Windows 및 Linux에서 SQL Server Always On 가용성 그룹 구성(플랫폼 간)
적용 대상:![]() SQL Server 2017(14.x) 이상
SQL Server 2017(14.x) 이상
이 문서에서는 Windows Server의 복제본 1개와 Linux 서버의 복제본 1개를 사용하여 Always On AG(가용성 그룹)를 만드는 단계를 설명합니다.
중요
완전한 고가용성 및 재해 복구 지원이 있는 다른 유형의 복제본을 포함하는 플랫폼 간 가용성 그룹을 SQL Server DH2i DxEnterprise에서 사용할 수 있습니다. 자세한 내용은 혼합 운영 체제를 사용하는 가용성 그룹 SQL Server를 참조하세요.
DH2i를 사용하여 플랫폼 간 가용성 그룹에 대해 알아보려면 다음 비디오를 참조하세요.
복제본이 서로 다른 운영 체제에 있기 때문에 이 구성은 플랫폼 간에 지원됩니다. 한 플랫폼에서 다른 플랫폼으로 마이그레이션하거나 DR(재해 복구)하려는 경우 이 구성을 사용합니다. 이 구성은 고가용성을 지원하지 않습니다.
계속 진행하기 전에 Windows 및 Linux의 SQL Server 인스턴스 설치 및 구성을 잘 알고 있어야 합니다.
시나리오
이 시나리오에서는 두 서버가 서로 다른 운영 체제에 있습니다. 이름이 WinSQLInstance인 Windows Server 2022에서 주 복제본을 호스트합니다. LinuxSQLInstance라는 Linux 서버는 보조 복제본을 호스트합니다.
AG 구성
AG를 만드는 단계는 읽기 확장 워크로드를 위한 AG를 만드는 단계와 동일합니다. 클러스터 관리자가 없기 때문에 AG 클러스터 유형은 NONE입니다.
참고 항목
이 문서의 스크립트에서 꺾쇠괄호 < 및 >는 해당 환경에 맞게 바꾸어야 하는 값을 식별합니다. 스크립트에는 꺾쇠 괄호 자체가 필요하지 않습니다.
Windows Server 2022에서 SQL Server 2022(16.x)를 설치하고 SQL Server 구성 관리자에서 Always On 가용성 그룹을 사용하도록 설정한 다음, 혼합 모드 인증을 설정합니다.
팁
Azure에서 이 솔루션의 유효성을 검사하는 경우 두 서버를 동일한 가용성 집합에 배치하여 데이터 센터에서 분리되도록 합니다.
가용성 그룹 사용
자세한 내용은 Always On 가용성 그룹 사용 및 사용 안 함(SQL Server)을 참조하세요.
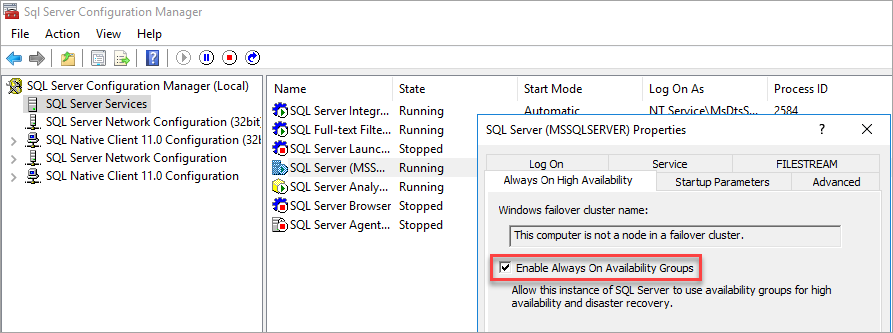
SQL Server 구성 관리자에서 컴퓨터가 장애 조치(failover) 클러스터의 노드가 아님을 확인합니다.
가용성 그룹을 사용하도록 설정한 후 SQL Server를 다시 시작합니다.
혼합 모드 인증
자세한 내용은 서버 인증 모드 변경을 참조하세요.
