SAP HANA용 Azure NetApp Files 기반 NFS v4.1 볼륨
Azure NetApp Files는 /hana/shared, /hana/data 및 /hana/log 볼륨에 사용할 수 있는 네이티브 NFS 공유를 제공합니다. /hana/data 및 /hana/log 볼륨에 ANF 기반 NFS 공유를 사용하려면 v4.1 NFS 프로토콜을 사용해야 합니다. 공유가 ANF를 기반으로 하는 경우 NFS 프로토콜 v3은 /hana/data 및 /hana/log 볼륨에서 사용이 지원되지 않습니다.
Important
Azure NetApp Files에서 구현된 NFS v3 프로토콜은 /hana/data 및 /hana/log에서 사용이 지원되지 않습니다. /hana/data 및 /hana/log 볼륨에는 기능 관점에서 NFS 4.1 사용이 필수입니다. 반면 /hana/shared 볼륨에는 기능 관점에서 NFS v3 또는 NFS v4.1 프로토콜을 사용할 수 있습니다.
중요 고려 사항
SAP Netweaver 및 SAP HANA에 Azure NetApp Files를 고려하는 경우 다음과 같은 중요한 사항을 고려해야 합니다.
최소 용량 풀은 4TiB입니다.
최소 볼륨 크기는 100GiB입니다.
ANF 기반 NFS 공유 및 해당 공유를 탑재하는 가상 머신은 동일한 Azure Virtual Network 또는 동일한 지역의 피어링된 가상 네트워크에 있어야 함
선택한 가상 네트워크에 Azure NetApp Files로 위임된 서브넷이 있어야 합니다. SAP 워크로드의 경우 ANF에 위임된 서브넷에 대해 /25 범위를 구성하는 것이 좋습니다.
예를 들어 다시 실행 로그 쓰기를 위해 SAP HANA에서 요구하는 것처럼 대기 시간을 줄이기 위해 가상 머신을 Azure NetApp Storage에 충분히 근접하게 배포하는 것이 중요합니다.
- 한편 Azure NetApp Files에는 특정 Azure 가용성 영역에 NFS 볼륨을 배포하는 기능이 있습니다. 이러한 영역 근접성은 대부분의 경우 1밀리초 미만의 대기 시간을 달성하는 데 충분합니다. 이 기능은 공개 미리보기로 제공되며 Azure NetApp Files에 대한 가용성 영역 볼륨 배치 관리 문서에 설명되어 있습니다. 이 기능은 VM과 할당한 NFS 볼륨 간의 근접성을 달성하기 위해 Microsoft와의 대화형 프로세스가 필요하지 않습니다.
- 최적의 근접성을 구현하기 위해 애플리케이션 볼륨 그룹 기능을 사용할 수 있습니다. 이 기능은 최적의 근접성을 찾을 뿐 아니라 NFS 볼륨의 최적 배치를 찾아 HANA 데이터와 다시 실행 로그 볼륨을 서로 다른 컨트롤러에서 처리합니다. 단점은 이 메서드가 VM을 고정하기 위해 Microsoft와의 대화형 프로세스가 필요하다는 것입니다.
데이터베이스 서버에서 ANF 볼륨까지의 대기 시간이 1밀리초 미만으로 측정되는지 확인합니다.
Azure NetApp 볼륨의 처리량은 Azure NetApp Files에 대한 서비스 수준에 설명된 대로 볼륨 할당량과 서비스 수준의 함수입니다. HANA Azure NetApp 볼륨을 크기 조정할 때 결과 처리량이 HANA 시스템 요구 사항을 충족해야 합니다. 또는 볼륨 용량 및 처리량을 독립적으로 구성하고 크기를 조정할 수 있는 수동 QoS 용량 풀을 사용하는 것이 좋습니다(SAP HANA 관련 예제는 이 문서 참조).
볼륨을 "통합"하여 더 큰 볼륨에서 더 많은 성능을 얻으세요. 예를 들어 /sapmnt, /usr/sap/trans, ...에 대해 하나의 볼륨을 사용합니다. 가능한 경우
Azure NetApp Files는 내보내기 정책을 제공합니다. 사용자는 허용되는 클라이언트, 액세스 유형(읽기 및 쓰기, 읽기 전용 등)을 제어할 수 있습니다.
