Red Hat Enterprise Linux의 Azure VM에 있는 SAP HANA의 고가용성
온-프레미스 개발에서 HANA 시스템 복제를 사용하거나 공유 스토리지를 사용하여 SAP HANA의 HA(고가용성)를 설정할 수 있습니다. Azure Virtual Machines에서 Azure의 HANA 시스템 복제는 현재 지원되는 유일한 HA 기능입니다.
SAP HANA 복제는 하나의 기본 노드와 하나 이상의 보조 노드로 구성됩니다. 기본 노드의 데이터를 변경하면 보조 노드에 동기적 또는 비동기적으로 복제됩니다.
이 문서에서는 VM(가상 머신)을 배포 및 구성하며, 클러스터 프레임워크를 설치하고, SAP HANA 시스템 복제를 설치 및 구성하는 방법을 설명합니다.
예제 구성에서 설치 명령, 인스턴스 번호 03 및 HANA 시스템 ID HN1이 사용됩니다.
필수 조건
다음 SAP Note 및 문서를 먼저 읽어 보세요.
- SAP Note 1928533, 다음 항목을 포함합니다.
- SAP 소프트웨어 배포에 지원되는 Azure VM 크기 목록.
- Azure VM 크기에 대한 중요한 용량 정보.
- 지원되는 SAP 소프트웨어 및 OS(운영 체제)와 데이터베이스 조합.
- Microsoft Azure에서 Windows 및 Linux에 필요한 SAP 커널 버전.
- SAP Note 2015553는 Azure에서 SAP을 지원하는 SAP 소프트웨어 배포에 대한 필수 구성 요소를 나열합니다.
- SAP Note 2002167에는 Red Hat Enterprise Linux에 권장되는 OS 설정이 있습니다.
- SAP Note 2009879에는 Red Hat Enterprise Linux용 SAP HANA 지침이 있습니다.
- SAP Note 3108302에는 Red Hat Enterprise Linux 9.x용 SAP HANA 지침이 있습니다.
- SAP Note 2178632는 Azure에서 SAP에 대해 보고된 모든 모니터링 메트릭에 대한 자세한 정보를 포함하고 있습니다.
- SAP Note 2191498는 Azure에서 Linux에 필요한 SAP Host Agent 버전을 포함하고 있습니다.
- SAP Note 2243692는 Azure에서 Linux의 SAP 라이선스에 대한 정보를 포함하고 있습니다.
- SAP Note 1999351에는 SAP용 Azure 고급 모니터링 확장에 대한 추가 문제 해결 정보가 있습니다.
- SAP Community WIKI는 Linux에 필요한 모든 SAP Note를 포함하고 있습니다.
- Linux에서 SAP용 Azure Virtual Machines 계획 및 구현
- Linux에서 SAP용 Azure Virtual Machines 배포(이 문서)
- Linux에서 SAP용 Azure Virtual Machines DBMS 배포
- Pacemaker 클러스터의 SAP HANA 시스템 복제
- 일반 RHEL 설명서:
- High Availability Add-On Overview(고가용성 추가 기능 개요)
- High Availability Add-On Administration(고가용성 추가 기능 관리)
- High Availability Add-On Reference(고가용성 추가 기능 참조)
- RHEL HA 추가 기능을 사용한 HANA 스케일 업 시스템 복제
- Azure 특정 RHEL 설명서:
- Support Policies for RHEL High Availability Clusters - Microsoft Azure Virtual Machines as Cluster Members(RHEL 고가용성 클러스터용 지원 정책 - Microsoft Azure Virtual Machines(클러스터 멤버))
- Installing and Configuring a Red Hat Enterprise Linux 7.4 (and later) High-Availability Cluster on Microsoft Azure(Microsoft Azure에서 Red Hat Enterprise Linux 7.4 이상 고가용성 클러스터 설치 및 구성)
- Install SAP HANA on Red Hat Enterprise Linux for Use in Microsoft Azure(Microsoft Azure에서 사용할 용도로 Red Hat Enterprise Linux에 SAP HANA 설치)
개요
HA를 달성하기 위해 SAP HANA는 두 개의 VM에 설치됩니다. HANA 시스템 복제를 사용하여 데이터가 복제됩니다.
