회귀
회귀 모델은 기능과 알려진 레이블을 모두 포함하는 학습 데이터를 기반으로 숫자 레이블 값을 예측하도록 학습됩니다. 회귀 모델(또는 실제로 감독되는 기계 학습 모델)을 학습하는 프로세스에는 적절한 알고리즘(일반적으로 일부 매개 변수가 있는 설정 포함)을 사용하여 모델을 학습시키고, 모델의 예측 성능을 평가하고, 예측 정확도의 허용 가능한 수준을 달성할 때까지 다양한 알고리즘 및 매개 변수로 학습 프로세스를 반복하여 모델을 구체화하는 여러 반복이 포함됩니다.
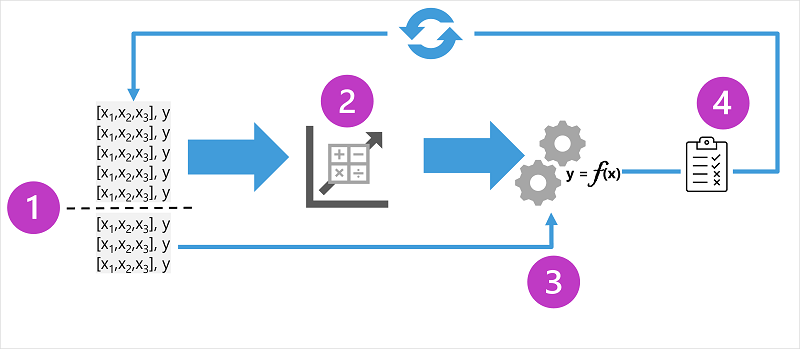
이 다이어그램은 감독되는 기계 학습 모델에 대한 학습 프로세스의 네 가지 주요 요소를 보여 줍니다.
- 학습 데이터를 임의로 분할하여 학습된 모델의 유효성을 검사하는 데 사용할 데이터의 하위 집합을 유지하면서 모델을 학습시킬 데이터 세트를 만듭니다.
- 알고리즘을 사용하여 학습 데이터를 모델에 맞춥니다. 회귀 모델의 경우 선형 회귀와 같은 회귀 알고리즘을 사용합니다.
- 보류한 유효성 검사 데이터를 사용하여 기능에 대한 레이블을 예측하여 모델을 테스트합니다.
- 검증 데이터 세트의 알려진 실제 레이블을 모델이 예측한 레이블과 비교합니다. 그런 다음, 예측된 레이블 값과 실제 레이블 값 간의 차이를 집계하여 모델이 유효성 검사 데이터에 대해 얼마나 정확하게 예측했는지를 나타내는 메트릭을 계산합니다.
각 학습, 유효성 검사 및 평가 반복 후에는 허용되는 평가 메트릭이 달성될 때까지 다양한 알고리즘 및 매개 변수를 사용하여 프로세스를 반복할 수 있습니다.
예제 - 회귀
단일 기능 값(x)을 기반으로 숫자 레이블(y)을 예측하도록 모델을 학습시키는 단순화된 예를 통해 회귀를 살펴보겠습니다. 대부분의 실제 시나리오에는 몇 가지 복잡성을 추가하는 여러 기능 값이 포함되지만, 원칙은 동일합니다.
이 예제에서는 앞에서 설명한 아이스크림 판매 시나리오를 살펴보겠습니다. 이 기능의 경우 온도(값이 지정된 날짜의 최대 온도라고 가정)를 고려하고 예측하도록 모델을 학습시키려는 레이블은 그날 판매된 아이스크림의 수입니다. 일일 기온(x) 및 아이스크림 판매(y)에 대한 기록을 포함하는 몇 가지 과거 데이터부터 시작하겠습니다.
 |
 |
|---|---|
| 온도(x) | 아이스크림 매출(y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
회귀 모델 학습
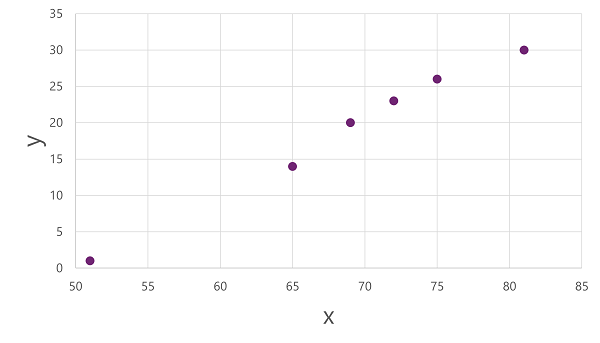
먼저 데이터를 분할하고 하위 집합을 사용하여 모델을 학습시킵니다. 학습 데이터 세트는 다음과 같습니다.
| 온도(x) | 아이스크림 매출(y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
이러한 x 및 y 값이 서로 어떻게 관련될 수 있는지에 대한 통찰력을 얻으려면 다음과 같이 두 축을 따라 좌표로 그릴 수 있습니다.