가상 머신의 sidadm 사용자 ID와
sapsys그룹 ID가 Azure NetApp Files의 구성과 일치해야 합니다.SAP Note 3024346에 언급된 Linux OS 매개 변수 구현
Important
SAP HANA 워크로드의 경우 짧은 대기 시간이 매우 중요합니다. Microsoft 담당자와 협력하여 가상 머신과 Azure NetApp Files 볼륨이 근접하게 배포되도록 해야 합니다.
Important
가상 머신과 Azure NetApp 구성 간에 sidadm 사용자 ID 및 sapsys 그룹 ID가 일치하지 않는 경우 VM에 탑재된 Azure NetApp 볼륨의 파일에 대한 권한은 nobody로 표시됩니다. Azure NetApp Files에 새 시스템을 온보딩할 때 sidadm 사용자 ID 및 sapsys 그룹 ID를 올바로 지정해야 합니다.
NCONNECT 탑재 옵션
Nconnect는 NFS 클라이언트가 단일 NFS 볼륨에 대해 여러 세션을 열 수 있도록 허용하는 ANF에서 호스팅되는 NFS 볼륨에 대한 탑재 옵션입니다. 값이 1보다 큰 nconnect를 사용하면 NFS 클라이언트가 클라이언트 쪽(게스트 OS)에서 둘 이상의 RPC 세션을 사용하여 게스트 OS와 탑재된 NFS 볼륨 간의 트래픽을 처리하도록 트리거합니다. 하나의 NFS 볼륨의 트래픽을 처리하는 여러 세션의 사용뿐만 아니라 여러 RPC 세션의 사용은 다음과 같은 성능 및 처리량 시나리오를 해결할 수 있습니다.
- 하나의 VM에서 서로 다른 서비스 수준으로 여러 ANF 호스팅 NFS 볼륨 탑재
- 용량과 단일 Linux 세션의 최대 쓰기 처리량은 1.2~1.4GB/초입니다. 하나의 ANF 호스팅 NFS 볼륨에 대해 여러 세션을 보유하면 처리량이 증가할 수 있습니다.
탑재 옵션으로 nconnect를 지원하는 Linux OS 릴리스 및 특히 다른 NFS 서버 엔드포인트가 있는 nconnect의 몇 가지 중요한 구성 고려 사항은 Azure NetApp Files에 대한 Linux NFS 탑재 옵션 모범 사례 문서를 참조하세요.
Azure NetApp Files에서 HANA 데이터베이스 크기 조정
Azure NetApp 볼륨의 처리량은 Azure NetApp Files에 대한 서비스 수준에 설명된 대로 볼륨 크기와 서비스 수준의 함수입니다.
크기 및 성능 관계와 서비스의 스토리지 엔드포인트에 대한 물리적 제한이 있다는 점을 이해하는 것이 중요합니다. 각 스토리지 엔드포인트는 볼륨을 만들 때 위임된 서브넷 Azure NetApp Files에 동적으로 삽입되며 IP 주소를 받습니다. Azure NetApp Files 볼륨은 사용 가능한 용량 및 배포 논리에 따라 스토리지 엔드포인트를 공유합니다
아래 표는 단일 용량의 최대 물리적 대역폭 용량을 초과하기 때문에 백업을 저장하기 위해 큰 "Standard" 볼륨을 만드는 것이 합리적이며 12TB 이상의 "Ultra" 볼륨을 만드는 것은 의미가 없음을 보여줍니다.
단일 Linux 세션이 제공할 수 있는 것보다 /hana/data 볼륨에 대한 최대 쓰기 처리량 이상이 필요한 경우 대안으로 SAP HANA 데이터 볼륨 분할을 사용할 수도 있습니다. SAP HANA 데이터 볼륨 파티셔닝은 데이터를 다시 로드하는 동안 I/O 작업을 스트라이핑하거나 여러 NFS 공유에 있는 여러 HANA 데이터 파일에 대해 HANA 저장점을 스트라이핑합니다. HANA 데이터 볼륨 스트라이핑에 대한 자세한 내용은 다음 문서를 참조하세요.
