연습: 마이그레이션된 데이터베이스 보호, 모니터링, 튜닝
AdventureWorks 조직의 데이터베이스 개발자로 근무하고 있다고 가정해 보겠습니다. AdventureWorks는 10년 이상 자전거와 자전거 부품을 최종 소비자 및 유통업자에게 직접 판매하고 있습니다. 회사 시스템에서는 이전에 Azure Database for PostgreSQL로 마이그레이션한 데이터베이스에 정보를 저장합니다.
마이그레이션을 수행한 후 시스템이 제대로 성능을 발휘하고 있는지 확인하려고 합니다. 서버를 모니터링하는 데 사용할 수 있는 Azure 도구를 사용하기로 결정했습니다. 경합 및 대기 시간 때문에 응답 시간이 느려질 가능성을 줄이기 위해 읽기 복제를 구현하기로 결정했습니다. 결과 시스템을 모니터링하고 결과를 유연한 서버 아키텍처와 비교해야 합니다.
이 연습에서 수행하는 작업은 다음과 같습니다.
- Azure Database for PostgreSQL 서비스에 대한 Azure 메트릭을 구성합니다.
- 여러 사용자가 데이터베이스를 쿼리하는 것을 시뮬레이션하는 애플리케이션 예제를 실행합니다.
- 메트릭을 확인합니다.
환경 설정
Cloud Shell에서 다음 Azure CLI 명령을 실행하여 adventureworks 데이터베이스 복사본으로 Azure Database for PostgreSQL을 생성합니다. 마지막 명령은 서버 이름을 인쇄합니다.
SERVERNAME="adventureworks$((10000 + RANDOM % 99999))"
PUBLICIP=$(wget http://ipecho.net/plain -O - -q)
git clone https://github.com/MicrosoftLearning/DP-070-Migrate-Open-Source-Workloads-to-Azure.git workshop
az postgres server create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--name $SERVERNAME \
--location westus \
--admin-user awadmin \
--admin-password Pa55w.rdDemo \
--version 10 \
--storage-size 5120
az postgres db create \
--name azureadventureworks \
--server-name $SERVERNAME \
--resource-group <rgn>[sandbox resource group name]</rgn>
az postgres server firewall-rule create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--server $SERVERNAME \
--name AllowMyIP \
--start-ip-address $PUBLICIP --end-ip-address $PUBLICIP
PGPASSWORD=Pa55w.rdDemo psql -h $SERVERNAME.postgres.database.azure.com -U awadmin@$SERVERNAME -d postgres -f workshop/migration_samples/setup/postgresql/adventureworks/create_user.sql
PGPASSWORD=Pa55w.rd psql -h $SERVERNAME.postgres.database.azure.com -U azureuser@$SERVERNAME -d azureadventureworks -f workshop/migration_samples/setup/postgresql/adventureworks/adventureworks.sql 2> /dev/null
echo "Your PostgreSQL server name is:\n"
echo $SERVERNAME.postgres.database.azure.com
Azure Database for PostgreSQL 서비스에 대한 Azure 메트릭 구성
웹 브라우저를 사용하여 새 탭을 열고 Azure Portal로 이동합니다.
Azure Portal에서 모든 리소스를 선택합니다.
adventureworks로 시작하는 Azure Database for PostgreSQL 서버 이름을 선택합니다.
모니터링 아래에서 메트릭을 선택합니다.
차트 페이지에서 다음 메트릭을 추가합니다.
속성 값 Scope adventureworks[nnn] 메트릭 네임스페이스 PostgreSQL 서버 표준 메트릭 메트릭 활성 연결 집계 Avg 이 메트릭은 분 단위로 서버에 대한 평균 연결 수를 표시합니다.
메트릭 추가를 선택하고 다음 메트릭을 추가합니다.
속성 값 Scope adventureworks[nnn] 메트릭 네임스페이스 PostgreSQL 서버 표준 메트릭 메트릭 CPU 비율 집계 Avg 메트릭 추가를 선택하고 다음 메트릭을 추가합니다.
속성 값 Scope adventureworks[nnn] 메트릭 네임스페이스 PostgreSQL 서버 표준 메트릭 메트릭 메모리 백분율 집계 Avg 메트릭 추가를 선택하고 다음 메트릭을 추가합니다.
