Apache Spark 및 Hive LLAP 쿼리 통합
이전 단원에서는 Interactive Query 클러스터에 저장된 정적 데이터를 쿼리하는 Data Analytics Studio 및 Zeppelin Notebook이라는 두 가지 방법을 살펴보았습니다. 하지만 Spark를 사용하여 새 부동산 데이터를 클러스터로 스트리밍하고 Hive를 사용하여 쿼리할 때 어떻게 되었나요? Hive 및 Spark에는 서로 다른 metastore 두 개가 있기 때문에 두 개를 브리지로 연결하는 커넥터가 필요하며 Apache HWC(Hive Warehouse Connector)가 해당 브리지입니다. Hive Warehouse Connector 라이브러리를 사용하면 Spark DataFrames와 Hive 테이블 간에 데이터를 이동하고 Spark 스트리밍 데이터를 Hive 테이블로 전송하는 등의 작업을 지원하여 Apache Spark 및 Apache Hive를 보다 쉽게 사용할 수 있습니다. 시나리오에서는 커넥터를 설정하지 않지만 옵션이 있다는 것을 알고 있어야 합니다.
Apache Spark에는 Apache Hive에서 사용할 수 없는 스트리밍 기능을 제공하는 구조적 스트리밍 API가 있습니다. HDInsight 4.0부터 Apache Spark 2.3.1 및 Apache Hive 3.1.0에는 별도의 metastore가 있으므로 상호 운용이 어려워집니다. Hive Warehouse Connector를 통해 보다 쉽게 Spark 및 Hive를 함께 사용할 수 있습니다. Hive Warehouse Connector 라이브러리는 LLAP 디먼에서 Spark 실행자로 병렬로 데이터를 로드하므로 Spark에서 Hive로 표준 JDBC 연결을 사용하는 것보다 더 효율적이고 확장성이 높습니다.
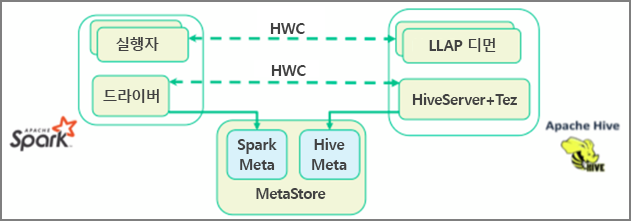
Hive Warehouse Connector에서 지원하는 일부 작업은 다음과 같습니다.
- 테이블 설명
- ORC(Optimized Row Columnar) 형식 데이터의 테이블 만들기
- Hive 데이터 선택 및 DataFrame 검색
- Hive에 DataFrame 일괄 쓰기
- Hive update 문 실행
- Hive에서 테이블 데이터 읽기, Spark에서 데이터 변환 및 새 Hive 테이블에 데이터 쓰기
- HiveStreaming를 사용하여 Hive에 DataFrame 또는 Spark 스트림 쓰기
Spark 클러스터 및 Interactive Query 클러스터가 배포되면 모든 HDInsight 클러스터에 포함된 웹 기반 도구인 Ambari에서 Spark 클러스터 설정을 구성합니다. Ambari를 열려면 인터넷 브라우저에서 https://servername. azurehdinsight.net으로 이동합니다. 여기서 servername은 Interactive Query 클러스터의 이름입니다.
그런 다음, 테이블에 Spark 스트리밍 데이터를 쓰려면 Hive 테이블을 만들고 테이블에 데이터를 쓰기 시작합니다. 그런 다음, 스트리밍 데이터에서 쿼리를 실행합니다. 다음 중 하나를 사용할 수 있습니다.
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy