Azure Synapse Analytics의 전용 SQL 풀(이전의 SQL DW)에 대한 참고 자료
이 참고 자료는 전용 SQL 풀(이전의 SQL DW) 솔루션을 빌드하는 데 유용한 팁과 모범 사례를 제공합니다.
다음 그래픽에서는 전용 SQL 풀(이전의 SQL DW)을 사용하여 데이터 웨어하우스를 설계하는 프로세스를 보여 줍니다.
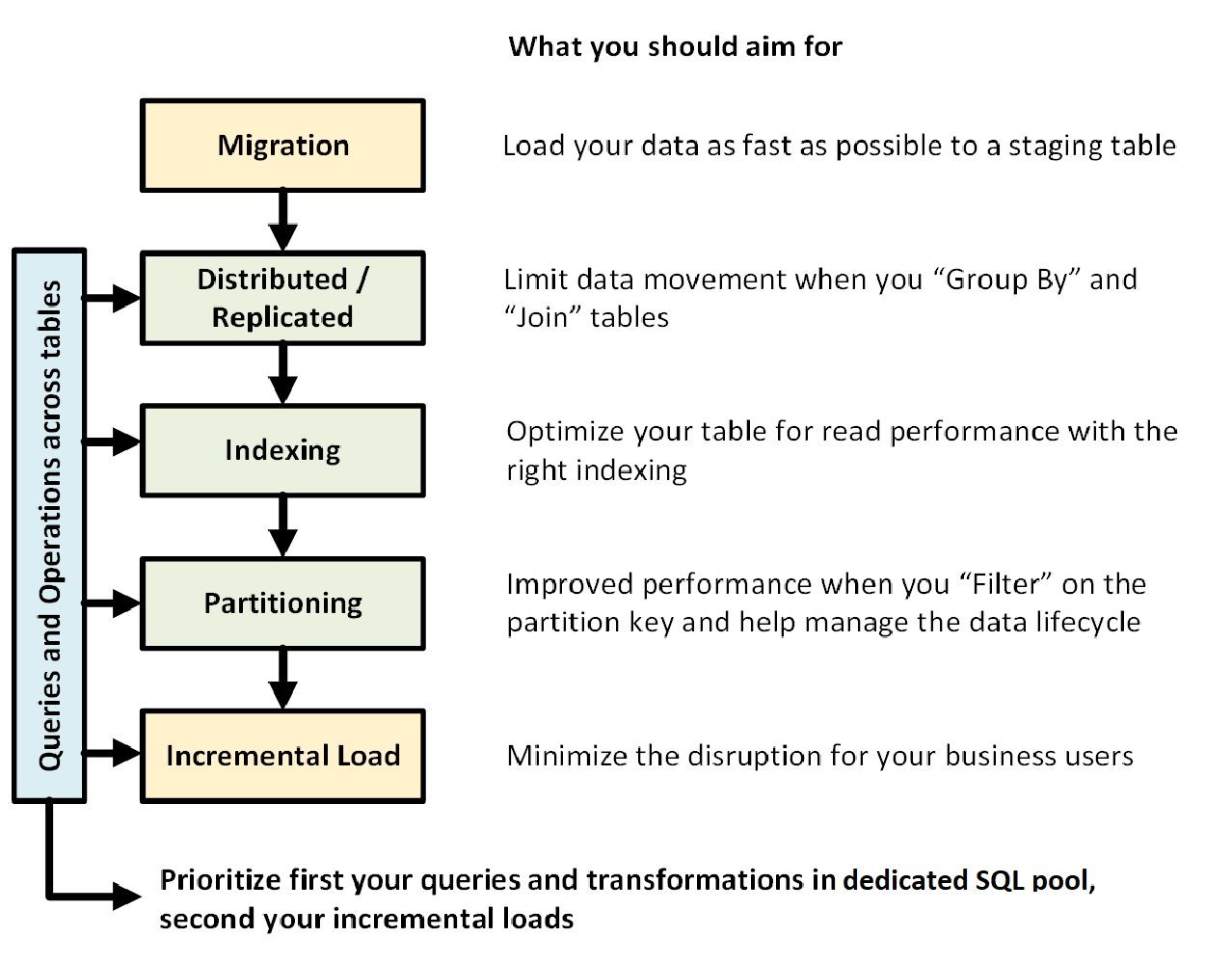
테이블에서 쿼리 및 작업
데이터 웨어하우스에서 실행할 기본 작업 및 쿼리를 미리 알고 있으면 이러한 작업에 대한 데이터 웨어하우스 아키텍처의 우선 순위를 지정할 수 있습니다. 이러한 쿼리 및 작업에는 다음이 포함될 수 있습니다.
- 하나 또는 두 개의 팩트 테이블을 차원 테이블과 조인하고, 결합된 테이블을 필터링한 다음, 결과를 데이터 마트에 추가합니다.
- 팩트 영업에 크거나 작은 업데이트를 수행합니다.
