Notebook을 사용하여 미러 데이터베이스에서 데이터 탐색
Notebook에서 Spark 쿼리를 사용하여 미러 데이터베이스에서 복제본(replica) 데이터를 탐색할 수 있습니다.
Notebook은 데이터에 대한 Apache Spark 작업 및 기계 학습 실험을 개발할 수 있는 강력한 코드 항목입니다. Fabric Lakehouse에서 Notebook을 사용하여 미러 테이블을 탐색할 수 있습니다.
필수 조건
- 자습서를 완료하여 원본 데이터베이스에서 미러 데이터베이스를 만듭니다.
바로 가기 만들기
먼저 미러 테이블에서 Lakehouse로 바로 가기를 만든 다음 Lakehouse에서 Spark 쿼리를 사용하여 Notebook을 빌드해야 합니다.
패브릭 포털에서 데이터 엔지니어 엽니다.
레이크하우스를 아직 만들지 않은 경우 Lakehouse를 선택하고 이름을 지정하여 새 레이크하우스를 만듭니다.
데이터 가져오기 ->새 바로 가기를 선택합니다.
Microsoft OneLake를 선택합니다.
패브릭 작업 영역에서 모든 미러 데이터베이스를 볼 수 있습니다.
Lakehouse에 추가할 미러 데이터베이스를 바로 가기로 선택합니다.
미러 데이터베이스에서 원하는 테이블을 선택합니다.
다음을 선택한 다음 만들기를 선택합니다.
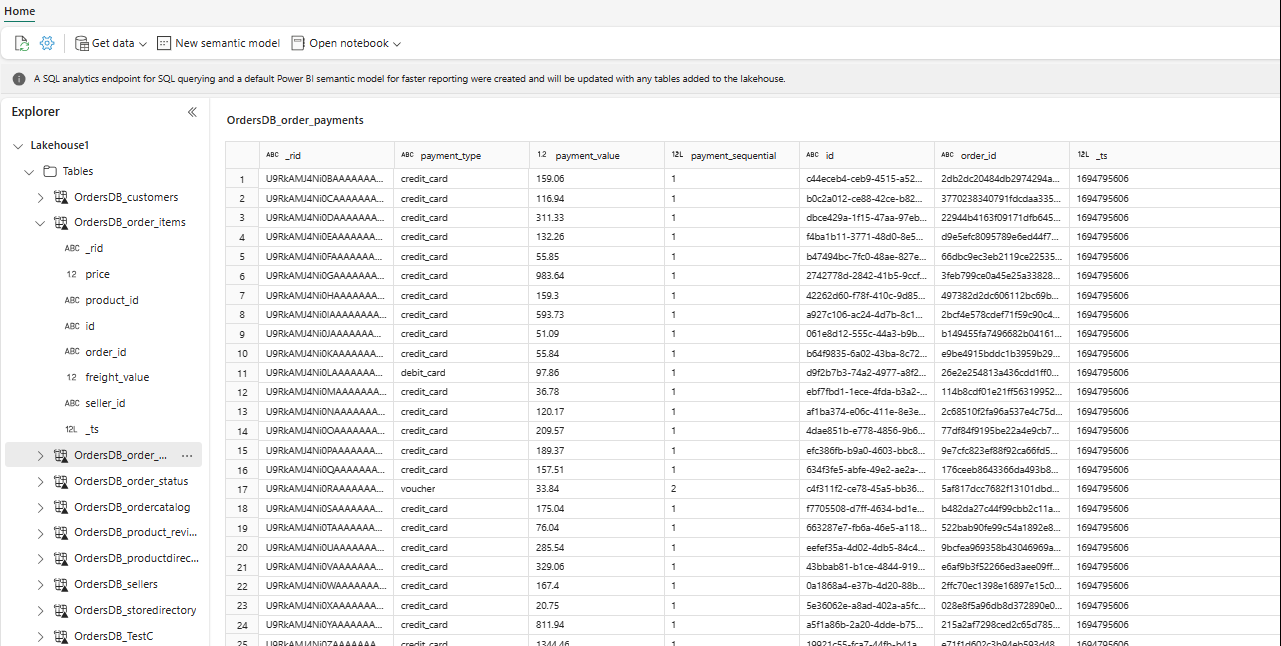
이제 탐색기에서 Lakehouse에서 선택한 테이블 데이터를 볼 수 있습니다.
