EF 4, 5 및 6에 대한 성능 고려 사항
David Obando, Eric Dettinger 등
게시일: 2012년 4월
마지막 업데이트: 2014년 5월
1. 소개
개체-관계형 매핑 프레임워크는 개체 지향 애플리케이션에서 데이터 액세스를 위한 추상화 방법을 제공하는 편리한 방법입니다. .NET 애플리케이션의 경우 Microsoft에서 권장하는 O/RM은 Entity Framework입니다. 그러나 추상화의 경우 성능이 문제가 될 수 있습니다.
이 백서는 Entity Framework를 사용하여 애플리케이션을 개발할 때 성능 고려 사항을 보여주고, 개발자에게 성능에 영향을 줄 수 있는 Entity Framework 내부 알고리즘에 대한 아이디어를 제공하고, Entity Framework를 사용하는 애플리케이션에서 조사 및 성능 향상을 위한 팁을 제공하기 위해 작성되었습니다. 웹에서 이미 사용할 수 있는 성능에 대한 좋은 항목이 많이 있으며 가능한 경우 이러한 리소스를 가리키려고 노력했습니다.
성능은 까다로운 항목입니다. 이 백서는 Entity Framework를 사용하는 애플리케이션에 대한 성능 관련 결정을 내리는 데 도움이 되는 리소스로 제공됩니다. 성능을 보여 주는 몇 가지 테스트 메트릭이 포함되어 있지만 이러한 메트릭은 애플리케이션에서 볼 수 있는 성능의 절대 지표로 의도된 것이 아닙니다.
실제로 이 문서에서는 Entity Framework 4가 .NET 4.0에서 실행되고 Entity Framework 5 및 6이 .NET 4.5에서 실행된다고 가정합니다. Entity Framework 5에 대해 개선된 많은 성능 향상은 .NET 4.5와 함께 제공되는 핵심 구성 요소 내에 있습니다.
Entity Framework 6은 대역 외 릴리스이며 .NET과 함께 제공되는 Entity Framework 구성 요소에 의존하지 않습니다. Entity Framework 6은 .NET 4.0 및 .NET 4.5 모두에서 작동하며 .NET 4.0에서 업그레이드하지 않았지만 애플리케이션에서 최신 Entity Framework 비트를 원하는 사용자에게 큰 성능 이점을 제공할 수 있습니다. 이 문서에서는 Entity Framework 6을 언급할 때 이 문서 작성 당시 사용 가능한 최신 버전인 버전 6.1.0을 참조합니다.
2. 콜드 대 웜 쿼리 실행
지정된 모델에 대해 쿼리를 처음 만들 때 Entity Framework는 모델을 로드하고 유효성을 검사하기 위해 백그라운드에서 많은 작업을 수행합니다. 이 첫 번째 쿼리를 "콜드" 쿼리라고 하는 경우가 많습니다. 이미 로드된 모델에 대한 추가 쿼리를 "웜" 쿼리라고 하며 훨씬 빠릅니다.
Entity Framework를 사용하여 쿼리를 실행할 때 소요되는 시간을 개략적으로 확인하고 Entity Framework 6에서 개선되는 부분을 살펴보겠습니다.
첫 번째 쿼리 실행 – 콜드 쿼리
| 코드 사용자 쓰기 | 작업 | EF4 성능 영향 | EF5 성능 영향 | EF6 성능 영향 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
컨텍스트 만들기 | 중간 | 중간 | 낮음 |
var q1 = from c in db.Customers where c.Id == id1 select c; |
쿼리 식 만들기 | 낮음 | 낮음 | 낮음 |
var c1 = q1.First(); |
LINQ 쿼리 실행 | - 메타데이터 로드: 높지만 캐시됨 - 뷰 생성: 잠재적으로 매우 높지만 캐시됨 - 매개 변수 평가: 중간 - 쿼리 번역: 중간 - Materializer 생성: 중간이지만 캐시됨 - 데이터베이스 쿼리 실행: 잠재적으로 높음 + Connection.Open + Command.ExecuteReader + DataReader.Read 개체 구체화: 중간 - ID 조회: 보통 |
- 메타데이터 로드: 높지만 캐시됨 - 뷰 생성: 잠재적으로 매우 높지만 캐시됨 - 매개 변수 평가: 낮음 - 쿼리 번역: 중간이지만 캐시됨 - Materializer 생성: 중간이지만 캐시됨 - 데이터베이스 쿼리 실행: 잠재적으로 높음(경우에 따라 더 나은 쿼리) + Connection.Open + Command.ExecuteReader + DataReader.Read 개체 구체화: 중간 - ID 조회: 보통 |
- 메타데이터 로드: 높지만 캐시됨 - 뷰 생성: 중간이지만 캐시됨 - 매개 변수 평가: 낮음 - 쿼리 번역: 중간이지만 캐시됨 - Materializer 생성: 중간이지만 캐시됨 - 데이터베이스 쿼리 실행: 잠재적으로 높음(경우에 따라 더 나은 쿼리) + Connection.Open + Command.ExecuteReader + DataReader.Read 개체 구체화: 중간(EF5보다 빠름) - ID 조회: 보통 |
} |
Connection.Close | 낮음 | 낮음 | 낮음 |
두 번째 쿼리 실행 – 웜 쿼리
| 코드 사용자 쓰기 | 작업 | EF4 성능 영향 | EF5 성능 영향 | EF6 성능 영향 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
컨텍스트 만들기 | 중간 | 중간 | 낮음 |
var q1 = from c in db.Customers where c.Id == id1 select c; |
쿼리 식 만들기 | 낮음 | 낮음 | 낮음 |
var c1 = q1.First(); |
LINQ 쿼리 실행 | - 메타데이터 - 뷰 - 매개 변수 평가: 중간 - 쿼리 - Materializer - 데이터베이스 쿼리 실행: 잠재적으로 높음 + Connection.Open + Command.ExecuteReader + DataReader.Read 개체 구체화: 중간 - ID 조회: 보통 |
- 메타데이터 - 뷰 - 매개 변수 평가: 낮음 - 쿼리 - Materializer - 데이터베이스 쿼리 실행: 잠재적으로 높음(경우에 따라 더 나은 쿼리) + Connection.Open + Command.ExecuteReader + DataReader.Read 개체 구체화: 중간 - ID 조회: 보통 |
- 메타데이터 - 뷰 - 매개 변수 평가: 낮음 - 쿼리 - Materializer - 데이터베이스 쿼리 실행: 잠재적으로 높음(경우에 따라 더 나은 쿼리) + Connection.Open + Command.ExecuteReader + DataReader.Read 개체 구체화: 중간(EF5보다 빠름) - ID 조회: 보통 |
} |
Connection.Close | 낮음 | 낮음 | 낮음 |
콜드 쿼리와 웜 쿼리의 성능 비용을 줄이는 방법에는 여러 가지가 있으며, 다음 섹션에서 살펴보겠습니다. 특히 미리 생성된 뷰를 사용하여 콜드 쿼리에서 모델 로드 비용을 줄이는 것을 살펴보겠습니다. 이는 뷰 생성 중에 발생하는 성능 저하를 완화하는 데 도움이 됩니다. 웜 쿼리의 경우 쿼리 계획 캐싱, 추적 쿼리 없음 및 다양한 쿼리 실행 옵션을 다룹니다.
2.1 뷰 생성이란?
뷰 생성이 무엇인지 이해하려면 먼저 "매핑 뷰"가 무엇인지 이해해야 합니다. 매핑 뷰는 각 엔터티 집합 및 연결에 대한 매핑에 지정된 변환의 실행 가능한 표현입니다. 내부적으로 이러한 매핑 뷰는 CQT(정식 쿼리 트리)의 모양을 사용합니다. 매핑 뷰에는 두 가지 유형이 있습니다.
- 쿼리 뷰: 데이터베이스 스키마에서 개념적 모델로 이동하는 데 필요한 변환을 나타냅니다.
- 업데이트 뷰: 개념적 모델에서 데이터베이스 스키마로 이동하는 데 필요한 변환을 나타냅니다.
개념적 모델은 다양한 방식으로 데이터베이스 스키마와 다를 수 있습니다. 예를 들어 하나의 단일 테이블을 사용하여 두 개의 서로 다른 엔터티 형식에 대한 데이터를 저장할 수 있습니다. 상속 및 사소한 매핑은 매핑 뷰의 복잡성에 중요한 역할을 합니다.
매핑 사양에 따라 이러한 뷰를 계산하는 프로세스는 뷰 생성이라고 합니다. 뷰 생성은 모델이 로드될 때 동적으로 수행되거나 빌드 시 "미리 생성된 뷰"를 사용하여 발생할 수 있습니다. 후자는 Entity SQL 문의 형태로 C# 또는 VB 파일로 직렬화됩니다.
뷰가 생성되면 뷰의 유효성도 검사됩니다. 성능 관점에서 뷰 생성 비용의 대부분은 실제로 엔터티 간의 연결이 합리적이고 지원되는 모든 작업에 대해 올바른 카디널리티를 갖도록 하는 뷰의 유효성 검사입니다.
엔터티 집합에 대한 쿼리가 실행되면 쿼리가 해당 쿼리 뷰와 결합되고, 이 컴퍼지션의 결과는 계획 컴파일러를 통해 실행되어 지원 저장소가 이해할 수 있는 쿼리의 표현을 만듭니다. SQL Server 경우 이 컴파일의 최종 결과는 T-SQL SELECT 문입니다. 엔터티 집합에 대한 업데이트가 처음 수행될 때 업데이트 뷰는 유사한 프로세스를 통해 실행되어 대상 데이터베이스에 대한 DML 문으로 변환됩니다.
2.2 생성 성능 뷰에 영향을 주는 요소
뷰 생성 단계의 성능은 모델의 크기뿐만 아니라 모델이 상호 연결된 방식에 따라 달라집니다. 상속 체인 또는 연결을 통해 두 엔터티가 연결된 경우 연결이라고 합니다. 마찬가지로 두 테이블이 외래 키를 통해 연결된 경우 연결됩니다. 스키마의 연결된 엔터티 및 테이블 수가 증가함에 따라 뷰 생성 비용이 증가합니다.
뷰를 생성하고 유효성을 검사하는 데 사용하는 알고리즘은 최악의 경우 기하급수적이지만 이를 개선하기 위해 몇 가지 최적화를 사용합니다. 성능에 부정적인 영향을 주는 가장 큰 요인은 다음과 같습니다.
- 엔터티 수와 이러한 엔터티 간의 연결 양을 참조하는 모델 크기입니다.
- 모델 복잡성, 특히 많은 수의 형식이 포함된 상속입니다.
- 외래 키 연결 대신 독립 연결을 사용합니다.
작고 간단한 모델의 경우 비용이 미리 생성된 뷰를 사용하지 않을 만큼 작을 수 있습니다. 모델 크기와 복잡성이 증가함에 따라 뷰 생성 및 유효성 검사 비용을 줄이는 데 사용할 수 있는 몇 가지 옵션이 있습니다.
2.3 미리 생성된 뷰를 사용하여 모델 로드 시간 단축
Entity Framework 6에서 미리 생성된 뷰를 사용하는 방법에 대한 자세한 내용은 미리 생성된 매핑 뷰를 참조하세요.
2.3.1 Entity Framework Power Tools Community Edition을 사용하여 미리 생성된 뷰
Entity Framework 6 Power Tools Community Edition을 사용하여 모델 클래스 파일을 마우스 오른쪽 단추로 클릭하고 Entity Framework 메뉴를 사용하여 뷰 생성을 선택하여 “EDMX 및 Code First 모델의 뷰를 생성할 수 있습니다”. Entity Framework Power Tools Community Edition은 DbContext 파생 컨텍스트에서만 작동합니다.
2.3.2 EDMGen에서 만든 모델에서 미리 생성된 뷰를 사용하는 방법
EDMGen은 .NET과 함께 제공되는 유틸리티이며 Entity Framework 4 및 5에서 작동하지만 Entity Framework 6에서는 작동하지 않습니다. EDMGen을 사용하면 명령줄에서 모델 파일, 개체 계층 및 뷰를 생성할 수 있습니다. 출력 중 하나는 원하는 언어의 Views 파일(VB 또는 C#)입니다. 각 엔터티 집합에 대한 Entity SQL 코드 조각을 포함하는 코드 파일입니다. 미리 생성된 뷰를 사용하도록 설정하려면 프로젝트에 파일을 포함하기만 하면 됩니다.