- 테이블에 데이터만 추가합니다.
작업 유형을 알고 있으면 테이블의 디자인을 최적화하는 데 유용합니다.
데이터 마이그레이션
먼저 Azure Data Lake Storage 또는 Azure Blob Storage에 데이터를 로드합니다. 그런 다음, COPY 문을 사용하여 데이터를 준비 테이블에 로드합니다. 다음 구성을 사용합니다.
| 디자인 | 권장 |
|---|---|
| 배포 | 라운드 로빈 |
| 인덱싱 | 힙 |
| 분할 | 없음 |
| 리소스 클래스 | largerc 또는 xlargerc |
데이터 마이그레이션, 데이터 로드, ELT(추출, 로드 및 변환) 프로세스에 대해 자세히 알아보세요.
분산 또는 복제된 테이블
테이블 속성에 따라 다음 전략을 사용합니다.
| Type | 적합한 대상 | 유의해야 하는 경우... |
|---|---|---|
| 복제됨 | * 압축 후 2GB 스토리지 이하 별모양 스키마의 소형 차원 테이블(~5배 압축) | * 많은 쓰기 트랜잭션이 테이블에 있음(예: insert, upsert, delete, update) * DWU(데이터 웨어하우스 단위) 프로비저닝이 자주 변경됨 * 2-3개 열만 사용하지만 테이블에 많은 열이 있음 * 복제된 테이블을 인덱싱 |
| 라운드 로빈(기본값) | * 임시/준비 테이블 * 명백한 조인 키 또는 양호한 후보 열이 없음 |
* 데이터 이동으로 인한 성능 저하 |
| 해시 | * 팩트 테이블 * 대형 차원 테이블 |
* 배포 키를 업데이트할 수 없음 |
팁:
- 라운드 로빈으로 시작하지만 대규모 병렬 아키텍처를 활용하는 해시 분산 전략을 목표로 합니다.
- 공통 해시 키의 데이터 형식이 동일한지 확인합니다.
- varchar 형식으로 배포하지 마세요.
- 조인 작업이 빈번한 팩트 테이블에 대한 공통 해시 키가 있는 차원 테이블은 해시 분산될 수 있습니다.
- sys.dm_pdw_nodes_db_partition_stats를 사용하여 데이터의 모든 왜곡도를 분석합니다.
- sys.dm_pdw_request_steps를 사용하여 쿼리의 백그라운드 데이터 이동 분석, 시간 브로드캐스트 모니터링 및 작업 순서 섞기를 수행합니다. 이는 분산 전략을 검토하는 데 유용합니다.
복제된 테이블 및 분산 테이블에 대해 자세히 알아보세요.
테이블 인덱싱
인덱싱은 테이블을 빠르게 읽는 데 유용합니다. 필요에 따라 사용할 수 있는 고유한 기술 집합이 있습니다.
| Type | 적합한 대상 | 유의해야 하는 경우... |
|---|---|---|
| 힙 | * 스테이징/임시 테이블 * 작은 조회를 통한 소형 테이블 |
* 전체 테이블을 검색하는 모두 조회 |
| 클러스터형 인덱스 | * 최대 1억 개 행이 있는 테이블 * 1-2개 열만 많이 사용하는 대형 테이블(1억 개가 넘는 행) |
* 복제 테이블에서 사용됨 * 여러 Join, Group By 작업과 관련된 복잡한 쿼리가 있음 * 인덱싱된 열을 업데이트하고 메모리가 필요함 |
| CCI(클러스터형 columnstore 인덱스)(기본값) | * 대형 테이블(1억 개가 넘는 행) | * 복제 테이블에서 사용됨 * 테이블에서 대량 업데이트 작업 수행 * 테이블을 과도하게 분할하고, 행 그룹이 다른 분산 노드와 파티션에 걸쳐 있지 않음 |
팁:
- 클러스터형 인덱스에 기반하여 필터링에 많이 사용되는 열에 비클러스터형 인덱스를 추가할 수 있습니다.
- CCI로 테이블에서 메모리를 관리하는 방법에 주의해야 합니다. 데이터를 로드할 때 사용자(또는 쿼리)가 큰 리소스 클래스의 이점을 사용하고자 합니다. 많고 작은 압축 행 그룹을 자르고 만들지 않도록 합니다.
- Gen2에서 CCI 테이블은 성능을 최대화하기 위해 컴퓨팅 노드에서 로컬로 캐시됩니다.
- CCI의 경우 행 그룹의 압축 불량으로 인해 성능이 저하될 수 있습니다. 이 경우 CCI를 다시 작성하거나 다시 구성합니다. 압축 행 그룹당 10만 개 이상의 행이 필요합니다. 이상적으로는 하나의 행 그룹에 100만 개 행이 있어야 합니다.
- 증분 로드 빈도 및 크기에 따라 인덱스를 다시 구성하거나 다시 빌드할 때 자동화하고자 합니다. 봄맞이 대청소는 항상 유용합니다.