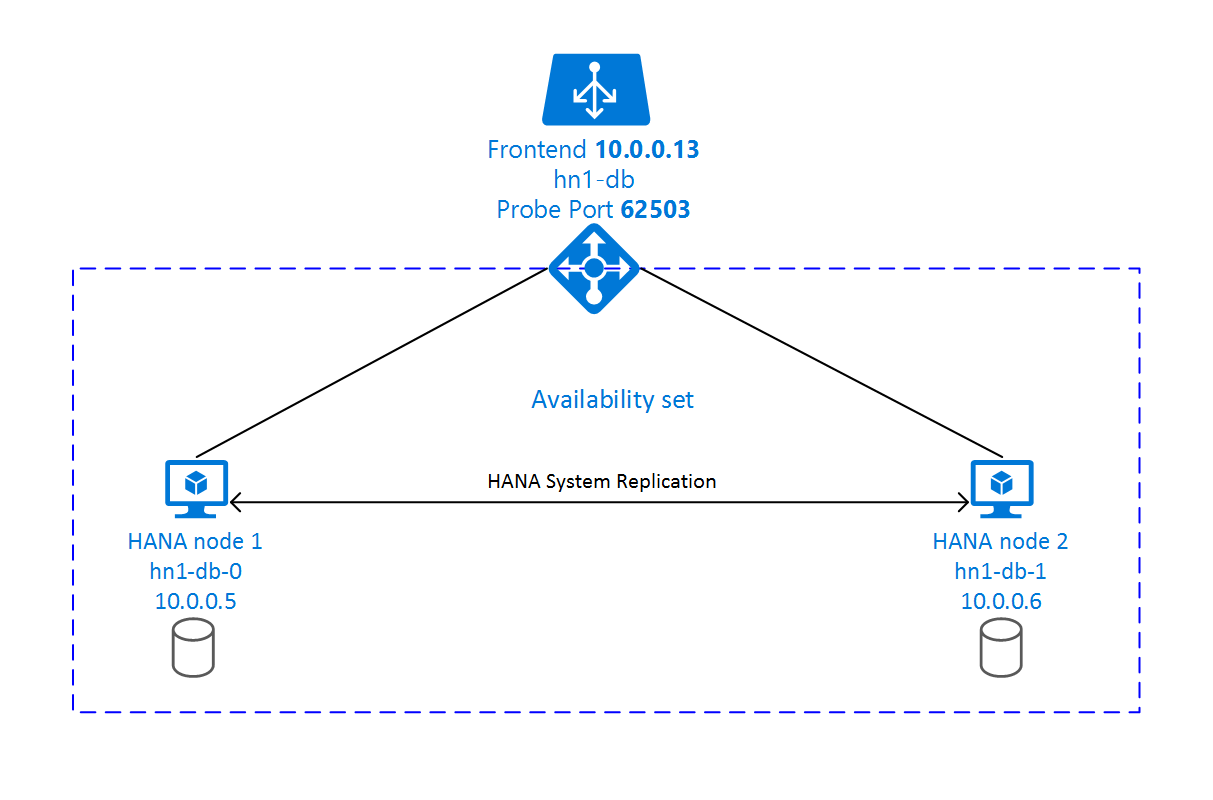
SAP HANA 시스템 복제 설정은 전용 가상 호스트 이름과 가상 IP 주소를 사용합니다. Azure에서는 가상 IP 주소를 사용하려면 부하 분산 장치가 필요합니다. 제시된 구성은 다음이 포함된 부하 분산 장치를 보여 줍니다.
- 프런트 엔드 IP 주소: hn1-db의 경우 10.0.0.13
- 프로브 포트: 62503
인프라 준비
Azure Marketplace에는 다양한 버전의 Red Hat을 사용하여 새 VM을 배포하는 데 사용할 수 있는 고가용성 추가 기능이 포함된 SAP HANA에 적합한 이미지가 포함되어 있습니다.
Azure Portal을 통해 수동으로 Linux VM 배포
이 문서에서는 리소스 그룹, Azure 가상 네트워크 및 서브넷을 이미 배포했다고 가정합니다.
SAP HANA용 VM을 배포합니다. HANA 시스템에 지원되는 적합한 RHEL 이미지를 선택합니다. 가상 머신 확장 집합, 가용성 영역 또는 가용성 집합 같은 옵션 중 하나에서 VM을 배포할 수 있습니다.
Important
선택한 운영 체제가 배포에 사용하려는 특정 VM 유형에서 SAP HANA용으로 인증된 SAP인지 확인해야 합니다. SAP HANA 인증 IaaS 플랫폼에서 SAP HANA 인증 VM 유형 및 해당 OS 릴리스 를 조회할 수 있습니다. 특정 VM 형식에 대한 SAP HANA 지원 OS 릴리스의 전체 목록을 보려면 VM 유형의 세부 정보를 확인하세요.
Azure Load Balancer 구성
VM 구성 중에 네트워킹 섹션에서 기존 부하 분산 장치를 만들거나 선택할 수 있는 옵션이 있습니다. HANA 데이터베이스의 고가용성 설정을 위해 표준 부하 분산 장치를 설정하려면 아래 단계를 따릅니다.
Azure Portal을 사용하여 고가용성 SAP 시스템용 표준 Load Balancer를 설정하려면 부하 분산 장치 만들기의 단계를 따릅니다. 부하 분산 장치를 설정하는 동안 다음 사항을 고려합니다.
- 프런트 엔드 IP 구성: 프런트 엔드 IP를 만듭니다. 데이터베이스 가상 머신과 동일한 가상 네트워크 및 서브넷 이름을 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 만들고 데이터베이스 VM을 추가합니다.
- 인바운드 규칙: 부하 분산 규칙을 만듭니다. 두 부하 분산 규칙 모두에 대해 동일한 단계를 수행합니다.
- 프런트 엔드 IP 주소: 프런트 엔드 IP를 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 선택합니다.
- 고가용성 포트: 이 옵션을 선택합니다.