모델에 대한 스키마 파일을 수동으로 편집하는 경우 뷰 파일을 다시 생성해야 합니다. /mode:ViewGeneration 플래그를 사용하여 EDMGen을 실행하여 이 작업을 수행할 수 있습니다.
2.3.3 EDMX 파일과 함께 미리 생성된 뷰를 사용하는 방법
EDMGen을 사용하여 EDMX 파일에 대한 뷰를 생성할 수도 있습니다. 이전에 참조된 MSDN 항목에서는 이를 위해 빌드 전 이벤트를 추가하는 방법을 설명하지만 이는 복잡하며 불가능한 경우도 있습니다. 일반적으로 T4 템플릿을 사용하여 모델이 edmx 파일에 있을 때 뷰를 생성하는 것이 더 쉽습니다.
ADO.NET 팀 블로그에는 뷰 생성(<https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>)에 T4 템플릿을 사용하는 방법을 설명하는 게시물이 있습니다. 이 게시물에는 다운로드하여 프로젝트에 추가할 수 있는 템플릿이 포함되어 있습니다. 템플릿은 첫 번째 버전의 Entity Framework용으로 작성되었으므로 최신 버전의 Entity Framework에서 작동하도록 보장되지 않습니다. 그러나 Visual Studio 갤러리에서 Entity Framework 4 및 5에 대한 최신 뷰 생성 템플릿 집합을 다운로드할 수 있습니다.
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Entity Framework 6을 사용하는 경우 의 Visual Studio 갤러리 <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>에서 뷰 생성 T4 템플릿을 가져올 수 있습니다.
2.4 뷰 생성 비용 절감
미리 생성된 뷰를 사용하면 뷰 생성 비용이 모델 로드(런타임)에서 디자인 시간으로 이동합니다. 이렇게 하면 런타임 시 시작 성능이 향상되지만 개발하는 동안 뷰 생성의 고통이 계속 발생합니다. 컴파일 시간과 런타임 모두에서 뷰 생성 비용을 줄이는 데 도움이 되는 몇 가지 추가 요령이 있습니다.
2.4.1 외래 키 연결을 사용하여 뷰 생성 비용 절감
모델의 연결을 독립 연결에서 외래 키 연결로 전환하면 뷰 생성에 소요된 시간이 크게 향상되는 경우가 많이 있습니다.
이러한 개선 사항을 설명하기 위해 EDMGen을 사용하여 두 가지 버전의 Navision 모델을 생성했습니다. 참고: Navision 모델에 대한 설명은 부록 C를 참조하세요. Navision 모델은 매우 많은 양의 엔터티와 엔터티 간의 관계로 인해 이 연습에서 흥미롭습니다.
이 매우 큰 모델의 한 버전은 외지 키 연결을 사용하여 생성되었고 다른 버전은 독립 연결을 사용하여 생성되었습니다. 그런 다음 각 모델에 대한 뷰를 생성하는 데 걸리는 시간을 지정했습니다. Entity Framework 5 테스트는 EntityViewGenerator 클래스의 GenerateViews() 메서드를 사용하여 뷰를 생성했으며 Entity Framework 6 테스트는 StorageMappingItemCollection 클래스의 GenerateViews() 메서드를 사용했습니다. 이는 Entity Framework 6 코드베이스에서 발생한 코드 재구성으로 인한 것입니다.
Entity Framework 5를 사용하여 외장 키를 사용하여 모델에 대한 뷰 생성은 랩 머신에서 65분이 걸렸습니다. 독립적인 연결을 사용한 모델에 대한 뷰를 생성하는 데 얼마나 오래 걸렸는지는 알 수 없습니다. 매월 업데이트를 설치하기 위해 랩에서 컴퓨터를 다시 부팅하기 전에 한 달 넘게 테스트를 실행했습니다.
Entity Framework 6을 사용하여 외장 키가 있는 모델의 뷰 생성은 동일한 랩 머신에서 28초가 걸렸습니다. 독립 연결을 사용하는 모델의 뷰 생성에는 58초가 걸렸습니다. 뷰 생성 코드에서 Entity Framework 6의 향상된 기능은 많은 프로젝트에서 더 빠른 시작 시간을 얻기 위해 미리 생성된 뷰가 필요하지 않음을 의미합니다.
Entity Framework 4 및 5에서 미리 생성된 뷰는 EDMGen 또는 Entity Framework Power Tools를 사용하여 수행할 수 있습니다. Entity Framework 6 뷰 생성의 경우 Entity Framework Power Tools를 통해 또는 미리 생성된 매핑 뷰에 설명된 대로 프로그래밍 방식으로 수행할 수 있습니다.
2.4.1.1 독립 연결 대신 외장 키를 사용하는 방법
Visual Studio에서 EDMGen 또는 엔터티 디자이너를 사용하는 경우 기본적으로 FK를 가져올 수 있으며, FK와 IA 간에 전환하려면 단일 확인란 또는 명령줄 플래그만 사용합니다.
큰 Code First 모델이 있는 경우 독립 연결을 사용하면 뷰 생성에 동일한 영향을 줍니다. 일부 개발자는 개체 모델을 오염시키는 것으로 간주하지만 종속 개체의 클래스에 Foreign Key 속성을 포함하면 이러한 영향을 방지할 수 있습니다. 이 주제에 대한 자세한 내용은 <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>에서 확인할 수 있습니다.
| 을 사용하는 경우 다음 위치에서 편집기에 액세스할 수 있습니다. | 방법 |
|---|---|
| Entity Designer | 두 엔터티 간의 연결을 추가한 후 참조 제약 조건이 있는지 확인합니다. 참조 제약 조건은 Entity Framework에 독립 연결 대신 외장 키를 사용하도록 지시합니다. 자세한 내용은 <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>를 참조하세요. |
| EDMGen | EDMGen을 사용하여 데이터베이스에서 파일을 생성하는 경우 외장 키가 준수되고 모델에 추가됩니다. EDMGen에서 노출하는 다양한 옵션에 대한 자세한 내용은 http://msdn.microsoft.com/library/bb387165.aspx를 방문하세요. |
| Code First | Code First를 사용할 때 종속 개체에 외래 키 속성을 포함하는 방법에 대한 자세한 내용은 Code First 규칙 항목의 "관계 규칙" 섹션을 참조하세요. |
2.4.2 모델을 별도의 어셈블리로 이동
모델이 애플리케이션의 프로젝트에 직접 포함되어 있고 빌드 전 이벤트 또는 T4 템플릿을 통해 뷰를 생성하는 경우 모델이 변경되지 않은 경우에도 프로젝트가 다시 빌드될 때마다 뷰 생성 및 유효성 검사가 수행됩니다. 모델을 별도의 어셈블리로 이동하고 애플리케이션의 프로젝트에서 참조하는 경우 모델이 포함된 프로젝트를 다시 빌드할 필요 없이 애플리케이션을 다른 변경 내용으로 만들 수 있습니다.
참고: 모델을 별도의 어셈블리로 이동할 때는 모델의 연결 문자열을 클라이언트 프로젝트의 애플리케이션 구성 파일에 복사해야 합니다.
2.4.3 edmx 기반 모델의 유효성 검사 사용 안 함
EDMX 모델은 모델이 변경되지 않더라도 컴파일 시간에 유효성이 검사됩니다. 모델의 유효성을 이미 검사한 경우 속성 창에서 "빌드 시 유효성 검사" 속성을 false로 설정하여 컴파일 시간에 유효성 검사를 표시하지 않을 수 있습니다. 매핑 또는 모델을 변경할 때 일시적으로 유효성 검사를 다시 사용하도록 설정하여 변경 내용을 확인할 수 있습니다.
Entity Framework 6용 Entity Framework Designer의 성능이 향상되었으며 "빌드 시 유효성 검사"의 비용은 이전 버전의 디자이너보다 훨씬 낮습니다.
3 Entity Framework의 캐싱
Entity Framework에는 다음과 같은 형태의 캐싱 기본 제공이 있습니다.
- 개체 캐싱 – ObjectContext 인스턴스에 기본 제공되는 ObjectStateManager는 해당 인스턴스를 사용하여 검색된 개체의 메모리를 추적합니다. 이를 첫 번째 수준 캐시라고도 합니다.
- 쿼리 계획 캐싱 - 쿼리가 두 번 이상 실행될 때 생성된 store 명령을 다시 사용합니다.
- 메타데이터 캐싱 - 동일한 모델에 대한 서로 다른 연결에서 모델에 대한 메타데이터를 공유합니다.
EF가 기본으로 제공하는 캐시 외에도 래핑 공급자라고 하는 특수한 종류의 ADO.NET 데이터 공급자를 사용하여 데이터베이스에서 검색된 결과에 대한 캐시를 사용하여 Entity Framework를 확장할 수 있습니다(두 번째 수준 캐싱이라고도 함).
3.1 개체 캐싱
기본적으로 쿼리 결과에서 엔터티가 반환될 때 EF가 이를 구체화하기 직전에 ObjectContext는 동일한 키를 가진 엔터티가 이미 ObjectStateManager에 로드되었는지 확인합니다. 동일한 키를 가진 엔터티가 이미 있는 경우 EF는 쿼리 결과에 포함됩니다. EF는 여전히 데이터베이스에 대해 쿼리를 실행하지만 이 동작은 엔터티를 여러 번 구체화하는 데 드는 많은 비용을 무시할 수 있습니다.
3.1.1 DbContext Find를 사용하여 개체 캐시에서 엔터티 가져오기
일반 쿼리와 달리 DbSet의 Find 메서드(EF 4.1에 처음으로 포함된 API)는 데이터베이스에 대해 쿼리를 실행하기 전에 메모리에서 검색을 수행합니다. 두 개의 서로 다른 ObjectContext 인스턴스에는 서로 다른 두 개의 ObjectStateManager 인스턴스가 있습니다. 즉, 별도의 개체 캐시가 있습니다.
DbSet의 Find 메서드는 기본 키 값을 사용하여 컨텍스트에서 추적하는 엔터티를 찾으려고 시도합니다. 엔터티가 컨텍스트에 없는 경우 쿼리가 데이터베이스에 대해 실행 및 평가되고 엔터티가 컨텍스트 또는 데이터베이스에서 찾을 수 없는 경우 null이 반환됩니다. 즉, Find는 컨텍스트에 추가되었지만 아직 데이터베이스에 저장되지 않은 엔터티를 반환합니다.
찾기를 사용할 때 수행해야 하는 성능 고려 사항이 있습니다. 기본적으로 이 메서드를 호출하면 데이터베이스에 대한 커밋 보류 중인 변경 내용을 검색하기 위해 개체 캐시의 유효성 검사가 트리거됩니다. 개체 캐시 또는 개체 캐시에 추가되는 개체 그래프가 매우 많은 경우 이 프로세스는 비용이 많이 들 수 있지만 사용하지 않도록 설정할 수도 있습니다. 경우에 따라 자동 검색 변경 내용을 사용하지 않도록 설정할 때 Find 메서드를 호출할 때 큰 차이의 순서를 인식할 수 있습니다. 그러나 개체가 실제로 캐시에 있을 때와 데이터베이스에서 개체를 검색해야 하는 경우의 두 번째 크기가 인식됩니다. 다음은 5,000개의 엔터티가 로드된 밀리초 단위로 표현된 일부 마이크로벤치마크를 사용하여 측정한 예제 그래프입니다.

자동 검색 변경 내용이 비활성화된 찾기의 예:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Find 메서드를 사용할 때 고려해야 할 사항은 다음과 같습니다.
- 개체가 캐시에 없는 경우 Find의 이점은 부정되지만 구문은 여전히 키별 쿼리보다 간단합니다.
- 자동 검색 변경 내용을 사용하도록 설정하면 Find 메서드의 비용이 모델의 복잡성과 개체 캐시의 엔터티 양에 따라 한 순서씩 증가하거나 훨씬 더 증가할 수 있습니다.