| 크기 | 처리량 Standard | 처리량 Premium | 처리량 Ultra |
|---|---|---|---|
| 1TB | 16MB/초 | 64MB/초 | 128MB/초 |
| 2TB | 32MB/초 | 128MB/초 | 256MB/초 |
| 4 TB | 64MB/초 | 256MB/초 | 512MB/초 |
| 10TB | 160MB/초 | 640MB/초 | 1,280MB/초 |
| 15TB | 240MB/초 | 960MB/초 | 1,400MB/초1 |
| 20TB | 320MB/초 | 1,280MB/초 | 1,400MB/초1 |
| 40TB | 640MB/초 | 1,400MB/초1 | 1,400MB/초1 |
1: 쓰기 또는 단일 세션 읽기 처리량 제한(NFS 탑재 옵션 nconnect가 사용되지 않는 경우)
데이터가 스토리지 백 엔드의 동일한 SSD에 기록된다는 점을 이해하는 것이 중요합니다. 환경을 관리할 수 있도록 용량 풀의 성능 할당량이 생성되었습니다. 스토리지 KPI는 모든 HANA 데이터베이스 크기에 대해 동일합니다. 거의 모든 경우에서 이러한 가정은 현실과 고객의 기대를 반영하지 않습니다. HANA 시스템의 크기는 반드시 작은 시스템의 스토리지 처리량은 낮아야 하고, 큰 시스템의 스토리지 처리량은 커야 한다는 의미가 아닙니다. 그러나 일반적으로 대규모 HANA 데이터베이스 인스턴스에 대한 처리량 요구 사항이 더 높을 것으로 예상할 수 있습니다. 기본 하드웨어에 대한 SAP의 크기 조정 규칙의 결과로 이러한 대규모 HANA 인스턴스는 인스턴스 재시작 후 데이터 로드와 같은 작업에서 더 많은 CPU 리소스를 제공하고 더 높은 병렬성을 제공합니다. 결과적으로 볼륨 크기는 고객의 기대와 요구 사항에 맞게 채택되어야 합니다. 그리고 순수 용량 요구 사항에 따라 달라지는 것도 아닙니다.
Azure에서 SAP용 인프라를 설계할 때 SAP의 최소 스토리지 처리량 요구 사항(프로덕션 시스템)에 대해 알고 있어야 합니다. 이러한 요구 사항은 다음의 최소 처리량 특성으로 변환됩니다.
| 볼륨 유형 및 I/O 유형 | SAP에서 요구하는 최소 KPI | Premium 서비스 계층 | Ultra 서비스 수준 |
|---|---|---|---|
| 로그 볼륨 쓰기 | 250MB/초 | 4 TB | 2TB |
| 데이터 볼륨 쓰기 | 250MB/초 | 4 TB | 2TB |
| 데이터 볼륨 읽기 | 400MB/초 | 6.3TB | 3.2TB |
세 가지 KPI가 모두 요구되므로 최소 읽기 요구 사항을 충족하려면 /hana/data 볼륨의 크기를 더 큰 용량으로 조정해야 합니다. 수동 QoS 용량 풀을 사용하는 경우 볼륨의 크기와 처리량을 독립적으로 정의할 수 있습니다. 용량과 처리량은 모두 동일한 용량 풀에서 가져와야 하므로 풀의 서비스 수준과 크기는 총 성능을 제공할 수 있을 만큼 충분히 커야 합니다(여기에 나와 있는 예제 참조).
높은 대역폭이 필요하지 않은 HANA 시스템의 경우 볼륨 크기를 줄이거나, 수동 QoS를 사용하거나, 처리량을 직접 조정하여 ANF 볼륨 처리량을 낮출 수 있습니다. HANA 시스템에 더 많은 처리량이 필요한 경우 온라인으로 용량 크기를 조정하여 볼륨을 조정할 수 있습니다. 백업 볼륨에 대해 정의된 KPI는 없습니다. 그러나 백업 볼륨 처리량은 성능이 좋은 환경에 필수적입니다. 로그 및 데이터 볼륨 성능은 고객의 기대에 맞게 설계되어야 합니다.
