Stream Analytics 스트리밍 단위 이해 및 조정
스트리밍 단위 및 스트리밍 노드 이해
SU(스트리밍 단위)는 Stream Analytics 작업을 실행하도록 할당된 컴퓨팅 리소스를 나타냅니다. SU 수가 클수록 작업에 더 많은 CPU 및 메모리 리소스가 할당됩니다. 이러한 용량을 통해 쿼리 논리에 중점을 두고 Stream Analytics 작업을 적시에 실행하도록 하드웨어를 관리해야 할 필요성을 요약할 수 있습니다.
Azure Stream Analytics는 SU V1(사용되지 않음) 및 SU V2(권장) 등의 두 가지 스트리밍 단위 구조를 지원합니다.
SU V1 모델은 ASA의 원래 제품으로, 모든 6개의 SU가 작업에 대한 단일 스트리밍 노드에 해당합니다. 작업은 1 및 3개의 SU로도 실행할 수 있으며 분수인 스트리밍 노드에 해당합니다. 크기 조정은 분산 컴퓨팅 리소스를 제공하는 더 많은 스트리밍 노드를 추가하여, 6개의 SU 작업 이후 12, 18, 24 등, 6 단위로 증가하는 형태로 발생합니다.
SU V2 모델(권장)은 동일한 컴퓨팅 리소스에 대해 가격 책정면에서 장점이 있는 간소화된 구조입니다. SU V2 모델에서 1개의 SU V2는 작업에 대한 하나의 스트리밍 노드에 해당합니다. 2개의 SU V2는 2, 3개는 3에 해당하는 식입니다. 1/3 및 2/3개 SU V2가 있는 작업은 하나의 스트리밍 노드와 컴퓨팅 리소스의 일부만 사용할 수 있습니다. 1/3 및 2/3개의 SU V2 작업은 더 작은 규모가 필요한 워크로드에 대해 비용 효율적인 옵션을 제공합니다.
V1 및 V2 스트리밍 단위의 기본 컴퓨팅 성능은 다음과 같습니다.
SU 가격 책정에 대한 자세한 내용은 Azure Stream Analytics 가격 책정 페이지를 참조하세요.
스트리밍 단위 변환 및 적용 위치 이해
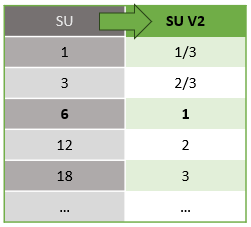
REST API 계층에서 UI(Azure Portal 및 Visual Studio Code)로 발생하는 스트리밍 단위의 자동 변환이 있습니다. SU 값이 UI의 값과 다르게 표시되는 활동 로그에서 이 변환을 확인할 수 있습니다. 이는 설계에 따라 REST API 필드가 정수 값으로 제한되고 ASA 작업이 분수인 노드(1/3 및 2/3 스트리밍 단위)를 지원하기 때문입니다. ASA의 UI는 노드 값 1/3, 2/3, 1, 2, 3 등을 표시하고 백 엔드(활동 로그, REST API 계층)는 각각 여기에 10을 곱한 3, 7, 10, 20, 30 등을 표시합니다.
| Standard | 표준 V2(UI) | 표준 V2(로그, Rest API 등과 같은 백 엔드) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
이를 통해 동일한 세분성을 전달하고 V2 SKU용 API 계층에서 소수점을 제거할 수 있습니다. 이 변환은 자동이며 작업 성능에 영향을 주지 않습니다.
사용량 및 메모리 사용률 이해
Azure Stream Analytics 작업은 대기 시간이 짧은 스트리밍 처리를 위해 모든 처리를 메모리 안에서 수행합니다. 메모리가 부족하면 스트리밍 작업이 실패합니다. 결과적으로, 프로덕션 작업의 경우 스트리밍 작업의 리소스 사용을 모니터링하고 작업을 중단 없이 실행하기에 충분한 리소스가 할당되도록 확인해야 합니다.