또한 Find는 찾고 있는 엔터티만 반환하며 연결된 엔터티가 개체 캐시에 아직 없는 경우 자동으로 로드되지 않습니다. 연결된 엔터티를 검색해야 하는 경우 즉시 로드할 때 키별 쿼리를 사용할 수 있습니다. 자세한 내용은 8.1 지연 로드 및 즉시 로드를 참조하세요.
3.1.2 개체 캐시에 많은 엔터티가 있는 경우 성능 문제
개체 캐시는 Entity Framework의 전반적인 응답성을 높이는 데 도움이 됩니다. 그러나 개체 캐시에 로드된 엔터티가 매우 많은 경우 추가, 제거, 찾기, 항목, SaveChanges 등과 같은 특정 작업에 영향을 줄 수 있습니다. 특히 DetectChanges 호출을 트리거하는 작업은 매우 큰 개체 캐시의 영향을 받습니다. DetectChanges는 개체 그래프를 개체 상태 관리자와 동기화하고 해당 성능은 개체 그래프의 크기에 따라 직접 결정됩니다. DetectChanges에 대한 자세한 내용은 POCO 엔터티의 변경 내용 추적을 참조하세요.
Entity Framework 6을 사용하는 경우 개발자는 컬렉션을 반복하고 인스턴스당 한 번 추가를 호출하는 대신 DbSet에서 직접 AddRange 및 RemoveRange를 호출할 수 있습니다. 범위 메서드를 사용하는 이점은 추가된 각 엔터티당 한 번이 아니라 전체 엔터티 집합에 대해 DetectChanges 비용이 한 번만 지불된다는 것입니다.
3.2 쿼리 계획 캐싱
쿼리가 처음 실행되면 내부 계획 컴파일러를 통해 개념적 쿼리를 store 명령(예: SQL Server 대해 실행할 때 실행되는 T-SQL)으로 변환합니다. 쿼리 계획 캐싱을 사용하도록 설정하면 다음에 쿼리가 실행될 때 실행하기 위해 쿼리 계획 캐시에서 직접 store 명령을 검색하고 계획 컴파일러를 무시합니다.
쿼리 계획 캐시는 동일한 AppDomain 내의 ObjectContext 인스턴스 간에 공유됩니다. 쿼리 계획 캐싱의 이점을 활용하려면 ObjectContext 인스턴스를 유지할 필요가 없습니다.
3.2.1 쿼리 계획 캐싱에 대한 몇 가지 참고 사항
- 쿼리 계획 캐시는 Entity SQL, LINQ to Entities 및 CompiledQuery 개체와 같은 모든 쿼리 형식에 대해 공유됩니다.
- 기본적으로 EntityCommand를 통해 또는 ObjectQuery를 통해 실행되었는지 여부에 관계없이 Entity SQL 쿼리에 대해 쿼리 계획 캐싱을 사용하도록 설정됩니다. 또한 .NET 4.5의 Entity Framework 및 Entity Framework 6에서 LINQ to Entities 쿼리에 대해 기본적으로 사용하도록 설정됩니다.
- EnablePlanCaching 속성(EntityCommand 또는 ObjectQuery)을 false로 설정하여 쿼리 계획 캐싱을 사용하지 않도록 설정할 수 있습니다. 예시:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- 매개 변수가 있는 쿼리의 경우 매개 변수의 값을 변경해도 캐시된 쿼리에 도달합니다. 그러나 매개 변수의 패싯(예: 크기, 정밀도 또는 배율)을 변경하면 캐시의 다른 항목에 도달합니다.
- Entity SQL을 사용하는 경우 쿼리 문자열은 키의 일부입니다. 쿼리를 전혀 변경하면 쿼리가 기능적으로 동일한 경우에도 다른 캐시 항목이 발생합니다. 여기에는 대/소문자 또는 공백에 대한 변경 내용이 포함됩니다.
- LINQ를 사용하는 경우 키의 일부를 생성하기 위해 쿼리가 처리됩니다. 따라서 LINQ 식을 변경하면 다른 키가 생성됩니다.
- 기타 기술적 제한 사항이 적용될 수 있습니다. 자세한 내용은 자동 컴파일된 쿼리를 참조하세요.
3.2.2 캐시 제거 알고리즘
내부 알고리즘의 작동 방식을 이해하면 쿼리 계획 캐싱을 사용하거나 사용하지 않도록 설정하는 시기를 파악하는 데 도움이 됩니다. 정리 알고리즘은 다음과 같습니다.
- 캐시에 설정된 항목 수(800)가 포함되면 주기적으로(분당 한 번) 캐시를 스윕하는 타이머를 시작합니다.
- 캐시 스윕 중에 항목은 LFRU(가장 자주 - 최근에 사용됨) 기준으로 캐시에서 제거됩니다. 이 알고리즘은 배출되는 항목을 결정할 때 적중 횟수와 나이를 모두 고려합니다.
- 각 캐시 스윕이 끝나면 캐시에 800개의 항목이 다시 포함됩니다.
제거할 항목을 결정할 때 모든 캐시 항목이 동일하게 처리됩니다. 즉, CompiledQuery에 대한 store 명령은 Entity SQL 쿼리에 대한 store 명령과 동일한 제거 가능성이 있습니다.
캐시에 800개 엔터티가 있는 경우 캐시 제거 타이머가 시작되지만 이 타이머가 시작된 후 60초 만에 캐시가 스윕됩니다. 즉, 최대 60초 동안 캐시가 매우 커질 수 있습니다.
3.2.3 쿼리 계획 캐싱 성능을 보여 주는 테스트 메트릭
쿼리 계획 캐싱이 애플리케이션 성능에 미치는 영향을 설명하기 위해 Navision 모델에 대해 여러 Entity SQL 쿼리를 실행한 테스트를 수행했습니다. Navision 모델 및 실행된 쿼리 유형에 대한 설명은 부록을 참조하세요. 이 테스트에서는 먼저 쿼리 목록을 반복하고 각 쿼리를 한 번 실행하여 캐시에 추가합니다(캐싱을 사용하는 경우). 이 단계는 시간이 지날 수 없습니다. 다음으로, 캐시 스윕이 수행되도록 주 스레드를 60초 이상 절전 모드로 설정합니다. 마지막으로 목록을 2번 반복하여 캐시된 쿼리를 실행합니다. 또한 각 쿼리 집합이 실행되기 전에 SQL Server 계획 캐시가 플러시되므로 얻은 시간이 쿼리 계획 캐시에서 제공하는 이점을 정확하게 반영합니다.
3.2.3.1 테스트 결과
| 테스트 | EF5 캐시 없음 | EF5 캐시됨 | EF6 캐시 없음 | EF6 캐시됨 |
|---|---|---|---|---|
| 18723개 쿼리 모두 열거 | 124 | 125.4 | 124.3 | 125.3 |
| 스윕 방지(복잡성에 관계없이 처음 800개 쿼리만) | 41.7 | 5.5 | 40.5 | 5.4 |
| AggregatingSubtotals 쿼리만(총 178개 - 스윕 방지) | 39.5 | 4.5. | 38.1 | 4.6 |
모든 시간은 초 단위입니다.
도덕적 - 많은 고유 쿼리(예: 동적으로 생성된 쿼리)를 실행할 때 캐싱은 도움이 되지 않으며 캐시의 결과 플러시로 인해 실제로 계획 캐싱을 통해 가장 많은 이점을 얻을 수 있는 쿼리를 유지할 수 있습니다.
AggregatingSubtotals 쿼리는 테스트한 쿼리 중 가장 복잡합니다. 예상대로 쿼리가 복잡할수록 쿼리 계획 캐싱에서 더 많은 이점을 얻을 수 있습니다.
CompiledQuery는 실제로 계획이 캐시된 LINQ 쿼리이므로 CompiledQuery와 동등한 Entity SQL 쿼리의 비교 결과는 유사해야 합니다. 실제로 앱에 동적 Entity SQL 쿼리가 많은 경우 캐시를 쿼리로 채우면 캐시에서 플러시될 때 CompiledQueries가 효과적으로 "디컴파일"됩니다. 이 시나리오에서는 동적 쿼리에서 캐싱을 사용하지 않도록 설정하여 CompiledQueries의 우선 순위를 지정하여 성능을 향상시킬 수 있습니다. 물론 동적 쿼리 대신 매개 변수가 있는 쿼리를 사용하도록 앱을 다시 작성하는 것이 좋습니다.
3.3 CompiledQuery를 사용하여 LINQ 쿼리로 성능 향상
테스트는 CompiledQuery를 사용하면 자동 컴파일된 LINQ 쿼리보다 7%의 이점을 얻을 수 있음을 나타냅니다. 즉, Entity Framework 스택에서 코드를 실행하는 데 7% 더 적은 시간을 소비하게 됩니다. 애플리케이션이 7% 더 빠르다는 의미는 아닙니다. 일반적으로 EF 5.0에서 CompiledQuery 개체를 작성하고 유지 관리하는 비용은 이점과 비교할 때 문제가 되지 않을 수 있습니다. 마일리지는 다를 수 있으므로 프로젝트에 추가 푸시가 필요한 경우 이 옵션을 실행합니다. CompiledQueries는 ObjectContext 파생 모델과만 호환되며 DbContext 파생 모델과 호환되지 않습니다.
CompiledQuery를 만들고 호출하는 방법에 대한 자세한 내용은 컴파일된 쿼리(LINQ to Entities)를 참조하세요.
CompiledQuery를 사용할 때 고려해야 할 두 가지 고려 사항이 있습니다. 즉 정적 인스턴스를 사용해야 하는 요구 사항과 구성 가능성과 관련된 문제입니다. 다음은 이 두 가지 고려 사항에 대한 자세한 설명을 따릅니다.
3.3.1 정적 CompiledQuery 인스턴스 사용
LINQ 쿼리를 컴파일하는 것은 시간이 많이 걸리는 프로세스이므로 데이터베이스에서 데이터를 가져와야 할 때마다 수행하지 않습니다. CompiledQuery 인스턴스를 사용하면 한 번 컴파일하고 여러 번 실행할 수 있지만 반복해서 컴파일하는 대신 매번 동일한 CompiledQuery 인스턴스를 다시 사용하기 위해 신중하고 조달해야 합니다. 정적 멤버를 사용하여 CompiledQuery 인스턴스를 저장해야 합니다. 그렇지 않으면 어떤 혜택도 표시되지 않습니다.
예를 들어 페이지에 선택한 범주에 대한 제품 표시를 처리하는 다음 메서드 본문이 있다고 가정합니다.
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
이 경우 메서드가 호출될 때마다 즉시 새 CompiledQuery 인스턴스를 만듭니다. 쿼리 계획 캐시에서 store 명령을 검색하여 성능상의 이점을 보는 대신, CompiledQuery는 새 인스턴스가 만들어질 때마다 계획 컴파일러를 통과합니다. 실제로 메서드가 호출될 때마다 새 CompiledQuery 항목으로 쿼리 계획 캐시가 오염됩니다.
대신 컴파일된 쿼리의 정적 인스턴스를 만들려고 하므로 메서드가 호출될 때마다 동일한 컴파일된 쿼리를 호출합니다. 이렇게 하는 한 가지 방법은 CompiledQuery 인스턴스를 개체 컨텍스트의 멤버로 추가하는 것입니다. 그런 다음 도우미 메서드를 통해 CompiledQuery에 액세스하여 작업을 좀 더 깔끔하게 만들 수 있습니다.
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
이 도우미 메서드는 다음과 같이 호출됩니다.
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 CompiledQuery를 통해 작성
LINQ 쿼리를 통해 작성하는 기능은 매우 유용합니다. 이렇게 하려면 Skip() 또는 Count()와 같은 IQueryable 다음에 메서드를 호출하기만 하면 됩니다. 그러나 이렇게 하면 기본적으로 새 IQueryable 개체가 반환됩니다. 기술적으로 CompiledQuery를 통해 구성하는 것을 막을 수 있는 것은 없지만 이렇게 하면 계획 컴파일러를 다시 통과해야 하는 새 IQueryable 개체가 생성됩니다.
