XMLA 엔드포인트 연결 문제 해결
Power BI의 XMLA 엔드포인트는 Power BI 의미 체계 모델에 액세스하기 위해 네이티브 Analysis Services 통신 프로토콜을 사용합니다. 이로 인해 XMLA 엔드포인트 문제 해결은 일반적인 Analysis Services 연결 문제를 해결하는 것과 거의 같습니다. 그러나 Power BI 관련 종속성에서 일부 차이점이 있습니다.
시작하기 전에
XMLA 엔드포인트 시나리오의 문제를 해결하기 전에 XMLA 엔드포인트를 사용한 의미 체계 모델 연결에 설명된 기본 사항을 검토해야 합니다. 가장 일반적인 XMLA 엔드포인트 사용 사례가 설명되어 있기 때문입니다. 게이트웨이 문제 해결 - Power BI 및 Excel에서 분석 문제 해결과 같은 다른 Power BI 문제 해결 가이드도 도움이 될 수 있습니다.
XMLA 엔드포인트 사용
XMLA 엔드포인트는 Power BI Premium, 사용자 단위 Premium, Power BI Embedded 용량에서 사용하도록 설정할 수 있습니다. 2.5GB 메모리를 사용하는 A1 용량과 같이 더 작은 용량에서는 XMLA 엔드포인트를 읽기/쓰기로 설정하고 적용을 선택하려고 하면 용량 설정 오류가 발생할 수 있습니다. 오류는 "워크로드 설정에 문제가 있습니다. 잠시 후에 다시 시도하세요."입니다.
시도해 볼 수 있는 작업은 다음과 같습니다.
- 데이터 흐름 등 다른 서비스에 대한 메모리 소비를 40% 이하로 제한하거나 불필요한 서비스를 완전히 사용하지 않도록 설정합니다.
- 용량을 더 큰 SKU로 업그레이드합니다. 예를 들어 A1에서 A3 용량으로 업그레이드하면 데이터 흐름을 사용하지 않도록 설정하지 않고도 이 구성 문제를 해결할 수 있습니다.
또한 Power BI 관리 포털에서 테넌트 수준 데이터 내보내기 설정을 사용하도록 설정해야 합니다. 이 설정은 Excel에서 분석 기능에도 필요합니다.
클라이언트 연결 설정
XMLA 엔드포인트를 사용하도록 설정한 후에는 용량에서 작업 영역에 대한 연결을 테스트하는 것이 좋습니다. 자세한 내용은 프리미엄 작업 영역에 연결을 참조하세요. 또한 현재 XMLA 연결 제한 사항에 대한 유용한 팁과 정보는 연결 요구 사항 섹션을 참조하세요.
서비스 주체로 연결
테넌트 설정에서 서비스 주체가 Power BI API를 사용할 수 있도록 설정한 경우 서비스 주체 사용에 설명된 대로 서비스 주체를 사용하여 XMLA 엔드포인트에 연결할 수 있습니다. 서비스 주체에는 작업 영역 또는 의미 체계 모델 수준에서 일반 사용자와 동일한 수준의 액세스 권한이 필요합니다.
서비스 주체를 사용하려면 연결 문자열에서 다음과 같이 애플리케이션 ID 정보를 지정해야 합니다.
User ID=<app:appid@tenantid>Password=<application secret>
예시:
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:91ab91bb-6b32-4f6d-8bbc-97a0f9f8906b@19373176-316e-4dc7-834c-328902628ad4;Password=6drX...;
다음과 같은 오류 메시지가 나타나는 경우:
"계정 정보가 불완전하기 때문에 의미 체계 모델에 연결할 수 없습니다. 서비스 주체의 경우 <appId>@<tenantId> 형식을 사용하여 앱 ID와 함께 테넌트 ID를 지정한 후 다시 시도하세요.”
올바른 형식을 사용하여 앱 ID와 함께 테넌트 ID를 지정해야 합니다.
테넌트 ID 없이 앱 ID를 지정하는 것도 유효합니다. 그러나 이 경우 데이터 원본 URL의 myorg 별칭을 실제 테넌트 ID로 바꾸어야 합니다. 그러면 Power BI가 올바른 테넌트에서 서비스 주체를 찾을 수 있습니다. 하지만 모범 사례로 myorg 별칭을 사용하고 사용자 ID 매개 변수에 앱 ID와 함께 테넌트 ID를 지정합니다.