Linux에서 SQL Server 2022(16.x)를 설치합니다. 자세한 내용은 SQL Server 설치를 참조하세요. mssql-conf를 사용하여
hadr을 활성화합니다.셸 프롬프트에서 mssql-conf를 통해
hadr을 사용하도록 설정하려면 다음 명령을 실행합니다.sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1hadr을 사용하도록 설정한 후 SQL Server 인스턴스를 다시 시작합니다.sudo systemctl restart mssql-server.service두 서버에서 모두
hosts파일을 구성하거나 서버 이름을 DNS에 등록합니다.Windows와 Linux에서 모두 TCP 1433 및 5022의 방화벽 포트를 엽니다.
주 복제본에서 데이터베이스 로그인 및 암호를 만듭니다.
CREATE LOGIN dbm_login WITH PASSWORD = '<C0m9L3xP@55w0rd!>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO주 복제본에서 마스터 키와 인증서를 만든 다음, 프라이빗 키를 사용하여 인증서를 백업합니다.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<C0m9L3xP@55w0rd!>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<C0m9L3xP@55w0rd!>' ); GO인증서 및 프라이빗 키를 Linux 서버(보조 복제본)의
/var/opt/mssql/data에 복사합니다.pscp를 사용하여 Linux 서버에 파일을 복사할 수 있습니다.프라이빗 키와 인증서의 그룹 및 소유권을
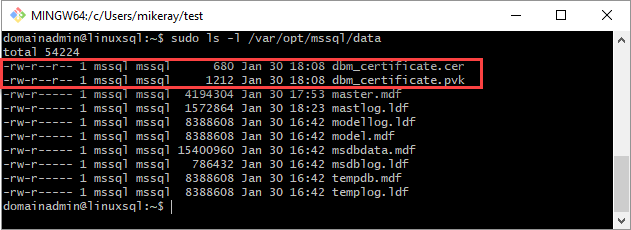
mssql:mssql로 설정합니다.다음 스크립트는 파일의 그룹 및 소유권을 설정합니다.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cer다음 다이어그램에서는 인증서 및 키의 소유권과 그룹이 올바르게 설정되었습니다.
보조 복제본에서 데이터베이스 로그인 및 암호를 만든 다음, 마스터 키를 만듭니다.
CREATE LOGIN dbm_login WITH PASSWORD = '<C0m9L3xP@55w0rd!>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<M@st3rKeyP@55w0rD!>' GO보조 복제본에서 복사한 인증서를
/var/opt/mssql/data로 복원합니다.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<C0m9L3xP@55w0rd!>' ) GO주 복제본에서 엔드포인트를 만듭니다.
CREATE ENDPOINT [Hadr_endpoint] AS TCP (LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GO중요
수신기 TCP 포트에 대해 방화벽이 열려 있어야 합니다. 위 스크립트에서 포트는 5022입니다. 사용 가능한 아무 TCP 포트나 사용합니다.
보조 복제본에서 엔드포인트를 만듭니다. 보조 복제본에서 위 스크립트를 반복하여 엔드포인트를 만듭니다.
주 복제본에서
CLUSTER_TYPE = NONE을 사용하여 AG를 만듭니다. 예제 스크립트에서는SEEDING_MODE = AUTOMATIC을 사용하여 AG를 만듭니다.참고 항목
SQL Server의 Windows 인스턴스가 데이터 및 로그 파일에 대해 다른 경로를 사용하는 경우 보조 복제본(replica) 이러한 경로가 없기 때문에 SQL Server의 Linux 인스턴스에 자동 시드가 실패합니다. 플랫폼 간 AG에 대해 다음 스크립트를 사용하려면 데이터베이스가 제대로 작동하기 위해 Windows Server의 데이터 및 로그 파일 경로가 같아야 합니다. 또는 스크립트를 업데이트하여
SEEDING_MODE = MANUAL을 설정한 다음,NORECOVERY로 데이터베이스를 백업 및 복원하여 데이터베이스를 시드할 수 있습니다.이 동작은 Azure Marketplace 이미지에 적용됩니다.
자동 시드에 대한 자세한 내용은 자동 시드 - 디스크 레이아웃을 참조하세요.