일부 구성 요소는 구성된 IQueryable 개체를 사용하여 고급 기능을 사용하도록 설정합니다. 예를 들어 ASP.NET의 GridView는 SelectMethod 속성을 통해 IQueryable 개체에 데이터 바인딩될 수 있습니다. 그런 다음 GridView는 이 IQueryable 개체를 통해 구성하여 데이터 모델에 대한 정렬 및 페이징을 허용합니다. 볼 수 있듯이 GridView에 CompiledQuery를 사용하면 컴파일된 쿼리에 충돌하지 않지만 새 자동 컴파일된 쿼리가 생성됩니다.
쿼리에 프로그레시브 필터를 추가할 때 이 작업이 발생할 수 있는 한 곳입니다. 예를 들어 선택적 필터(예: Country 및 OrdersCount)에 대한 여러 드롭다운 목록이 있는 고객 페이지가 있다고 가정합니다. CompiledQuery의 IQueryable 결과에 대해 이러한 필터를 작성할 수 있지만 이렇게 하면 새 쿼리가 실행될 때마다 계획 컴파일러를 통해 진행됩니다.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
이 다시 컴파일을 방지하려면 CompiledQuery를 다시 작성하여 가능한 필터를 고려할 수 있습니다.
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
다음과 같이 UI에서 호출됩니다.
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
여기서 장단점은 생성된 store 명령에 항상 null 검사가 있는 필터가 있지만 데이터베이스 서버에서 최적화하는 것은 매우 간단해야 합니다.
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 메타데이터 캐싱
Entity Framework는 메타데이터 캐싱도 지원합니다. 이는 기본적으로 동일한 모델에 대한 서로 다른 연결에서 형식 정보 및 형식-데이터베이스 매핑 정보를 캐싱하는 것입니다. 메타데이터 캐시는 AppDomain별로 고유합니다.
3.4.1 메타데이터 캐싱 알고리즘
모델에 대한 메타데이터 정보는 각 EntityConnection에 대한 ItemCollection에 저장됩니다.
- 참고로 모델의 여러 부분에 대해 다른 ItemCollection 개체가 있습니다. 예를 들어 StoreItemCollections에는 데이터베이스 모델에 대한 정보가 포함됩니다. ObjectItemCollection에는 데이터 모델에 대한 정보가 포함되어 있습니다. EdmItemCollection에는 개념적 모델에 대한 정보가 포함되어 있습니다.
두 연결이 동일한 연결 문자열을 사용하는 경우 동일한 ItemCollection 인스턴스를 공유합니다.
기능적으로 동일하지만 텍스트로 다른 연결 문자열로 인해 메타데이터 캐시가 다를 수 있습니다. 연결 문자열을 토큰화하므로 토큰 순서를 변경하기만 하면 공유 메타데이터가 생성됩니다. 그러나 기능적으로 동일한 것으로 보이는 두 개의 연결 문자열은 토큰화 후에 동일하게 평가되지 않을 수 있습니다.
ItemCollection은 주기적으로 사용하도록 확인됩니다. 작업 영역에 최근에 액세스하지 않은 것으로 확인되면 다음 캐시 스윕에서 정리되도록 표시됩니다.
EntityConnection을 만들면 메타데이터 캐시가 만들어집니다(연결이 열릴 때까지 항목 컬렉션은 초기화되지 않음). 이 작업 영역은 캐싱 알고리즘이 "사용 중"이 아니라고 판단할 때까지 메모리 내로 유지됩니다.
고객 자문 팀은 대형 모델을 사용할 때 "사용 중단"을 방지하기 위해 ItemCollection에 대한 참조를 보유하는 것을 설명하는 블로그 게시물을 작성했습니다(<https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>).
3.4.2 메타데이터 캐싱과 쿼리 계획 캐싱 간의 관계
쿼리 계획 캐시 인스턴스는 MetadataWorkspace의 Store 형식 ItemCollection에 있습니다. 즉, 캐시된 store 명령은 지정된 MetadataWorkspace를 사용하여 인스턴스화된 컨텍스트에 대한 쿼리에 사용됩니다. 또한 토큰화 후 약간 다르고 일치하지 않는 두 개의 연결 문자열이 있는 경우 다른 쿼리 계획 캐시 인스턴스가 있음을 의미합니다.
3.5 결과 캐싱
결과 캐싱("두 번째 수준 캐싱"라고도 함)을 사용하면 쿼리 결과를 로컬 캐시에 유지합니다. 쿼리를 실행할 때 먼저 저장소에 대해 쿼리하기 전에 결과를 로컬로 사용할 수 있는지 확인합니다. 결과 캐싱은 Entity Framework에서 직접 지원되지 않지만 래핑 공급자를 사용하여 두 번째 수준 캐시를 추가할 수 있습니다. 두 번째 수준 캐시가 있는 래핑 공급자의 예는 NCache를 기반으로 하는 Alachisoft의 Entity Framework 두 번째 수준 캐시입니다.
이 두 번째 수준 캐싱 구현은 LINQ 식이 평가되고(및 funcletized) 쿼리 실행 계획이 첫 번째 수준 캐시에서 계산되거나 검색된 후에 발생하는 삽입된 기능입니다. 그런 다음 두 번째 수준 캐시는 원시 데이터베이스 결과만 저장하므로 구체화 파이프라인은 나중에 계속 실행됩니다.
3.5.1 래핑 공급자를 사용하여 결과 캐싱에 대한 추가 참조
- Julie Lerman은 Windows Server AppFabric 캐싱을 사용하도록 샘플 래핑 공급자를 업데이트하는 방법을 포함하는 "Entity Framework 및 Windows Azure의 두 번째 수준 캐싱" MSDN 문서를 작성했습니다(https://msdn.microsoft.com/magazine/hh394143.aspx).
- Entity Framework 5를 사용하는 경우 팀 블로그에는 Entity Framework 5용 캐싱 공급자를 사용하여 실행하는 방법을 설명하는 게시물이 있습니다(<https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>). 또한 프로젝트에 2단계 캐싱을 자동으로 추가하는 데 도움이 되는 T4 템플릿도 포함되어 있습니다.
자동 컴파일된 쿼리 4개
Entity Framework를 사용하여 데이터베이스에 대해 쿼리를 실행한 경우 실제로 결과를 구체화하기 전에 일련의 단계를 거쳐야 합니다. 이러한 단계 중 하나는 쿼리 컴파일입니다. 엔터티 SQL 쿼리는 자동으로 캐시되므로 성능이 좋은 것으로 알려져 있으므로 동일한 쿼리를 두 번째 또는 세 번째로 실행할 때 계획 컴파일러를 건너뛰고 캐시된 계획을 대신 사용할 수 있습니다.
Entity Framework 5에는 LINQ to Entities 쿼리에 대한 자동 캐싱도 도입되었습니다. 성능 속도를 높이기 위해 CompiledQuery를 만드는 이전 버전의 Entity Framework에서는 LINQ to Entities 쿼리를 캐시할 수 있으므로 일반적인 사례였습니다. 이제 CompiledQuery를 사용하지 않고 캐싱이 자동으로 수행되므로 이 기능을 "자동 컴파일된 쿼리"라고 합니다. 쿼리 계획 캐시 및 해당 메커니즘에 대한 자세한 내용은 쿼리 계획 캐싱을 참조하세요.
Entity Framework는 쿼리를 다시 컴파일해야 하는 경우를 감지하고 이전에 컴파일된 경우에도 쿼리가 호출될 때 이를 수행합니다. 쿼리를 다시 컴파일하는 일반적인 조건은 다음과 같습니다.
- 쿼리에 연결된 MergeOption 변경 캐시된 쿼리는 사용되지 않습니다. 대신 계획 컴파일러가 다시 실행되고 새로 만든 계획이 캐시됩니다.
- ContextOptions.UseCSharpNullComparisonBehavior 값을 변경합니다. MergeOption을 변경하는 것과 동일한 효과를 얻습니다.
다른 조건으로 인해 쿼리가 캐시를 사용하지 못할 수 있습니다. 일반적인 예는 다음과 같습니다.
- IEnumerable<T>.Contains<> 사용(T 값).
- 상수를 사용하여 쿼리를 생성하는 함수 사용.
- 매핑하지 않은 개체의 속성 사용.
- 쿼리를 다시 컴파일해야 하는 다른 쿼리에 연결.
4.1 IEnumerable<T>.Contains<T> 사용(T 값)
컬렉션의 값은 휘발성으로 간주되므로 Entity Framework는 메모리 내 컬렉션에 대해 IEnumerable<T>.Contains<T>(T 값)를 호출하는 쿼리를 캐시하지 않습니다. 다음 예제 쿼리는 캐시되지 않으므로 항상 계획 컴파일러에서 처리됩니다.
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Contains가 실행되는 IEnumerable의 크기는 쿼리가 컴파일되는 속도 또는 속도를 결정합니다. 위의 예제에 표시된 것과 같은 큰 컬렉션을 사용할 때 성능이 크게 저하할 수 있습니다.
Entity Framework 6에는 쿼리가 실행될 때 IEnumerable<T>.Contains<T>(T 값)가 작동하는 방식에 대한 최적화가 포함되어 있습니다 생성되는 SQL 코드는 생성 속도가 훨씬 빠르며 읽기가 가능하며, 대부분의 경우 서버에서도 더 빠르게 실행됩니다.
4.2 상수가 있는 쿼리를 생성하는 함수 사용
Skip(), Take(), Contains() 및 DefautIfEmpty() LINQ 연산자는 매개 변수를 사용하여 SQL 쿼리를 생성하지 않고 전달된 값을 상수로 배치합니다. 이로 인해 동일할 수 있는 쿼리는 EF 스택과 데이터베이스 서버 모두에서 쿼리 계획 캐시를 오염시키고 후속 쿼리 실행에서 동일한 상수를 사용하지 않는 한 다시 사용되지 않습니다. 예시:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
이 예제에서는 이 쿼리가 ID에 대해 다른 값으로 실행될 때마다 쿼리가 새 계획으로 컴파일됩니다.
특히 페이징을 수행할 때 건너뛰기 및 가져오기 사용에 주의하세요. EF6에서는 이러한 메서드에 전달된 변수를 캡처하고 SQLparameters로 변환할 수 있으므로 캐시된 쿼리 계획을 효과적으로 재사용할 수 있는 람다 오버로드가 있습니다. 또한 Skip 및 Take에 대해 상수가 다른 각 쿼리가 자체 쿼리 계획 캐시 항목을 가져올 수 있기 때문에 캐시 클리너를 유지하는 데도 도움이 됩니다.
최적이 아니지만 이 쿼리 클래스를 예시하기 위한 다음 코드를 고려합니다.
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
이 동일한 코드의 더 빠른 버전에는 람다를 사용하여 Skip을 호출하는 작업이 포함됩니다.
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
두 번째 코드 조각은 쿼리가 실행 될 때마다 동일한 쿼리 계획이 사용되므로 CPU 시간을 절약하고 쿼리 캐시의 오염을 방지하므로 최대 11 % 더 빠르게 실행 될 수 있습니다. 또한 Skip 매개 변수가 닫히기 때문에 코드도 다음과 같이 표시될 수 있습니다.
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 매핑하지 않은 개체의 속성 사용
쿼리가 매핑되지 않은 개체 형식의 속성을 매개 변수로 사용하는 경우 쿼리는 캐시되지 않습니다. 예시:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
이 예제에서는 NonMappedType 클래스가 엔터티 모델의 일부가 아니라고 가정합니다. 매핑되지 않은 형식을 사용하지 않고 대신 로컬 변수를 쿼리의 매개 변수로 사용하도록 이 쿼리를 쉽게 변경할 수 있습니다.
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
이 경우 쿼리는 캐시될 수 있으며 쿼리 계획 캐시의 이점을 누릴 수 있습니다.
4.4 다시 컴파일해야 하는 쿼리에 연결
위와 동일한 예제에 따라 다시 컴파일해야 하는 쿼리를 사용하는 두 번째 쿼리가 있는 경우 전체 두 번째 쿼리도 다시 컴파일됩니다. 이 시나리오를 설명하는 예제는 다음과 같습니다.
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
예제는 제네릭이지만 firstQuery에 연결하면 secondQuery가 캐시되지 않는 방법을 보여 줍니다. firstQuery가 다시 컴파일해야 하는 쿼리가 아니었다면 secondQuery는 캐시되었을 것입니다.
