순서가 지정된 클러스터형 columnstore 인덱스를 사용한 성능 조정
적용 대상: Azure Synapse Analytics 전용 SQL 풀, SQL Server 2022(16.x) 이상
사용자가 전용 SQL 풀에서 columnstore 테이블을 쿼리하는 경우 최적화 프로그램은 각 세그먼트에 저장된 최솟값과 최댓값을 확인합니다. 쿼리 조건자의 경계를 벗어난 세그먼트는 디스크에서 메모리로 읽지 않습니다. 읽을 세그먼트의 수와 전체 크기가 작은 경우 쿼리가 더 빨리 완료될 수 있습니다.
순서가 지정된 클러스터형 columnstore 인덱스 및 순서가 지정되지 않은 클러스터형 columnstore 인덱스
기본적으로 인덱스 옵션 없이 생성된 각 테이블에 대해 내부 구성 요소(인덱스 작성기)는 순서가 지정되지 않은 CCI(클러스터형 columnstore 인덱스)를 만듭니다. 각 열의 데이터는 분리된 CCI 행 그룹 세그먼트로 압축됩니다. 각 세그먼트의 값 범위에 대한 메타데이터가 있으므로 쿼리 조건자의 경계를 벗어나는 세그먼트는 쿼리 실행 중에 디스크에서 읽지 않습니다. CCI는 가장 높은 수준의 데이터 압축을 제공하고 읽을 세그먼트 크기를 줄이므로 쿼리를 더 빠르게 실행할 수 있습니다. 그러나 인덱스 작성기는 데이터를 세그먼트로 압축하기 전에 데이터를 정렬하지 않으므로 값 범위가 겹치는 세그먼트가 발생하여 쿼리가 디스크에서 더 많은 세그먼트를 읽고 완료하는 데 시간이 더 오래 걸릴 수 있습니다.
효율적인 세그먼트 제거를 사용하도록 설정하여 순서가 지정된 클러스터형 columnstore 인덱스는 쿼리 조건자와 일치하지 않는 순서가 지정된 대량의 데이터를 건너뛰어 훨씬 더 빠른 성능을 제공합니다. 순서가 지정된 CCI를 만들 때 전용 SQL 풀 엔진이 순서 키를 기준으로 메모리의 기존 데이터를 정렬한 후 인덱스 작성기가 해당 데이터를 인덱스 세그먼트로 압축합니다. 정렬된 데이터를 사용하면 세그먼트 겹침이 감소하여 쿼리가 더 효율적으로 세그먼트를 제거할 수 있으므로 디스크에서 읽을 세그먼트 수가 더 작기 때문에 성능이 향상됩니다. 메모리에서 한 번에 모든 데이터를 정렬할 수 있는 경우 세그먼트 겹침을 방지할 수 있습니다. 데이터 웨어하우스에는 큰 테이블이 있기 때문에 이 시나리오는 자주 발생하지 않습니다.
열의 세그먼트 범위를 확인하려면 테이블 이름 및 열 이름을 사용하여 다음 명령을 실행합니다.
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
참고 항목
순서가 지정된 CCI 테이블에서 DML 또는 데이터 로드 작업의 동일한 일괄 처리로 생성되는 새 데이터는 해당 일괄 처리 내에서 정렬되며 테이블의 모든 데이터에서 전체 정렬이 없습니다. 사용자는 순서가 지정된 CCI를 다시 빌드하여 테이블의 모든 데이터를 정렬할 수 있습니다. 전용 SQL 풀에서 columnstore 인덱스 다시 빌드는 오프라인 작업입니다. 분할된 테이블의 경우 다시 빌드는 한 번에 하나의 파티션에서 수행됩니다. 다시 빌드되는 파티션의 데이터는 “오프라인” 상태이며 해당 파티션에 대해 다시 빌드가 완료될 때까지 사용할 수 없습니다.
쿼리 성능
순서가 지정된 CCI의 쿼리 성능 향상은 쿼리 패턴, 데이터 크기, 데이터 정렬 방법, 세그먼트의 물리적 구조 및 쿼리 실행을 위해 선택한 DWU 및 리소스 클래스에 따라 달라집니다. 사용자는 순서가 지정된 CCI 테이블을 디자인할 때 순서 지정 열을 선택하기 전에 모든 요소를 검토해야 합니다.
모든 패턴이 포함된 쿼리는 일반적으로 순서가 지정된 CCI를 사용하여 더 빠르게 실행됩니다.
- 쿼리에는 같음, 같지 않음 또는 범위 조건자가 포함됩니다.
- 조건자 열과 순서가 지정된 CCI 열은 동일합니다.
이 예제에서 테이블 T1에는 Col_C, Col_B 및 Col_A 시퀀스로 순서가 지정된 클러스터형 columnstore 인덱스가 있습니다.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
쿼리 1 및 쿼리 2의 성능은 정렬된 모든 CCI 열을 참조하므로 다른 쿼리보다 정렬된 CCI를 통해 많은 이점을 얻을 수 있습니다.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
데이터 로드 성능
순서가 지정된 CCI 테이블에 대한 데이터 로드 성능은 분할된 테이블과 비슷합니다. 데이터 정렬 작업으로 인해 순서가 지정되지 않은 CCI 테이블보다 순서가 지정된 CCI 테이블에 데이터를 로드하는 데 시간이 오래 걸릴 수 있지만, 나중에 순서가 지정된 CCI를 사용하여 쿼리를 더 빠르게 실행할 수 있습니다.
다양한 스키마를 사용하는 테이블에 대한 데이터 로드의 성능 비교 예는 다음과 같습니다.
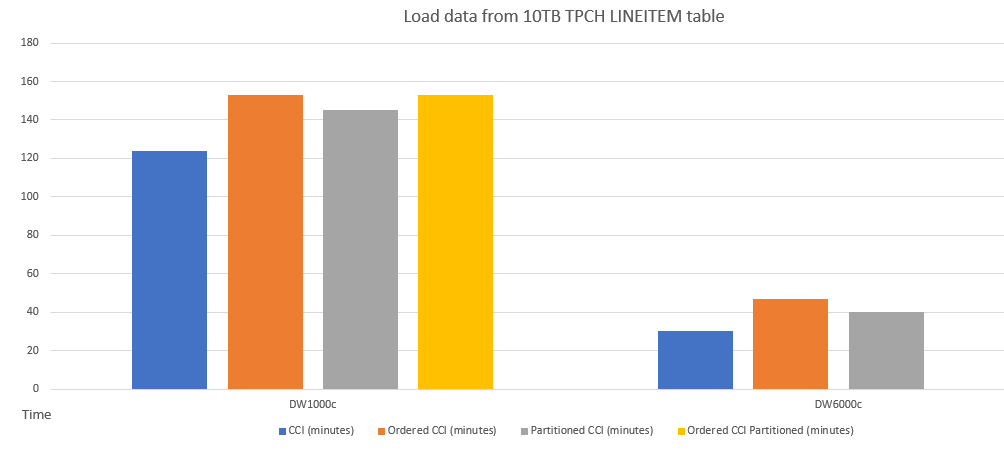
CCI와 순서가 지정된 CCI 간 쿼리 성능 비교 예는 다음과 같습니다.

세그먼트 겹침 줄이기
겹치는 세그먼트 수는 순서가 지정된 CCI를 만드는 동안 정렬할 데이터 크기, 사용 가능한 메모리 및 최대 병렬 처리 수준(MAXDOP) 설정에 따라 달라집니다. 다음 전략은 순서가 지정된 CCI를 만들 때 세그먼트 겹침을 줄입니다.
더 높은 DWU에서
xlargerc리소스 클래스를 사용하면 인덱스 작성기가 데이터를 세그먼트로 압축하기 전에 데이터 정렬에 더 많은 메모리를 사용할 수 있습니다. 인덱스 세그먼트에서 데이터의 물리적 위치를 변경할 수는 없습니다. 세그먼트 내 또는 세그먼트 간에는 데이터 정렬이 없습니다.OPTION (MAXDOP = 1)을 사용하여 순서가 지정된 CCI를 만듭니다. 순서가 지정된 CCI 만들기에 사용되는 각 스레드는 데이터의 하위 집합에서 작동하며 데이터를 로컬로 정렬합니다. 서로 다른 스레드에 의해 정렬된 데이터에서는 전체 정렬이 없습니다. 병렬 스레드를 사용하면 순서가 지정된 CCI를 만드는 시간을 줄일 수 있지만 단일 스레드를 사용하는 것보다 겹치는 세그먼트가 더 많이 생성됩니다. 단일 스레드 작업을 사용하면 최고의 압축 품질을 제공합니다. 예시:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
참고 항목
현재 Azure Synapse Analytics의 전용 SQL 풀에서 MAXDOP 옵션은 CREATE TABLE AS SELECT 명령을 사용하여 정렬된 CCI 테이블을 만드는 경우에만 지원됩니다. CREATE INDEX 또는 CREATE TABLE 명령을 통해 정렬된 CCI 만들기는 MAXDOP 옵션을 지원하지 않습니다. 이 제한은 CREATE INDEX 또는 CREATE TABLE 명령으로 MAXDOP를 지정할 수 있는 SQL Server 2022 이상 버전에는 적용되지 않습니다.