Important
단일 NFS 볼륨에 배포하는 용량에 관계없이 처리량은 단일 세션의 소비자가 활용하는 1.2~1.4GB/초 대역폭의 범위에서 안정될 것으로 예상됩니다. 이는 ANF 제품의 기본 아키텍처와 NFS 관련 Linux 세션 제한과 관련이 있습니다. Azure NetApp Files에 대한 성능 벤치 마크 테스트 결과 문서에 설명된 성능 및 처리량 수치는 여러 클라이언트 VM이 있는 한 공유 NFS 볼륨에서 여러 세션에 걸쳐 테스트한 결과입니다. 이 시나리오는 SAP에서 측정하는 시나리오와 다릅니다. 즉, ANF에서 호스트되는 단일 NFS 볼륨에 대해 단일 VM에서 처리량을 측정합니다.
데이터 및 로그에 대한 SAP 최소 처리량 요구 사항을 충족하기 위해 또한 /hana/shared에 대한 지침에 따라 권장 크기는 다음과 같습니다.
| 볼륨 | 크기 Premium Storage 계층 |
크기 Ultra Storage 계층 |
지원되는 NFS 프로토콜 |
|---|---|---|---|
| /hana/log/ | 4TiB | 2TiB | v4.1 |
| /hana/data | 6.3TiB | 3.2TiB | v4.1 |
| /hana/shared 스케일 업 | 최소(1TB, 1 x RAM) | 최소(1TB, 1 x RAM) | v3 또는 v4.1 |
| /hana/shared 스케일 아웃 | 작업자 노드의 1 x RAM 4개 작업자 노드 당 |
작업자 노드의 1 x RAM 4개 작업자 노드 당 |
v3 또는 v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 또는 v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 또는 v4.1 |
모든 볼륨에 NFS v4.1을 사용할 것을 강력하게 권장합니다.
적절한 크기의 /hana/shared 볼륨이 시스템의 안정성에 기여하므로 /hana/shared 크기 조정에 대한 고려 사항을 신중하게 검토합니다.
백업 볼륨의 크기는 추정치입니다. 정확한 요구 사항은 워크로드 및 운영 프로세스에 따라 정의해야 합니다. 백업의 경우 다양한 SAP HANA 인스턴스에 대한 많은 볼륨을 하나(또는 두 개)의 더 큰 볼륨으로 통합할 수 있으며, ANF의 서비스 수준이 더 낮을 수 있습니다.
참고
이 설명서에 명시된 Azure NetApp Files 크기 조정 권장 사항은 SAP가 인프라 공급자에게 제시하는 최소 요구 사항을 대상으로 합니다. 실제 고객 배포 및 워크로드 시나리오에서는 충분하지 않을 수 있습니다. 이러한 권장 사항을 시작점으로 삼아 워크로드의 요구 사항에 따라 조정합니다.
따라서 Ultra Disk 스토리지에 대해 나열된 것처럼 ANF 볼륨에 비슷한 처리량을 배포하는 것을 고려할 수 있습니다. 또한 이미 Ultra Disk 테이블에서 수행한 것처럼 다른 VM SKU의 볼륨에 대해 나열된 크기에 대해서도 크기를 고려합니다.
팁
볼륨을 unmount하거나 가상 머신을 중지하거나 SAP HANA를 중지하지 않고도 Azure NetApp Files 볼륨의 크기를 동적으로 조정할 수 있습니다. 그러므로 애플리케이션이 예상된 처리량 수요와 예측하지 못한 처리량 수요를 모두 충족할 수 있습니다.
ANF 기반 NFS v4.1 볼륨을 사용하는 대기 노드로 SAP HANA 스케일 아웃 구성을 배포하는 방법에 대한 설명서는 SUSE Linux Enterprise Server의 Azure NetApp Files를 사용하여 Azure VM의 대기 노드로 SAP HANA 스케일 아웃에 게시되어 있습니다.
Linux 커널 설정
ANF Linux에 SAP HANA를 성공적으로 배포하려면 SAP Note 3024346에 따라 커널 설정을 구현해야 합니다.