- 프로토콜: TCP를 선택합니다.
- 상태 프로브: 다음 세부 정보를 사용하여 상태 프로브를 만듭니다.
- 프로토콜: TCP를 선택합니다.
- 포트: 예: 625<instance-no.>.
- 간격: 5를 입력합니다.
- 프로브 임계값: 2를 입력합니다.
- 유휴 시간 제한(분): 30을 입력합니다.
- 부동 IP 사용: 이 옵션을 선택합니다.
참고 항목
포털에서 비정상 임계값이라고도 알려진 상태 프로브 구성 속성 numberOfProbes는 준수되지 않습니다. 성공하거나 실패한 연속 프로브 수를 제어하려면 probeThreshold 속성을 2로 설정합니다. 현재 Azure Portal을 사용하여 이 속성을 설정할 수 없으므로 Azure CLI 또는 PowerShell 명령을 사용합니다.
SAP HANA에 필요한 포트에 대한 자세한 내용은 SAP HANA 테넌트 데이터베이스 가이드의 테넌트 데이터베이스에 연결 챕터 또는 SAP Note 2388694를 참조하세요.
Important
부동 IP는 부하 분산 시나리오의 NIC 보조 IP 구성에서 지원되지 않습니다. 자세한 내용은 Azure Load Balancer 제한 사항을 참조하세요. VM에 다른 IP 주소가 필요한 경우 두 번째 NIC를 배포합니다.
참고 항목
공용 IP 주소가 없는 VM이 표준 Azure Load Balancer의 내부(공용 IP 주소 없음) 인스턴스의 백 엔드 풀에 배치되면 공용 엔드포인트로의 라우팅을 허용하도록 추가 구성이 수행되지 않는 한 아웃바운드 인터넷 연결이 이루어지지 않습니다. 아웃바운드 연결을 달성하는 방법에 대한 자세한 내용은 SAP 고가용성 시나리오에서 Azure 표준 Load Balancer를 사용하는 VM에 대한 공용 엔드포인트 연결을 참조하세요.
Important
Azure Load Balancer 뒤에 배치되는 Azure VM에서 TCP 타임스탬프를 사용하도록 설정하면 안 됩니다. TCP 타임스탬프를 사용하도록 설정하면 상태 프로브가 실패할 수 있습니다. net.ipv4.tcp_timestamps 매개 변수를 0으로 설정합니다. 자세한 내용은 부하 분산 장치 상태 프로브 및 AP Note 2382421을 참조하세요.
SAP HANA 설치
이 섹션의 다음 단계에서는 다음과 같은 접두사를 사용합니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1] : 단계가 노드 1에만 적용됩니다.
- [2] : 단계가 Pacemaker 클러스터의 노드 2에만 적용됩니다.
[A] 디스크 레이아웃 LVM(논리 볼륨 관리자)을 설정합니다.
데이터와 로그 파일을 저장하는 볼륨의 LVM을 사용하는 것이 좋습니다. 다음 예제에서는 VM에 2개의 볼륨을 만드는 데 사용되는 4개의 데이터 디스크가 연결되어 있다고 가정합니다.
사용 가능한 모든 디스크를 나열합니다.
ls /dev/disk/azure/scsi1/lun*예제 출력:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3사용하려는 모든 디스크의 물리적 볼륨을 만듭니다.
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3데이터 파일에 대한 볼륨 그룹을 만듭니다. 로그 파일에 대해 한 볼륨 그룹, SAP HANA의 공유 디렉터리에 대해 한 볼륨을 사용합니다.
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3논리 볼륨을 만듭니다.
-i스위치 없이lvcreate를 사용하는 경우 선형 볼륨이 만들어집니다. 더 나은 I/O 성능을 위해 스트라이프 볼륨을 만드는 것이 좋습니다. 스트라이프 크기를 SAP HANA VM 스토리지 구성에 설명된 값에 맞춥니다.-i인수는 기본 실제 볼륨의 수여야 하며-I인수는 스트라이프 크기입니다.이 문서에서는 2개의 물리적 볼륨이 데이터 볼륨에 사용되므로
-i스위치 인수가 2로 설정됩니다. 데이터 볼륨의 스트라이프 크기는 256KiB입니다. 로그 볼륨에는 하나의 실제 볼륨이 사용되므로-i또는-I스위치는 로그 볼륨 명령에 명시적으로 사용되지 않습니다.Important
각 데이터, 로그 또는 공유 볼륨에 대해 하나 이상의 물리적 볼륨을 사용하는 경우
-i스위치를 사용하고 기본 물리적 볼륨 수로 설정합니다. 스트라이프 볼륨을 만들 때-I스위치를 사용하여 스트라이프 크기를 지정합니다. 스트라이프 크기 및 디스크 수를 비롯한 권장되는 스토리지 구성은 SAP HANA VM 스토리지 구성을 참조하세요. 다음 레이아웃 예제는 특정 시스템 크기에 대한 성능 지침을 반드시 충족하지는 않습니다. 이 예제는 설명을 돕기 위해 제공된 것입니다.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_shared탑재 명령을 실행하여 디렉터리를 탑재하지 마세요. 대신
fstab에 구성을 입력하고 최종mount -a를 발행하여 구문의 유효성을 검사합니다. 먼저 각 볼륨에 대한 탑재 디렉터리를 만듭니다.sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared그런 다음,
/etc/fstab파일에 다음 줄을 삽입하여 3개의 논리 볼륨에 대한fstab항목을 만듭니다./dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
마지막으로 새 볼륨을 한 번에 탑재합니다.
sudo mount -a[A] 모든 호스트의 호스트 이름 확인을 설정합니다.