이제 학습 데이터에 알고리즘을 적용하고 x에 연산을 적용하여 y를 계산하는 함수에 맞출 준비가 되었습니다. 이러한 알고리즘 중 하나는 선형 회귀로써, 다음과 같이 선과 표시된 점 사이의 평균 거리를 최소화하면서 x와 y 값의 교차점을 통해 직선을 생성하는 함수를 도출하여 작동합니다.
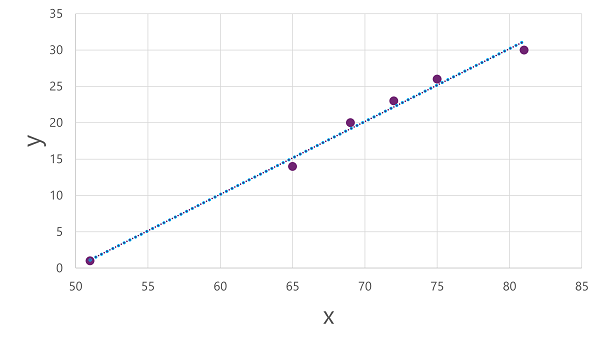
선은 선의 기울기가 주어진 x 값에 대해 y 값을 계산하는 방법을 설명하는 함수의 시각적 표현입니다. 선은 50에서 x축을 인터셉트하므로 x가 50이면 y는 0입니다. 플롯의 축 마커에서 볼 수 있듯이 x축을 따라 5가 증가할 때마다 y축이 위로 5씩 증가하도록 선이 기울어집니다. 따라서 x가 55일 때 y는 5입니다. x가 60이면 y는 10입니다. 주어진 x 값에 대해 y 값을 계산하기 위해 함수는 단순히 50을 뺍니다. 즉, 함수는 다음과 같이 표현할 수 있습니다.
f(x) = x-50
이 함수를 사용하여 지정된 온도로 하루에 판매되는 아이스크림의 수를 예측할 수 있습니다. 예를 들어 일기 예보에서 내일은 화씨 77도(섭씨 25도)가 될 것이라고 가정해 보겠습니다. 모델을 적용하여 77-50을 계산하고 내일 27개의 아이스크림을 판매할 것이라고 예측할 수 있습니다.
하지만 모델이 얼마나 정확한가요?
회귀 모델 평가
모델의 유효성을 검사하고 모델이 얼마나 잘 예측하는지 평가하기 위해 레이블(y) 값을 알고 있는 일부 데이터를 보류했습니다. 보류한 데이터는 다음과 같습니다.
| 온도(x) | 아이스크림 매출(y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
모델을 사용하여 기능(x) 값을 기반으로 이 데이터 세트의 각 관측치에 대한 레이블을 예측할 수 있습니다. 그런 다음 예측된 레이블(ŷ)을 알려진 실제 레이블 값(y)과 비교합니다.
함수 f(x) = x-50을 캡슐화하는 앞에서 학습한 모델을 사용하면 다음과 같은 예측을 얻을 수 있습니다.
| 온도(x) | 실제 매출(y) | 예상 매출(ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
다음과 같이 기능 값에 대해 예측된 레이블과 실제 레이블을 모두 그릴 수 있습니다.
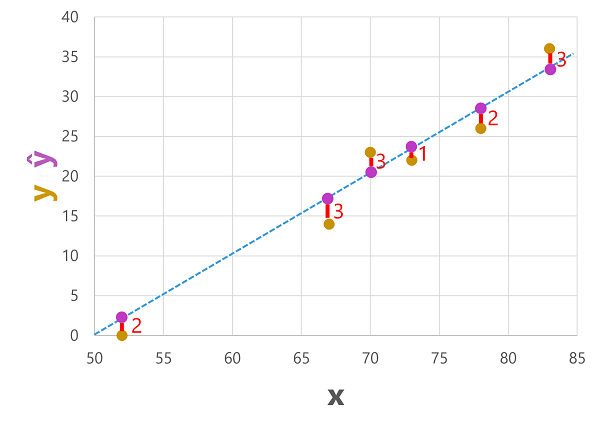
예측된 레이블은 모델에 의해 계산되므로 함수 줄에 있지만 함수에서 계산한 ŷ 값과 유효성 검사 데이터 세트의 실제 y 값 사이에는 약간의 차이가 있습니다. 이는 플롯에서 ŷ와 y 값 사이의 선으로 표시되며, 이는 예측이 실제 값에서 얼마나 멀리 떨어져 있는지를 보여줍니다.