5 NoTracking 쿼리
5.1 상태 관리 오버헤드를 줄이기 위해 변경 내용 추적을 사용하지 않도록 설정
읽기 전용 시나리오에서 개체를 ObjectStateManager에 로드하는 오버헤드를 방지하려면 "추적 없음" 쿼리를 실행할 수 있습니다. 쿼리 수준에서 변경 내용 추적을 사용하지 않도록 설정할 수 있습니다.
변경 내용 추적을 사용하지 않도록 설정하면 개체 캐시를 효과적으로 해제할 수 있습니다. 엔터티를 쿼리할 때 ObjectStateManager에서 이전에 구체화된 쿼리 결과를 끌어와 구체화를 건너뛸 수 없습니다. 동일한 컨텍스트에서 동일한 엔터티를 반복적으로 쿼리하는 경우 실제로 변경 내용 추적을 사용하도록 설정하면 성능이 향상될 수 있습니다.
ObjectContext를 사용하여 쿼리할 때 ObjectQuery 및 ObjectSet 인스턴스는 설정되면 MergeOption을 기억하며, 이 인스턴스에 구성된 쿼리는 부모 쿼리의 유효 MergeOption을 상속합니다. DbContext를 사용하는 경우 DbSet에서 AsNoTracking() 한정자를 호출하여 추적을 사용하지 않도록 설정할 수 있습니다.
5.1.1 DbContext를 사용할 때 쿼리에 대한 변경 내용 추적 비활성화
쿼리에서 AsNoTracking() 메서드에 대한 호출을 연결하여 쿼리 모드를 NoTracking으로 전환할 수 있습니다. ObjectQuery와 달리 DbContext API의 DbSet 및 DbQuery 클래스에는 MergeOption에 대한 변경 가능한 속성이 없습니다.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 ObjectContext를 사용하여 쿼리 수준에서 변경 내용 추적 비활성화
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 ObjectContext를 사용하여 전체 엔터티 집합에 대한 변경 내용 추적 비활성화
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 NoTracking 쿼리의 성능 이점을 보여 주는 테스트 메트릭
이 테스트에서는 추적을 Navision 모델에 대한 NoTracking 쿼리와 비교하여 ObjectStateManager를 채우는 비용을 살펴봅니다. Navision 모델 및 실행된 쿼리 유형에 대한 설명은 부록을 참조하세요. 이 테스트에서는 쿼리 목록을 반복하고 각 쿼리를 한 번 실행합니다. 테스트의 두 가지 변형을 실행했습니다. 한 번은 NoTracking 쿼리를 사용하고 기본 병합 옵션은 "AppendOnly"로 한 번 실행했습니다. 각 변형을 3번 실행하고 실행의 평균 값을 사용합니다. 테스트 사이에 다음 명령을 실행하여 SQL Server 쿼리 캐시를 지우고 tempdb를 축소합니다.
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE(tempdb, 0)
테스트 결과, 3회 이상의 평균 실행:
| 추적 없음 – 작업 집합 | 추적 없음 – 시간 | 추가 전용 – 작업 집합 | 추가 전용 – 시간 | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536밀리초 | 596545536 | 1273042밀리초 |
| Entity Framework 6 | 647127040 | 190228밀리초 | 832798720 | 195521밀리초 |
Entity Framework 5는 실행이 끝날 때 Entity Framework 6보다 메모리 공간이 더 적습니다. Entity Framework 6에서 사용하는 추가 메모리는 새로운 기능과 더 나은 성능을 가능하게 하는 추가 메모리 구조 및 코드의 결과입니다.
ObjectStateManager를 사용할 때 메모리 공간의 명확한 차이점도 있습니다. Entity Framework 5는 데이터베이스에서 구체화한 모든 엔터티를 추적할 때 공간을 30% 증가시켰습니다. Entity Framework 6은 이 작업을 수행할 때 공간을 28% 증가시켰습니다.
시간 측면에서 Entity Framework 6은 이 테스트에서 Entity Framework 5보다 큰 차이로 능가합니다. Entity Framework 6은 Entity Framework 5에서 소요된 시간의 약 16%에서 테스트를 완료했습니다. 또한 Entity Framework 5는 ObjectStateManager를 사용할 때 완료하는 데 9% 더 많은 시간이 걸립니다. 반면 Entity Framework 6은 ObjectStateManager를 사용할 때 3% 더 많은 시간을 사용하고 있습니다.
6 쿼리 실행 옵션
Entity Framework는 쿼리하는 여러 가지 방법을 제공합니다. 다음 옵션을 살펴보고, 각 옵션의 장단점을 비교하고, 성능 특성을 살펴봅니다.
- LINQ to Entities.
- 추적 LINQ to Entities 없습니다.
- ObjectQuery를 통해 엔터티 SQL.
- EntityCommand를 통해 Entity SQL.
- ExecuteStoreQuery.
- SqlQuery.
- CompiledQuery.
6.1 LINQ to Entities 쿼리
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
장점
- CUD 작업에 적합합니다.
- 완전히 구체화된 개체입니다.
- 프로그래밍 언어에 기본 제공되는 구문을 사용하여 작성하는 것이 가장 간단합니다.
- 성능 양호.
단점
- 다음과 같은 특정 기술 제한 사항:
- OUTER JOIN 쿼리에 DefaultIfEmpty를 사용하는 패턴은 Entity SQL의 간단한 OUTER JOIN 문보다 더 복잡한 쿼리를 생성합니다.
- 일반적인 패턴 일치에는 LIKE를 사용할 수 없습니다.
6.2 추적 LINQ to Entities 쿼리 없음
컨텍스트가 ObjectContext를 파생하는 경우:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
컨텍스트가 DbContext를 파생하는 경우:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
장점
- 일반 LINQ 쿼리에 비해 성능이 향상되었습니다.
- 완전히 구체화된 개체입니다.
- 프로그래밍 언어에 기본 제공되는 구문을 사용하여 작성하는 것이 가장 간단합니다.
단점
- CUD 작업에 적합하지 않습니다.
- 다음과 같은 특정 기술 제한 사항:
- OUTER JOIN 쿼리에 DefaultIfEmpty를 사용하는 패턴은 Entity SQL의 간단한 OUTER JOIN 문보다 더 복잡한 쿼리를 생성합니다.
- 일반적인 패턴 일치에는 LIKE를 사용할 수 없습니다.
NoTracking이 지정되지 않은 경우에도 프로젝트 스칼라 속성에 대한 쿼리는 추적되지 않습니다. 예시:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
이 특정 쿼리는 NoTracking을 명시적으로 지정하지 않지만 개체 상태 관리자에게 알려진 형식을 구체화하지 않으므로 구체화된 결과가 추적되지 않습니다.
6.3 ObjectQuery를 통해 Entity SQL
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
장점
- CUD 작업에 적합합니다.
- 완전히 구체화된 개체입니다.
- 쿼리 계획 캐싱을 지원합니다.
단점
- 언어에 기본 제공되는 쿼리 구문보다 사용자 오류가 발생하기 쉬운 텍스트 쿼리 문자열을 포함합니다.
6.4 엔터티 명령을 통해 엔터티 SQL
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
장점
- .NET 4.0에서 쿼리 계획 캐싱을 지원합니다(계획 캐싱은 .NET 4.5의 다른 모든 쿼리 형식에서 지원됨).
단점
- 언어에 기본 제공되는 쿼리 구문보다 사용자 오류가 발생하기 쉬운 텍스트 쿼리 문자열을 포함합니다.
- CUD 작업에 적합하지 않습니다.
- 결과는 자동으로 구체화되지 않으며 데이터 판독기에서 읽어야 합니다.
6.5 SqlQuery 및 ExecuteStoreQuery
데이터베이스의 SqlQuery:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
DbSet의 SqlQuery:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
장점
- 계획 컴파일러가 무시되므로 일반적으로 가장 빠른 성능입니다.
- 완전히 구체화된 개체입니다.
- DbSet에서 사용할 때 CUD 작업에 적합합니다.
단점
- 쿼리는 텍스트이며 오류가 발생하기 쉽습니다.
- 쿼리는 개념적 의미 체계 대신 저장소 의미 체계를 사용하여 특정 백 엔드에 연결됩니다.
- 상속이 있는 경우 수공예 쿼리는 요청된 형식에 대한 매핑 조건을 고려해야 합니다.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
장점
- 일반 LINQ 쿼리보다 성능이 최대 7% 향상됩니다.
- 완전히 구체화된 개체입니다.
- CUD 작업에 적합합니다.
단점
- 복잡성 및 프로그래밍 오버헤드가 증가했습니다.
- 컴파일된 쿼리를 기반으로 작성할 때 성능 향상이 손실됩니다.
- 일부 LINQ 쿼리는 CompiledQuery로 작성할 수 없습니다(예: 익명 형식의 프로젝션).
6.7 다양한 쿼리 옵션의 성능 비교
컨텍스트 생성 시간이 초과되지 않은 간단한 마이크로벤치마크가 테스트에 적용되었습니다. 제어된 환경에서 캐시되지 않은 엔터티 집합에 대한 쿼리를 5000회 측정했습니다. 이러한 숫자는 경고와 함께 사용해야 합니다. 즉, 애플리케이션에서 생성된 실제 숫자를 반영하지는 않지만, 새 컨텍스트를 만드는 비용을 제외하고 다른 쿼리 옵션을 나란히 비교할 때 성능 차이의 양을 매우 정확하게 측정합니다.
| EF | 테스트 | 시간(밀리초) | 메모리 |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | ObjectContext Linq 쿼리 | 2692 | 38277120 |
| EF5 | DbContext Linq 쿼리 추적 없음 | 2818 | 41840640 |
| EF5 | DbContext Linq 쿼리 | 2930 | 41771008 |
| EF5 | ObjectContext Linq 쿼리 추적 없음 | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | ObjectContext Linq 쿼리 | 3074 | 45248512 |
| EF6 | DbContext Linq 쿼리 추적 없음 | 3125 | 47575040 |
| EF6 | DbContext Linq 쿼리 | 3420 | 47652864 |
| EF6 | ObjectContext Linq 쿼리 추적 없음 | 3593 | 45260800 |
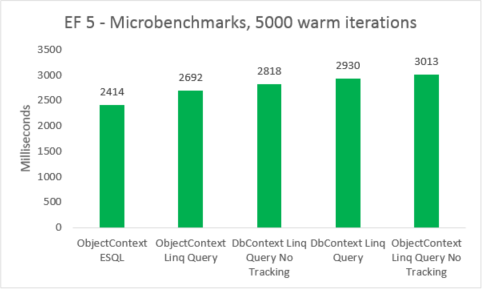
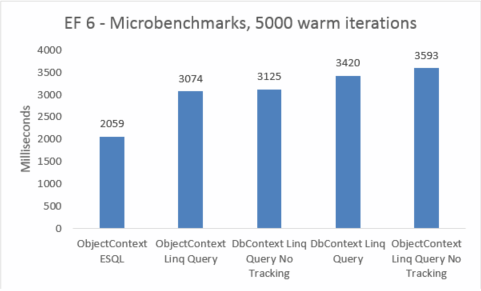
마이크로벤치마크는 코드의 작은 변경 내용에 매우 민감합니다. 이 경우 Entity Framework 5와 Entity Framework 6의 비용 간의 차이는 가로채기 및 트랜잭션 개선이 추가되기 때문입니다. 그러나 이러한 마이크로벤치마크 숫자는 Entity Framework가 수행하는 작업의 매우 작은 조각으로 증폭된 비전입니다. 웜 쿼리의 실제 시나리오는 Entity Framework 5에서 Entity Framework 6으로 업그레이드할 때 성능 회귀를 볼 수 없습니다.
다양한 쿼리 옵션의 실제 성능을 비교하기 위해 다른 쿼리 옵션을 사용하여 범주 이름이 "음료"인 모든 제품을 선택하는 5개의 개별 테스트 변형을 만들었습니다. 각 반복에는 컨텍스트를 만드는 비용과 반환된 모든 엔터티를 구체화하는 비용이 포함됩니다. 1000회 반복의 합계를 가져오기 전에 10번의 반복이 시간 초과 없이 실행됩니다. 표시된 결과는 각 테스트의 5개 실행에서 가져온 중앙값 실행입니다. 자세한 내용은 테스트 코드를 포함하는 부록 B를 참조하세요.