DNS 서버를 사용하거나
/etc/hosts에서 다음과 같이 모든 노드에 대한 항목을 생성하여 모든 노드에서/etc/hosts파일을 수정할 수 있습니다.10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] HANA용 RHEL 구성을 수행합니다.
다음 노트에 설명된 대로 RHEL을 구성합니다.
[A] SAP HANA를 설치합니다.
SAP HANA 시스템 복제를 설치하려면 RHEL HA 추가 기능을 사용하여 SAP HANA 확장 시스템 복제 자동화를 참조하세요.
HANA DVD에서 hdblcm 프로그램을 실행합니다. 프롬프트에서 다음 값을 입력합니다.
- 설치 선택: 1을 입력합니다.
- 설치할 추가 구성 요소 선택: 1을 입력합니다.
- 설치 경로 [/hana/shared] 입력: Enter 키를 누릅니다.
- 로컬 호스트 이름 [..] 입력: Enter 키를 누릅니다.
- 시스템에 호스트를 추가할까요? (y/n) [n]: Enter 키를 선택합니다.
- SAP HANA 시스템 ID 입력: HANA의 SID를 입력합니다(예: HN1).
- 인스턴스 번호 [00] 입력: HANA 인스턴스 번호를 입력합니다. Azure 템플릿을 사용하거나 이 문서의 수동 배포 섹션을 수행한 경우 03을 입력합니다.
- 데이터베이스 모드 선택/인덱스 입력 [1]: Enter를 선택합니다.
- 시스템 사용량 선택/인덱스 [4] 입력: 시스템 사용량 값을 선택합니다.
- 데이터 볼륨의 위치 [/hana/data] 입력: Enter 키를 누릅니다.
- 데이터 볼륨의 위치 [/hana/log] 입력: Enter 키를 누릅니다.
- 최대 메모리 할당 제한? [n]: Enter 키를 선택합니다.
- 호스트 '...'에 대한 인증서 호스트 이름 [...] 입력: Enter 키를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 입력: 호스트 에이전트 사용자 암호를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 확인: 호스트 에이전트 사용자 암호를 다시 입력하여 확인합니다.
- 시스템 관리자(hdbadm) 암호 입력: 시스템 관리자 암호를 입력합니다.
- 시스템 관리자(hdbadm) 암호 확인: 시스템 관리자 암호를 다시 입력하여 확인합니다.
- 시스템 관리자 홈 디렉터리 [/usr/sap/HN1/home] 입력: Enter 키를 누릅니다.
- 시스템 관리자 로그인 셸 [/bin/sh] 입력: Enter 키를 누릅니다.
- 시스템 관리자 사용자 ID [1001] 입력: Enter 키를 누릅니다.
- 사용자 그룹의 ID(sapsys) [79] 입력: Enter 키를 누릅니다.
- 데이터베이스 사용자(SYSTEM) 암호 입력: 데이터베이스 사용자 암호를 입력합니다.
- 데이터베이스 사용자(SYSTEM) 암호 확인: 데이터베이스 사용자 암호를 다시 입력하여 확인합니다.
- 컴퓨터를 다시 부팅한 다음 시스템 다시 시작? [n]: Enter 키를 선택합니다.
- 계속할까요? (y/n): 요약의 유효성을 검사합니다. 계속하려면 y를 입력합니다.
[A] SAP 호스트 에이전트를 업그레이드합니다.
SAP Software Center에서 최신 SAP 호스트 에이전트 아카이브를 다운로드하고 다음 명령을 실행하여 에이전트를 업그레이드합니다. 다운로드한 파일을 가리키도록 아카이브의 경로를 바꿉니다.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent>;[A] 방화벽을 구성합니다.
Azure 부하 분산 장치 프로브 포트의 방화벽 규칙을 만듭니다.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
SAP HANA 2.0 시스템 복제 구성
이 섹션의 다음 단계에서는 다음과 같은 접두사를 사용합니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1] : 단계가 노드 1에만 적용됩니다.
- [2] : 단계가 Pacemaker 클러스터의 노드 2에만 적용됩니다.
[A] 방화벽을 구성합니다.
HANA 시스템 복제 및 클라이언트 트래픽을 허용하는 방화벽 규칙을 만듭니다. 필수 포트 목록은 모든 SAP 제품의 TCP/IP 포트에 나열되어 있습니다. 다음 명령은 HANA 2.0 시스템 복제 및 데이터베이스 SYSTEMDB, HN1, NW1에 대한 클라이언트 트래픽을 허용하는 예입니다.
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] 테넌트 데이터베이스를 만듭니다.