0%에서 100% 범위의 SU % 사용률 메트릭은 워크로드의 메모리 사용량을 설명합니다. 최소 사용되는 스트리밍 작업의 경우 이 메트릭은 보통 10~20% 범위입니다. SU% 사용률이 높거나(80% 이상) 입력 이벤트가 백로그되는 경우(CPU 사용량을 표시하지 않으므로 SU% 사용률이 낮은 경우에도) 워크로드에 더 많은 컴퓨팅 리소스가 필요할 수 있으며, 이 경우에는 스트리밍 단위의 수를 높여야 합니다. 경우에 따른 사용량 급증을 대비하여 SU 메트릭을 80% 이하로 유지하는 것이 가장 좋습니다. 증가하는 워크로드에 대응하여 스트리밍 단위를 늘리려면 SU 사용률 메트릭에 80% 경고를 설정하는 것이 좋습니다. 또한 워터마크 연기 및 백로그 이벤트 메트릭을 사용하여 영향이 있는지 확인할 수 있습니다.
Stream Analytics 스트리밍 단위(SU) 구성
Azure 포털에 로그인합니다.
리소스 목록에서 확장할 Stream Analytics 작업을 찾은 후 엽니다.
작업 페이지의 구성 제목 아래 크기 조정을 선택합니다. 작업을 만들 때 기본값 SU 수는 1입니다.
드롭다운 목록에서 SU 옵션을 선택하여 작업에 대한 SU를 설정합니다. 특정 SU 범위로 제한됩니다.
작업을 실행 중인 동안 작업에 할당되는 SU의 수를 변경할 수 있습니다. 작업이 분할되지 않은 출력을 사용하거나 PARTITION BY 값이 다른 다단계 쿼리가 있는 경우 작업이 실행 중일 때 SU 값 집합에서 선택하도록 제한될 수 있습니다.
작업 성능 모니터링
Azure Portal을 사용하여 작업의 성능 관련 메트릭을 추적할 수 있습니다. 메트릭 정의에 대한 자세한 내용은 Azure Stream Analytics 작업 메트릭을 참조하세요. 포털의 메트릭 모니터링에 대한 자세한 내용은 Azure Portal로 Stream Analytics 작업 모니터링을 참조하세요.

워크로드의 예상 처리량을 계산합니다. 처리량이 예상보다 더 작은 경우 입력 파티션을 조정하고, 쿼리를 조정하고, 작업에 SU를 추가합니다.
작업에 필요한 SU 수는?
특정 작업에 필요한 SU 수 선택은 입력에 대한 파티션 구성 및 작업에 정의된 쿼리에 따라 달라집니다. 비율 크기 조정 블레이드를 사용하면 올바른 SU 수를 설정할 수 있습니다. 필요한 것보다 많은 SU를 할당하는 것이 좋습니다. Stream Analytics 처리 엔진은 메모리를 추가로 할당하는 비용으로 대기 시간과 처리량을 최적화합니다.
일반적으로 PARTITION BY을 사용하지 않는 쿼리는 1개 SU V2로 시작하는 것이 좋습니다. 그런 다음 대표적인 데이터 양을 전달하고 SU % 사용률 메트릭을 시험한 후 SU 수를 수정하는 평가판 및 오류 메서드를 사용하여 가장 적절한 부분을 판단합니다. Stream Analytics 작업에 사용될 수 있는 최대 스트리밍 단위 수는 작업에 대해 정의된 쿼리의 단계 수와 각 단계에 대한 파티션 수에 따라 결정됩니다. 이러한 제한에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
올바른 SU 수 선택에 대한 자세한 내용은 처리량을 높이기 위한 Azure Stream Analytic 작업 비율 크기 조정 페이지를 참조하세요.
참고 항목
특정 작업에 필요한 SU 수 선택은 입력에 대한 파티션 구성 및 작업에 정의된 쿼리에 따라 달라집니다. 작업에 대해 SU의 할당량까지 선택할 수 있습니다. Azure Stream Analytics 구독 할당량에 대한 자세한 내용은 Stream Analytics 제한을 참조하세요. 구독의 SU를 이 할당량을 초과하여 늘리려면 Microsoft 지원에 문의하세요. 작업당 SU에 유효한 값은 1/3, 2/3, 1, 2, 3 등입니다.