Microsoft Entra B2B를 사용하여 커넥트
Power BI에서 Microsoft Entra B2B(Business-to-Business)를 지원하면 외부 게스트 사용자에게 XMLA 엔드포인트를 통해 의미 체계 모델에 대한 액세스 권한을 제공할 수 있습니다. Power BI 관리 포털에서 외부 사용자와 콘텐츠 공유 설정이 사용하도록 설정되어 있는지 확인합니다. 자세한 내용은 Microsoft Entra B2B를 사용하여 외부 게스트 사용자에게 Power BI 콘텐츠 배포를 참조하세요.
의미 체계 모델 배포
Visual Studio(SSDT)의 테이블 형식 모델 프로젝트를 프리미엄 용량에 할당된 작업 영역에 배포할 수 있습니다. 방법은 Azure Analysis Services의 서버 리소스에 배포하는 것과 거의 비슷합니다. 그러나 이 작업 영역에 배포하는 경우 몇 가지 추가 고려 사항이 있습니다. XMLA 엔드포인트를 사용하여 의미 체계 모델 연결 문서의 Visual Studio에서 모델 프로젝트 배포(SSDT) 섹션을 검토해야 합니다.
새 모델 배포
기본 구성에서 Visual Studio는 데이터 원본에서 의미 체계 모델로 데이터를 로드하는 배포 작업의 일부로 모델을 처리하려고 합니다. Visual Studio에서 모델 프로젝트 배포(SSDT)에 설명된 것처럼, 배포 작업의 일부로 데이터 원본 자격 증명을 지정할 수 없기 때문에 이 작업이 실패할 수 있습니다. 대신, 데이터 원본에 대한 자격 증명이 아직 기존 의미 체계 모델에 대해 정의되지 않은 경우 Power BI 사용자 인터페이스를 사용하여 의미 체계 모델 설정에서 데이터 원본 자격 증명을 지정해야 합니다(의미 체계 모델>설정>데이터 원본 자격 증명>자격 증명 편집). 데이터 원본 자격 증명을 정의하면 Power BI가 메타데이터 배포에 성공하고 의미 체계 모델을 만든 후 모든 새 의미 체계 모델에 대해 자동으로 이 데이터 원본에 대한 자격 증명을 적용할 수 있습니다.
Power BI가 새 의미 체계 모델을 데이터 원본 자격 증명에 바인딩할 수 없는 경우 아래와 같이 "데이터베이스를 처리할 수 없습니다. 이유: 수정 내용을 서버에 저장하지 못했습니다.”라는 오류가 오류 코드 “DMTS_DatasourceHasNoCredentialError”와 함께 표시됩니다.
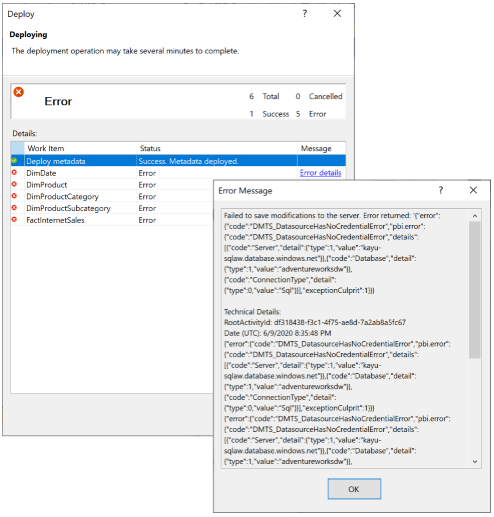
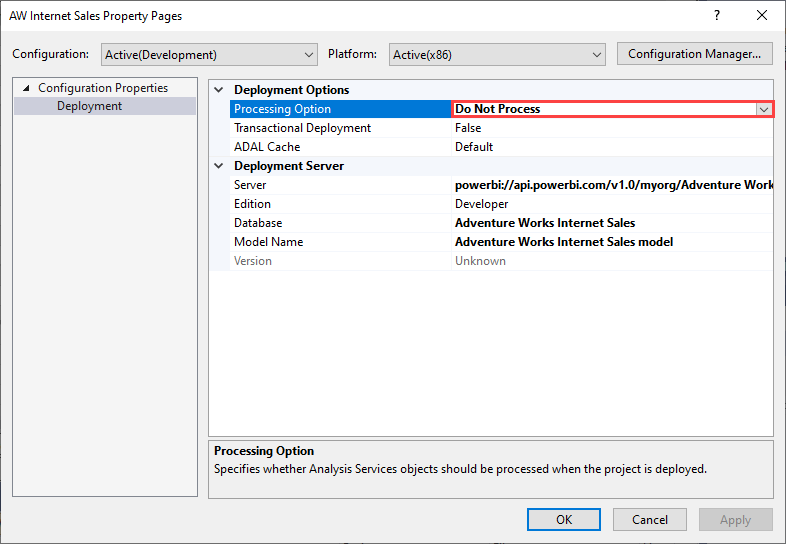