SAP HANA 2.0 또는 MDC를 사용하는 경우 SAP NetWeaver 시스템에 대한 테넌트 데이터베이스를 만듭니다. NW1을 SAP 시스템의 SID로 바꿉니다.
다음 명령을 <hanasid>adm으로 실행합니다.
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] 첫 번째 노드에서 시스템 복제를 구성합니다.
데이터베이스를 <hanasid>adm으로 백업합니다.
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"시스템 PKI 파일을 보조 사이트에 복사합니다.
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/기본 사이트를 만듭니다.
hdbnsutil -sr_enable --name=SITE1[2] 두 번째 노드에서 시스템 복제를 구성합니다.
두 번째 노드를 등록하여 시스템 복제를 시작합니다. 다음 명령을 <hanasid>adm으로 실행합니다.
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[1] 복제 상태를 확인합니다.
복제 상태를 확인하고 모든 데이터베이스가 동기화될 때까지 기다립니다. 상태가 여전히 UNKNOWN으로 남아 있는 경우 방화벽 설정을 확인합니다.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
SAP HANA 1.0 시스템 복제 구성
이 섹션의 다음 단계에서는 다음과 같은 접두사를 사용합니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1] : 단계가 노드 1에만 적용됩니다.
- [2] : 단계가 Pacemaker 클러스터의 노드 2에만 적용됩니다.
[A] 방화벽을 구성합니다.
HANA 시스템 복제 및 클라이언트 트래픽을 허용하는 방화벽 규칙을 만듭니다. 필수 포트 목록은 모든 SAP 제품의 TCP/IP 포트에 나열되어 있습니다. 다음 명령은 HANA 2.0 시스템 복제를 허용하는 예제입니다. SAP HANA 1.0 설치에 적용하세요.
sudo firewall-cmd --zone=public --add-port=40302/tcp --permanent sudo firewall-cmd --zone=public --add-port=40302/tcp[1] 필요한 사용자를 만듭니다.
다음 명령을 루트로 실행합니다. HANA 시스템 ID(예 : HN1), 인스턴스 번호(03) 및 사용자 이름 값을 SAP HANA 설치 값으로 바꿔야 합니다.
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -u system -i 03 'CREATE USER hdbhasync PASSWORD "passwd"' hdbsql -u system -i 03 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i 03 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] 키 저장소 항목을 만듭니다.
다음 명령을 루트로 실행하여 새로운 키 저장소 항목을 만듭니다.
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbuserstore SET hdbhaloc localhost:30315 hdbhasync passwd[1] 데이터베이스를 백업합니다.
루트로 데이터베이스를 백업합니다.
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -d SYSTEMDB -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"다중 테넌트 설치를 사용하는 경우 테넌트 데이터베이스도 백업합니다.
hdbsql -d HN1 -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"[1] 첫 번째 노드에서 시스템 복제를 구성합니다.
기본 사이트를 <hanasid>adm으로 만듭니다.
su - hdbadm hdbnsutil -sr_enable –-name=SITE1[2] 보조 노드에서 시스템 복제를 구성합니다.
보조 사이트를 <hanasid>adm으로 등록합니다.
HDB stop hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 HDB start
Pacemaker 클러스터 만들기
Azure의 Red Hat Enterprise Linux에서 Pacemaker 설정 단계에 따라 이 HANA 서버용 기본 Pacemaker 클러스터를 만듭니다.
Important
시스템 기반 SAP Startup Framework를 사용하면 이제 systemd에서 SAP HANA 인스턴스를 관리할 수 있습니다. 필요한 최소 RHEL(Red Hat Enterprise Linux) 버전은 SAP용 RHEL 8입니다. SAP Note 3189534에서 설명한 대로 SAP HANA SPS07 수정 버전 70 이상을 새로 설치하거나 HANA 시스템을 HANA 2.0 SPS07 수정 버전 70 이상으로 업데이트하면 SAP 시작 프레임워크가 자동으로 systemd에 등록됩니다.
HA 솔루션을 사용하여 시스템 지원 SAP HANA 인스턴스(SAP Note 3189534참조)와 함께 SAP HANA 시스템 복제를 관리하는 경우 HA 클러스터가 systemd의 간섭 없이 SAP 인스턴스를 관리할 수 있도록 추가 단계가 필요합니다. 따라서 systemd와 통합된 SAP HANA 시스템의 경우 모든 클러스터 노드에서 Red Hat KBA 7029705에 설명된 추가 단계를 따라야 합니다.
Python 시스템 복제 후크 SAPHanaSR 구현
이 중요한 단계에서는 클러스터와의 통합을 최적화하고 클러스터 장애 조치(failover)가 필요할 때 검색 기능을 향상합니다. SAPHanaSR python 후크를 구성하는 것이 좋습니다.
[A]모든 노드에 SAP HANA 리소스 에이전트를 설치합니다. 패키지가 포함된 리포지토리를 사용하도록 설정해야 합니다. RHEL 8.x HA 사용 이미지를 사용하는 경우 추가 리포지토리를 사용하도록 설정할 필요가 없습니다.