속성 값 Scope adventureworks[nnn] 메트릭 네임스페이스 PostgreSQL 서버 표준 메트릭 메트릭 IO 백분율 집계 Avg 마지막 세 메트릭은 테스트 애플리케이션에서 리소스가 사용되는 방법을 보여 줍니다.
차트의 시간 범위를 지난 30분으로 설정합니다.
대시보드에 고정을 선택하고 고정을 선택합니다.
여러 사용자가 데이터베이스를 쿼리하는 것을 시뮬레이션하는 애플리케이션 예제 실행
Azure Portal의 Azure Database for PostgreSQL 서버 페이지에서 설정 아래의 연결 문자열을 선택합니다. ADO.NET 연결 문자열을 클립보드에 복사합니다.
~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTest 폴더로 이동합니다.
cd ~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTest코드 편집기를 사용하여 App.config 파일을 엽니다.
code App.config데이터베이스 값을 azureadventureworks로 바꾸고 ConectionString0을 클립보드의 연결 문자열로 바꿉니다. 사용자 ID를 azureuser@adventureworks[nnn]으로 변경하고 암호를Pa55w.rd로 설정합니다. 전체 파일은 아래 예와 유사합니다.
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="INSERT CONNECTION STRING HERE" /> <add key="ConnectionString2" value="INSERT CONNECTION STRING HERE" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="1"/> </appSettings> </configuration>참고
여기에서는 ConnectionString1 및 ConnectionString2 설정을 무시합니다. 이러한 항목은 랩의 뒷부분에서 업데이트합니다.
변경 내용을 저장하고 편집기를 닫습니다.
Cloud Shell 프롬프트에서 다음 명령을 실행하여 앱을 빌드하고 실행합니다.
dotnet run앱이 시작되면 수많은 스레드를 생성합니다. 스레드마다 각 사용자를 시뮬레이션합니다. 스레드는 일련의 쿼리를 실행하는 루프를 수행합니다. 아래와 같은 메시지가 표시되기 시작합니다.
Client 48 : SELECT * FROM purchasing.vendor Response time: 630 ms Client 48 : SELECT * FROM sales.specialoffer Response time: 702 ms Client 43 : SELECT * FROM purchasing.vendor Response time: 190 ms Client 57 : SELECT * FROM sales.salesorderdetail Client 68 : SELECT * FROM production.vproductanddescription Response time: 51960 ms Client 55 : SELECT * FROM production.vproductanddescription Response time: 160212 ms Client 59 : SELECT * FROM person.person Response time: 186026 ms Response time: 2191 ms Client 37 : SELECT * FROM person.person Response time: 168710 ms다음 단계를 수행하는 동안 앱이 실행되도록 둡니다.
메트릭 보기
Azure Portal로 돌아갑니다.
왼쪽 창에서 대시보드를 선택합니다.
Azure Database for PostgreSQL 서비스에 대한 메트릭을 표시하는 차트가 표시됩니다.
차트를 선택하여 메트릭 창에서 엽니다.
