덱싱 및 검색에 서로 다른 분석기를 지정할 수 있습니다. 분석기를 지정하지 않으면 analyzer 속성을 통해 설정된 분석기가 인덱싱과 검색에 모두 사용됩니다.
예제 문서의 반전된 인덱스
예제로 돌아가서, 제목 필드의 경우 반전된 인덱스는 다음과 같습니다.
| 용어 | 문서 목록 |
|---|---|
| atman | 1 |
| beach | 2 |
| hotel | 1, 3 |
| ocean | 4 |
| playa | 3 |
| resort | 3 |
| retreat | 4 |
제목 필드에서는 오직 hotel만 1, 3 문서에 표시됩니다.
설명 필드의 경우 인덱스는 다음과 같습니다.
| 용어 | 문서 목록 |
|---|---|
| air | 3 |
| 및 | 4 |
| beach | 1 |
| conditioned | 3 |
| comfortable | 3 |
| 거리 | 1 |
| island | 2 |
| kauaʻi | 2 |
| located | 2 |
| north | 2 |
| ocean | 1, 2, 3 |
| 의 | 2 |
| On | 2 |
| quiet | 4 |
| rooms | 1, 3 |
| secluded | 4 |
| 바닷가 | 2 |
| spacious | 1 |
| the | 1, 2 |
| to | 1 |
| view | 1, 2, 3 |
| walking | 1 |
| 다음과 같이 바꿉니다. | 3 |
쿼리 용어를 인덱싱된 용어와 연결
위의 반전된 인덱스를 전제로, 샘플 쿼리로 돌아가서 쿼리 예와 일치하는 문서를 어떻게 찾아내는지 살펴보겠습니다. 최종 쿼리 트리는 다음과 같다고 했습니다.
쿼리가 실행되는 동안, 검색 가능한 필드에 대해 개별 쿼리가 독립적으로 실행됩니다.
TermQuery "spacious"는 문서 1(Hotel Atman)과 일치합니다.
PrefixQuery "air-condition*"은 일치하는 문서가 없습니다.
이는 종종 개발자를 혼란스럽게 만드는 동작입니다. air-conditioned라는 용어가 문서에 있기는 하지만 이 용어는 기본 분석기에서 두 개 용어로 분할됩니다. 앞에서 부분 용어를 포함한 접두사 쿼리는 분석되지 않았던 것을 떠올려 보세요. 따라서 접두사 "air-condition"을 포함하는 용어는 반전된 인덱스에서 조회되지만 찾을 수 없었습니다.
PhraseQuery "ocean view"는 용어 "ocean"과 "view"를 조회하며 원래 문서에서 용어의 근접도를 확인합니다. 문서 1, 2, 3은 설명 필드가 이 쿼리와 일치합니다. 문서 4는 제목에 용어 ocean이 있지만 일치 항목으로 간주되지 않습니다. 쿼리에서 찾는 것이 개별 단어가 아닌 "ocean view"라는 구이기 때문입니다.
참고 항목
검색 요청 예에서 보여드린 것처럼 searchFields 매개 변수를 사용하여 필드 집합을 제한하지 않는 이상, 검색 쿼리는 Azure AI 검색 인덱스의 모든 검색 가능 필드에 대해 독립적으로 실행됩니다. 선택한 필드 중 아무 필드와 일치하는 문서가 반환됩니다.
전체적으로 볼 때, 예제의 쿼리와 일치하는 문서는 1, 2, 3입니다.
4단계: 점수 매기기
검색 결과 집합의 모든 문서에 관련성 점수가 할당됩니다. 관련성 점수의 기능은 검색 쿼리의 표현에 따라 사용자 질문에 가장 잘 대답한 문서에 더 높은 순위를 매기는 것입니다. 점수는 일치하는 용어의 통계 속성에 따라 계산됩니다. 점수 매기기 공식의 핵심은 TF/IDF(term frequency-inverse document frequency)입니다. 드문 용어와 일반적인 용어가 포함된 쿼리에서, TF/IDF는 드문 용어가 포함된 결과에 더 높은 순위를 부여합니다. 예를 들어 모든 Wikipedia 문서가 포함된 가상의 인덱스에서 the president 쿼리와 일치하는 문서의 경우 president와 일치하는 문서는 the와 일치하는 문서보다 관련성이 높은 것으로 간주됩니다.
점수 매기기 예제
앞에서 예제 쿼리와 일치한 세 문서를 떠올려 보세요.
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
문서 1이 쿼리와 가장 정확하게 일치했습니다. spacious라는 용어와 ocean view라는 필수 구가 설명 필드에서 모두 발생했기 때문입니다. 그 다음 두 문서는 ocean view라는 구만 일치합니다. 문서 2와 3이 동일한 방식으로 쿼리와 일치하는데 관련성 점수는 서로 다르다는 점에 놀라실 수도 있습니다. 이는 점수 매기기 공식에 TF/IDF 외에도 여러 구성 요소가 더 있기 때문입니다. 이 예에서는 문서 3에 약간 더 높은 점수가 할당되었는데, 설명이 좀 더 짧기 때문입니다. 필드 길이 및 기타 요소가 관련성 점수에 미치는 영향에 대해 자세히 알아보려면 Lucene의 실제 점수 매기기 공식을 살펴보세요.
일부 쿼리 유형(와일드카드, 접두사, regex)은 전체적인 문서 점수에 항상 상수 점수를 부여합니다. 따라서 쿼리 확장을 통해 검색된 일치 항목이 결과에는 포함되지만 순위에는 영향을 주지 않습니다.