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo yum install -y resource-agents-sap-hana[A] HANA를 설치
system replication hook합니다. 후크는 두 개의 HANA DB 노드에 모두 설치해야 합니다.팁
Python 후크는 HANA 2.0에서만 구현할 수 있습니다.
후크를
root로 준비합니다.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR/srHook/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooks두 노드에서 HANA를 중지합니다. <sid>adm으로 실행합니다.
sapcontrol -nr 03 -function StopSystem각 클러스터 노드에서
global.ini를 조정합니다.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[A] 클러스터에는 <sid>adm용 각 클러스터 노드에
sudoers구성이 필요합니다. 이 예제에서는 새 파일을 만들어 수행합니다.visudo명령을 사용하여20-saphana드롭인 파일을root로 편집합니다.sudo visudo -f /etc/sudoers.d/20-saphana다음 줄을 삽입한 다음, 저장합니다.
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] 두 노드에서 SAP HANA를 시작합니다. <sid>adm으로 실행합니다.
sapcontrol -nr 03 -function StartSystem[1] 후크 설치를 확인합니다. 활성 HANA 시스템 복제 사이트에서 <sid>adm으로 실행합니다.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK
SAP HANA 시스템 복제 후크 구현에 대한 자세한 내용은 SAP HA/DR 공급자 후크 사용을 참조하세요.
SAP HANA 클러스터 리소스 만들기
HANA 토폴로지를 만듭니다. Pacemaker 클러스터 노드 중 하나에서 다음 명령을 실행합니다. 이 지침 전체에서 적절한 경우 인스턴스 번호, HANA 시스템 ID, IP 주소 및 시스템 이름을 대체해야 합니다.
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
다음에는 HANA 리소스를 만듭니다.
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
RHEL 7.x에서 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
RHEL 8.x/9.x에서 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
SAP HANA용 priority-fencing-delay을 구성하려면(Pacemaker-2.0.4-6.el8 이상에만 적용 가능) 다음 명령을 실행해야 합니다.
참고 항목
2노드 클러스터가 있는 경우 priority-fencing-delay 클러스터 속성을 구성할 수 있습니다. 이 속성은 분할 브레인 시나리오가 발생할 때 총 리소스 우선 순위가 더 높은 노드를 펜싱하는 데 지연을 발생시킵니다. 자세한 내용은 Pacemaker가 가장 적은 실행 중인 리소스로 클러스터 노드를 펜스할 수 있나요?를 참조하세요.
속성 priority-fencing-delay는 pacemaker-2.0.4-6.el8 버전 이상에 적용할 수 있습니다. 기존 클러스터에서 priority-fencing-delay를 설정하는 경우 펜싱 디바이스에서 pcmk_delay_max 옵션을 설정 해제해야 합니다.
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
Important
장애 조치(failover) 테스트를 수행하는 동안 실패한 주 인스턴스가 자동으로 보조 인스턴스로 등록되지 않도록 AUTOMATED_REGISTER를 false로 설정하는 것이 좋습니다. 테스트 후 모범 사례로 AUTOMATED_REGISTER를 true로 설정하여 인수 후 시스템 복제가 자동으로 다시 시작될 수 있도록 합니다.
클러스터 상태가 정상이며 모든 리소스가 시작되었는지 확인합니다. 리소스가 실행 중인 노드는 중요하지 않습니다.
참고 항목
앞의 구성에서 시간 제한은 단지 예제이며 특정 HANA 설정에 맞게 조정해야 할 수 있습니다. 예를 들어 SAP HANA 데이터베이스를 시작하는 데 시간이 더 오래 걸리는 경우 시작 시간 제한을 늘려야 할 수 있습니다.
생성된 클러스터 리소스의 상태를 확인하려면 sudo pcs status 명령을 사용합니다.
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Pacemaker 클러스터에서 HANA 활성/읽기 사용 시스템 복제 구성
SAP HANA 2.0 SPS 01부터 SAP는 SAP HANA 시스템 복제를 위한 활성/읽기 사용 설정을 허용합니다. 여기서 SAP HANA 시스템 복제의 보조 시스템은 읽기 집약적인 워크로드에 적극적으로 사용할 수 있습니다.
클러스터에서 이러한 설정을 지원하려면 클라이언트가 보조 읽기 사용 SAP HANA 데이터베이스에 액세스할 수 있도록 두 번째 가상 IP 주소가 필요합니다. 인수가 발생한 후에도 보조 복제 사이트에 액세스할 수 있도록 클러스터에서 가상 IP 주소를 SAPHana 리소스의 보조로 이동해야 합니다.
이 섹션에서는 두 번째 가상 IP가 있는 Red Hat HA 클러스터에서 HANA 활성/읽기 사용 시스템 복제를 관리하는 데 필요한 기타 단계를 설명합니다.
계속 진행하기 전에 설명서의 이전 부분에 설명된 대로 SAP HANA 데이터베이스를 관리하는 Red Hat HA 클러스터를 완전히 구성했는지 확인합니다.