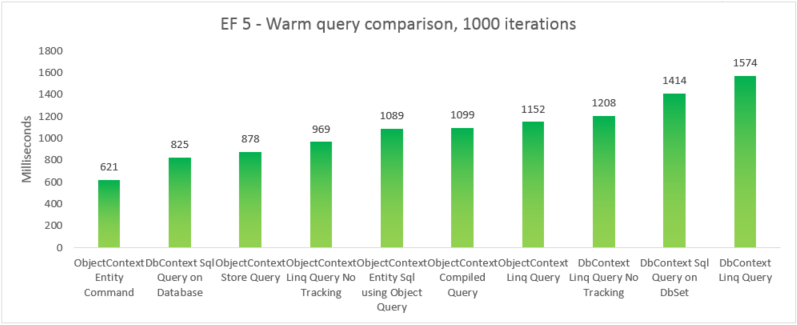
| EF | 테스트 | 시간(밀리초) | 메모리 |
|---|---|---|---|
| EF5 | ObjectContext 엔터티 명령 | 621 | 39350272 |
| EF5 | 데이터베이스의 DbContext Sql 쿼리 | 825 | 37519360 |
| EF5 | ObjectContext 저장소 쿼리 | 878 | 39460864 |
| EF5 | ObjectContext Linq 쿼리 추적 없음 | 969 | 38293504 |
| EF5 | 개체 쿼리를 사용하는 ObjectContext Entity Sql | 1089 | 38981632 |
| EF5 | ObjectContext 컴파일된 쿼리 | 1099 | 38682624 |
| EF5 | ObjectContext Linq 쿼리 | 1,152 | 38178816 |
| EF5 | DbContext Linq 쿼리 추적 없음 | 1208 | 41803776 |
| EF5 | DbSet의 DbContext Sql 쿼리 | 1414 | 37982208 |
| EF5 | DbContext Linq 쿼리 | 1574 | 41738240 |
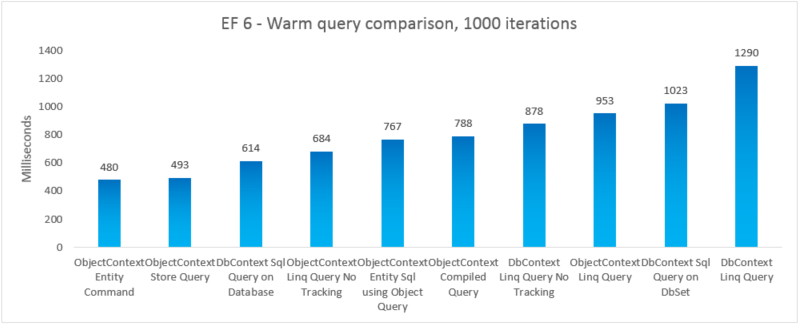
| EF6 | ObjectContext 엔터티 명령 | 480 | 47247360 |
| EF6 | ObjectContext 저장소 쿼리 | 493 | 46739456 |
| EF6 | 데이터베이스의 DbContext Sql 쿼리 | 614 | 41607168 |
| EF6 | ObjectContext Linq 쿼리 추적 없음 | 684 | 46333952 |
| EF6 | 개체 쿼리를 사용하는 ObjectContext Entity Sql | 767 | 48865280 |
| EF6 | ObjectContext 컴파일된 쿼리 | 788 | 48467968 |
| EF6 | DbContext Linq 쿼리 추적 없음 | 878 | 47554560 |
| EF6 | ObjectContext Linq 쿼리 | 953 | 47632384 |
| EF6 | DbSet의 DbContext Sql 쿼리 | 1023 | 41992192 |
| EF6 | DbContext Linq 쿼리 | 1290 | 47529984 |
참고 항목
완전성을 위해 EntityCommand에서 Entity SQL 쿼리를 실행하는 변형을 포함했습니다. 그러나 이러한 쿼리에 대한 결과가 구체화되지 않으므로 비교가 반드시 사과와 사과가 되는 것은 아닙니다. 테스트에는 비교를 더 공정하게 만들기 위해 구체화에 대한 근사값이 포함됩니다.
이 엔드투엔드 사례에서 Entity Framework 6은 훨씬 더 가벼운 DbContext 초기화 및 더 빠른 MetadataCollection<T> 조회를 포함하여 스택의 여러 부분에서 향상된 성능 덕분에 Entity Framework 5를 능가합니다.
7 디자인 타임 성능 고려 사항
7.1 상속 전략
Entity Framework를 사용할 때 또 다른 성능 고려 사항은 사용하는 상속 전략입니다. Entity Framework는 3가지 기본 유형의 상속 및 해당 조합을 지원합니다.
- TPH(계층당 하나의 테이블) - 각 상속 집합이 판별자 열이 있는 테이블에 매핑되어 행에 표시되는 계층의 특정 형식을 나타냅니다.
- TPT(형식당 하나의 테이블) - 각 형식에 데이터베이스에 자체 테이블이 있는 경우 자식 테이블은 부모 테이블에 포함되지 않은 열만 정의합니다.
- TPC(클래스당 하나의 테이블) - 각 형식에 데이터베이스에 자체 전체 테이블이 있는 경우 자식 테이블은 부모 형식에 정의된 필드를 포함하여 모든 필드를 정의합니다.
모델에서 TPT 상속을 사용하는 경우 생성되는 쿼리는 다른 상속 전략으로 생성된 쿼리보다 더 복잡하므로 저장소에서 실행 시간이 길어질 수 있습니다. 일반적으로 TPT 모델을 통해 쿼리를 생성하고 결과 개체를 구체화하는 데 시간이 오래 걸립니다.
MSDN 블로그 게시물인 "Entity Framework에서 TPT(형식당 하나의 테이블) 상속을 사용할 때의 성능 고려 사항" 블로그 게시물을 참조하세요(<https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>).
7.1.1 Model First 또는 Code First 애플리케이션에서 TPT 방지
TPT 스키마가 있는 기존 데이터베이스를 통해 모델을 만들 때 많은 옵션이 없습니다. 그러나 Model First 또는 Code First를 사용하여 애플리케이션을 만들 때 성능 문제에 대한 TPT 상속을 피해야 합니다.
엔터티 디자이너 마법사에서 모델 우선을 사용하는 경우 모델의 상속에 대한 TPT를 받게 됩니다. Model First를 사용하여 TPH 상속 전략으로 전환하려는 경우 Visual Studio 갤러리(<http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>)에서 사용할 수 있는 "엔터티 디자이너 데이터베이스 생성 파워 팩"을 사용할 수 있습니다.
Code First를 사용하여 상속이 있는 모델의 매핑을 구성하는 경우 EF는 기본적으로 TPH를 사용하므로 상속 계층 구조의 모든 엔터티는 동일한 테이블에 매핑됩니다. 자세한 내용은 MSDN Magazine(http://msdn.microsoft.com/magazine/hh126815.aspx)의 "Entity Framework 4.1의 Code First" 문서의 "Fluent API를 사용하여 매핑" 섹션을 참조하세요.
7.2 모델 생성 시간을 개선하기 위해 EF4에서 업그레이드
모델의 SSDL(저장소 계층)을 생성하는 알고리즘에 대한 SQL Server 특정 개선 사항은 Entity Framework 5 및 6에서 사용할 수 있으며 Visual Studio 2010 SP1이 설치될 때 Entity Framework 4에 대한 업데이트로 사용할 수 있습니다. 다음 테스트 결과는 매우 큰 모델(이 경우 Navision 모델)을 생성할 때 향상된 기능을 보여 줍니다. 자세한 내용은 부록 C를 참조하세요.
모델에는 1005개의 엔터티 집합과 4227개의 연결 집합이 포함됩니다.
| 구성 | 소요된 시간 분석 |
|---|---|
| Visual Studio 2010, Entity Framework 4 | SSDL 생성: 2시간 27분 매핑 생성: 1초 CSDL 생성: 1초 ObjectLayer 생성: 1초 뷰 생성: 2시간 14분 |
| Visual Studio 2010 SP1, Entity Framework 4 | SSDL 생성: 1초 매핑 생성: 1초 CSDL 생성: 1초 ObjectLayer 생성: 1초 뷰 생성: 1시간 53분 |
| Visual Studio 2013, Entity Framework 5 | SSDL 생성: 1초 매핑 생성: 1초 CSDL 생성: 1초 ObjectLayer 생성: 1초 뷰 생성: 65분 |
| Visual Studio 2013, Entity Framework 6 | SSDL 생성: 1초 매핑 생성: 1초 CSDL 생성: 1초 ObjectLayer 생성: 1초 뷰 생성: 28초. |
SSDL을 생성할 때 클라이언트 개발 컴퓨터가 서버에서 결과를 다시 가져오기 위해 유휴 상태로 대기하는 동안 부하가 거의 전적으로 SQL Server 소비됩니다. DBA는 특히 이러한 개선에 감사해야 합니다. 또한 기본적으로 모델 생성의 전체 비용은 지금 뷰 생성에서 발생한다는 사실에 주목하는 것이 좋습니다.
7.3 데이터베이스 우선 및 모델 우선을 사용하여 큰 모델 분할
모델 크기가 증가하면 디자이너 표면이 복잡해지고 사용하기가 어려워집니다. 일반적으로 300개 이상의 엔터티가 있는 모델이 너무 커서 디자이너를 효과적으로 사용할 수 없는 것으로 간주합니다. 다음 블로그 게시물에서는 큰 모델을 분할하기 위한 몇 가지 옵션에 대해 설명합니다(<https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>).
이 게시물은 첫 번째 버전의 Entity Framework용으로 작성되었지만 단계는 여전히 적용됩니다.
7.4 엔터티 데이터 원본 제어를 사용하는 성능 고려 사항
EntityDataSource 컨트롤을 사용하는 웹 애플리케이션의 성능이 크게 저하되는 다중 스레드 성능 및 스트레스 테스트의 사례를 살펴보았습니다. 근본 원인은 EntityDataSource가 웹 애플리케이션에서 참조하는 어셈블리에서 MetadataWorkspace.LoadFromAssembly를 반복적으로 호출하여 엔터티로 사용할 형식을 검색하기 위한 것입니다.
해결 방법은 EntityDataSource의 ContextTypeName을 파생 ObjectContext 클래스의 형식 이름으로 설정하는 것입니다. 이렇게 하면 참조된 모든 어셈블리에서 엔터티 형식을 검사하는 메커니즘이 해제됩니다.
ContextTypeName 필드를 설정하면 리플렉션을 통해 어셈블리에서 형식을 로드할 수 없는 경우 .NET 4.0의 EntityDataSource가 ReflectionTypeLoadException을 throw하는 기능 문제도 방지됩니다. 이 문제는 NET 4.5에서 해결되었습니다.
7.5 POCO 엔터티 및 변경 내용 추적 프록시
에서는 사용자 지정 데이터 클래스 자체를 수정하지 않고도 데이터 모델과 함께 사용할 수 있습니다. 즉, 기존 도메인 개체 등의 POCO(Plain Old CLR Object)를 데이터 모델과 함께 사용할 수 있습니다. 데이터 모델에 정의된 엔터티에 매핑되는 이러한 POCO 데이터 클래스(지속성 무시 개체라고도 함)는 도구에서 생성된 엔터티 형식과 동일한 쿼리, 삽입, 업데이트 및 삭제 동작을 대부분 지원합니다.
Entity Framework는 POCO 엔터티에서 지연 로드 및 자동 변경 내용 추적과 같은 기능을 사용하도록 설정할 때 사용되는 POCO 형식에서 파생된 프록시 클래스를 만들 수도 있습니다. POCO 클래스는 여기에 설명된 대로 엔터티 프레임워크가 프록시를 사용할 수 있도록 특정 요구 사항을 충족해야 합니다(http://msdn.microsoft.com/library/dd468057.aspx).
확률 추적 프록시는 엔터티의 속성 값이 변경될 때마다 개체 상태 관리자에게 알리므로 Entity Framework는 항상 엔터티의 실제 상태를 알 수 있습니다. 이 작업은 속성의 setter 메서드 본문에 알림 이벤트를 추가하고 개체 상태 관리자가 이러한 이벤트를 처리하도록 하여 수행됩니다. 일반적으로 프록시 엔터티를 만드는 것은 Entity Framework에서 만든 이벤트 집합이 추가되어 프록시가 아닌 POCO 엔터티를 만드는 것보다 비용이 많이 듭니다.
