CSV 파일 쿼리
이 문서에서는 Azure Synapse Analytics에서 서버리스 SQL 풀을 사용하여 단일 CSV 파일을 쿼리하는 방법에 대해 알아봅니다. CSV 파일의 형식은 서로 다를 수 있습니다.
- 헤더 행 포함 또는 제외
- 쉼표 및 탭으로 구분된 값
- Windows 및 Unix 스타일 줄 끝
- 따옴표가 붙지 않은 값 및 따옴표가 붙은 값과 문자 이스케이프
위의 모든 변형은 아래에서 다룹니다.
빠른 시작 예제
OPENROWSET 함수를 사용하면 파일에 대한 URL을 제공하여 CSV 파일의 콘텐츠를 읽을 수 있습니다.
CSV 파일 읽기
CSV 파일의 콘텐츠를 확인하는 가장 쉬운 방법은 OPENROWSET 함수에 파일 URL을 제공하고 csv FORMAT 및 2.0 PARSER_VERSION을 지정하는 것입니다. 파일이 공개적으로 사용 가능하거나 Microsoft Entra ID가 이 파일에 액세스할 수 있는 경우 다음 예에 표시된 것과 같은 쿼리를 사용하여 파일의 콘텐츠를 볼 수 있습니다.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
firstrow 옵션은 이 경우에 헤더를 나타내는 CSV 파일의 첫 번째 행을 건너뛰는 데 사용됩니다. 이 파일에 액세스할 수 있는지 확인합니다. 파일이 SAS 키 또는 사용자 지정 ID를 통해 보호되는 경우 sql 로그인에 대한 서버 수준 자격 증명을 설정해야 합니다.
Important
CSV 파일에 UTF-8 문자가 포함된 경우 UTF-8 데이터베이스 데이터 정렬을 사용하고 있는지 확인합니다(예: Latin1_General_100_CI_AS_SC_UTF8).
파일의 텍스트 인코딩과 데이터 정렬이 일치하지 않으면 예기치 않은 변환 오류가 발생할 수 있습니다.
다음 T-SQL 문 alter database current collate Latin1_General_100_CI_AI_SC_UTF8을 사용하여 현재 데이터베이스의 기본 데이터 정렬을 쉽게 변경할 수 있습니다.
데이터 원본 사용
이전 예제에서는 파일에 전체 경로를 사용했습니다. 전체 경로 대신 스토리지의 루트 폴더를 가리키는 위치를 사용하여 외부 데이터 원본을 만들 수 있습니다.
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
데이터 원본을 만든 후에는 OPENROWSET 함수에서 해당 데이터 원본 및 파일의 상대 경로를 사용할 수 있습니다.
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
데이터 원본이 SAS 키 또는 사용자 지정 ID를 통해 보호되는 경우 데이터베이스 범위 자격 증명을 사용하여 데이터 원본을 구성할 수 있습니다.
스키마를 명시적으로 지정
OPENROWSET을 사용하면 WITH 절을 사용하여 파일에서 읽을 열을 명시적으로 지정할 수 있습니다.
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
WITH 절에서 데이터 형식 뒤의 숫자는 CSV 파일의 열 인덱스를 나타냅니다.
Important
CSV 파일에 UTF-8 문자가 포함된 경우 WITH 절의 모든 열에 대해 UTF-8 데이터 정렬(예: Latin1_General_100_CI_AS_SC_UTF8)을 명시적으로 지정하거나 데이터베이스 수준에서 UTF-8 데이터 정렬을 설정합니다.
파일의 텍스트 인코딩과 데이터 정렬이 일치하지 않으면 예기치 않은 변환 오류가 발생할 수 있습니다.
다음 T-SQL 문을 사용하여 현재 데이터베이스의 기본 데이터 정렬을 쉽게 변경할 수 있습니다. alter database current collate Latin1_General_100_CI_AI_SC_UTF8 다음 정의를 사용하여 열 형식에 대한 데이터 정렬을 쉽게 설정할 수 있습니다. geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
다음 섹션에서는 다양한 유형의 CSV 파일을 쿼리하는 방법을 알아볼 수 있습니다.
필수 조건
첫 번째 단계는 테이블을 만들 데이터베이스를 만드는 것입니다. 그런 다음 해당 데이터베이스에서 설치 스크립트를 실행하여 개체를 초기화합니다. 이 설치 스크립트는 이러한 샘플에서 사용되는 데이터 원본, 데이터베이스 범위 자격 증명 및 외부 파일 형식을 만듭니다.