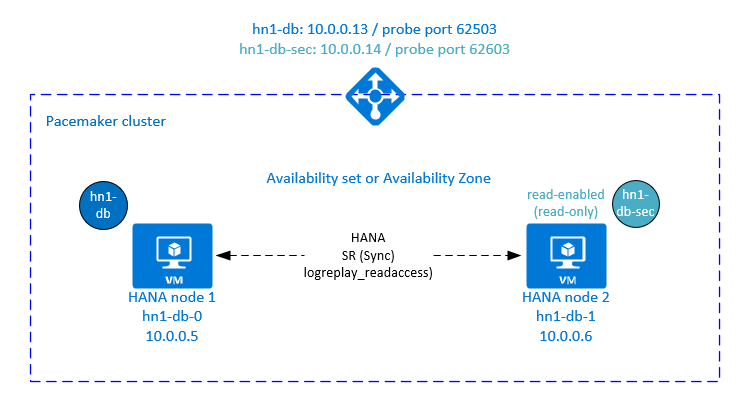
활성/읽기 지원 설정을 위한 Azure Load Balancer의 추가 설정
두 번째 가상 IP를 프로비전하는 단계를 추가로 진행하려면 Azure Portal을 통해 수동으로 Linux VM 배포 섹션에 설명된 대로 Azure Load Balancer를 구성했는지 확인합니다.
표준 부하 분산 장치의 경우 이전 섹션에서 만든 것과 동일한 부하 분산 장치에서 이러한 단계를 수행합니다.
a. 두 번째 프런트 엔드 IP 풀 만들기:
- 부하 분산 장치를 열고, 프런트 엔드 IP 풀을 선택하고, 추가를 선택합니다.
- 두 번째 프런트 엔드 IP 풀의 이름을 입력합니다(예: hana-secondaryIP).
- 할당을 고정으로 설정하고 IP 주소를 입력합니다(예: 10.0.0.14).
- 확인을 선택합니다.
- 새 프런트 엔드 IP 풀을 만든 후, 풀 IP 주소를 적어 둡니다.
b. 상태 프로브 만들기:
- 부하 분산 장치를 열고, 상태 프로브를 선택한 다음, 추가를 선택합니다.
- 새 상태 프로브의 이름(예: hana-secondaryhp)을 입력합니다.
- 프로토콜 및 포트 62603으로 TCP를 선택합니다. 5로 설정된 간격 값, 2로 설정된 비정상 임계값 값을 유지합니다.
- 확인을 선택합니다.
c. 부하 분산 규칙 만들기:
- 부하 분산 장치를 열고, 부하 분산 규칙을 선택한 다음, 추가를 선택합니다.
- 새 부하 분산 장치 규칙의 이름(예: hana-secondarylb)을 입력합니다.
- 이전에 만든 프런트 엔드 IP 주소, 백 엔드 풀, 상태 프로브를 선택합니다(예: hana-secondaryIP, hana-backend 및 hana-secondaryhp).
- HA 포트를 선택합니다.
- 부동 IP를 사용하도록 설정했는지 확인합니다.
- 확인을 선택합니다.
HANA 활성/읽기 지원 시스템 복제 구성
HANA 시스템 복제를 구성하는 단계는 SAP HANA 2.0 시스템 복제 구성 섹션에 설명되어 있습니다. 읽기 사용 보조 시나리오를 배포하는 경우 두 번째 노드에서 시스템 복제를 구성하는 동안 hanasidadm으로 다음 명령을 실행합니다.
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
활성/읽기 지원 설정에 대한 보조 가상 IP 주소 리소스 추가
두 번째 가상 IP 및 적절한 공동 배치 제약 조건은 다음 명령으로 구성할 수 있습니다.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
pcs property set maintenance-mode=false
클러스터 상태가 정상이며 모든 리소스가 시작되었는지 확인합니다. 두 번째 가상 IP는 보조 사이트에서 SAPHana 보조 리소스와 함께 실행됩니다.
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
다음 섹션에서는 실행할 일반적인 장애 조치(failover) 테스트 세트를 찾을 수 있습니다.
읽기 사용 보조로 구성된 HANA 클러스터를 테스트하는 동안 두 번째 가상 IP 동작에 유의하세요.
SAPHana_HN1_03 클러스터 리소스를 보조 사이트 hn1-db-1로 마이그레이션하는 경우 두 번째 가상 IP는 동일한 사이트 hn1-db-1에서 계속 실행됩니다. 리소스에 대해
AUTOMATED_REGISTER="true"을 설정했고 HANA 시스템 복제가 hn1-db-0에 자동으로 등록된 경우 두 번째 가상 IP도 hn1-db-0으로 이동합니다.서버 충돌을 테스트할 때 두 번째 가상 IP 리소스(rsc_secip_HN1_HDB03)와 Azure Load Balancer 포트 리소스(rsc_secnc_HN1_HDB03)는 주 가상 IP 리소스와 함께 주 서버에서 실행됩니다. 보조 서버가 다운 상태인 동안 읽기 사용 HANA 데이터베이스에 연결된 애플리케이션은 주 HANA 데이터베이스에 연결됩니다. 보조 서버를 사용할 수 없을 때까지 읽기 사용 HANA 데이터베이스에 연결된 애플리케이션에 액세스할 수 없도록 하려는 것이 아니므로 이 동작은 예상됩니다.