POCO 엔터티에 변경 내용 추적 프록시가 없는 경우 엔터티의 내용을 이전 저장된 상태의 복사본과 비교하여 변경 내용을 찾을 수 있습니다. 이 심층 비교는 컨텍스트에 엔터티가 많거나 엔터티에 매우 많은 양의 속성이 있는 경우, 마지막 비교 이후 변경된 속성이 없는 경우에도 긴 프로세스가 됩니다.
요약하자면, 변경 내용 추적 프록시를 만들 때 성능이 저하되지만, 변경 내용 추적은 엔터티에 속성이 많거나 모델에 엔터티가 많은 경우 변경 검색 프로세스를 가속화하는 데 도움이 됩니다. 엔터티 양이 너무 많이 증가하지 않는 속성 수가 적은 엔터티의 경우 변경 내용 추적 프록시가 있으면 큰 이점이 없을 수 있습니다.
8 관련 엔터티 로드
8.1 지연 로드 대 즉시 로드
Entity Framework는 대상 엔터티와 관련된 엔터티를 로드하는 여러 가지 방법을 제공합니다. 예를 들어 제품을 쿼리할 때 관련 주문이 개체 상태 관리자에 로드되는 다양한 방법이 있습니다. 성능 관점에서 관련 엔터티를 로드할 때 고려해야 할 가장 큰 문제는 지연 로드 또는 즉시 로드를 사용할지 여부입니다.
Eager Loading을 사용하는 경우 관련 엔터티가 대상 엔터티 집합과 함께 로드됩니다. 쿼리에서 Include 문을 사용하여 가져올 관련 엔터티를 나타냅니다.
지연 로드를 사용하는 경우 초기 쿼리는 대상 엔터티 집합만 가져옵니다. 그러나 탐색 속성에 액세스할 때마다 관련 엔터티를 로드하기 위해 저장소에 대해 다른 쿼리가 실행됩니다.
엔터티가 로드되면 지연 로드 또는 즉시 로드를 사용하든 관계없이 엔터티에 대한 추가 쿼리가 개체 상태 관리자에서 직접 로드됩니다.
8.2 지연 로드와 즉시 로드 중에서 선택하는 방법
중요한 점은 지연 로드와 즉시 로드의 차이점을 이해하여 애플리케이션에 대해 올바른 선택을 할 수 있다는 것입니다. 이렇게 하면 데이터베이스에 대한 여러 요청과 큰 페이로드를 포함할 수 있는 단일 요청 간의 절충을 평가하는 데 도움이 됩니다. 애플리케이션의 일부 부분에서 즉시 로드하고 다른 부분에서 지연 로드를 사용하는 것이 적절할 수 있습니다.
내부적으로 발생하는 일의 예로 영국에 거주하는 고객과 주문 횟수를 쿼리한다고 가정합니다.
즉시 로드 사용
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
지연 로드 사용
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
즉시 로드를 사용하는 경우 모든 고객과 모든 주문을 반환하는 단일 쿼리를 실행합니다. store 명령은 다음과 같습니다.
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
지연 로드를 사용하는 경우 처음에 다음 쿼리를 실행합니다.
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
그리고 고객의 Orders 탐색 속성에 액세스할 때마다 다음과 같은 다른 쿼리가 저장소에 대해 발급됩니다.
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
자세한 내용은 관련 개체 로드를 참조하세요.
8.2.1 지연 로드와 즉시 로드 치트 시트 비교
즉시 로드와 지연 로드를 선택하는 데는 하나의 크기에 맞는 것은 없습니다. 먼저 두 전략 간의 차이점을 이해하여 정보에 입각한 결정을 내릴 수 있습니다. 또한 코드가 다음 시나리오에 적합한지 고려합니다.
| 시나리오 | 제안 사항 |
|---|---|
| 페치된 엔터티에서 많은 탐색 속성에 액세스해야 합니까? | 아니요 - 두 옵션 모두 아마 그렇게 할 것입니다. 그러나 쿼리가 가져오는 페이로드가 너무 크지 않은 경우 개체를 구체화하는 데 네트워크 왕복이 적기 때문에 즉시 로드를 사용하면 성능상의 이점이 발생할 수 있습니다. 예 - 엔터티에서 많은 탐색 속성에 액세스해야 하는 경우 Eager 로드를 사용하여 쿼리에 여러 include 문을 사용하여 이 작업을 수행합니다. 엔터티가 많을수록 쿼리가 반환하는 페이로드가 커지게 됩니다. 쿼리에 세 개 이상의 엔터티를 포함하면 지연 로드로 전환하는 것이 좋습니다. |
| 런타임에 필요한 데이터를 정확히 알고 있나요? | 아니요 - 지연 로드가 더 좋습니다. 그렇지 않으면 필요하지 않은 데이터를 쿼리하게 될 수 있습니다. 예 - 즉시 로드하는 것이 가장 좋은 선택일 것입니다. 전체 집합을 더 빠르게 로드하는 데 도움이 됩니다. 쿼리에서 매우 많은 양의 데이터를 가져와야 하는 경우 이 속도가 너무 느려지면 지연 로드를 대신 시도합니다. |
| 코드가 데이터베이스에서 멀리 실행되고 있나요? (네트워크 대기 시간 증가) | 아니요 - 네트워크 대기 시간이 문제가 되지 않는 경우 지연 로드를 사용하면 코드가 간소화됩니다. 애플리케이션의 토폴로지 변경될 수 있으므로 데이터베이스 근접성을 당연하게 여기지 마세요. 예 - 네트워크가 문제인 경우 시나리오에 더 적합한 항목을 결정할 수 있습니다. 왕복이 더 적게 필요하기 때문에 일반적으로 즉시 로드하는 것이 더 좋습니다. |
8.2.2 여러 포함의 성능 문제
서버 응답 시간 문제와 관련된 성능 질문이 들리면 문제의 원본은 여러 Include 문이 있는 쿼리가 자주 발생합니다. 쿼리에 관련 엔터티를 포함하는 것은 강력하지만, 중요한 내용은 이해해야 합니다.
여러 Include 문이 포함된 쿼리가 내부 계획 컴파일러를 통해 store 명령을 생성하는 데 비교적 오랜 시간이 걸립니다. 이 시간의 대부분은 결과 쿼리를 최적화하는 데 소요됩니다. 생성된 store 명령에는 매핑에 따라 각 Include에 대한 외부 조인 또는 공용 구조체가 포함됩니다. 이와 같은 쿼리는 데이터베이스에서 연결된 큰 그래프를 단일 페이로드로 가져오며, 특히 페이로드에 중복성이 많은 경우(예: 일대다 방향으로 연결을 트래버스하는 데 여러 수준의 Include를 사용하는 경우) 대역폭 문제가 발생합니다.
ToTraceString을 사용하고 SQL Server Management Studio store 명령을 실행하여 쿼리에 대한 기본 TSQL에 액세스하여 쿼리가 지나치게 큰 페이로드를 반환하는 경우를 확인할 수 있습니다. 이러한 경우 쿼리에서 Include 문의 수를 줄여 필요한 데이터만 가져올 수 있습니다. 또는 쿼리를 더 작은 하위 쿼리 시퀀스로 분할할 수 있습니다. 예를 들면 다음과 같습니다.
쿼리를 중단하기 전:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
쿼리를 중단한 후:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
컨텍스트에서 ID 확인 및 연결 수정을 자동으로 수행해야 하는 기능을 사용하므로 추적된 쿼리에서만 작동합니다.
지연 로드와 마찬가지로 더 작은 페이로드에 대한 더 많은 쿼리가 절충됩니다. 개별 속성의 프로젝션을 사용하여 각 엔터티에서 필요한 데이터만 명시적으로 선택할 수도 있지만 이 경우 엔터티를 로드하지 않으며 업데이트가 지원되지 않습니다.
8.2.3 속성 지연 로드를 가져오는 해결 방법
Entity Framework는 현재 스칼라 또는 복합 속성의 지연 로드를 지원하지 않습니다. 그러나 BLOB과 같은 큰 개체를 포함하는 테이블이 있는 경우 테이블 분할을 사용하여 큰 속성을 별도의 엔터티로 구분할 수 있습니다. 예를 들어 varbinary 사진 열이 포함된 Product 테이블이 있다고 가정합니다. 쿼리에서 이 속성에 자주 액세스할 필요가 없는 경우 테이블 분할을 사용하여 일반적으로 필요한 엔터티 부분만 가져올 수 있습니다. 제품 사진을 나타내는 엔터티는 명시적으로 필요한 경우에만 로드됩니다.
Gil Fink의 "Entity Framework의 테이블 분할" 블로그 게시물은 테이블 분할을 사용하도록 설정하는 방법을 보여 주는 좋은 리소스입니다(<http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>).
9 기타 고려 사항
9.1 서버 가비지 수집
일부 사용자는 가비지 수집기가 제대로 구성되지 않은 경우 예상되는 병렬 처리를 제한하는 리소스 경합을 경험할 수 있습니다. 다중 스레드 시나리오 또는 서버 쪽 시스템과 유사한 애플리케이션에서 EF를 사용할 때마다 서버 가비지 수집을 사용하도록 설정해야 합니다. 이 작업은 애플리케이션 구성 파일의 간단한 설정을 통해 수행됩니다.
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
이렇게 하면 스레드 경합이 줄어들고 CPU 포화 시나리오에서 처리량이 최대 30%까지 증가합니다. 일반적으로 클래식 가비지 수집(UI 및 클라이언트 쪽 시나리오에 대해 더 잘 조정됨)과 서버 가비지 수집을 사용하여 애플리케이션이 어떻게 작동하는지 항상 테스트해야 합니다.
9.2 AutoDetectChanges
앞에서 설명한 것처럼 개체 캐시에 많은 엔터티가 있는 경우 Entity Framework에 성능 문제가 표시될 수 있습니다. Add, Remove, Find, Entry 및 SaveChanges와 같은 특정 작업은 개체 캐시의 크기를 기준으로 많은 양의 CPU를 사용할 수 있는 DetectChanges에 대한 호출을 트리거합니다. 그 이유는 개체 캐시와 개체 상태 관리자가 컨텍스트에 수행된 각 작업에서 가능한 한 동기화된 상태를 유지하려고 시도하여 생성된 데이터가 다양한 시나리오에서 올바른지 확인하기 때문입니다.
일반적으로 애플리케이션의 전체 수명 동안 Entity Framework의 자동 변경 검색을 사용하도록 설정하는 것이 좋습니다. 시나리오가 높은 CPU 사용량으로 인해 부정적인 영향을 받고 있고 프로필에서 원인은 DetectChanges 호출임을 나타내는 경우 코드의 중요한 부분에서 AutoDetectChanges를 일시적으로 해제하는 것이 좋습니다.
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
AutoDetectChanges를 해제하기 전에 Entity Framework가 엔터티에서 발생하는 변경 내용에 대한 특정 정보를 추적하는 기능을 상실할 수 있음을 이해하는 것이 좋습니다. 잘못 처리되면 애플리케이션에서 데이터 불일치가 발생할 수 있습니다. AutoDetectChanges를 해제하는 방법에 대한 자세한 내용은 <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>를 참조하세요.
9.3 요청당 컨텍스트
Entity Framework의 컨텍스트는 최적 성능 환경을 제공하기 위해 수명이 짧은 인스턴스로 사용됩니다. 컨텍스트는 수명이 짧고 삭제될 것으로 예상되며, 가능하면 매우 가볍고 메타데이터를 다시 사용하도록 구현되었습니다. 웹 시나리오에서는 이를 염두에 두고 단일 요청 기간 이상 컨텍스트가 없는 것이 중요합니다. 마찬가지로 웹이 아닌 시나리오에서는 Entity Framework의 다양한 캐싱 수준에 대한 이해에 따라 컨텍스트를 삭제해야 합니다. 일반적으로 애플리케이션의 수명 동안 컨텍스트 인스턴스와 스레드 및 정적 컨텍스트당 컨텍스트를 사용하지 않아야 합니다.
