분류 모델 평가
분류 모델의 학습 정확도보다 훨씬 중요한 것은 처음 보는 새 데이터가 제공될 때 모델이 잘 작동하는 것입니다. 모델을 학습시키는 근본적인 목적은 현실에서 찾은 새 데이터에 사용할 수 있도록 만드는 것입니다. 따라서 분류 모델을 학습시킨 후에는 처음 보는 새 데이터 세트에서 분류 모델이 어떻게 수행되는지 평가할 것입니다.
이전 단원에서는 환자의 혈당 수치를 기준으로 당뇨병 여부를 예측하는 모델을 만들었습니다. 이번에는 학습 집합에 없는 데이터에 모델을 적용하면 다음과 같은 예측 값을 얻을 수 있습니다.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
x는 혈당 수치를 나타내고, y는 환자에게 실제로 당뇨병이 있는지 여부를 나타내고, ŷ는 환자의 당뇨병 여부에 대한 모델의 예측 값을 나타냅니다.
적중한 예측 건수를 계산하는 것만으로는 해석이 잘못되거나 너무 단순해서 현실에서 발생할 오류의 종류를 이해하지 못할 수 있습니다. 다음과 같이 결과를 오차 행렬이라는 구조의 테이블 형식으로 만들면 보다 구체적인 정보를 얻을 수 있습니다.
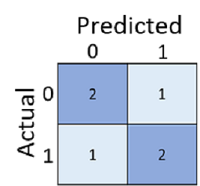
오차 행렬은 다음과 같은 경우의 총 사례 수를 보여 줍니다.
- 모델은 0을 예측했고 실제 레이블은 0입니다(진음성, 왼쪽 상단).
- 모델은 1을 예측했고 실제 레이블은 1입니다(진양성, 오른쪽 하단).
- 모델은 0을 예측했고 실제 레이블은 1입니다(가음성, 왼쪽 하단).
- 모델은 1을 예측했고 실제 레이블은 0입니다(가양성, 오른쪽 상단).
오차 행렬의 셀은 종종 음영 처리되며 값이 높을수록 음영이 짙어집니다. 이렇게 하면 왼쪽 상단에서 오른쪽 하단으로 이어지는 강력한 대각선 추세를 쉽게 확인할 수 있으며 예측 값과 실제 값이 동일한 셀을 강조 표시합니다.
이 핵심 값에서 모델의 성능을 평가하는 데 도움이 될 수 있는 다른 메트릭의 범위를 계산할 수 있습니다. 예를 들면 다음과 같습니다.
- 정확도: (TP+TN)/(TP+TN+FP+FN) - 모든 예측 중 몇 개가 적중했나요?
- 재현율: TP/(TP+FN) - 양성 사례 중 모델이 식별한 사례는 몇 개인가요?
- 정밀도: TP/(TP+FP) - 모델이 양성일 것으로 예측한 사례 중 실제로 양성인 사례는 몇 개인가요?