Kafka 및 Spark 아키텍처 만들기
Azure HDInsight에서 Kafka 및 Spark를 함께 사용하려면 클러스터가 DNS 이름 확인을 사용하여 작동하도록 동일한 VNet 내에 추가하거나 VNet를 피어링해야 합니다.
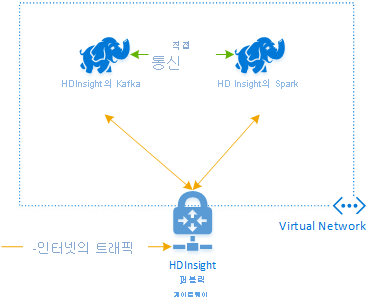
동일한 VNet에서 클러스터를 만들려면 다음 절차를 수행합니다.
- 리소스 그룹 만들기
- 리소스 그룹에 VNet 추가
- 동일한 VNet에 Kafka 클러스터 및 Spark 클러스터를 추가 또는 그 대신에 이러한 서비스가 작동하는 VNet을 DNS 이름 확인으로 피어링합니다.
HDInsight을 Kafka 및 Spark 클러스터에 연결하는 데 권장되는 방법은 기본 Spark-Kafka 커넥터입니다. 이 커넥터를 사용하면 Spark 클러스터가 Kafka 클러스터 내에서 데이터의 개별 파티션에 액세스할 수 있으므로 실시간 처리 작업에 포함되는 병렬 처리가 증가하고 처리량이 매우 높아집니다.
두 클러스터 모두 동일한 VNet에 있는 경우 Spark 스트리밍 코드에서 Kafka Broker FQDN을 사용하고 엔터프라이즈 보안을 위해 VNet에서 NSG 규칙을 만들 수 있습니다.
솔루션 아키텍처
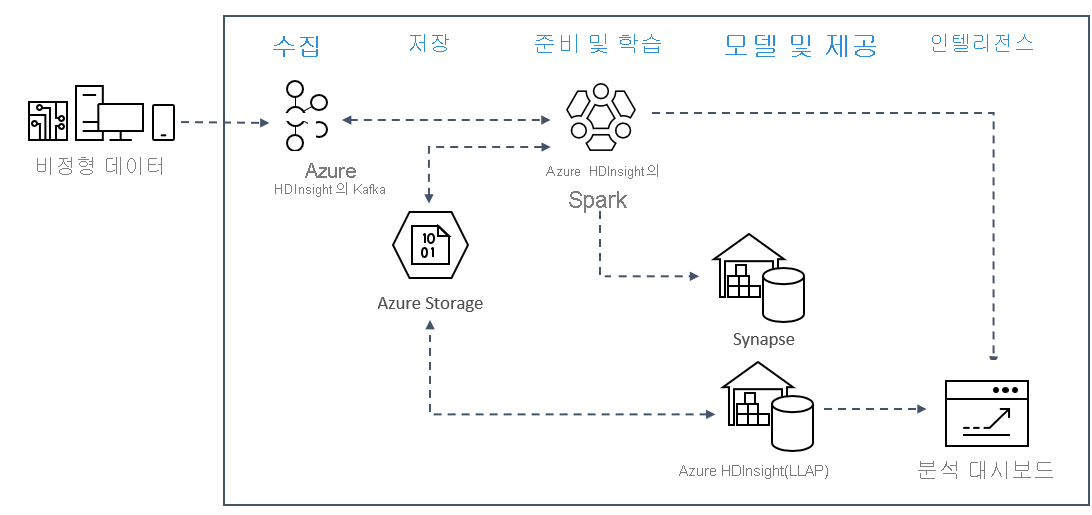
Azure의 실시간 스트리밍 분석 패턴은 일반적으로 다음과 같은 솔루션 아키텍처를 사용합니다.
- 수집: 비정형 또는 정형 데이터는 Azure HDInsight의 Kafka 클러스터로 수집됩니다.
- 준비 및 학습: 데이터는 HDInsight에서 Spark를 사용하여 준비 및 학습됩니다.
- 모델 및 서비스: 데이터는 Azure Synapse 또는 HDInsight Interactive Query와 같은 데이터 웨어하우스에 저장됩니다.
- 인텔리전스: 데이터는 Power BI 또는 Tableau와 같은 분석 대시보드에 제공됩니다.
- 저장소: 데이터는 Azure Storage와 같은 콜드 스토리지 솔루션에 저장되며 나중에 제공됩니다.
샘플 시나리오 아키텍처
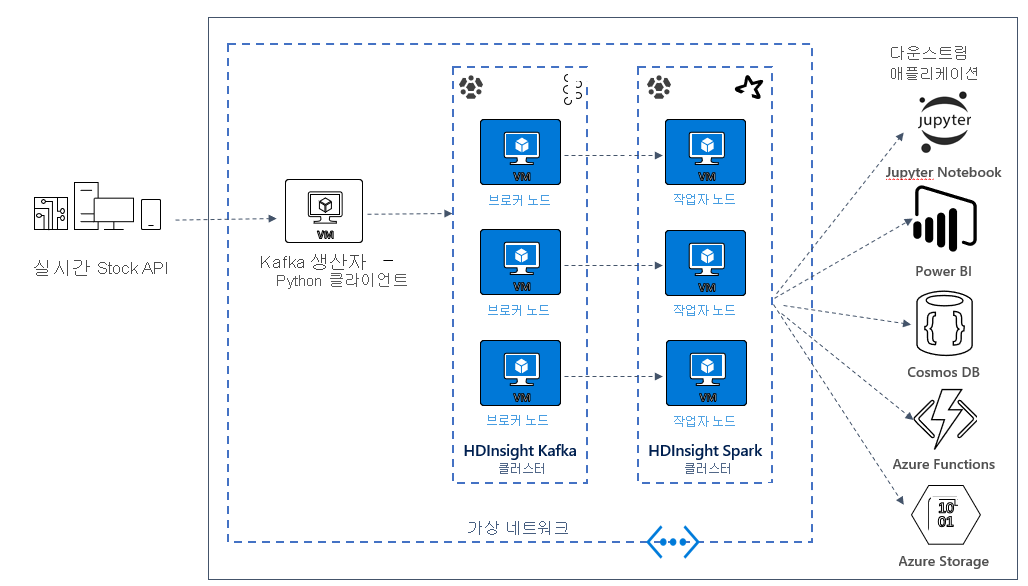
다음 단원에서는 샘플 애플리케이션을 위한 솔루션 아키텍처 빌드를 시작합니다. 이 샘플에서는 Azure Resource Manager 템플릿 파일을 사용하여 리소스 그룹, VNet, Spark 클러스터 및 Kafka 클러스터를 만듭니다.
클러스터가 배포되면 Kafka broker 중 하나로 SSH하고 Python 생산자 파일을 헤드 노드에 복사합니다. 이 생산자 파일은 10초마다 인위의 주식 가격을 제공하며, 메시지의 파티션 번호 및 오프셋을 콘솔에 기록합니다.
생산자를 실행한 후에는 Jupyter Notebook을 Spark 클러스터에 업로드할 수 있습니다. Notebook에서 Spark 및 Kafka 클러스터를 연결하고 이벤트 창 내에서 주식의 최고 및 최저 값을 검색하는 것을 포함하여 데이터에 대한 샘플 쿼리를 실행합니다.