9.4 데이터베이스 null 의미 체계
Entity Framework는 기본적으로 C# null 비교 의미 체계가 있는 SQL 코드를 생성합니다. 다음 예제 쿼리를 살펴보세요.
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
이 예제에서는 여러 nullable 변수를 SupplierID 및 UnitPrice와 같은 엔터티의 nullable 속성과 비교합니다. 이 쿼리에 대해 생성된 SQL은 매개 변수 값이 열 값과 같은지 또는 매개 변수와 열 값이 모두 null인지 묻습니다. 이렇게 하면 데이터베이스 서버가 null을 처리하는 방식이 숨겨지고 여러 데이터베이스 공급업체에서 일관된 C# null 환경을 제공합니다. 반면에 생성된 코드는 약간 어수선하며 쿼리의 where 문에서 비교의 양이 큰 수로 증가할 때 잘 수행되지 않을 수 있습니다.
이 상황을 처리하는 한 가지 방법은 데이터베이스 null 의미 체계를 사용하는 것입니다. 이제 Entity Framework는 데이터베이스 엔진이 null 값을 처리하는 방식을 노출하는 더 간단한 SQL을 생성하므로 C# null 의미 체계와 다르게 동작할 수 있습니다. 컨텍스트 구성에 대해 하나의 단일 구성 줄로 컨텍스트별로 데이터베이스 null 의미 체계를 활성화할 수 있습니다.
context.Configuration.UseDatabaseNullSemantics = true;
중소 규모의 쿼리는 데이터베이스 null 의미 체계를 사용할 때 인식할 수 있는 성능 향상을 표시하지 않지만 잠재적인 null 비교가 많은 쿼리에서 차이가 더 두드러집니다.
위의 예제 쿼리에서 성능 차이는 제어된 환경에서 실행되는 마이크로벤치마크에서 2% 미만이었습니다.
9.5 비동기
Entity Framework 6에서는 .NET 4.5 이상에서 실행할 때 비동기 작업을 지원합니다. 대부분의 경우 IO 관련 경합이 있는 애플리케이션은 비동기 쿼리 및 저장 작업을 사용하여 가장 많은 이점을 얻을 수 있습니다. 애플리케이션에 IO 경합이 발생하지 않는 경우 비동기 사용은 최상의 경우 동기식으로 실행되고 동기 호출과 동일한 시간 동안 결과를 반환하거나 최악의 경우 단순히 비동기 작업으로 실행을 연기하고 시나리오 완료에 추가 시간을 추가합니다.
비동기 프로그래밍이 애플리케이션의 성능을 향상시킬지 여부를 결정하는 데 도움이 되는 비동기 프로그래밍이 작동하는 방법에 대한 자세한 내용은 Async 및 Await를 사용한 비동기 프로그래밍을 참조하세요. Entity Framework에서 비동기 작업을 사용하는 방법에 대한 자세한 내용은 비동기 쿼리 및 저장을 참조하세요.
9.6 NGEN
Entity Framework 6은 .NET Framework의 기본 설치에 제공되지 않습니다. 따라서 Entity Framework 어셈블리는 기본적으로 NGEN이 아니므로 모든 Entity Framework 코드에는 다른 MSIL 어셈블리와 동일한 JIT'ing 비용이 적용됩니다. 이렇게 하면 개발 중에 F5 환경이 저하되고 프로덕션 환경에서 애플리케이션이 콜드 시작될 수도 있습니다. JIT'ing의 CPU 및 메모리 비용을 줄이기 위해 엔터티 프레임워크 이미지를 적절하게 NGEN하는 것이 좋습니다. NGEN을 사용하여 Entity Framework 6의 시작 성능을 개선하는 방법에 대한 자세한 내용은 NGen을 사용하여 시작 성능 향상을 참조하세요.
9.7 Code First 및 EDMX
Entity Framework는 개념적 모델(개체), 스토리지 스키마(데이터베이스) 및 둘 사이의 매핑을 메모리 내 표현으로 표시하여 개체 지향 프로그래밍과 관계형 데이터베이스 간의 임피던스 불일치 문제를 발생시키는 이유를 설명합니다. 이 메타데이터를 엔터티 데이터 모델 또는 짧은 EDM이라고 합니다. 이 EDM에서 Entity Framework는 메모리의 개체에서 데이터베이스로 데이터를 왕복하는 뷰를 파생합니다.
Entity Framework를 개념적 모델, 스토리지 스키마 및 매핑을 공식적으로 지정하는 EDMX 파일과 함께 사용하는 경우 모델 로드 단계에서는 EDM이 올바른지(예: 매핑이 누락되지 않았는지 확인) 뷰를 생성한 다음, 뷰의 유효성을 검사하고 이 메타데이터를 사용할 준비가 되었는지 확인해야 합니다. 그런 다음에만 쿼리를 실행하거나 새 데이터를 데이터 저장소에 저장할 수 있습니다.
Code First 접근 방식은 핵심적인 정교한 엔터티 데이터 모델 생성기입니다. Entity Framework는 제공된 코드에서 EDM을 생성해야 합니다. 이렇게 하려면 모델과 관련된 클래스를 분석하고, 규칙을 적용하고, Fluent API를 통해 모델을 구성합니다. EDM이 빌드된 후 Entity Framework는 기본적으로 프로젝트에 EDMX 파일이 있는 것과 동일한 방식으로 작동합니다. 따라서 Code First에서 모델을 빌드하면 EDMX가 있는 것과 비교할 때 Entity Framework의 시작 시간이 느려지는 복잡성이 추가됩니다. 비용은 빌드 중인 모델의 크기와 복잡성에 완전히 따라 달라집니다.
EDMX와 Code First를 사용하도록 선택하는 경우 Code First에서 도입된 유연성으로 인해 처음으로 모델을 빌드하는 비용이 증가한다는 것을 알아야 합니다. 애플리케이션이 이 처음 로드 비용을 견딜 수 있는 경우 일반적으로 Code First가 선호하는 방법이 됩니다.
10 성능 조사
10.1 Visual Studio Profiler 사용
Entity Framework에 성능 문제가 있는 경우 Visual Studio에 기본 제공된 프로파일러와 같은 프로파일러를 사용하여 애플리케이션이 시간을 소비하는 위치를 확인할 수 있습니다. 이 도구는 "ADO.NET Entity Framework의 성능 탐색 - 1부" 블로그 게시물(<https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>)에서 원형 차트를 생성하는 데 사용한 도구로, Entity Framework가 춥고 따뜻한 쿼리 중에 시간을 보내는 위치를 보여 줍니다.
데이터 및 모델링 고객 자문 팀에서 작성한 "Visual Studio 2010 Profiler를 사용한 프로파일링 엔터티 프레임워크" 블로그 게시물은 프로파일러를 사용하여 성능 문제를 조사하는 방법에 대한 실제 예제를 보여줍니다. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. 이 게시물은 Windows 애플리케이션용으로 작성되었습니다. 웹 애플리케이션을 프로파일러해야 하는 경우 WPR(Windows Performance Recorder) 및 WPA(Windows 성능 분석기) 도구가 Visual Studio에서 작업하는 것보다 더 잘 작동할 수 있습니다. WPR 및 WPA는 Windows 평가 및 배포 키트에 포함된 Windows Performance Toolkit의 일부입니다.
10.2 애플리케이션/데이터베이스 프로파일링
Visual Studio에 기본 제공되는 프로파일러와 같은 도구는 애플리케이션이 시간을 소비하는 위치를 알려줍니다. 요구 사항에 따라 프로덕션 또는 사전 프로덕션에서 실행 중인 애플리케이션의 동적 분석을 수행하고 데이터베이스 액세스의 일반적인 문제 및 안티 패턴을 찾는 또 다른 유형의 프로파일러를 사용할 수 있습니다.
상용 프로파일러 2개는 Entity Framework Profiler(<http://efprof.com>) 및 ORMProfiler(<http://ormprofiler.com>)입니다.
애플리케이션이 Code First를 사용하는 MVC 애플리케이션인 경우 StackExchange의 MiniProfiler를 사용할 수 있습니다. Scott Hanselman은 블로그에서 이 도구에 대해 설명합니다(<http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>).
애플리케이션의 데이터베이스 활동을 프로파일링하는 방법에 대한 자세한 내용은 Entity Framework의 프로파일링 데이터베이스 활동이라는 Julie Lerman의 MSDN Magazine 문서를 참조하세요.
10.3 데이터베이스 로거
Entity Framework 6을 사용하는 경우 기본 제공 로깅 기능도 사용하는 것이 좋습니다. 컨텍스트의 Database 속성은 간단한 한 줄 구성을 통해 해당 작업을 기록하도록 지시할 수 있습니다.
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
이 예제에서는 데이터베이스 활동이 콘솔에 기록되지만 Log 속성은 모든 작업<문자열> 대리자를 호출하도록 구성할 수 있습니다.
다시 컴파일하지 않고 데이터베이스 로깅을 사용하도록 설정하려는 경우 Entity Framework 6.1 이상을 사용하는 경우 애플리케이션의 web.config 또는 app.config 파일에 인터셉터를 추가하여 이 작업을 수행할 수 있습니다.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
다시 컴파일하지 않고 로깅을 추가하는 방법에 대한 자세한 내용은 <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>으로 이동합니다.
11 부록
11.1 A. 테스트 환경
이 환경에서는 클라이언트 애플리케이션과 별도의 컴퓨터에서 데이터베이스와 함께 컴퓨터 2대 설정을 사용합니다. 컴퓨터가 동일한 랙에 있으므로 네트워크 대기 시간은 비교적 낮지만 단일 머신 환경보다 더 현실적입니다.
11.1.1 App Server
11.1.1.1 소프트웨어 환경
- Entity Framework 4 소프트웨어 환경
- OS 이름: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 – Ultimate.
- Visual Studio 2010 SP1(일부 비교에만 해당).
- Entity Framework 5 및 6 소프트웨어 환경
- OS 이름: Windows 8.1 Enterprise
- Visual Studio 2013 – Ultimate.
11.1.1.2 하드웨어 환경
- 듀얼 프로세서: Intel(R) Xeon(R) CPU L5520 W3530 @ 2.27GHz, 2261Mhz8GHz, 4코어, 논리 프로세서 84개.
- 2412GB RamRAM.
- 4개의 파티션으로 분할된 136GB SCSI250GB SATA 7200rpm 3GB/s 드라이브.
11.1.2 DB 서버
11.1.2.1 소프트웨어 환경
- OS 이름: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 하드웨어 환경
- 단일 프로세서: Intel(R) Xeon(R) CPU L5520 @ 2.27GHz, 2261MhzES-1620 0 @ 3.60GHz, 4 Core, 논리 프로세서 8개.
- 824GB RamRAM.
- 4개의 파티션으로 분할된 465GB ATA500GB SATA 7200rpm 6GB/s 드라이브.
11.2 B. 쿼리 성능 비교 테스트
Northwind 모델은 이러한 테스트를 실행하는 데 사용되었습니다. Entity Framework 디자이너를 사용하여 데이터베이스에서 생성되었습니다. 그런 다음, 다음 코드를 사용하여 쿼리 실행 옵션의 성능을 비교했습니다.
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Navision 모델
Navision 데이터베이스는 Microsoft Dynamics - NAV를 데모하는 데 사용되는 대형 데이터베이스입니다. 생성된 개념 모델에는 1005개의 엔터티 집합과 4227개의 연결 집합이 포함됩니다. 테스트에 사용된 모델은 "플랫"이며 상속이 추가되지 않았습니다.
11.3.1 Navision 테스트에 사용되는 쿼리
Navision 모델과 함께 사용되는 쿼리 목록에는 엔터티 SQL 쿼리의 3가지 범주가 포함되어 있습니다.
11.3.1.1 조회
집계가 없는 간단한 조회 쿼리
- 개수: 16232
- 예시:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
여러 집계가 있지만 부분합이 없는 일반 BI 쿼리(단일 쿼리)
- 개수: 2313
- 예시:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
모델에서 MDF_SessionLogin_Time_Max()가 정의되는 위치는 다음과 같습니다.
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregatingSubtotals
집계 및 부분합이 있는 BI 쿼리(union all을 통해)
- 개수: 178
- 예시:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>
.NET
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기