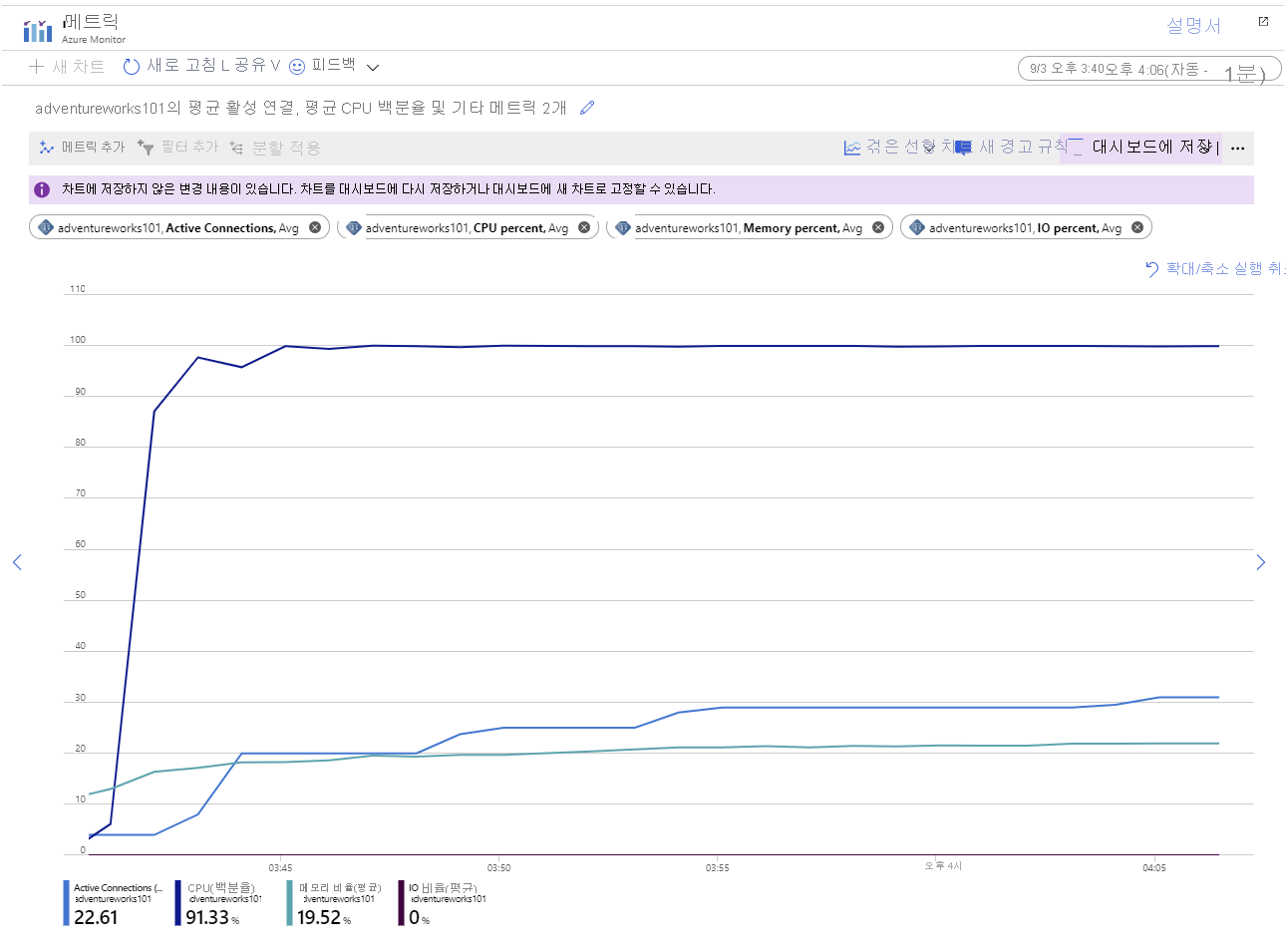
앱이 몇 분 동안 실행되도록 합니다(길수록 좋음). 시간이 지남에 따라 차트의 메트릭은 다음 이미지에 나오는 패턴과 비슷해야 합니다.