처리 실패를 방지하려면 다음 그림에 표시된 것처럼 배포 옵션>처리 옵션을 처리 안 함으로 설정합니다. 그러면 Visual Studio에서 메타데이터만 배포합니다. 그런 다음, 데이터 원본 자격 증명을 구성하고 Power BI 사용자 인터페이스의 의미 체계 모델에 대해 지금 새로 고침을 클릭할 수 있습니다.
기존 의미 체계 모델의 새 프로젝트
기존 의미 체계 모델에서 메타데이터를 가져와서 Visual Studio에 새 테이블 형식 프로젝트를 만들 수는 없습니다. 그러나 SQL Server Management Studio를 사용하여 의미 체계 모델에 연결하고 메타데이터를 스크립팅한 다음, 다른 테이블 형식 프로젝트에서 다시 사용할 수 있습니다.
의미 체계 모델을 Power BI로 마이그레이션
테이블 형식 모델에 대해 호환성 수준을 1500 이상으로 지정하는 것이 좋습니다. 이 호환성 수준은 대부분의 기능과 데이터 원본 유형을 지원합니다. 이후 호환성 수준은 이전 수준과 호환됩니다.
지원되는 데이터 공급자
1500 호환성 수준에서 Power BI는 다음과 같은 데이터 원본 유형을 지원합니다.
- 공급자 데이터 원본(모델 메타데이터에 연결 문자열이 있는 레거시)
- 구조적 데이터 원본(1400 호환성 수준에서 도입됨)
- 데이터 원본의 인라인 M 선언(Power BI Desktop의 선언을 따름)
데이터 가져오기 흐름을 진행하는 경우 Visual Studio에서 기본적으로 만드는 구조적 데이터 원본을 사용하는 것이 좋습니다. 그러나 공급자 데이터 원본을 사용하는 기존 모델을 Power BI로 마이그레이션하려는 경우 공급자 데이터 원본이 지원되는 데이터 공급자를 사용하는지 확인합니다. 특히 Microsoft OLE DB Driver for SQL Server 및 타사 ODBC 드라이버가 있습니다. OLE DB Driver for SQL Server의 경우 데이터 원본 정의를 .NET Framework Data Provider for SQL Server로 전환해야 합니다. Power BI 서비스에서 사용할 수 없는 타사 ODBC 드라이버의 경우 구조적 데이터 원본 정의로 전환해야 합니다.
또한 SQL Server 데이터 원본 정의에서 오래된 Microsoft OLE DB Driver for SQL Server(SQLNCLI11)를 .NET Framework Data Provider for SQL Server로 바꾸는 것이 좋습니다.
다음 표에는 .NET Framework Data Provider for SQL Server 연결 문자열이 OLE DB Driver for SQL Server에 해당하는 연결 문자열을 대체하는 예제가 나와 있습니다.