Pacemaker 및 Azure Load Balancer를 사용하여 고가용성(HA)을 사용하는 시스템의 경우 다음 설정을 /etc/sysctl.d/91-NetApp-HANA.conf 파일에서 구현해야 합니다.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Pacemaker 및 Azure Load Balancer 없이 실행되는 시스템은 /etc/sysctl.d/91-NetApp-HANA.conf에서 이러한 설정을 구현해야 합니다.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
영역 근접성을 사용하여 배포
NFS 볼륨 및 VM의 영역 근접성을 얻으려면 Azure NetApp Files에 대한 가용성 영역 볼륨 배치 관리에 설명된 지침을 따르세요. 이 메서드를 사용하면 VM 및 NFS 볼륨이 동일한 Azure 가용성 영역에 있습니다. 대부분의 Azure 지역에서 이 유형의 근접성은 SAP HANA에 대한 더 작은 다시 실행 로그 쓰기에 대해 1밀리초 미만의 대기 시간을 달성하기에 충분해야 합니다. 이 메서드는 특정 데이터 센터에 VM을 배치하고 고정하기 위해 Microsoft와의 대화형 작업이 필요하지 않습니다. 따라서 배포한 가용성 영역에서 제공되는 모든 VM 유형 및 제품군 내에서 VM 크기 및 제품군을 유연하게 변경할 수 있습니다. 따라서 변화하는 조건에 유연하게 대응하거나 비용 효율적인 VM 크기 또는 제품군으로 더 빠르게 이동할 수 있습니다. 이 메서드는 1밀리초에 가까운 다시 실행 로그 대기 시간으로 작업할 수 있는 비프로덕션 및 프로덕션 시스템에 권장합니다. 이 기능은 현재 공개 미리 보기로 제공됩니다.
SAP HANA용 Azure NetApp Files 애플리케이션 볼륨 그룹(AVG)을 통한 배포
VM에 근접하게 ANF 볼륨을 배포하기 위해 SAP HANA용 Azure NetApp Files 애플리케이션 볼륨 그룹(AVG)이라는 새로운 기능이 개발되었습니다. 이 기능을 설명하는 일련의 문서가 있습니다. SAP HANA용 Azure NetApp Files 애플리케이션 볼륨 그룹 이해 문서로 시작하는 것이 가장 좋습니다. 문서를 읽으면 AVG 사용 시 Azure 근접 배치 그룹도 사용된다는 것을 알게 됩니다. 근접 배치 그룹은 생성되는 볼륨과 연결하기 위해 새 기능에서 사용됩니다. HANA 시스템의 수명 동안 VM이 ANF 볼륨에서 이동되지 않도록 하려면 배포하는 각 영역에 Avset/PPG 조합을 사용하는 것이 좋습니다. 배포 순서는 다음과 같습니다.
- 양식을 사용하여 VM이 이동하지 않도록 빈 AvSet을 컴퓨팅 HW에 고정해 달라고 요청해야 합니다.
- 가용성 집합에 PPG를 할당하고 이 가용성 집합에 할당된 VM 시작
- SAP HANA 기능에 Azure NetApp Files 애플리케이션 볼륨 그룹을 사용하여 HANA 볼륨 배포
최적의 방법으로 AVG를 사용하는 근접 배치 그룹 구성은 다음과 같습니다.