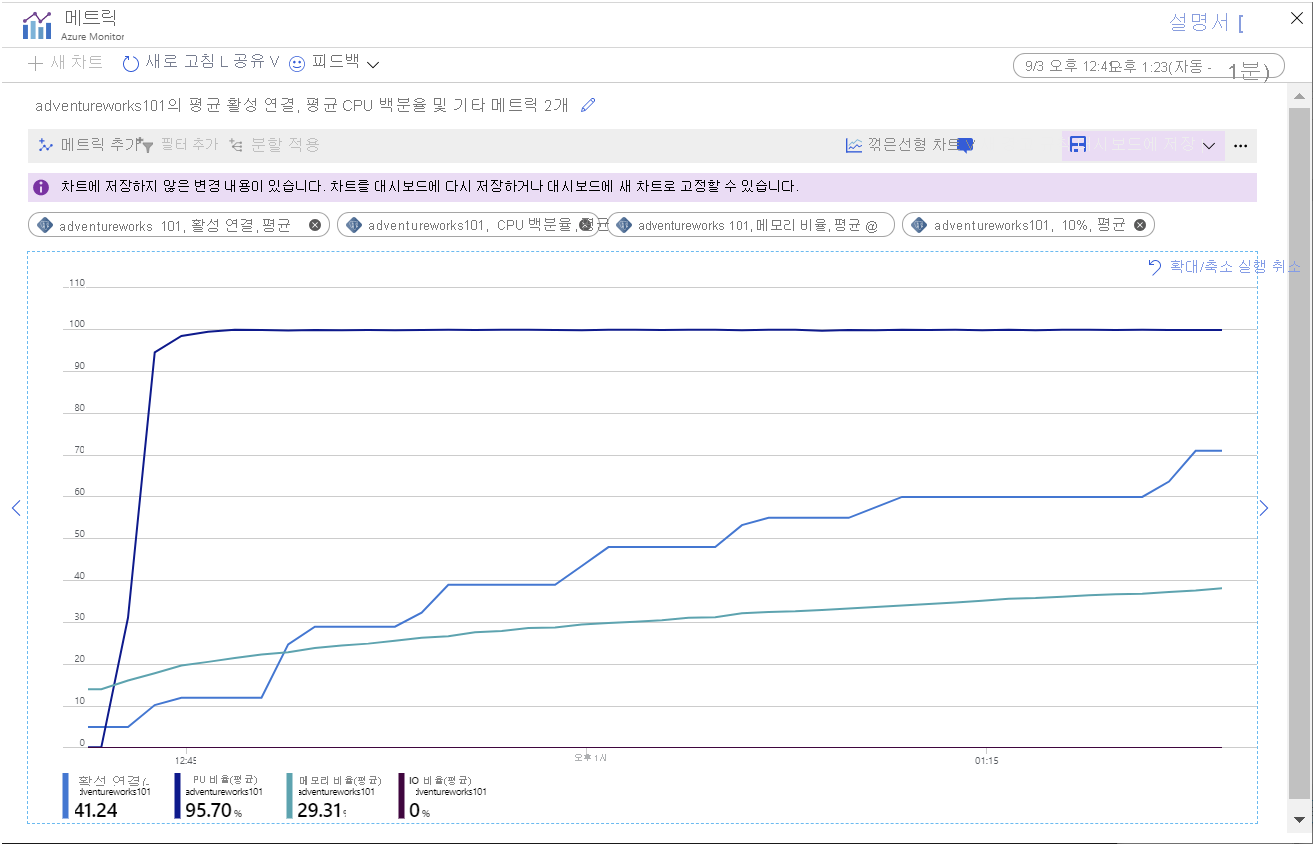
이 차트에는 다음 사항이 강조 표시됩니다.
- CPU가 전체 용량으로 실행되고 있습니다. 사용률이 매우 빠르게 100%에 도달합니다.
- 연결 수가 천천히 증가합니다. 애플리케이션 예제는 빠르게 연속해서 101개의 클라이언트를 시작하도록 설계되었지만 서버는 한 번에 소수의 연결만 열 수 있습니다. 차트의 각 “단계”에 추가되는 연결 수는 점점 작아지고 “단계” 사이의 시간은 점점 늘어납니다. 약 45분 후에는 시스템이 70개의 클라이언트 연결만 설정할 수 있었습니다.
- 시간이 지남에 따라 메모리 사용률은 일관되게 늘어납니다.
- IO 사용률은 0에 가깝습니다. 클라이언트 애플리케이션에 필요한 모든 데이터는 현재 메모리에 캐시되어 있습니다.
애플리케이션이 충분히 오래 실행되도록 두면 다음 이미지에 있는 것처럼 연결이 실패하기 시작하고 오류 메시지가 표시될 것입니다.