| SQL Server용 OLE DB 드라이버 | .NET Framework Data Provider for SQL Server |
|---|---|
Provider=SQLNCLI11;Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW;Trusted_Connection=yes; |
Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW2016;Integrated Security=SSPI;Encrypt=true;TrustServerCertificate=false |
파티션 원본 상호 참조
데이터 원본 유형이 여러 개인 것과 마찬가지로 한 테이블 형식 모델이 테이블에 데이터를 가져오기 위해 포함할 수 있는 파티션 원본 유형도 여러 개입니다. 특히 파티션은 쿼리 파티션 원본 또는 M 파티션 원본을 사용할 수 있습니다. 이러한 파티션 원본 유형은 공급자 데이터 원본 또는 구조적 데이터 원본을 참조할 수 있습니다. Azure Analysis Services의 테이블 형식 모델은 이러한 다양한 데이터 원본 및 파티션 유형을 상호 참조하는 것을 지원하지만 Power BI는 보다 엄격한 관계를 적용합니다. 쿼리 파티션 원본은 공급자 데이터 원본을 참조해야 하고, M 파티션 원본은 구조적 데이터 원본을 참조해야 합니다. 다른 조합은 Power BI에서 지원되지 않습니다. 상호 참조하는 의미 체계 모델을 마이그레이션하는 경우 다음 표에서 지원되는 구성이 설명되어 있습니다.
| 데이터 원본 | 파티션 원본 | 설명 | XMLA 엔드포인트로 지원 |
|---|---|---|---|
| 공급자 데이터 원본 | 쿼리 파티션 원본 | AS 엔진은 카트리지 기반 연결 스택을 사용하여 데이터 원본에 액세스합니다. | 예 |
| 공급자 데이터 원본 | M 파티션 원본 | AS 엔진은 공급자 데이터 원본을 일반 구조적 데이터 원본으로 변환한 다음 매시업 엔진을 사용하여 데이터를 가져옵니다. | 아니요 |
| 구조적 데이터 동기화 | 쿼리 파티션 원본 | AS 엔진은 파티션 원본에 대한 기본 쿼리를 M 식으로 래핑한 다음 매시업 엔진을 사용하여 데이터를 가져옵니다. | 아니요 |
| 구조적 데이터 동기화 | M 파티션 원본 | AS 엔진은 매시업 엔진을 사용하여 데이터를 가져옵니다. | 예 |
데이터 원본 및 가장
공급자 데이터 원본에 대해 정의할 수 있는 가장 설정은 Power BI와 관련이 없습니다. Power BI는 의미 체계 모델 설정에 따라 다른 메커니즘을 사용하여 데이터 원본 자격 증명을 관리합니다. 따라서 공급자 데이터 원본을 만드는 경우 서비스 계정을 선택해야 합니다.
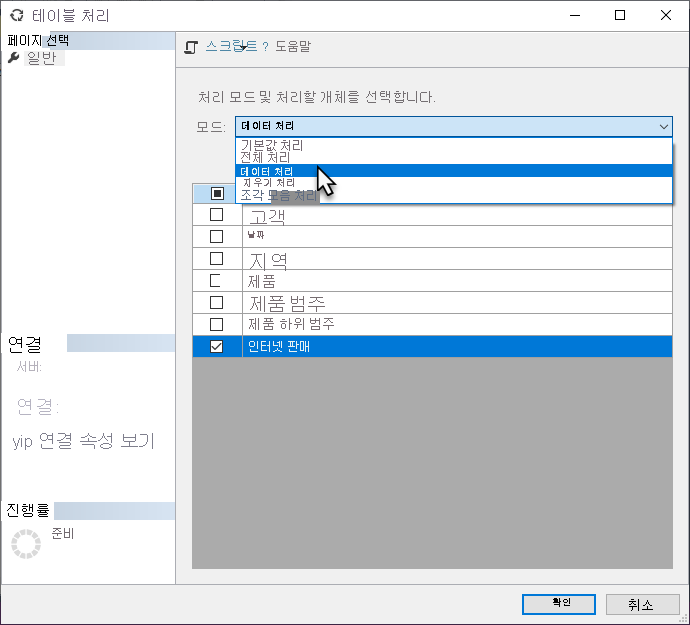
세분화된 처리
Power BI에서 예약된 새로 고침 또는 요청 시 새로 고침을 트리거하는 경우 Power BI는 일반적으로 전체 의미 체계 모델을 새로 고칩니다. 대부분의 경우 더 선택적으로 새로 고침을 수행하는 것이 더 효율적입니다. 아래와 같이 SSMS(SQL Server Management Studio)에서 세분화된 처리 작업을 수행하거나 타사 도구 또는 스크립트를 사용할 수 있습니다.