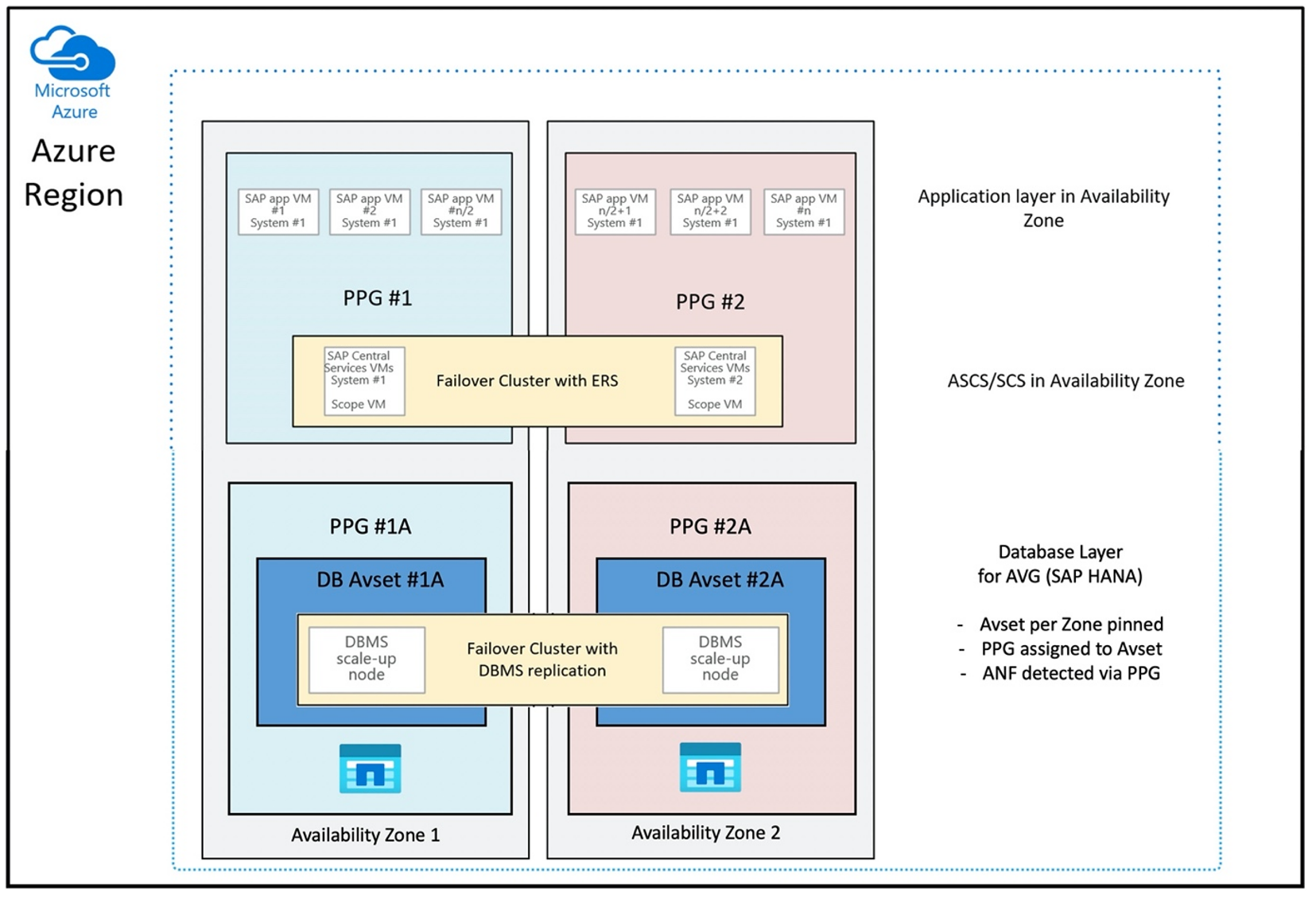
이 다이어그램은 DBMS 계층에 Azure 근접 배치 그룹을 사용하려는 경우를 보여줍니다. 따라서 AVG와 함께 사용할 수 있습니다. 근접 배치 그룹에 HANA 인스턴스를 실행하는 VM만 포함하는 것이 가장 좋습니다. AVG가 ANF 하드웨어의 가장 가까운 근접성을 식별하려면 단일 HANA 인스턴스가 있는 VM이 하나만 사용되더라도 근접 배치 그룹이 필요합니다. 그리고 NFS 볼륨을 사용하는 VM에 최대한 가깝게 ANF에 NFS 볼륨을 할당합니다.
이 메서드는 짧은 대기 시간과 관련된 가장 최적의 결과를 생성합니다. NFS 볼륨과 VM을 최대한 가깝게 가져오는 것만이 아닙니다. 그러나 NetApp 백엔드의 여러 컨트롤러에 걸쳐 데이터 및 다시 실행 로그 볼륨을 배치하는 고려 사항도 고려됩니다. 그러나 단점은 VM 배포가 하나의 데이터 센터에 고정된다는 것입니다. 이를 통해 VM 유형 및 제품군을 변경할 때 유연성을 잃게 됩니다. 결과적으로 이 메서드는 짧은 스토리지 대기 시간이 절대적으로 필요한 시스템으로 제한해야 합니다. 다른 모든 시스템의 경우 VM 및 ANF의 기존 영역 배포를 사용하여 배포를 시도해야 합니다. 대부분의 경우 짧은 대기 시간 측면에서 이 정도면 충분합니다. 이렇게 하면 VM 및 ANF를 쉽게 유지 관리하고 관리할 수 있습니다.