두 번째 가상 IP 주소의 장애 조치(failover) 및 대체 중에 두 번째 가상 IP를 사용하여 HANA 데이터베이스에 연결하는 애플리케이션의 기존 연결이 중단될 수 있습니다.
이 설정은 정상 SAP HANA 인스턴스가 실행 중인 노드에 두 번째 가상 IP 리소스가 할당되는 시간을 최대화합니다.
클러스터 설정 테스트
이 섹션에서는 설정을 테스트하는 방법을 설명합니다. 테스트를 시작하기 전에 Pacemaker에 실패한 작업이 없으며(pcs 상태를 통해), 예기치 않은 위치 제약 조건이 없고(예: 마이그레이션 테스트의 결과), systemReplicationStatus의 경우처럼 해당 HANA가 동기화 상태에 있는지 확인합니다.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
마이그레이션 테스트
테스트 시작 전 리소스 상태:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
다음 명령을 루트로 실행하여 SAP HANA 마스터 노드를 마이그레이션할 수 있습니다.
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
클러스터는 SAP HANA 마스터 노드와 가상 IP 주소가 포함된 그룹을 hn1-db-1로 마이그레이션합니다.
마이그레이션이 완료되면 sudo pcs status 출력은 다음과 같습니다.
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
AUTOMATED_REGISTER="false"를 사용하면 클러스터가 실패한 HANA 데이터베이스를 다시 시작하지 않거나 hn1-db-0의 새 기본 데이터베이스에 등록하지 않습니다. 이 경우 다음 명령을 hn1adm로 실행하여 HANA 인스턴스를 보조로 구성합니다.
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
마이그레이션을 통해 다시 삭제해야 하는 위치 제약조건을 만듭니다. 다음 명령을 루트로 또는 sudo을 통해 실행합니다.
pcs resource clear SAPHana_HN1_03-master
pcs status을 사용하여 HANA 리소스의 상태를 모니터링합니다. HANA가 hn1-db-0에서 시작되면 출력은 다음과 같습니다.
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
네트워크 통신 차단
테스트 시작 전 리소스 상태:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
방화벽 규칙을 실행하여 노드 중 하나에서 통신을 차단합니다.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
클러스터 노드가 서로 통신할 수 없는 경우 분할 브레인 시나리오의 위험이 있습니다. 이러한 상황에서 클러스터 노드는 동시에 서로 울타리를 시도하여 펜스 경합을 초래합니다. 이러한 상황을 방지하려면 클러스터 구성에서 priority-fencing-delay 속성을 설정하는 것이 좋습니다(pacemaker-2.0.4-6.el8 이상에만 적용됨).
클러스터는 priority-fencing-delay 속성을 사용하도록 설정하여 특히 HANA 마스터 리소스를 호스트하는 노드에서 펜싱 작업의 지연을 발생시켜 노드가 펜스 경합에서 승리할 수 있도록 합니다.
다음 명령을 실행하여 방화벽 규칙을 삭제합니다.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Azure 펜싱 에이전트 테스트
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
테스트 시작 전 리소스 상태:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
SAP HANA가 마스터로 실행 중인 노드에서 네트워크 인터페이스를 사용하지 않도록 설정하여 Azure 펜싱 에이전트의 설정을 테스트할 수 있습니다. 네트워크 장애를 시뮬레이션하는 방법에 대한 설명은 Red Hat 기술 자료 문서 79523을 참조하세요.
이 예제에서는 net_breaker 스크립트를 사용하여 네트워크에 대한 모든 액세스를 차단합니다.
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
이제 클러스터 구성에 따라 VM을 다시 시작하거나 중지해야 합니다.
stonith-action 설정을 off로 설정하면 VM이 중지되고 리소스가 실행 중인 VM으로 마이그레이션됩니다.
VM을 다시 시작한 후, AUTOMATED_REGISTER="false"로 설정한 경우 SAP HANA 리소스가 보조로 시작하는 데 실패합니다. 이 경우 다음 명령을 hn1adm 사용자로 실행하여 HANA 인스턴스를 보조로 구성합니다.
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
루트로 다시 전환하고 실패한 상태를 정리합니다.
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
테스트 후 리소스 상태:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
수동 장애 조치(failover) 테스트
테스트 시작 전 리소스 상태:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
hn1-db-0 노드에서 루트로 클러스터를 중지하여 수동 장애 조치(failover)를 테스트할 수 있습니다.
pcs cluster stop
장애 조치(failover) 후에 클러스터를 다시 시작할 수 있습니다. AUTOMATED_REGISTER="false"로 설정하면 hn1-db-0 노드에서 SAP HANA 리소스를 보조로 시작하는 데 실패합니다. 이 경우 루트로 다음 명령을 실행하여 HANA 인스턴스를 보조로 구성합니다.
pcs cluster start
다음을 hn1adm으로 실행합니다.
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
그런 다음, 루트로 다음을 실행합니다.
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
테스트 후 리소스 상태:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1