Azure Stream Analytics 쿼리 문제 해결
이 문서에서는 Stream Analytics 쿼리 개발과 관련한 일반적인 문제 및 그 해결 방법을 설명합니다.
이 문서에서는 Azure Stream Analytics 쿼리 개발과 관련한 일반적인 문제, 쿼리 문제를 해결하는 방법 및 해당 문제를 해결하는 방법을 설명합니다. 대부분의 문제 해결 단계에서는 Stream Analytics 작업에 대해 리소스 로그를 사용하도록 설정해야 합니다. 리소스 로그를 사용하도록 설정하지 않은 경우 리소스 로그를 사용하여 Azure Stream Analytics 문제 해결을 참조하세요.
쿼리가 예상 출력을 생성하지 않음
로컬로 테스트하여 오류를 검사합니다.
- Azure Portal의 쿼리 탭에서 테스트를 선택합니다. 다운로드한 샘플 데이터를 사용하여 쿼리를 테스트합니다. 모든 오류를 검사하고 수정합니다.
- Visual Studio용 Azure Stream Analytics 도구 또는 Visual Studio Code를 사용하여 쿼리를 로컬로 테스트할 수도 있습니다.
Visual Studio Code용 Azure Stream Analytics 도구에서 작업 다이어그램을 사용하여 로컬로 쿼리를 단계별로 디버그합니다. 작업 다이어그램은 입력 원본(Event Hub, IoT Hub 등)에서 여러 쿼리 단계를 거쳐 최종적으로 출력 싱크까지의 데이터 흐름 방식을 보여줍니다. 각 쿼리 단계는 WITH 문을 사용하여 스크립트에 정의된 임시 결과 집합에 매핑됩니다. 각 중간 결과 집합에서 메트릭뿐만 아니라 데이터를 보고 문제의 원인을 찾을 수 있습니다.
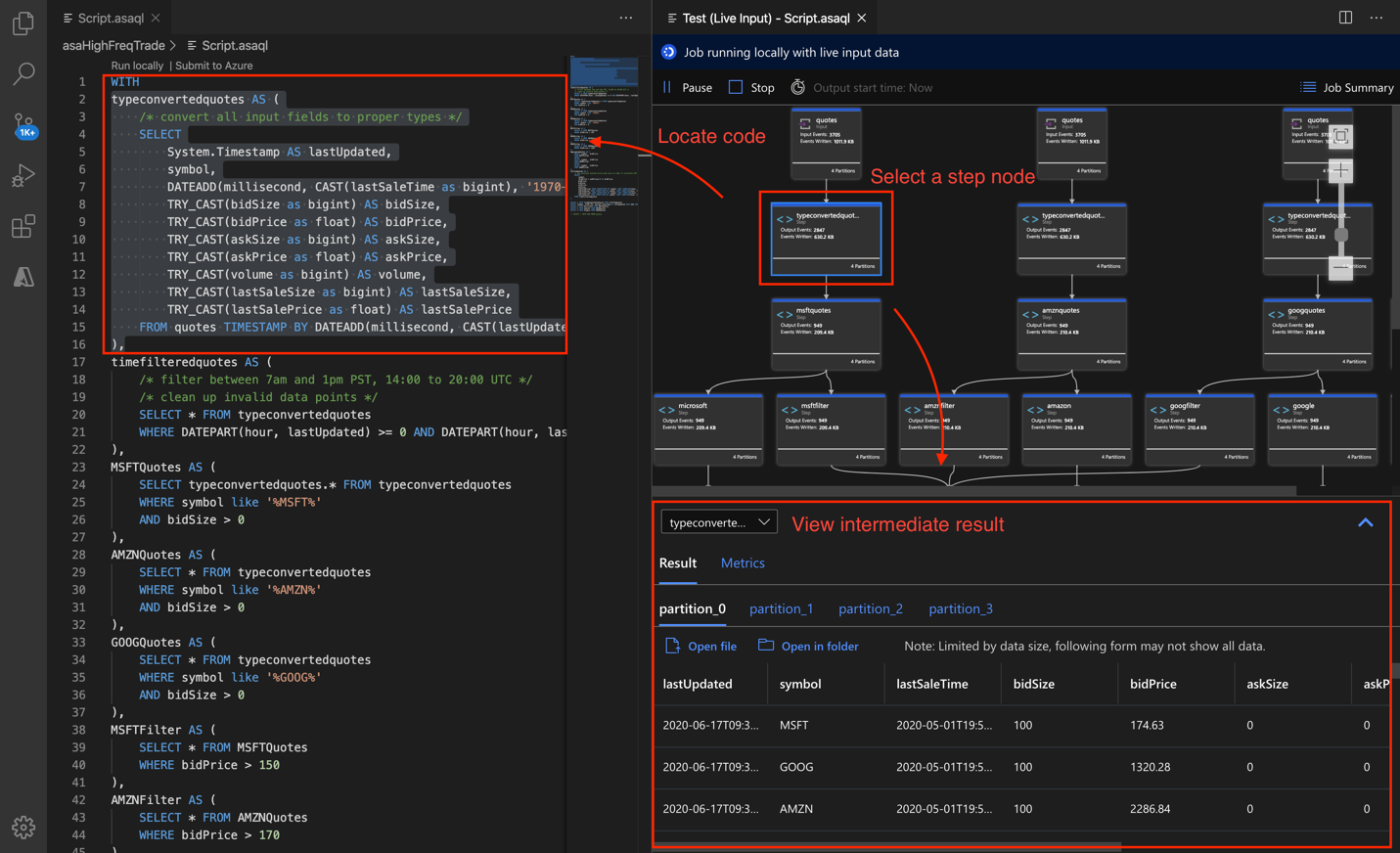
Timestamp By를 사용하는 경우 이벤트에 작업 시작 시간보다 큰 타임스탬프가 있는지 확인합니다.