스크립트를 실행하기 전에 해당 AG의 값을 업데이트합니다.
<WinSQLInstance>를 주 복제본 SQL Server 인스턴스의 서버 이름으로 바꿉니다.<LinuxSQLInstance>를 보조 복제본 SQL Server 인스턴스의 서버 이름으로 바꿉니다.
AG를 만들려면 값을 업데이트하고 주 복제본에서 스크립트를 실행합니다.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GO자세한 내용은 CREATE AVAILABILITY GROUP(Transact-SQL)을 참조하세요.
보조 복제본에서 AG를 조인합니다.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOAG의 데이터베이스를 만듭니다. 예제 단계에서는
TestDB라는 데이터베이스를 사용합니다. 자동 시드를 사용하는 경우 데이터와 로그 파일 모두에 대해 동일한 경로를 설정합니다.스크립트를 실행하기 전에 해당 데이터베이스의 값을 업데이트합니다.
TestDB를 해당 데이터베이스의 이름으로 바꿉니다.<F:\Path>를 해당 데이터베이스 및 로그 파일의 경로로 바꿉니다. 데이터베이스 및 로그 파일에 대해 동일한 경로를 사용합니다.
기본 경로를 사용할 수도 있습니다.
데이터베이스를 만들려면 스크립트를 실행합니다.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON ( NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GO데이터베이스의 전체 백업을 수행합니다.
자동 시드를 사용하지 않는 경우 보조 복제본(Linux) 서버에서 데이터베이스를 복원합니다. 백업 및 복원을 사용하여 Windows에서 Linux로 SQL Server 데이터베이스를 마이그레이션합니다. 보조 복제본에서
WITH NORECOVERY데이터베이스를 복원합니다.AG에 데이터베이스를 추가합니다. 예제 스크립트를 업데이트합니다.
TestDB를 해당 데이터베이스의 이름으로 바꿉니다. 주 복제본에서 T-SQL 쿼리를 실행하여 AG에 데이터베이스를 추가합니다.ALTER AG [ag1] ADD DATABASE TestDB; GO데이터베이스가 보조 복제본에 채워지고 있는지 확인합니다.
주 복제본 장애 조치(failover)
각 가용성 그룹에는 하나의 주 복제본만 있습니다. 주 복제본은 읽기 및 쓰기를 허용합니다. 주 복제본을 변경하기 위해 장애 조치(failover)를 수행할 수 있습니다. 일반적인 가용성 그룹에서 클러스터 관리자는 장애 조치 프로세스를 자동화합니다. 클러스터 형식이 NONE인 가용성 그룹에서 장애 조치(failover) 프로세스는 수동입니다.
클러스터 형식이 NONE인 가용성 그룹에서 두 가지 방법으로 주 복제본을 장애 조치(failover)할 수 있습니다:
- 데이터가 손실되지 않는 수동 장애 조치(Failover)
- 데이터 손실이 있는 강제 수동 장애 조치(Failover)
데이터가 손실되지 않는 수동 장애 조치(Failover)
주 복제본을 사용할 수 있지만 주 복제본을 호스트하는 인스턴스를 일시적으로 또는 영구적으로 변경해야 하는 경우 이 방법을 사용합니다. 잠재적인 데이터 손실을 방지하려면 수동 장애 조치(failover)를 실행하기 전에 대상 보조 복제본이 최신 상태인지 확인합니다.
데이터 손실이 없는 수동 장애 조치(Failover)를 수행하려면:
현재 주 복제본 및 대상 보조 복제본을
SYNCHRONOUS_COMMIT으로 설정합니다.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);활성 트랜잭션이 주 복제본과 적어도 하나의 동기 보조 복제본에 커밋되었는지 확인하려면 다음 쿼리를 실행합니다:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;보조 복제본이
synchronization_state_desc가SYNCHRONIZED일 때 동기화됩니다.REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT을 1로 업데이트합니다.다음 스크립트에서는
ag1라는 가용성 그룹에서REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT을 1로 설정합니다. 다음 스크립트를 실행하기 전에ag1을 가용성 그룹의 이름으로 바꿉니다:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);이 설정은 모든 활성 트랜잭션이 주 복제본과 적어도 하나의 동기 보조 복제본에 커밋되었는지 확인합니다.