회귀 평가 메트릭
예측 값과 실제 값의 차이점에 따라 회귀 모델을 평가하는 데 사용되는 몇 가지 일반적인 메트릭을 계산할 수 있습니다.
MAE(평균 절대 오차)
이 예제의 차이는 각 예측에서 잘못된 아이스크림 수를 나타냅니다. 예측이 실제 값보다 높거나낮았는지 여부는 중요하지 않습니다(예: -3과 +3은 모두 분산이 3임을 나타냄). 이 메트릭은 각 예측에 대한 절대 오차라고 하며 전체 유효성 검사 집합에 대해 평균 절대 오차(MAE)로 요약할 수 있습니다.
아이스크림 예에서 절대 오차(2, 3, 3, 1, 2, 3)의 평균은 2.33입니다.
MSE(평균 제곱 오차)
평균 절대 오차 메트릭은 예측 레이블과 실제 레이블 간의 모든 불일치를 동일하게 고려합니다. 그러나 더 적지만 더 큰 오류를 만드는 모델보다 소량으로 일관되게 잘못된 오류를 만드는 모델을 갖는 것이 더 바람직할 수 있습니다. 개별 오차를 제곱하고 제곱 값의 평균을 계산하여 더 큰 오차를 "증폭"하는 메트릭을 생성하는 한 가지 방법입니다. 이 메트릭을 평균 제곱 오차(MSE)라고 합니다.
아이스크림 예에서 제곱 절대값(4, 9, 9, 1, 4, 9)의 평균은 6입니다.
RMSE(제곱 평균 오차)
평균 제곱 오차는 오차의 크기를 고려하는 데 도움이 되지만, 오차 값을 제곱하기 때문에 결과 지표는 더 이상 레이블로 측정된 수량을 나타내지 않습니다. 즉, 모델의 MSE는 6이라고 말할 수 있지만, 이는 잘못 예측된 아이스크림 수 측면에서 정확도를 측정하지는 않습니다. 6은 유효성 검사 예측의 오류 수준을 나타내는 숫자 점수일 뿐입니다.
아이스크림 수로 오차를 측정하려면 MSE의 제곱근을 계산해야 합니다. 이는 당연히 제곱 평균 오차라는 메트릭을 생성합니다. 이 경우 √6은 2.45(아이스크림)입니다.
결정 계수(R2):
지금까지의 모든 메트릭은 모델을 평가하기 위해 예측 값과 실제 값 간의 불일치를 비교합니다. 그러나 실제로는 모델이 고려한 아이스크림의 일일 판매에서 자연적인 무작위 차이가 있습니다. 선형 회귀 모델에서 학습 알고리즘은 함수와 알려진 레이블 값 간의 평균 차이를 최소화하는 직선에 적합합니다. 결정 계수(보다 일반적으로 R2 또는 R-제곱이라고 함)는 검증 데이터의 일부 비정상적인 측면(예: 지역 축제로 인해 아이스크림 판매량이 매우 특이한 날)과 달리 모델로 설명할 수 있는 검증 결과의 분산 비율을 측정하는 메트릭입니다.
R2에 대한 계산은 이전 메트릭보다 더 복잡합니다. 예측 레이블과 실제 레이블 간의 제곱 차이의 합계를 실제 레이블 값과 실제 레이블 값의 평균 간의 제곱 차이의 합계와 비교합니다.
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
복잡해 보이는 경우 너무 걱정하지 마세요. 대부분의 기계 학습 도구는 메트릭을 계산할 수 있습니다. 중요한 점은 결과가 모델에서 설명하는 분산의 비율을 설명하는 0에서 1 사이의 값이라는 것입니다. 간단히 말하면 이 값이 1에 가까울수록 모델이 유효성 검사 데이터에 더 적합합니다. 아이스크림 회귀 모델의 경우, 검증 데이터로부터 계산된 R2는 0.95입니다.
반복 학습
위에서 설명한 메트릭은 일반적으로 회귀 모델을 평가하는 데 사용됩니다. 대부분의 실제 시나리오에서 데이터 과학자는 반복 프로세스를 사용하여 다양한 모델을 반복적으로 학습하고 평가합니다.
- 기능 선택 및 준비(모델에 포함할 기능 선택 및 더 나은 적합성을 보장하기 위해 적용된 계산).
- 알고리즘 선택(이전 예제에서는 선형 회귀를 살펴보았지만 다른 많은 회귀 알고리즘이 있음)
- 알고리즘 매개 변수(알고리즘 동작을 제어하기 위한 숫자 설정, 더 정확하게는 x 및 y 매개 변수와 구별하기 위해 하이퍼 매개 변수라고 함)
여러 차례 반복한 후 특정 시나리오에 허용되는 최상의 평가 메트릭을 생성하는 모델이 선택됩니다.