다음과 같은 공통 문제를 제거합니다.
이벤트 순서 지정 정책이 예상대로 구성되었는지 확인합니다. 설정으로 이동하여 이벤트 순서 지정을 선택합니다. 정책은 테스트 단추를 사용하여 쿼리를 테스트하는 경우 적용되지 않습니다. 이것이 브라우저에서 테스트할 때와 프로덕션의 작업을 실행할 때의 차이입니다.
활동 및 리소스 로그를 사용하여 디버그:
리소스 사용률이 높습니다.
Azure Stream Analytics의 병렬 처리를 활용해야 합니다. 입력 파티션을 구성하고, 분석 쿼리 정의를 조정하여 Stream Analytics 작업의 쿼리 병렬 처리로 크기를 조정할 수 있습니다.
리소스 사용률이 지속적으로 80%를 초과하고, 워터마크 지연 시간이 늘어나고 백로그된 이벤트 수가 늘어나는 경우 스트리밍 단위를 증가시키는 것이 좋습니다. 사용률이 높으면 작업에서 할당된 최대 리소스에 가까운 용량을 사용하고 있음을 나타냅니다.
점진적으로 쿼리 디버그
실시간 데이터를 처리하는 동안 쿼리 중간에 데이터가 어떤 상태인지를 알면 유용할 수 있습니다. Visual Studio의 작업 다이어그램을 사용하여 이를 확인할 수 있습니다. Visual Studio가 없는 경우 추가 단계를 수행하여 중간 데이터를 출력할 수 있습니다.
Azure Stream Analytics 작업의 입력 또는 단계를 여러 번 읽을 수 있기 때문에 추가 SELECT INTO 문을 작성할 수 있습니다. 이렇게 하면 프로그램을 디버그할 때 watch 변수가 동작하는 것처럼 중간 데이터가 스토리지로 출력되어 데이터의 정확성을 검사할 수 있습니다.
Azure Stream Analytics 작업의 다음 예제 쿼리에는 Azure Table Storage에 대해 하나의 스트림 입력, 두 개의 참조 데이터 입력 및 출력이 있습니다. 쿼리는 이벤트 허브의 데이터와 두 개의 참조 Blob을 조인하여 이름 및 범주 정보를 가져옵니다.
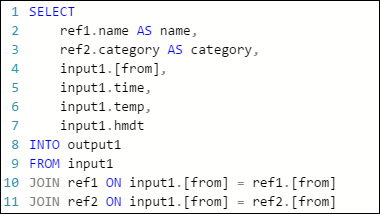
작업이 실행되고 있지만 이벤트는 출력에 생성되지 않습니다. 여기에 표시된 모니터링 타일에서 입력이 데이터를 생성하는 것을 확인할 수는 있지만 JOIN의 어떤 단계에서 모든 이벤트가 삭제되었는지는 알 수 없습니다.
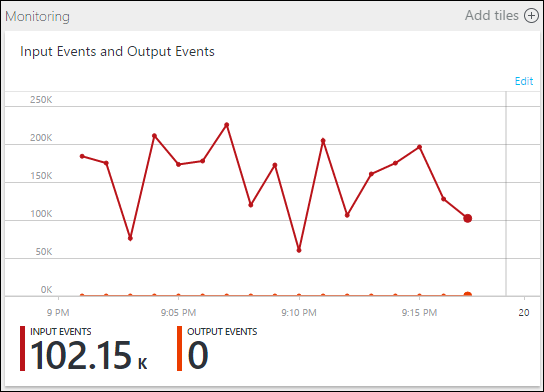
이 경우 몇 가지 추가 SELECT INTO 문을 추가하여 중간 JOIN 결과와 입력에서 읽은 데이터를 “로깅”할 수 있습니다.