가용성
ANF 시스템 업데이트 및 업그레이드는 고객 환경에 영향을 주지 않고 적용됩니다. 정의된 SLA는 99.99%입니다.
볼륨, IP 주소 및 용량 풀
ANF를 사용하는 경우, 기본 인프라가 구축되는 방식을 이해하는 것이 중요합니다. 용량 풀은 용량 풀 서비스 수준에 따라 용량과 성능 예산과 청구 단위를 제공하는 구문입니다. 용량 풀은 기본 인프라와 물리적 관계가 없습니다. 서비스에서 볼륨을 만들 때 스토리지 엔드포인트가 만들어집니다. 볼륨에 대한 데이터 액세스를 제공하기 위해 이 스토리지 엔드포인트에 단일 IP 주소가 할당됩니다. 여러 볼륨을 만드는 경우, 모든 볼륨이 이 스토리지 엔드포인트에 연결된 기본 운영 체제 미설치 장치로 분산됩니다. ANF에는 구성된 스토리지의 볼륨 또는/및 용량이 사전 정의된 내부 수준에 도달하면 고객 워크로드를 자동으로 배포하는 논리가 있습니다. 새 IP 주소를 사용하는 새 스토리지 엔드포인트는 볼륨에 액세스하기 위해 자동으로 생성되기 때문에 이러한 경우를 알 수 있습니다. ANF 서비스는 이 배포 논리에 대해 고객 제어를 제공하지 않습니다.
로그 볼륨 및 로그 백업 볼륨
"로그 볼륨"(/hana/log)은 온라인 다시 실행 로그를 작성하는 데 사용됩니다. 따라서 이 볼륨에 열려 있는 파일이 있으므로 이 볼륨을 스냅샷하는 것은 의미가 없습니다. 온라인 다시 실행 로그 파일은 온라인 다시 실행 로그 파일이 가득 차거나 다시 실행 로그 백업이 실행되면 로그 백업 볼륨에 보관되거나 백업됩니다. 적절한 백업 성능을 제공하려면 로그 백업 볼륨에 양호한 처리량이 필요합니다. 스토리지 비용을 최적화하려면 여러 HANA 인스턴스의 로그 백업 볼륨을 통합하는 것이 좋습니다. 따라서, 여러 HANA 인스턴스는 동일한 볼륨을 활용하고 백업을 다른 디렉터리에 기록합니다. 이러한 통합을 사용하면 볼륨을 조금 더 크게 만들어야 하므로 더 많은 처리량을 얻을 수 있습니다.
전체 HANA 데이터베이스 백업 쓰기를 사용하는 볼륨에도 동일하게 적용됩니다.
Backup
Azure Virtual Machines의 SAP HANA 백업 가이드에 설명된 대로 스트리밍 백업 및 Azure Backup 서비스의 SAP HANA 데이터베이스 백업 외에도 Azure NetApp Files는 스토리지 기반 스냅샷 백업을 수행할 수 있는 가능성을 열어줍니다.
SAP HANA는 다음을 지원합니다.
- SAP HANA 1.0 SPS7 이상을 사용하는 단일 컨테이너 시스템에 대한 스토리지 기반 스냅샷 백업 지원
- SAP HANA 2.0 SPS1 이상과 단일 테넌트를 사용하는 MDC(다중 데이터베이스 컨테이너) HANA 환경을 위한 스토리지 기반 스냅샷 백업 지원
- SAP HANA 2.0 SPS4 이상과 여러 테넌트를 사용하는 MDC(다중 데이터베이스 컨테이너) HANA 환경을 위한 스토리지 기반 스냅샷 백업 지원
스토리지 기반 스냅샷 백업 만들기는 간단한 4단계 절차입니다.