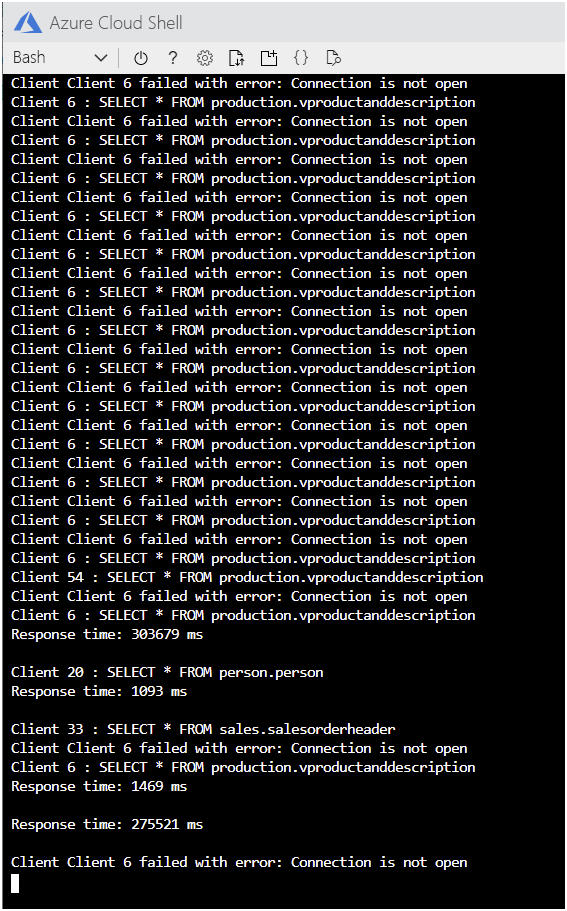
Cloud Shell에서 Enter 키를 눌러 애플리케이션을 중지합니다.
쿼리 성능 데이터를 수집하도록 서버 구성
Azure Portal의 Azure Database for PostgreSQL 서버 페이지에서 설정 아래의 서버 매개 변수를 선택합니다.
서버 매개 변수 페이지에서 다음 매개 변수를 아래 테이블에 지정된 값으로 설정합니다.
매개 변수 값 pg_qs.max_query_text_length 6000 pg_qs.query_capture_mode ALL pg_qs.replace_parameter_placeholders ON pg_qs.retention_period_in_days 7 pg_qs.track_utility ON pg_stat_statements.track ALL pgms_wait_sampling.history_period 100 pgms_wait_sampling.query_capture_mode ALL 저장을 선택합니다.
쿼리 저장소를 사용하여 애플리케이션에서 실행되는 쿼리 검사
Cloud Shell로 돌아가서 앱 예제를 다시 시작합니다.
dotnet run앱이 약 5분 동안 실행되도록 한 다음, 계속합니다.
앱이 실행되도록 두고 Azure Portal로 전환합니다.
Azure Database for PostgreSQL 서버 페이지에서 지능형 성능아래의 Query Performance Insight를 선택합니다.
Query Performance Insight 페이지의 장기 실행 쿼리 탭에서 쿼리 수를 10으로 설정하고, 선택 기준을 avg로 설정하고, 기간을 지난 6시간으로 설정합니다.
차트 위에 있는 확대(“+” 기호가 있는 돋보기 아이콘)를 두세 번 선택하여 바로 최신 데이터를 표시합니다.
애플리케이션을 실행한 기간에 따라 아래와 유사한 차트가 표시됩니다. 쿼리 저장소는 15분마다 쿼리에 대한 통계를 집계하므로 15분마다 각 쿼리에 사용된 상대적 시간이 각 막대에 표시됩니다.