이 예제에서는 두 개의 새로운 "임시 출력"을 추가했습니다. 원하시는 싱크가 될 수도 있습니다. 여기서는 Azure Storage를 예로 사용합니다.
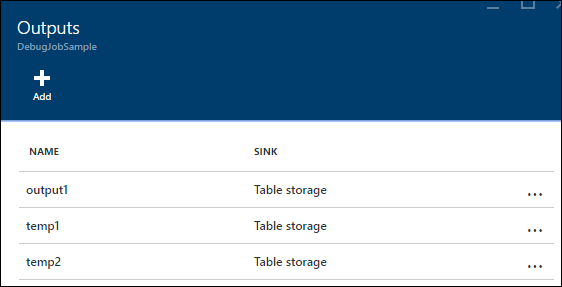
그런 다음 다음과 같이 쿼리를 다시 작성할 수 있습니다.
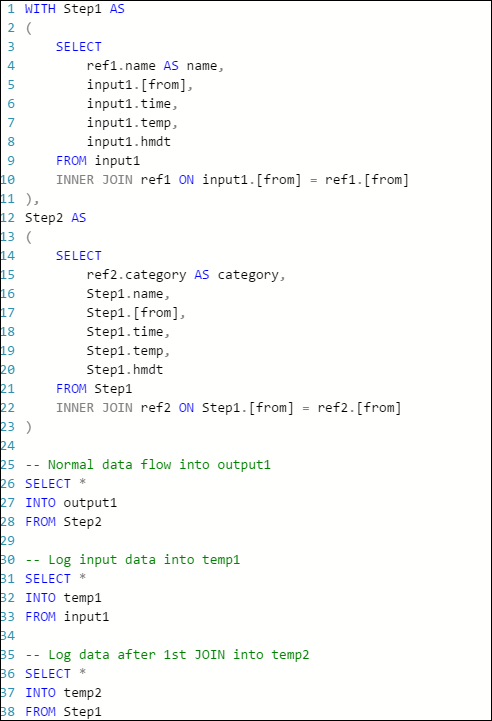
이제 작업을 다시 시작하고 몇 분 동안 실행되도록 합니다. 그런 다음 Visual Studio Cloud Explorer를 통해 temp1 및 temp2를 쿼리하여 다음과 같은 테이블을 생성합니다.
temp1 테이블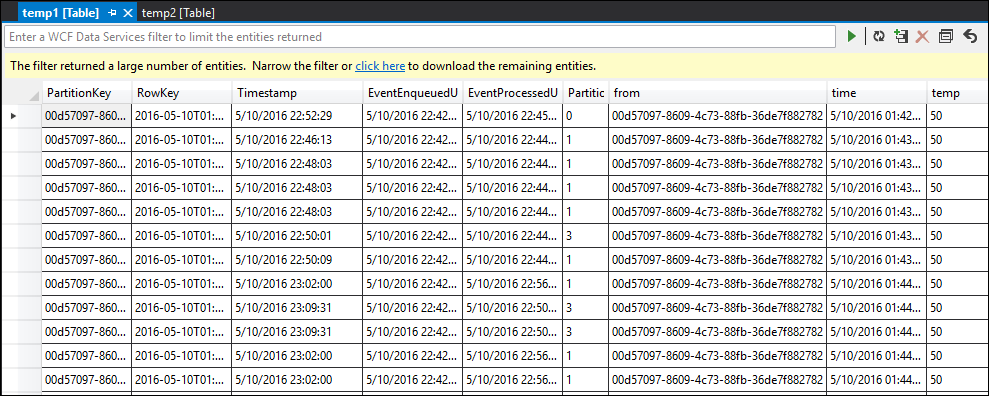
temp2 테이블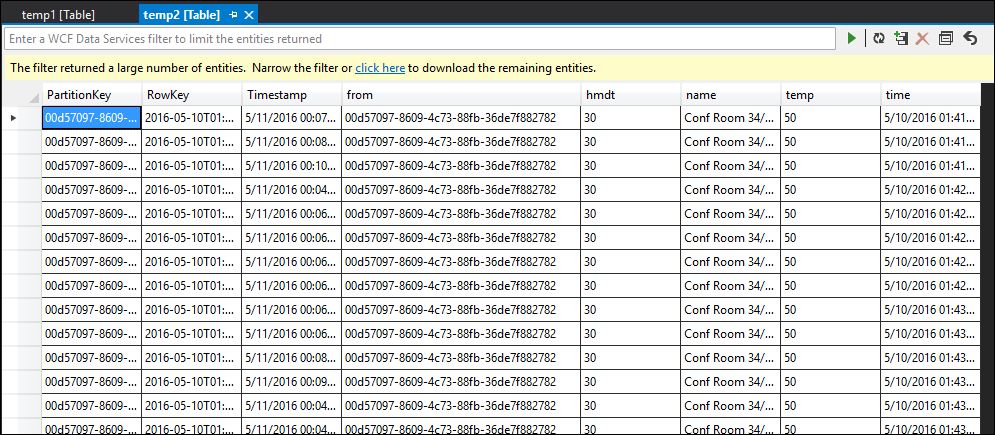
보시다시피 temp1 및 temp2에 모두 데이터가 있고 이름 열이 temp2에서 올바르게 채워집니다. 그러나 여전히 출력에 데이터가 없기 때문에 문제가 있습니다.