Refresh TMSL 명령의 재정의
명령(TMSL)의 재정의를 통해 사용자는 새로 고침 작업의 다른 파티션 쿼리 정의 또는 데이터 원본 정의를 선택할 수 있습니다.
메일 구독
XMLA 엔드포인트를 사용하여 새로 고쳐진 의미 체계 모델은 이메일 구독을 트리거하지 않습니다.
프리미엄 용량의 오류
SSMS의 서버에 연결 오류
SSMS(SQL Server Management Studio)를 사용하여 Power BI 작업 영역에 연결할 때 다음 오류가 표시될 수 있습니다.
TITLE: Connect to Server
------------------------------
Cannot connect to powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name].
------------------------------
ADDITIONAL INFORMATION:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId:
Date (UTC): 10/6/2021 1:03:25 AM (Microsoft.AnalysisServices.AdomdClient)
------------------------------
The remote server returned an error: (400) Bad Request. (System)
SSMS를 사용하여 Power BI 작업 영역에 연결할 때 다음을 확인합니다.
- 테넌트의 용량에 대해 XMLA 엔드포인트 설정이 사용하도록 설정되어 있습니다. 자세히 알아보려면 XMLA 읽기/쓰기를 사용하도록 설정을 참조하세요.
- 테넌트 설정에서 온-프레미스 의미 체계 모델을 사용하여 XMLA 엔드포인트 및 Excel에서 분석 허용 설정이 사용하도록 설정되어 있습니다.
- 최신 버전의 SSMS를 사용하고 있습니다. 최신 버전 다운로드.
SSMS에서 쿼리 실행
Power BI Premium 또는 Power BI Embedded 용량의 작업 영역에 연결된 경우 SQL Server Management Studio에 다음 오류가 표시될 수 있습니다.
Executing the query ...
Error -1052311437: We had to move the session with ID '<Session ID>' to another Power BI Premium node. Moving the session temporarily interrupted this trace - tracing will resume automatically as soon as the session has been fully moved to the new node.
클라이언트 라이브러리는 자동으로 다시 연결되므로 이 메시지는 SSMS 18.8 이상에서 무시해도 되는 정보 메시지입니다. SSMS v18.7.1 또는 이전 버전에서 함께 설치되는 클라이언트 라이브러리는 세션 추적을 지원하지 않습니다. 최신 SSMS를 다운로드하세요.
XMLA 엔드포인트를 사용하여 큰 명령 실행
XMLA 엔드포인트를 사용하여 큰 명령을 실행할 때 다음 오류가 발생할 수 있습니다.
Executing the query ...
Error -1052311437:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId: 3716c0f7-3d01-4595-8061-e6b2bd9f3428
Date (UTC): 11/13/2020 7:57:16 PM
Run complete
SSMS v18.7.1 이하를 사용하여 Power BI Premium 또는 Power BI Embedded 용량의 의미 체계 모델에서 장기 실행(>1분) 새로 고침 작업을 수행하는 경우 새로 고침 작업이 성공하더라도 이 오류가 표시될 수 있습니다. 이는 새로 고침 요청의 상태가 올바르지 않게 추적되는 클라이언트 라이브러리의 알려진 문제 때문입니다. SSMS 18.8 이상에서 해결되었습니다. 최신 SSMS를 다운로드하세요.
이 오류는 매우 큰 요청을 프리미엄 클러스터의 다른 노드로 리디렉션해야 하는 경우에도 발생할 수 있습니다. 대용량 TMSL 스크립트를 사용하여 의미 체계 모델을 만들거나 변경하려고 할 때 표시되는 경우가 많습니다. 이러한 경우 명령을 실행하기 전에 데이터베이스 이름에 초기 카탈로그를 지정하면 대개 오류를 방지할 수 있습니다.
새 데이터베이스를 만들 때 빈 의미 체계 모델을 만들 수 있습니다. 예를 들면 다음과 같습니다.
{
"create": {
"database": {
"name": "DatabaseName"
}
}
}
새 의미 체계 모델을 만든 후 초기 카탈로그를 지정한 다음, 의미 체계 모델을 변경합니다.