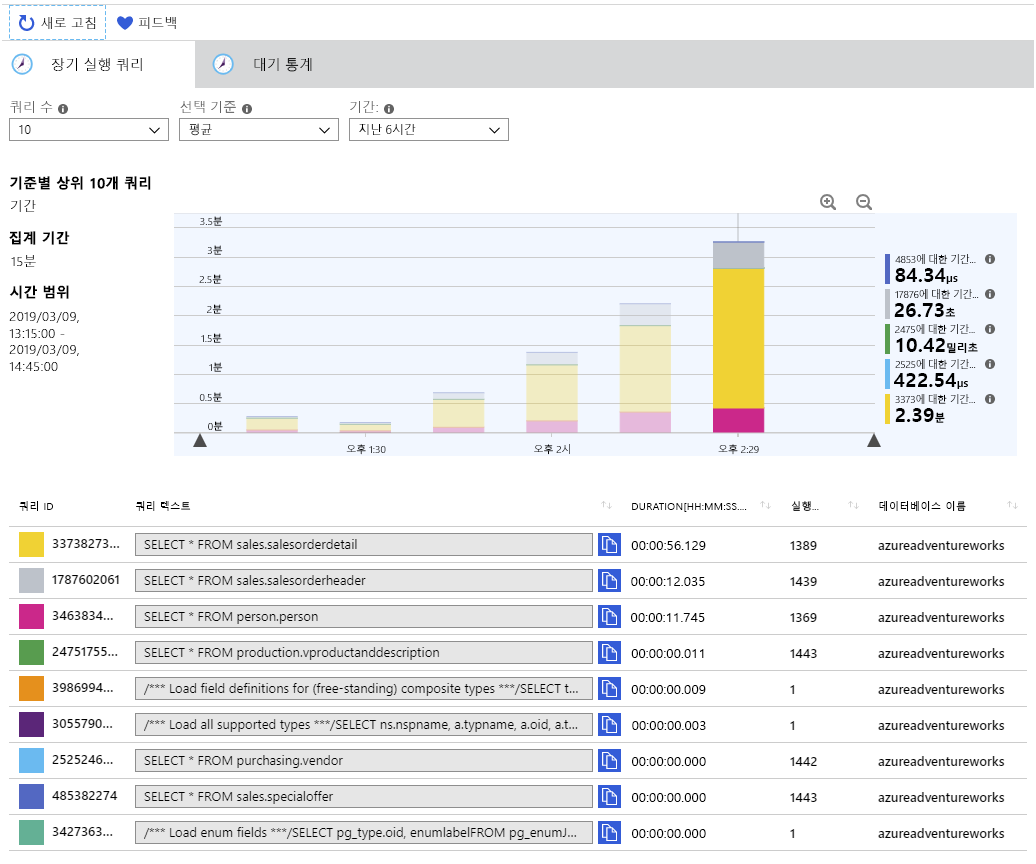
각 막대를 차례로 마우스로 가리켜서 해당 기간의 쿼리에 대한 통계를 확인합니다. 시스템에서 수행하는 데 가장 많은 시간이 걸리는 세 가지 쿼리는 다음과 같습니다.
SELECT * FROM sales.salesorderdetail SELECT * FROM sales.salesorderheader SELECT * FROM person.person이 정보는 시스템을 모니터링하는 관리자에게 유용합니다. 사용자 및 앱에서 실행하는 쿼리에 대한 인사이트를 얻으면 수행되는 워크로드를 이해할 수 있으며 애플리케이션 개발자에게 코드를 개선할 수 있는 방법에 대한 권장 사항을 제공할 수도 있습니다. 예를 들어 애플리케이션이 sales.salesorderdetail 테이블의 121,000개가 넘는 행을 모두 검색할 필요가 있을까요?
쿼리 저장소를 사용하여 발생한 대기 검사
대기 통계 탭을 선택합니다.
기간을 지난 6시간으로 설정하고, 그룹화 기준을 이벤트로 설정하고, 최대 그룹 수를 5로 설정합니다.
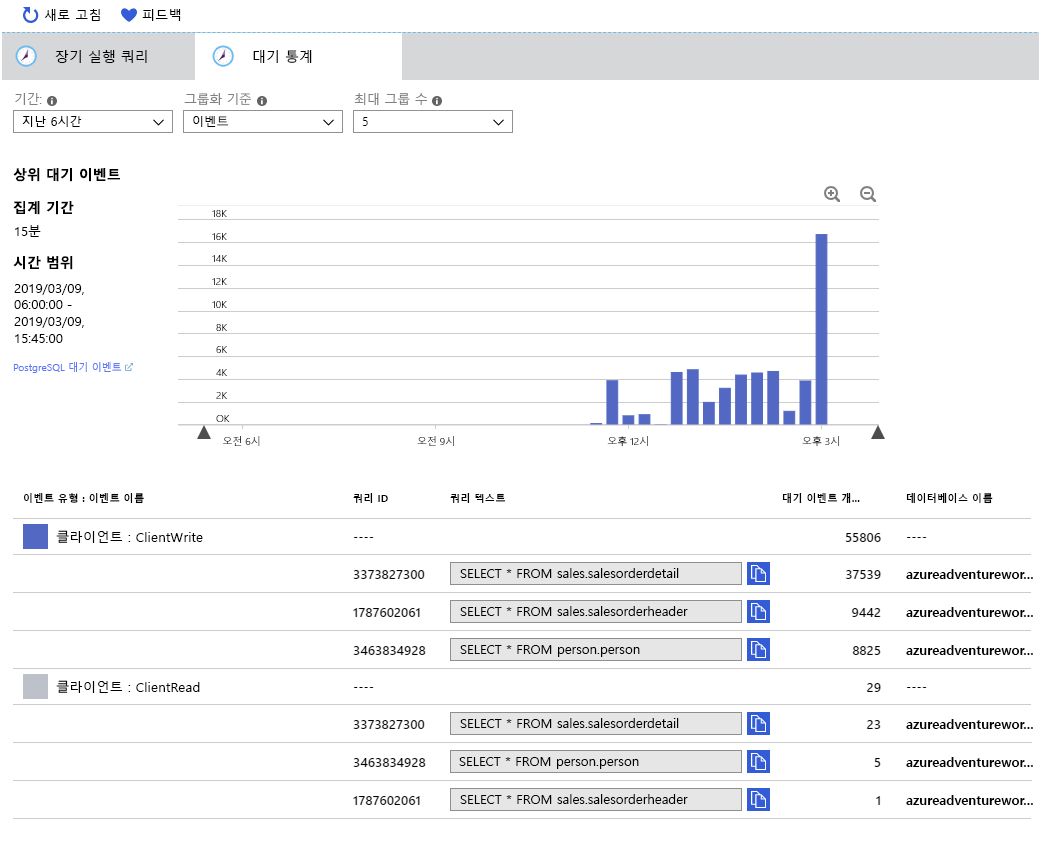
장기 실행 쿼리 탭과 마찬가지로 데이터는 15분마다 집계됩니다. 차트 아래 테이블에 따르면, 시스템에는 다음 두 가지 유형의 대기 이벤트가 자주 발생했습니다.
- Client: ClientWrite. 이 대기 이벤트는 서버가 클라이언트에 데이터(결과)를 다시 쓸 때 발생합니다. 데이터베이스에 쓰는 동안 대기가 발생했음을 나타내지 않습니다.