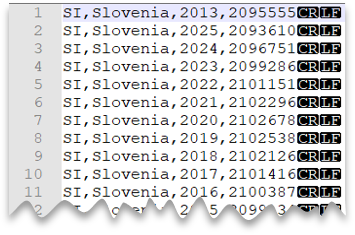
Windows 스타일 줄 바꿈
다음 쿼리는 Windows 스타일 새 행과 쉼표로 구분된 열을 사용하여 헤더 행 없는 CSV 파일을 읽는 방법을 보여 줍니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
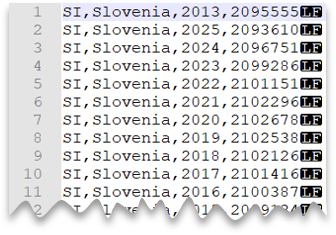
Unix 스타일 줄 바꿈
다음 쿼리에서는 헤더 행이 없이 Unix 스타일 줄 바꿈 및 쉼표로 구분된 열로 구성된 파일을 읽는 방법을 보여 줍니다. 다른 예와 비교하면 파일의 위치가 다르다는 것을 알 수 있습니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
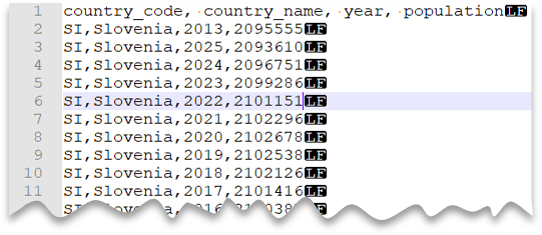
헤더 행
다음 쿼리는 헤더 행이 있고 Unix 스타일 줄 바꿈 및 쉼표로 구분된 열로 구성된 파일을 읽는 방법을 보여 줍니다. 다른 예와 비교하면 파일의 위치가 다르다는 것을 알 수 있습니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
HEADER_ROW = TRUE 옵션은 파일의 헤더 행에서 열 이름을 읽습니다. 파일 내용에 익숙하지 않은 경우 탐색 용도로 사용하기에 좋습니다. 최상의 성능을 위해 모범 사례에서 적절한 데이터 형식 사용 섹션을 참조하세요. 또한 여기에서 OPENROWSET 구문에 대해 자세히 알아볼 수 있습니다.
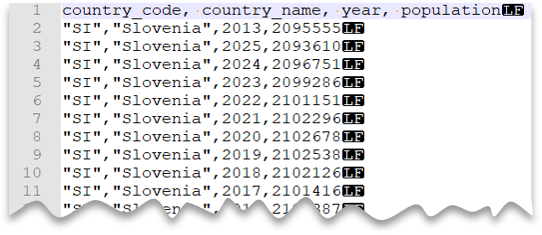
사용자 지정 따옴표
다음 쿼리에서는 헤더 행이 있고 Unix 스타일 줄 바꿈, 쉼표로 구분된 열 및 따옴표가 붙은 값으로 구성된 파일을 읽는 방법을 보여 줍니다. 다른 예와 비교하면 파일의 위치가 다르다는 것을 알 수 있습니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
참고 항목
FIELDQUOTE의 기본값은 큰따옴표이므로 FIELDQUOTE 매개 변수를 생략하면 이 쿼리는 동일한 결과를 반환합니다.
이스케이프 문자
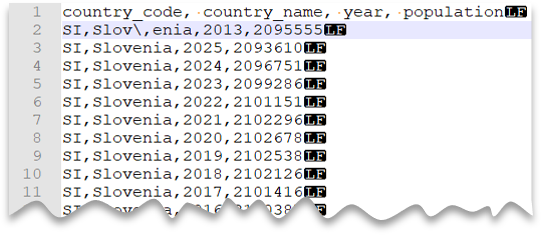
다음 쿼리에서는 헤더 행이 있고 Unix 스타일 줄 바꿈, 쉼표로 구분된 열 및 값 내의 필드 구분 기호(쉼표)에 사용되는 이스케이프 문자로 구성된 파일을 읽는 방법을 보여 줍니다. 다른 예와 비교하면 파일의 위치가 다르다는 것을 알 수 있습니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
참고 항목
"Slov,enia"의 쉼표가 국가/지역 이름의 일부가 아니라 필드 구분 기호로 처리되기 때문에 ESCAPECHAR를 지정하지 않으면 이 쿼리는 실패합니다. "Slov,enia"는 두 개의 열로 처리됩니다. 따라서 특정 행에는 다른 행보다 하나의 열이 더 있고, WITH 절에서 정의한 것보다 하나의 열이 더 있습니다.