기타 클라이언트 애플리케이션 및 도구
Excel, Power BI Desktop, SSMS 또는 Power BI Premium 용량의 데이터 세트에 연결되고 이러한 의미 체계 모델에서 작동하는 외부 도구 등의 클라이언트 애플리케이션/도구는 다음과 같은 오류를 발생시킬 수 있습니다. 원격 서버에서 오류를 반환했습니다. (400) 잘못된 요청. 특히 기본 DAX 쿼리 또는 XMLA 명령이 장기 실행되는 경우 이 오류가 발생할 수 있습니다. 잠재적 오류를 완화하려면 정기적인 업데이트와 함께 최신 버전의 Analysis Services 클라이언트 라이브러리의 최신 버전을 설치하는 최신 애플리케이션 및 도구를 사용해야 합니다. 애플리케이션 또는 도구에 관계없이 XMLA 엔드포인트를 통해 Premium 용량의 데이터 세트에 연결하고 해당 의미 체계 모델로 작업하는 데 필요한 최소 클라이언트 라이브러리 버전은 다음과 같습니다.
| 클라이언트 라이브러리 | 버전 |
|---|---|
| MSOLAP | 15.1.65.22 |
| AMO | 19.12.7.0 |
| ADOMD | 19.12.7.0 |
SSMS에서 역할 멤버 자격 편집
SSMS(SQL Server Management Studio) v18.8을 사용하여 의미 체계 모델에 대한 역할 멤버 자격을 편집하는 경우 SSMS에서 다음 오류를 표시할 수 있습니다.
Failed to save modifications to the server.
Error returned: ‘Metadata change of current operation cannot be resolved, please check the command or try again later.’
App Services REST API의 알려진 문제 때문입니다. 이 문제는 향후 릴리스에서 해결될 예정입니다. 당분간은 이 오류를 해결하려면 역할 속성에서 스크립트를 클릭하고 다음 TMSL 명령을 입력한 후 실행합니다.
{
"createOrReplace": {
"object": {
"database": "AdventureWorks",
"role": "Role"
},
"role": {
"name": "Role",
"modelPermission": "read",
"members": [
{
"memberName": "xxxx",
"identityProvider": "AzureAD"
},
{
"memberName": “xxxx”
"identityProvider": "AzureAD"
}
]
}
}
}
게시 오류 - 라이브 연결된 의미 체계 모델
Analysis Services 커넥터를 사용하여 라이브 연결된 의미 체계 모델을 다시 게시할 때 다음과 같은 오류가 발생합니다. "동일한 이름의 기존 보고서/의미 체계 모델이 있습니다. 기존 의미 체계 모델을 삭제하거나 이름을 바꾸고 다시 시도하세요."가 표시될 수 있습니다.

이는 다른 연결 문자열이 있지만 기존 의미 체계 모델과 이름이 같은 의미 체계 모델이 게시되기 때문입니다. 이 문제를 해결하려면 기존 의미 체계 모델을 삭제하거나 이름을 바꿉니다. 또한 보고서에 종속된 모든 앱을 다시 게시해야 합니다. 필요한 경우 다운스트림 사용자가 최신 보고서에 액세스할 수 있도록 하기 위해 새 보고서 주소로 책갈피를 업데이트하라는 알림이 표시되는 것이 좋습니다.
작업 영역/서버 별칭
프리미엄 작업 영역에서는 Azure Analysis Services와 달리 서버 이름 별칭이 지원되지 않습니다.
DISCOVER_M_EXPRESSIONS
DMV DISCOVER_M_EXPRESSIONS 데이터 관리 보기(DMV)는 XMLA 엔드포인트를 사용하는 Power BI에서 현재 지원되지 않습니다. 애플리케이션에서는 TOM(테이블 형식 개체 모델)을 사용하여 데이터 모델에서 사용되는 M 식을 가져올 수 있습니다.
프리미엄의 리소스 관리 명령 메모리 한도
프리미엄 용량에서는 리소스 관리를 사용하여 단일 의미 체계 모델 작업이 용량에 사용 가능한 메모리 리소스의 양(SKU에 의해 결정)을 초과하지 않도록 합니다. 예를 들어 P1 구독은 항목당 유효 메모리 한도가 25GB이고, P2 구독은 한도가 50GB이고, P3 구독은 한도가 100GB입니다. 의미 체계 모델(데이터베이스) 크기 외에 유효 메모리 한도도 Create, Alter, Refresh 등의 기본 의미 체계 모델 명령 작업에 적용됩니다.