SU% 사용률이 증가하는 요인
temporal(시간 지향적인) 쿼리 요소는 Stream Analytics에서 제공하는 상태 저장 연산자의 핵심 집합입니다. Stream Analytics는 서비스 업그레이드 중 메모리 소비, 복원력 검사점 및 상태 복구를 관리하여 사용자 대신 내부적으로 이러한 작업의 상태를 관리합니다. Stream Analytics가 상태를 완전히 관리하더라도 사용자가 고려해야 하는 몇 가지 모범 사례 권장 사항이 있습니다.
복잡한 쿼리 논리를 사용하는 작업은 입력 이벤트를 지속적으로 수신하지 않더라도 높은 SU% 사용률을 나타낼 수 있습니다. 입력 및 출력 이벤트가 급격히 증가한 후에 이러한 현상이 발생할 수 있습니다. 쿼리가 복잡한 경우 작업은 메모리의 상태를 계속 유지할 수 있습니다.
SU% 사용률은 잠시 동안 갑자기 0으로 떨어졌다가 정상 수준으로 돌아올 수도 있습니다. 이러한 현상은 일시적인 오류 또는 시스템에서 시작한 업그레이드로 인해 발생합니다. 쿼리가 완전히 병렬되지 않은 경우 작업에 대한 스트리밍 단위 수를 늘려도 SU% 사용률이 감소하지 않을 수 있습니다.
일정 기간 동안의 사용률을 비교하는 동안 이벤트 요금 메트릭을 사용합니다. InputEvents 및 OutputEvents 메트릭은 읽고 처리한 이벤트의 수를 표시합니다. Deserialization 오류와 같은 오류 이벤트의 수를 나타내는 메트릭도 있습니다. 시간 단위당 이벤트 수가 늘어나면 대부분의 경우 SU%도 늘어납니다.
temporal 요소의 상태 저장 쿼리 논리
Azure Stream Analytics 작업의 고유한 기능 중 하나는 기간 이동 집계, 임시 조인 및 임시 분석 함수 등과 같은 상태 저장 처리를 수행하는 것입니다. 이러한 연산자마다 상태 정보를 유지합니다. 이러한 쿼리 요소의 최대 시간 범위는 7일입니다.
temporal 시간 범위 개념은 몇 가지 Stream Analytics 쿼리 요소에 나타납니다.
기간 이동 집계: 연속, 도착 및 슬라이딩 시간 범위의 GROUP BY
temporal 조인: DATEDIFF 함수를 사용한 JOIN
temporal 분석 함수: LIMIT DURATION이 있는 ISFIRST, LAST 및 LAG
다음 요소는 Stream Analytics 작업에 사용되는 메모리(스트리밍 단위 메트릭의 일부)에 영향을 줍니다.
기간 이동 집계
기간 이동 집계에 소비되는 메모리(상태 크기)가 시간 범위 크기에 항상 비례하지는 않습니다. 대신 소비되는 메모리는 데이터의 카디널리티 또는 각 시간 범위의 그룹 수에 비례합니다.
예를 들어 다음 쿼리에서 clusterid와 연결된 수는 쿼리의 카디널리티입니다.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
앞의 쿼리에서 카디널리티가 발생시킨 문제를 완화하기 위해 clusterid로 분할된 Event Hubs에 이벤트를 보내고 아래 예제에서처럼 PARTITION BY를 사용하여 개별적으로 각 입력 파티션을 처리할 수 있습니다.
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
쿼리가 분할되면 여러 노드에 걸쳐 분산됩니다. 결과적으로, 각 노드로 들어오는 clusterid 값의 수가 감소하여 GROUP BY 연산자 카디널리티가 줄어듭니다.
Event Hubs 파티션은 단계를 줄이지 않아도 되도록 그룹 키로 분할되어야 합니다. 자세한 내용은 Event Hubs 개요를 참조하세요.
temporal 조인
temporal 조인의 메모리 소비(상태 크기)는 조인의 temporal 위글 공간의 이벤트 수에 비례합니다. 즉 이벤트 입력 속도와 위글 공간 크기의 곱입니다. 즉, 조인에 의해 소비되는 메모리는 DateDiff 시간 범위에 평균 이벤트 속도를 곱한 값에 비례합니다.
조인에서 일치하지 않는 이벤트 수는 쿼리에 대한 메모리 사용률에 영향을 줍니다. 다음 쿼리는 클릭을 유도하는 광고 노출을 찾는 것입니다.