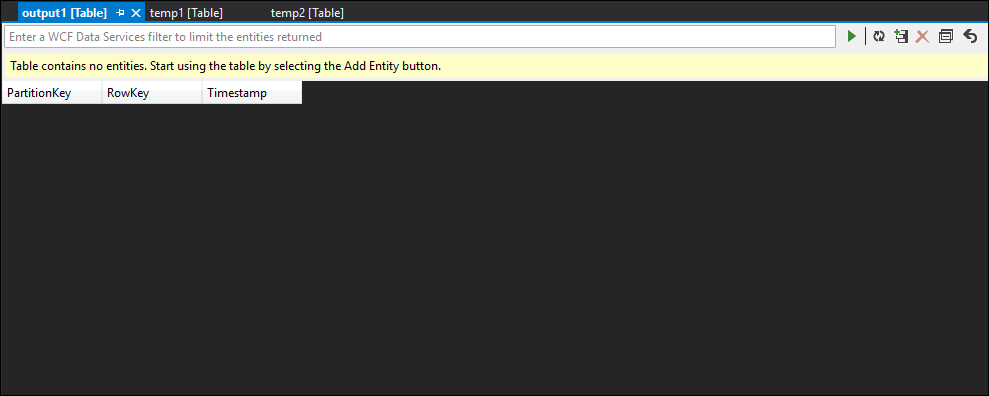
데이터를 샘플링하면 두 번째 JOIN에서 문제가 있음을 거의 확신할 수 있습니다. Blob의 참조 데이터를 다운로드하고 살펴 볼 수 있습니다.
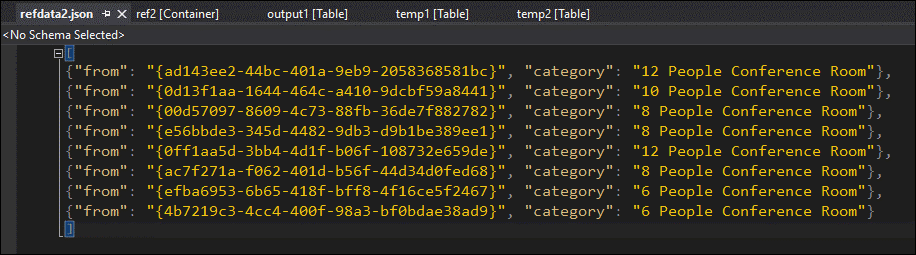
보시다시피 이 참조 데이터에서 GUID의 형식은 temp2의 열 형식과는 다릅니다. 데이터가 output1에 예상대로 도착하지 않았기 때문입니다.
데이터 형식을 수정하고, 참조 Blob에 업로드하고 다시 시도할 수 있습니다.
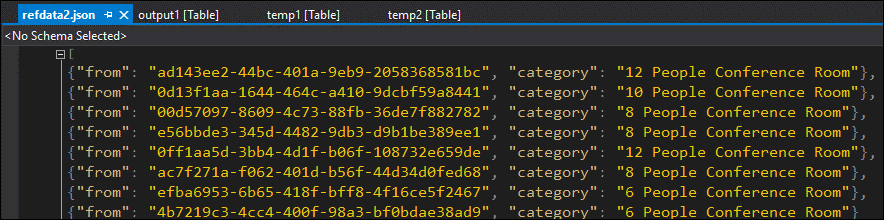
이번에는 출력 데이터가 예상대로 포맷되고 채워져 있습니다.
도움말 보기
추가 지원이 필요한 경우 Azure Stream Analytics용 Microsoft Q&A 질문 페이지를 참조하세요.