SQL Server 빅 데이터 클러스터의 데이터 풀 소개
적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
이 문서에서는 SQL Server 빅 데이터 클러스터에서 SQL Server 데이터 풀의 역할을 설명합니다. 다음 섹션에서는 데이터 풀의 아키텍처, 기능, 사용 시나리오에 대해 설명합니다.
5분 분량의 다음 동영상에서는 데이터 풀을 소개하고 데이터 풀에서 데이터를 쿼리하는 방법을 보여 줍니다.
데이터 풀 아키텍처
데이터 풀은 클러스터에 대한 영구 SQL Server 스토리지를 제공하는 하나 이상의 SQL Server 데이터 풀 인스턴스로 구성됩니다. 외부 데이터 원본에 대해 캐시된 데이터의 쿼리와 작업 오프로딩의 성능을 높일 수 있습니다. 데이터는 T-SQL 쿼리를 사용하거나 Spark 작업을 통해 데이터 풀에 수집됩니다. 큰 데이터 집합에서 성능을 향상시키기 위해, 수집된 데이터는 분할된 데이터베이스에 배포되고 풀의 모든 SQL Server 인스턴스에 저장됩니다. 지원되는 배포 방법은 라운드 로빈 및 복제입니다. 읽기 액세스 최적화를 위해 클러스터된 columnstore 인덱스가 각 데이터 풀 인스턴스의 각 테이블에 만들어집니다. 데이터 풀은 SQL Server 빅 데이터 클러스터에 대한 스케일 아웃 데이터 마트 역할을 합니다.
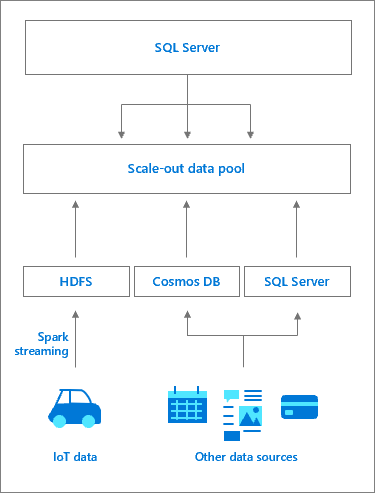
데이터 풀의 SQL Server 인스턴스에 대한 액세스는 SQL Server 마스터 인스턴스에서 관리합니다. 데이터 풀에 대한 외부 데이터 원본이 데이터 캐시를 저장하는 PolyBase 외부 테이블과 함께 만들어집니다. 백그라운드에서 컨트롤러는 외부 테이블과 일치하는 테이블을 사용하여 데이터 풀에 데이터베이스를 만듭니다. SQL Server 마스터 인스턴스에서 워크플로는 투명합니다. 컨트롤러에서 특정 외부 테이블 요청을 데이터 풀의 SQL Server 인스턴스로 리디렉션하고(컴퓨팅 풀을 통해 리디렉션될 수 있음), 쿼리를 실행하며, 결과 집합을 반환합니다. 데이터 풀의 데이터는 수집 또는 쿼리만 할 수 있으며 수정할 수 없습니다. 따라서 모든 데이터 새로 고침에는 테이블 삭제가 필요하며, 그 이후에는 테이블을 다시 작성하고 추후 데이터를 다시 채워야 합니다.
데이터 풀 시나리오
보고 용도는 일반적인 데이터 풀 시나리오입니다. 예를 들어 주간 보고서에 사용되는 여러 PolyBase 데이터 원본을 조인하는 복잡한 쿼리를 데이터 풀로 오프로딩할 수 있습니다. 캐시된 데이터는 빠른 로컬 컴퓨팅을 제공하고, 원본 데이터 세트로 다시 이동할 필요가 없습니다. 마찬가지로 주기적인 새로 고침이 필요한 대시보드 데이터는 최적화된 보고를 위해 데이터 풀에 캐시될 수 있습니다. Machine Learning 반복 탐색은 데이터 풀에서 데이터 세트의 캐싱을 활용할 수도 있습니다.
다음 단계
SQL Server 빅 데이터 클러스터에 대한 자세한 내용은 다음 리소스를 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기