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
이 예제에서 광고는 많은 데 사용자가 거의 클릭하지 않는 경우 모든 이벤트를 timewindow에 있도록 해야 합니다. 사용된 메모리는 창 크기와 이벤트 속도에 비례합니다.
이를 조치하기 위해 조인 키(이 경우 ID)로 분할된 Event Hubs에 이벤트를 보내고 다음과 같이 시스템이 PARTITION BY를 사용하여 별도로 각각의 입력 파티션을 처리할 수 있게 쿼리를 확장합니다.
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
쿼리가 분할되면 여러 노드에 걸쳐 분산됩니다. 결과적으로, 각 노드로 들어오는 이벤트 수가 감소하여 조인 창에 유지되는 상태 크기가 줄어듭니다.
temporal 분석 함수
temporal 분석 함수의 소비 메모리(상태 크기)는 이벤트 속도와 기간의 곱에 비례합니다. 분석 함수가 소비하는 메모리는 시간 범위의 크기에 비례하지 않고 각 시간 범위의 파티션 수에 비례합니다.
조치는 임시 조인과 유사합니다. PARTITION BY를 사용하여 쿼리를 확장할 수 있습니다.
잘못된 버퍼
이벤트 순서 지정 구성 창에서 잘못된 버퍼 크기를 구성할 수 있습니다. 이 버퍼는 창의 기간에 대한 입력을 유지하고 순서를 재지정하는 데 사용됩니다. 버퍼 크기는 이벤트 입력 비율과 잘못된 창 크기의 곱에 비례합니다. 기본 창 크기는 0입니다.
순서가 잘못된 버퍼의 오버플로를 수정하려면 PARTITION BY를 사용하여 쿼리를 확장합니다. 쿼리가 분할되면 여러 노드에 걸쳐 분산됩니다. 결과적으로, 각 노드로 들어오는 이벤트 수가 감소하여 각각의 순서 재지정 버퍼의 이벤트 수가 줄어듭니다.
입력 분할 개수
작업 입력의 각 입력 파티션에는 버퍼가 있습니다. 입력 파티션 수가 클수록 이 작업이 더 많은 리소스를 소비합니다. 각 스트리밍 단위에 대해 Azure Stream Analytics는 대략 7MB/s의 입력을 처리할 수 있습니다. 따라서 Stream Analytics 스트리밍 단위 수를 이벤트 허브의 파티션 수와 일치 시켜서 최적화할 수 있습니다.
일반적으로 1/3개의 스트리밍 유닛으로 구성된 작업은 두 개의 파티션이 있는 이벤트 허브(이벤트 허브의 최소값)로 충분합니다. 이벤트 허브에 더 많은 파티션이 있으면 Stream Analytics 작업이 더 많은 리소스를 소비하지만 Event Hub에서 제공한 추가적인 처리량을 반드시 사용하는 것은 아닙니다.
1개 V2 스트리밍 단위의 작업에서는 이벤트 허브에 4 또는 8개 파티션이 필요할 수 있습니다. 그러나 불필요한 파티션을 너무 많이 사용하면 과도한 리소스 사용이 발생하므로 피해야 합니다. 스트리밍 단위가 1인 Stream Analytics 작업에서 16개 이상의 파티션이 있는 이벤트 허브가 그러한 예입니다.
참조 데이터
ASA의 참조 데이터는 빠른 조회를 위해 메모리에 로드됩니다. 현재 구현에서는 동일한 참조 데이터를 여러 번 조인하더라도 참조 데이터와의 각 조인 작업이 메모리에 참조 데이터의 사본을 유지합니다. PARTITION BY를 통한 쿼리의 경우 각 파티션은 참조 데이터의 사본을 유지하므로 파티션이 완전히 분리됩니다. 참조 데이터를 여러 파티션과 여러 차례 조인할 경우 승수 효과에 따라 메모리 사용이 갑자기 급증할 수 있습니다.
UDF 함수 사용
UDF 함수를 추가하면 Azure Stream Analytics가 JavaScript 런타임을 메모리에 로드합니다. 이것이 SU%에 영향을 주게 됩니다.