명령의 유효 메모리 한도는 용량의 메모리 한도(SKU에 의해 결정) 또는 DbpropMsmdRequestMemoryLimit XMLA 속성 값 중 더 적은 값을 기준으로 합니다.
예를 들어 P1 용량의 경우 다음과 같습니다.
DbpropMsmdRequestMemoryLimit가 0이거나 지정되지 않은 경우 명령의 유효 메모리 한도는 25GB입니다.
DbpropMsmdRequestMemoryLimit가 5GB이면 명령의 유효 메모리 한도는 5GB입니다.
DbpropMsmdRequestMemoryLimit가 50GB이면 명령의 유효 메모리 한도는 25GB입니다.
일반적으로 명령의 유효 메모리 한도는 용량에서 의미 체계 모델에 허용하는 메모리(25GB, 50GB, 100GB)와 명령 실행이 시작될 때 의미 체계 모델에서 이미 사용하고 있는 메모리양에 따라 계산됩니다. 예를 들어 P1 용량의 12GB를 사용 중인 의미 체계 모델에서는 새 명령의 유효 메모리 한도(13GB)를 허용합니다. 그러나 애플리케이션에서 선택적으로 지정하는 DbPropMsmdRequestMemoryLimit XMLA 속성으로 유효 메모리 한도가 추가로 제한될 수 있습니다. 앞의 예제를 사용하면 DbPropMsmdRequestMemoryLimit 속성에 10GB를 지정하는 경우 명령의 유효 한도가 10GB로 더 줄어듭니다.
명령 작업에서 한도에 따라 허용되는 메모리보다 더 많이 사용하려고 하면 작업이 실패할 수 있고 오류가 반환됩니다. 예를 들어 다음 오류는 명령 실행이 시작될 때 의미 체계 모델에서 이미 12GB(12288MB)를 사용했고 명령 작업에 유효 한도 13GB(13312MB)가 적용되었으므로 유효 메모리 한도인 25GB(P1 용량)가 초과되었음을 나타냅니다.
“리소스 관리: 메모리가 부족하여 실행을 완료할 수 없기 때문에 이 작업이 취소되었습니다. 가져온 데이터의 양을 제한하는 등의 작업을 수행하여 이 의미 체계 모델이 호스트되는 프리미엄 용량의 메모리를 늘리거나 의미 체계 모델의 메모리 사용 공간을 줄입니다. 추가 세부 정보: 사용된 메모리 13312MB, 메모리 제한 13312MB, 명령 실행 전 데이터베이스 크기 12288MB 자세한 정보: https://go.microsoft.com/fwlink/?linkid=2159753”
경우에 따라 다음 오류와 같이 “사용되는 메모리”가 0이지만 “명령 실행 전 데이터베이스 크기”에 표시된 양이 이미 유효 메모리 한도보다 큽니다. 이는 의미 체계 모델에서 이미 사용하는 메모리양이 SKU의 메모리 한도보다 커서 작업 실행을 시작하지 못했음을 의미합니다.
“리소스 관리: 메모리가 부족하여 실행을 완료할 수 없기 때문에 이 작업이 취소되었습니다. 가져온 데이터의 양을 제한하는 등의 작업을 수행하여 이 의미 체계 모델이 호스트되는 프리미엄 용량의 메모리를 늘리거나 의미 체계 모델의 메모리 사용 공간을 줄입니다. 추가 세부 정보: 사용된 메모리 0MB, 메모리 제한 25600MB, 명령 실행 전 데이터베이스 크기 26000MB 자세한 정보: https://go.microsoft.com/fwlink/?linkid=2159753”
유효 메모리 제한을 초과하지 않도록 하려면 다음을 수행합니다.
- 의미 체계 모델에 대해 더 큰 프리미엄 용량(SKU) 크기로 업그레이드합니다.
- 각 새로 고침으로 로드되는 데이터양을 제한하여 의미 체계 모델의 메모리 공간을 줄입니다.
- XMLA 엔드포인트를 통한 새로 고침 작업의 경우 병렬로 처리되는 파티션 수를 줄입니다. 단일 명령을 사용하여 너무 많은 파티션을 병렬로 실행하면 유효 메모리 한도를 초과할 수 있습니다.
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기