팁
Lakehouse에서 직접 다른 데이터를 추가하거나 S3, ADLS Gen2와 같은 바로 가기를 가져올 수 있습니다. Lakehouse의 SQL 분석 엔드포인트로 이동하여 이러한 모든 원본의 데이터를 미러 데이터와 원활하게 조인할 수 있습니다.
Spark에서 이 데이터를 탐색하려면 테이블 옆에 있는
...점을 선택합니다. 새 전자 필기장 또는 기존 전자 필기장을 선택하여 분석을 시작합니다.
Notebook이 자동으로 열리고 Spark SQL 쿼리를 사용하여 데이터 프레임을
SELECT ... LIMIT 1000로드합니다.- 새 Notebook을 완전히 로드하는 데 최대 2분이 걸릴 수 있습니다. 활성 세션이 있는 기존 Notebook을 사용하여 이 지연을 방지할 수 있습니다.
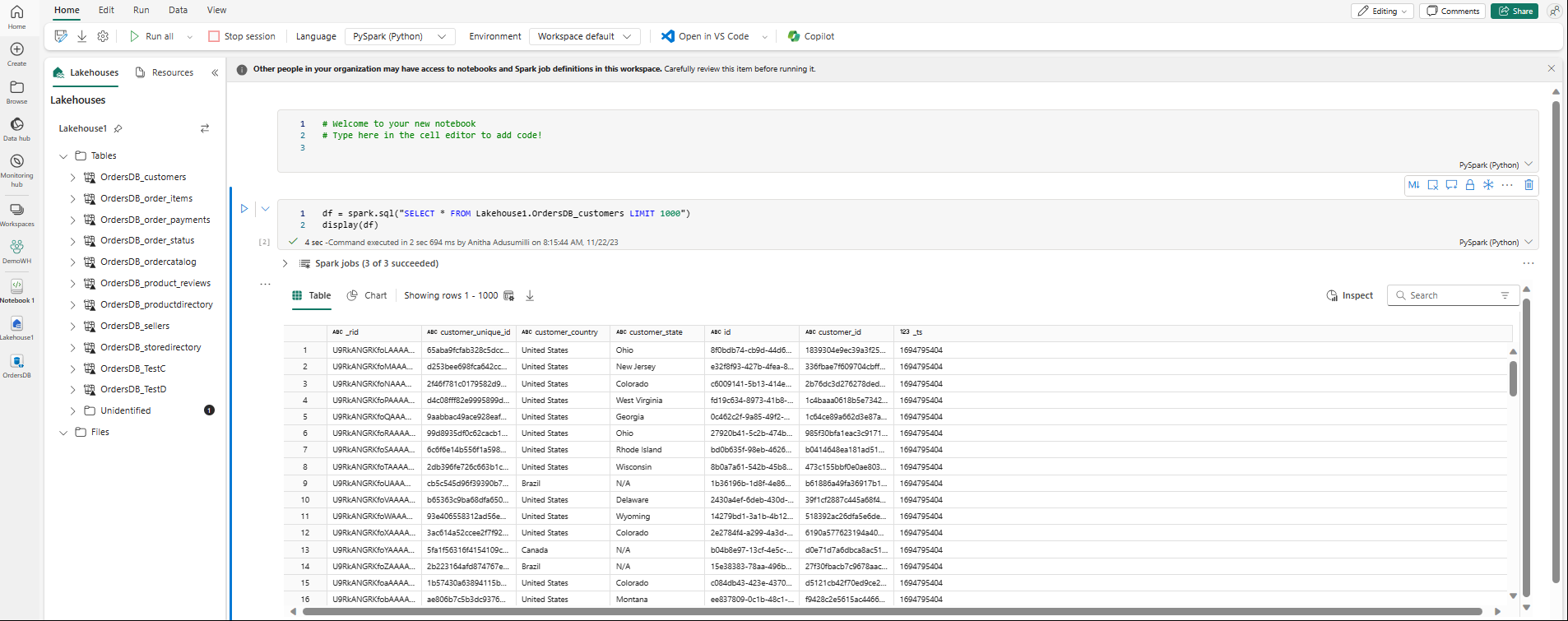
- 새 Notebook을 완전히 로드하는 데 최대 2분이 걸릴 수 있습니다. 활성 세션이 있는 기존 Notebook을 사용하여 이 지연을 방지할 수 있습니다.



관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기