- HANA(내부) 데이터베이스 스냅샷 만들기 - 사용자 또는 도구에서 수행해야 하는 작업
- SAP HANA는 데이터 파일에 데이터를 기록하여 스토리지에서 일관된 상태로 만들기 - HANA가 HANA 스냅샷을 만든 결과로 이 단계를 수행
- 스토리지의 /hana/data 볼륨에 스냅샷 만들기 - 사용자 또는 도구에서 수행해야 하는 단계. /Hana/log 볼륨에서 스냅샷을 수행할 필요는 없음
- HANA(내부) 데이터베이스 스냅샷을 삭제하고 정상 작동 재개 - 사용자 또는 도구에서 수행해야 하는 단계
Warning
마지막 단계가 누락되거나 마지막 단계를 수행하지 못하면 SAP HANA의 메모리 수요에 심각한 영향을 미치고 SAP HANA가 중단될 수 있습니다.
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
이 스냅샷 백업 절차는 다양한 도구를 사용하여 다양한 방법으로 관리할 수 있습니다. 한 가지 예가 GitHub에서 사용할 수 있는 Python 스크립트"ntaphana_azure.py"입니다. https://github.com/netapp/ntaphana 이것은 유지 관리 또는 지원 없이 "있는 그대로" 제공되는 샘플 코드입니다.
주의
스냅샷 자체는 방금 스냅샷을 생성한 볼륨과 동일한 물리적 스토리지에 있으므로 보호된 백업이 아닙니다. 하루에 하나 이상의 스냅샷을 다른 위치로 "보호"해야 합니다. 이는 동일한 환경, 원격 Azure 지역 또는 Azure Blob 스토리지에서 수행할 수 있습니다.
스토리지 스냅샷 기반 애플리케이션 일치 백업에 사용할 수 있는 솔루션:
- Microsoft Azure 애플리케이션 일치 스냅샷 도구란 타사 데이터베이스의 데이터 보호를 지원하는 명령줄 도구입니다. 스토리지 스냅샷을 가져오기 전에 데이터베이스를 애플리케이션 일치 상태로 유지하는 데 필요한 모든 오케스트레이션을 처리합니다. 스토리지 스냅샷을 가져온 후 도구는 데이터베이스를 작동 상태로 반환합니다. AzAcSnap은 HANA 대규모 인스턴스 및 Azure NetApp Files에 대한 스냅샷 기반 백업을 지원합니다. 자세한 내용은 Azure 애플리케이션 일치 스냅샷 도구란? 문서를 참조하세요.
- Commvault 백업 제품 사용자의 경우, Commvault IntelliSnap V.11.21 이상이 또 다른 옵션이 될 수 있습니다. 이 Commvault 버전 이상에서는 Azure NetApp Files 스냅샷 지원을 제공합니다. Commvault IntelliSnap 11.21 문서에서 자세한 정보를 제공합니다.
Azure Blob 스토리지를 사용하여 스냅샷 백업
Azure Blob 스토리지에 백업은 ANF 기반 HANA 데이터베이스 스토리지 스냅샷 백업을 비용 효율적이고 빠르게 저장할 수 있는 방법입니다. 스냅샷을 Azure Blob 스토리지에 저장하려면 AzCopy 도구를 사용하는 것이 좋습니다. 이 도구의 최신 버전을 다운로드하여 GitHub의 Python 스크립트가 설치된 bin 디렉터리에 설치합니다. 최신 AzCopy 도구를 다운로드합니다.
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
가장 고급 기능은 SYNC 옵션입니다. SYNC 옵션을 사용하는 경우 azcopy는 원본과 대상 디렉터리를 동기화합니다. --delete-destination 매개 변수를 사용하는 것이 중요합니다. 이 매개 변수가 없으면 azcopy가 대상 사이트에서 파일을 삭제하지 않고 대상 쪽의 공간 사용이 증가합니다. Azure Storage 계정에 컨테이너를 만듭니다. 그런 다음, Blob 컨테이너에 대한 SAS 키를 만들고 스냅샷 폴더를 Azure Blob 컨테이너에 동기화합니다.
예를 들어 일별 스냅샷을 Azure Blob 컨테이너와 동기화하여 데이터를 보호해야 하는 경우가 있습니다. 그리고 해당 스냅샷만 보관해야 하며 아래 명령을 사용할 수 있습니다.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
다음 단계
문서