- 데이터를 테이블에 로드하기 전에 정렬 키를 기준으로 데이터를 미리 정렬합니다.
위의 권장 사항에 따라 세그먼트가 겹치지 않는 순서가 지정된 CCI 테이블 배포 예는 다음과 같습니다. 순서가 지정된 CCI 테이블은 MAXDOP 1 및 xlargerc를 사용하여 20GB 힙 테이블의 CTAS를 통해 DWU1000c 데이터베이스에 만들어집니다. CCI는 중복 없이 BIGINT 열에서 순서가 지정됩니다.
큰 테이블에서 순서가 지정된 CCI 만들기
순서가 지정된 CCI를 만드는 작업은 오프라인 작업입니다. 파티션이 없는 테이블의 경우에는 순서가 지정된 CCI 만들기 프로세스가 완료될 때까지 사용자가 데이터에 액세스할 수 없습니다. 분할된 테이블의 경우에는 엔진이 파티션별로 순서가 지정된 CCI 파티션을 만들기 때문에 사용자는 순서가 지정된 CCI 만들기가 진행되지 않는 파티션의 데이터에 계속 액세스할 수 있습니다. 이 옵션을 사용하여 큰 테이블에서 순서가 지정된 CCI를 만드는 동안 가동 중지 시간을 최소화할 수 있습니다.
- 대상 큰 테이블(
Table_A라고 함)에 파티션을 만듭니다. Table_A와 동일한 테이블 및 파티션 스키마를 사용하여 정렬된 빈 CCI 테이블(Table_B라고 함)을 만듭니다.- 하나의 파티션을
Table_A에서Table_B로 전환합니다. ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>를 실행하여Table_B에서 전환된 파티션을 다시 빌드합니다.Table_A의 각 파티션에 대해 3단계와 4단계를 반복합니다.- 모든 파티션이
Table_A에서Table_B로 전환되고 다시 빌드되면Table_A를 삭제하고Table_B의 이름을Table_A로 바꿉니다.
팁
순서가 지정된 CCI를 포함하는 전용 SQL 풀 테이블의 경우 ALTER INDEX REBUILD는 tempdb를 사용하여 데이터를 다시 정렬합니다. 다시 빌드 작업 중 tempdb를 모니터링합니다. tempdb 공간이 더 필요하면 풀을 스케일 업합니다. 인덱스 다시 빌드가 완료되면 다시 크기를 줄입니다.
순서가 지정된 CCI를 포함하는 전용 SQL 풀 테이블의 경우 ALTER INDEX REORGANIZE는 데이터를 다시 정렬하지 않습니다. 데이터를 다시 정렬하려면 ALTER INDEX REBUILD를 사용합니다.
순서가 지정된 CCI 유지 관리에 관한 자세한 내용은 클러스터형 columnstore 인덱스 최적화를 참조하세요.
SQL Server 2022 기능의 기능 차이점
SQL Server 2022(16.x)에는 Azure Synapse 전용 SQL 풀의 기능과 유사한 정렬된 클러스터형 columnstore 인덱스가 도입되었습니다.
- 현재 SQL Server 2022(16.x) 이상 버전에서만 문자열, 이진 및 guid 데이터 형식에 대한 클러스터형 columnstore 향상된 세그먼트 제거 기능과 2보다 큰 배율에 대한 datetimeoffset 데이터 형식을 지원합니다. 이전에는 이 세그먼트 제거가 숫자, 날짜 및 시간 데이터 형식과 배율이 2보다 작거나 같은 datetimeoffset 데이터 형식에 적용되었습니다.
- 현재 SQL Server 2022(16.x) 이상 버전만
LIKE조건자의 접두사(예:column LIKE 'string%')에 대한 클러스터형 columnstore 행 그룹 제거를 지원합니다.column LIKE '%string'과 같은 LIKE의 비접두사 사용에 대해서는 세그먼트 제거가 지원되지 않습니다.
자세한 내용은 Columnstore 인덱스의 새로운 기능을 참조하세요.
예제
A. 순서가 지정된 열 순서 서수를 확인하려면:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. 열 서수를 변경하거나, 순서 목록에서 열을 추가 또는 제거하거나, CCI에서 순서가 지정된 CCI로 변경하려면:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
다음 단계
- 더 많은 개발 팁은 개발 개요를 참조하세요.
- Columnstore 인덱스: 개요
- columnstore 인덱스의 새로운 기능
- Columnstore 인덱스 - 디자인 지침
- Columnstore 인덱스 쿼리 성능