- 행 그룹은 전략적으로 줄입니다. 열려 있는 행 그룹의 크기는? 앞으로 로드할 데이터의 양은?
인덱스에 대해 자세히 알아보세요.
분할
큰 팩트 테이블(10억 개 행 보다 큼)이 있는 경우 테이블을 분할할 수 있습니다. 99%의 경우 파티션 키는 날짜를 기반으로 해야 합니다.
ELT가 필요한 스테이징 테이블을 사용하면 분할의 이점을 활용할 수 있습니다. 데이터 수명 주기 관리가 용이해집니다. 특히 클러스터형 columnstore 인덱스에서 팩트 또는 준비 테이블을 과도하게 분할하지 않도록 주의합니다.
분할에 대해 자세히 알아보세요.
증분 로드
데이터를 증분 방식으로 로드하려면 먼저 더 큰 리소스 클래스를 데이터 로드에 할당해야 합니다. 클러스터형 columnstore 인덱스가 있는 테이블로 로드할 때 특히 중요합니다. 자세한 내용은 리소스 클래스를 참조하세요.
ELT 파이프라인을 데이터 웨어하우스로 자동화하는 데 PolyBase 및 ADF V2를 사용하는 것이 좋습니다.
기록 데이터의 업데이트를 대량으로 일괄 처리하는 경우 INSERT, UPDATE 및 DELETE를 사용하는 대신 CTAS를 사용하여 테이블에 유지할 데이터를 작성하는 것이 좋습니다.
통계 유지 관리
데이터에 중요한 변경 내용이 있는 것 만큼 통계를 업데이트하는 것도 중요합니다. 중요한 변경이 발생했는지 확인하려면 통계 업데이트를 참조하세요. 업데이트된 통계는 쿼리 계획을 최적화합니다. 모든 통계를 유지 관리하는 데 시간이 너무 오래 걸리는 경우 통계가 있는 열을 선택해야 합니다.
또한 업데이트의 빈도를 정의할 수 있습니다. 예를 들어 매일 새 값이 추가될 수 있는 날짜 열을 업데이트할 수 있습니다. 조인에 포함된 열, WHERE 절에 사용된 열 및 GROUP BY에서 찾은 열에 대한 통계를 통해 가장 많은 이점을 얻을 수 있습니다.
통계에 대해 자세히 알아보세요.
리소스 클래스
리소스 그룹은 메모리를 쿼리에 할당하기 위한 방법으로 사용됩니다. 쿼리 또는 로드 속도를 개선하기 위해 더 많은 메모리가 필요한 경우 더 높은 리소스 클래스를 할당해야 합니다. 다른 한편으로, 더 큰 리소스 클래스를 사용하면 동시성에 영향을 줍니다. 모든 사용자를 큰 리소스 클래스로 이동하기 전에 고려해야 할 사항입니다.
쿼리 시간이 오래 걸리는 경우 사용자가 큰 리소스 클래스에서 실행하지 않는지 검사합니다. 큰 리소스 클래스는 많은 동시성 슬롯을 사용합니다. 이는 다른 쿼리를 큐에 대기시킬 수 있습니다.
마지막으로, 전용 SQL 풀(이전의 SQL DW)의 Gen2를 사용하여 각 리소스 클래스가 Gen1보다 2.5배 더 많은 메모리를 가져옵니다.
리소스 클래스 및 동시성으로 작업하는 방법에 대해 자세히 알아보세요.
비용 절감
Azure Synapse의 주요 기능은 컴퓨팅 리소스 관리 기능입니다. 전용 SQL 풀(이전의 SQL DW)을 사용하지 않을 때 일시 중지하여 컴퓨팅 리소스에 대한 청구를 중지할 수 있습니다. 성능 요구를 충족하기 위해 리소스를 확장할 수 있습니다. 일시 중지하려면 Azure Portal 또는 PowerShell을 사용합니다. 확장하려면 Azure Portal, PowerShell, T-SQL 또는 REST API를 사용합니다.
이제 Azure Functions를 통해 원하는 시간에 자동 크기 조정을 수행할 수 있습니다.

성능을 위한 아키텍처 최적화
허브 및 스포크 아키텍처에서 SQL Database 및 Azure Analysis Services를 고려하는 것이 좋습니다. 이 솔루션은 SQL Database 및 Azure Analysis Services의 고급 보안 기능을 사용하면서 동시에 다른 사용자 그룹 간에 워크로드 격리를 제공할 수 있습니다. 또한 사용자에게 무제한 동시성을 제공하는 방법이기도 합니다.
Azure Synapse Analytics에서 전용 SQL 풀(이전의 SQL DW)을 활용하는 일반적인 아키텍처에 대해 자세히 알아보세요.
전용 SQL 풀(이전의 SQL DW)에서 SQL 데이터베이스의 스포크를 한 번의 클릭으로 배포합니다.