참고
이 설정은 장애 조치에만 적용되는 것이 아니며, 환경 요구 사항에 따라 설정해야 합니다.
주 복제본과 장애 조치(failover)에 참여하지 않는 보조 복제본을 오프라인으로 설정하여 역할 변경을 준비합니다:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINE대상 보조 복제본을 주 복제본으로 승격합니다.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;기존의 주 복제본 및 다른 보조 복제본을 호스팅하는 SQL Server 인스턴스에서 다음 명령을 실행하여 기존의 주 복제본의 역할을
SECONDARY로 업데이트합니다:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);참고
가용성 그룹 사용을 삭제하려면 DROP AVAILABILITY GROUP을 사용합니다. NONE 또는 EXTERNAL 클러스터 형식을 사용하여 만든 가용성 그룹의 경우 가용성 그룹의 일부인 모든 복제본에서 명령을 실행합니다.
데이터 이동을 계속하고, 주 복제본을 호스팅하는 SQL Server 인스턴스의 가용성 그룹에 있는 모든 데이터베이스에 대해 다음 명령을 실행합니다:
ALTER DATABASE [db1] SET HADR RESUME읽기 확장 목적으로 만들었으며 클러스터 관리자가 관리하지 않는 수신기를 다시 만듭니다. 원래 수신기가 기존 주 복제본을 가리키는 경우 이 수신기를 삭제하고 새로운 주 복제본을 가리키도록 다시 만듭니다.
데이터 손실이 있는 강제 수동 장애 조치(Failover)
주 복제본을 사용할 수 없고 즉시 복구할 수 없는 경우에는 데이터 손실이 있는 보조 복제본에 대한 장애 조치(failover)를 강제로 수행해야 합니다. 그러나 장애 조치 후 원래 주 복제본이 복구되면 주 복제본이 주 역할을 맡습니다. 각 복제본이 서로 다른 상태에 있지 않도록 하려면 데이터 손실이 있는 강제 장애 조치 후 가용성 그룹에서 원래 주 복제본을 제거합니다. 원래 주 복제본이 다시 온라인 상태가 되면 주 복제본에서 가용성 그룹을 완전히 제거합니다.
주 복제본 N1에서 보조 복제본 N2로 데이터 손실이 있는 수동 장애 조치를 강제로 수행하려면 다음 단계를 수행합니다:
보조 복제본(N2)에서 강제 장애 조치를 시작합니다:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;새 주 복제본(N2)에서 원래 주 복제본(N1)을 제거합니다:
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';모든 애플리케이션 트래픽이 수신기 및/또는 새 주 복제본을 가리키고 있는지 확인합니다.
원래 주 복제본(N1)이 온라인 상태가 되면 원래 주 복제본(N1)에서 가용성 그룹 AGRScale을 즉시 오프라인 상태로 설정합니다:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINE데이터 또는 동기화되지 않은 변경 내용이 있는 경우에는 백업을 사용하거나 비즈니스 요구 사항에 맞는 기타 데이터 복제 옵션을 사용하여 이 데이터를 보존합니다.
다음으로, 원래 주 복제본(N1)에서 가용성 그룹을 제거합니다:
DROP AVAILABILITY GROUP [AGRScale];원래 주 복제본(N1)에서 가용성 그룹 데이터베이스를 삭제합니다:
USE [master] GO DROP DATABASE [AGDBRScale] GO(선택 사항) 이제 원하는 경우 N1을 가용성 그룹 AGRScale에 새 보조 복제본으로 다시 추가할 수 있습니다.
이 문서에서는 마이그레이션 또는 읽기 확장 워크로드를 지원하기 위해 플랫폼 간 AG를 만드는 단계를 검토했습니다. 이 AG는 수동 재해 복구에 사용할 수 있습니다. AG를 장애 조치(failover)하는 방법도 설명했습니다. 플랫폼 간 AG는 NONE 클러스터 유형을 사용하며 고가용성을 지원하지 않습니다.
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기