이것이 왜 중요한지 예제를 통해 살펴보겠습니다. 접두사 검색을 포함한 와일드카드 검색은 기본적으로 모호할 수밖에 없습니다. 왜냐하면 그 입력이 수많은 다른 용어와 일치할 가능성이 있는 부분 문자열이기 때문입니다(예를 들어 "tour*"를 입력하면 “tours”, “tourettes”, “tourmaline”이 전부 일치 항목으로 검색됨). 이러한 결과의 특성을 감안할 때, 어떤 용어가 더 중요한지 합리적으로 유추할 방법이 없습니다. 이러한 이유로 와일드카드, 접두사, regex 쿼리 유형의 결과에 대한 점수를 매길 때에는 용어 빈도를 무시합니다. 부분 용어와 완전한 용어가 포함된 다중 파트 검색 요청에서 부분 입력의 결과는 예상치 않은 일치 항목 가능성을 방지하기 위해 상수 점수와 통합됩니다.
관련성 튜닝
Azure AI 검색에서 관련성 점수를 조정하는 방법에는 두 가지가 있습니다.
점수 매기기 프로필은 규칙 집합을 기준으로 순위가 지정된 결과 목록에서 문서를 승격합니다. 이 문서의 예제에서는 제목 필드와 일치하는 문서가 설명 필드와 일치하는 문서보다 관련성이 높은 것으로 간주할 수 있습니다. 뿐만 아니라 만약 인덱스에 각 호텔의 가격 필드가 있다면 가격이 낮은 문서를 승격할 수 있습니다. 검색 인덱스에 점수 매기기 프로필 추가에 대해 자세히 알아보세요.
용어 상승(전체 Lucene 쿼리 구문에만 사용 가능)은 쿼리 트리의 어떤 부분에도 적용할 수 있는
^상승 연산자를 제공합니다. 이 문서의 예제에서 접두사 air-condition*을 검색하는 대신, 정확한 용어 air-condition으로 검색하거나 접두사로 검색할 수 있습니다. 하지만 용어 쿼리에 상승을 적용하여(air-condition^2||air-condition*) 정확한 용어와 일치하는 문서에 더 높은 순위가 부여됩니다. 쿼리에서 용어 상승에 대해 자세히 알아보세요.
분산된 인덱스에 점수 매기기
Azure AI 검색의 모든 인덱스는 여러 분할 영역으로 자동 분할되므로 서비스 스케일 업 또는 스케일 다운 시 인덱스를 여러 노드에 신속하게 배포할 수 있습니다. 검색 요청이 실행될 때 검색 요청은 각 분할 영역에 대해 독립적으로 실행됩니다. 그런 다음 각 분할 영역의 결과가 점수를 기준으로(다른 정렬 기준이 정의되지 않은 경우) 병합되고 정렬됩니다. 점수 매기기 함수는 분할 영역 전체가 아닌 해당 분할 영역 내부의 모든 문서에서 반전 문서 빈도보다 쿼리 용어 빈도에 가중치를 부여한다는 것을 기억해야 합니다.
즉, 같은 문서라도 서로 다른 분할 영역에 상주할 경우 관련성 점수가 다를 수 있습니다. 다행스럽게도 이러한 차이는 인덱스의 문서 수가 증가하면 용어가 보다 균등하게 배포되기 때문에 사라지는 경향이 있습니다. 특정 문서가 어떤 분할 영역에 배치되는지 추정하는 것은 불가능합니다. 그러나 문서 키가 변경되지 않는다고 가정할 때 항상 같은 분할 영역에 할당됩니다.
순서 안정성이 중요한 경우 일반적으로 문서 점수는 문서를 정렬하는 최선의 특성이 아닙니다. 예를 들어 점수가 같은 두 개의 문서가 있을 때, 같은 쿼리를 또 다시 실행하면 어떤 문서가 먼저 표시되는지 보장할 수 없습니다. 문서 점수는 결과 집합의 다른 문서와 비교한 일반적인 문서 관련성만 제공합니다.
결론
상용 검색 엔진의 성공으로 프라이빗 데이터에 대한 전체 텍스트 검색의 기대가 높아졌습니다. 이제 우리는 거의 모든 종류의 검색 환경에서 용어의 맞춤법이 틀리거나 불완전하더라도 엔진이 사람의 의도를 이해할 수 있을 것으로 기대합니다. 지정하지 않은 거의 동등한 용어나 동의어를 기반으로 일치를 기대할 수도 있습니다.
기술적인 측면에서 전체 텍스트 검색은 매우 복잡합니다. 쿼리 용어를 제거하고, 확장하고, 변환하여 관련 결과를 제공하는 정교한 언어 분석과 체계적인 처리 방법이 필요합니다. 내재된 복잡성을 고려할 때 쿼리 결과에 영향을 줄 수 있는 수많은 요소가 있습니다. 이러한 이유로 전체 텍스트 검색의 역학을 이해하는 데 시간을 투자하면 예상치 않은 결과를 작업할 때 확실한 이점이 있습니다.
이 문서에서는 Azure AI 검색의 전체 텍스트 검색을 살펴보았습니다. 일반적인 쿼리 문제의 잠재적 원인과 해결책을 찾는 데 충분한 배경 지식을 익히셨기를 바랍니다.
다음 단계
샘플 인덱스를 작성하고, 여러 쿼리를 시도하고, 결과를 검토합니다. 자세한 지침은 포털에서 인덱스를 빌드하고 쿼리를 참조하세요.
포털의 Search 탐색기에서 문서 검색 예제 섹션 또는 단순 쿼리 구문의 다른 쿼리 구문을 사용해 보세요.
검색 애플리케이션의 순위를 조정하려는 경우 점수 매기기 프로필을 검토하세요.
언어별 어휘 분석기를 적용하는 방법을 알아보세요.
특정 필드에 대해 최소한의 처리 또는 특수한 처리를 수행하려면 사용자 지정 분석기를 구성하세요.