- Client: ClientRead. 이 대기 이벤트는 서버가 클라이언트에서 데이터(쿼리 요청 또는 다른 명령)를 읽기 위해 기다리고 있을 때 발생합니다. 데이터베이스에서 읽는 데 걸린 시간은 관련이 없습니다.
참고 항목
데이터베이스에 대한 읽기 및 쓰기는 클라이언트 이벤트가 아니라 IO 이벤트로 나타납니다. 이 애플리케이션 예제에서는 처음 읽기 이후 필요한 모든 데이터가 메모리에 캐시되어 있으므로 IO 대기가 발생하지 않습니다. 메트릭이 메모리가 부족한 것으로 표시되면 IO 대기 이벤트가 발생하기 시작하는 것을 볼 수 있습니다.
Cloud Shell로 돌아가서 Enter 키를 눌러 애플리케이션 예제를 중지합니다.
Azure Database for PostgreSQL 서비스에 복제본 추가
Azure Portal의 Azure Database for PostgreSQL 서버 페이지에서 설정 아래의 복제를 선택합니다.
복제 페이지에서 + 복제본 추가를 선택합니다.
PostgreSQL 서버 페이지의 서버 이름 상자에 adventureworks[nnn]-replica1을 입력하고 확인을 선택합니다.
첫 번째 복제본이 만들어지면(시간이 몇 분 걸림) 이전 단계를 반복하여 adventureworks[nnn]-replica2라는 다른 복제본을 추가합니다.
복제본 상태가 둘 다 배포 중에서 사용 가능으로 변경될 때까지 기다린 다음, 계속합니다.
복제본에서 클라이언트 액세스를 사용할 수 있도록 구성
- adventureworks[nnn]-replica1 복제본의 이름을 선택합니다. 이 복제본의 Azure Database for PostgreSQL 페이지로 이동합니다.
- 설정에서 연결 보안을 선택합니다.