이스케이프 따옴표 문자
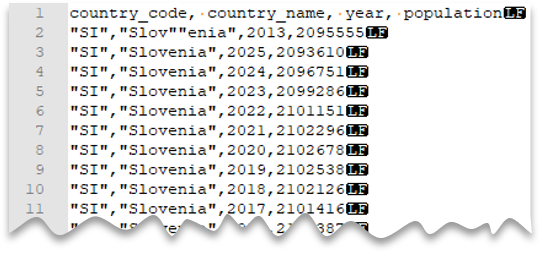
다음 쿼리에서는 헤더 행, Unix 스타일 줄 바꿈, 쉼표로 구분된 열 및 값 내에서 이스케이프된 큰따옴표가 있는 파일을 읽는 방법을 보여 줍니다. 다른 예와 비교하면 파일의 위치가 다르다는 것을 알 수 있습니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
참고 항목
따옴표 문자는 다른 따옴표 문자로 이스케이프해야 합니다. 따옴표로 묶은 문자는 값이 따옴표 문자로 캡슐화된 경우에만 열 값 내에 나타날 수 있습니다.
탭으로 구분된 파일
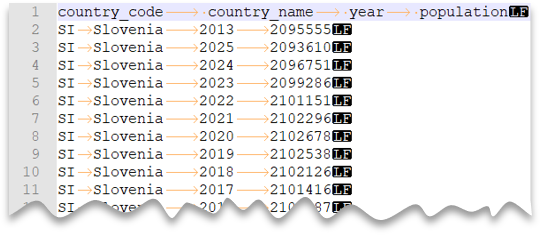
다음 쿼리는 헤더 행이 있고 Unix 스타일 줄 바꿈 및 탭으로 구분된 열로 구성된 파일을 읽는 방법을 보여 줍니다. 다른 예와 비교하면 파일의 위치가 다르다는 것을 알 수 있습니다.
파일 미리 보기:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
열의 하위 집합 반환
지금까지 WITH를 사용하고 모든 열을 나열하는 CSV 파일 스키마를 지정했습니다. 필요한 각 열에 서수를 사용하여 쿼리에 실제로 필요한 열만 지정할 수 있습니다. 또한 관심이 없는 열은 생략합니다.
다음 쿼리는 필요한 열만 지정하여 파일의 고유한 국가/지역 이름 수를 반환합니다.
참고 항목
아래 쿼리의 WITH 절을 보면 [country_name] 열을 정의하는 행의 끝에 "2"(따옴표 제외)가 있습니다. 이는 [country_name] 열이 파일의 두 번째 열임을 의미합니다. 이 쿼리는 파일에서 두 번째 열을 제외한 모든 열을 무시합니다.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
추가 가능한 파일 쿼리
쿼리가 실행되는 동안에는 쿼리에 사용되는 CSV 파일을 변경하지 않아야 합니다. 장기 실행 쿼리에서 SQL 풀은 읽기를 재시도하거나 파일의 일부를 읽거나 여러 번 파일을 읽을 수도 있습니다. 파일 내용을 변경하면 잘못된 결과가 발생할 수 있습니다. 따라서 쿼리 실행 중에 파일의 수정 시간 변경이 감지하면 SQL 풀은 쿼리에 실패합니다.
일부 시나리오에서는 지속적으로 추가되는 파일을 읽을 수 있습니다. 지속적으로 추가되는 파일로 인한 쿼리 실패를 방지하려면 ROWSET_OPTIONS 설정을 사용하여 OPENROWSET 함수가 잠재적으로 일치하지 않는 읽기를 무시하도록 지정할 수 있습니다.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
ALLOW_INCONSISTENT_READS 읽기 옵션은 쿼리 수명 주기 동안 파일 수정 시간 확인을 사용하지 않고 파일에서 사용 가능한 모든 것을 읽습니다. 추가 가능한 파일에서 기존 내용은 업데이트되지 않고 새 행만 추가됩니다. 따라서 업데이트 가능한 파일에 비해 결과가 잘못될 가능성이 최소화됩니다. 이 옵션을 사용하면 오류를 처리하지 않고 자주 추가되는 파일을 읽을 수 있습니다. 대부분의 시나리오에서 SQL 풀은 쿼리를 실행하는 동안 파일에 추가되는 일부 행만 무시합니다.
다음 단계
다음 문서에서는 다음을 수행하는 방법을 보여 줍니다.