- 연결 보안 페이지에서 Azure 서비스에 대한 액세스 허용을 ON으로 설정하고 저장을 선택합니다. 이 설정은 Cloud Shell을 사용하여 실행한 애플리케이션이 서버에 액세스할 수 있도록 합니다.
- 설정이 저장되면 이전 단계를 반복하여 Azure 서비스에서 adventureworks[nnn]-replica2 복제본에 액세스할 수 있도록 합니다.
각 서버 다시 시작
참고
복제 구성에서는 서버를 다시 시작할 필요가 없습니다. 이 작업은 애플리케이션을 다시 실행할 때 수집된 메트릭이 ‘정리’되도록 각 서버에서 메모리 및 불필요한 연결을 지우기 위한 것입니다.
- adventureworks[nnn] 서버 페이지로 이동합니다.
- 개요 페이지에서 다시 시작을 선택합니다.
- 서버 다시 시작 대화 상자에서 예를 선택합니다.
- 서버가 다시 시작할 때까지 기다린 다음, 계속합니다.
- 동일한 절차에 따라 adventureworks[nnn]-replica1 및 adventureworks[nnn]-replica2 서버를 다시 시작합니다.
애플리케이션 예제에서 복제본을 사용하도록 다시 구성
Cloud Shell에서 App.config 파일을 편집합니다.
code App.configConnectionString1 및 ConnectionString2 설정에 대한 연결 문자열을 추가합니다. 해당 값은 ConnectionString0의 값과 동일해야 하지만 서버 및 사용자 ID 요소의 adventureworks[nnn] 텍스트는 adventureworks[nnn]-replica1 및 adventureworks[nnn]-replica2로 바뀌어야 합니다.
NumReplicas 설정을 3으로 설정합니다.
App.config 파일은 다음과 유사합니다.
<configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="Server=adventureworks101-replica1.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica1;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString2" value="Server=adventureworks101-replica2.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica2;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="3"/> </appSettings> </configuration>파일을 저장하고 편집기를 닫습니다.
앱 실행을 다시 시작합니다.
dotnet run애플리케이션이 전과 같이 실행됩니다. 하지만 이번에는 요청이 세 개의 서버로 분산됩니다.
앱이 몇 분 동안 실행되도록 한 다음, 계속합니다.
앱 모니터링 및 성능 메트릭의 차이 관찰
앱을 실행 중인 상태로 두고 Azure Portal로 돌아갑니다.
왼쪽 창에서 대시보드를 선택합니다.
차트를 선택하여 메트릭 창에서 엽니다.
이 차트에는 복제본이 아닌 adventureworks*[nnn]* 서버에 대한 메트릭이 표시됩니다. 각 복제본에 대한 로드는 동일해야 합니다.
차트 예제에서는 시작부터 30분 넘게 애플리케이션에 대해 수집된 메트릭을 보여 줍니다. 이 차트를 보면 CPU 사용률은 여전히 높으나 메모리 사용률은 더 낮습니다. 또한, 약 25분 후에는 시스템이 30개가 넘는 연결에 대한 연결을 설정했습니다. 이전 구성과 비교하기에 적합하지 않을 수도 있으나 이전 구성에서는 45분 후에 70개의 연결을 지원했습니다. 하지만 이제는 모두 동일한 수준에서 작동하며 101개의 연결이 모두 설정된 세 개의 서버에 워크로드가 분산되었습니다. 시스템도 연결 오류를 보고하지 않고 실행을 계속할 수 있었습니다.
CPU 사용률 이슈는 CPU 코어 수가 더 많은 더 높은 가격 책정 계층으로 스케일 업하여 해결할 수 있습니다. 이 랩에서 사용된 시스템 예제는 코어가 두 개인 기본 가격 책정 계층을 사용하여 실행됩니다. 범용 가격 책정 계층으로 변경하면 최대 64개의 코어를 제공합니다.
Cloud Shell로 돌아가서 Enter 키를 눌러 앱을 중지합니다.
이제 Azure Portal에서 제공하는 도구를 사용하여 서버 활동을 모니터링하는 방법을 알았습니다. 복제를 구성하는 방법도 배웠고, 읽기 집약적인 데이터 시나리오에서 읽기 전용 복제본을 만들어 워크로드를 분산할 수 있는 방법도 알아보았습니다.