스레드 및 작업 아키텍처 가이드
적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
운영 체제 태스크 예약
스레드는 운영 체제에서 실행되는 가장 작은 처리 단위이며 애플리케이션 논리를 여러 동시 실행 경로로 구분할 수 있습니다. 스레드는 여러 태스크를 동시에 수행할 수 있는 복잡한 애플리케이션에 유용합니다.
운영 체제가 애플리케이션의 인스턴스를 실행하는 경우 인스턴스를 관리하는 프로세스라는 단위를 만듭니다. 프로세스에 실행 스레드가 있습니다. 애플리케이션 코드에서 수행하는 일련의 프로그래밍 지침입니다. 예를 들어 간단한 애플리케이션에 직렬로 수행할 수 있는 단일 명령 집합이 있는 경우 해당 명령 집합은 단일 작업으로 처리되고 애플리케이션을 통해 하나의 실행 경로(또는 스레드)만 있습니다. 더 복잡한 애플리케이션에는 직렬로 수행하는 대신 동시에 수행할 수 있는 여러 작업이 있을 수 있습니다. 애플리케이션은 리소스를 많이 사용하는 작업인 각 태스크에 대해 별도의 프로세스를 시작하거나 리소스를 상대적으로 적게 사용하는 별도의 스레드를 시작하여 이를 수행할 수 있습니다. 또한 각 스레드는 프로세스와 연결된 다른 스레드와 독립적으로 실행을 예약할 수 있습니다.
스레드를 사용하면 단일 CPU가 있는 컴퓨터에서도 복잡한 애플리케이션이 프로세서(CPU)를 보다 효과적으로 사용할 수 있습니다. 하나의 CPU를 사용하면 한 번에 하나의 스레드만 실행할 수 있습니다. 한 스레드가 디스크 읽기 또는 쓰기와 같이 CPU를 사용하지 않는 장기 실행 작업을 실행하는 경우 첫 번째 작업이 완료될 때까지 스레드 중 하나를 실행할 수 있습니다. 다른 스레드가 작업이 끝날 때까지 기다리는 동안 스레드를 실행할 수 있으면 애플리케이션이 CPU의 사용을 최대화할 수 있습니다. 이와 같은 이점은 특히 데이터베이스 서버와 같은 여러 사용자가 사용하는 디스크 입출력 집중형 애플리케이션에서 잘 나타납니다. CPU가 여러 개인 컴퓨터는 CPU당 하나의 스레드를 동시에 실행할 수 있습니다. 예를 들어 컴퓨터에 8개의 CPU가 있는 경우 동시에 8개의 스레드를 실행할 수 있습니다.
SQL Server 작업 예약
SQL Server 범위에서 요청 은 쿼리 또는 일괄 처리의 논리적 표현입니다. 또한 요청은 검사point 또는 로그 기록기와 같은 시스템 스레드에 필요한 작업을 나타냅니다. 요청은 수명 동안 다양한 상태에 존재하며, 요청을 실행하는 데 필요한 리소스를 사용할 수 없는 경우(예: 잠금 또는 래치) 대기를 누적할 수 있습니다. 요청 상태에 대한 자세한 내용은 sys.dm_exec_requests 참조하세요.
작업
작업은 요청을 수행하기 위해 완료해야 하는 작업 단위를 나타냅니다. 하나 이상의 태스크를 단일 요청에 할당할 수 있습니다.
- 병렬 요청에는 하나의 부모 작업(또는 작업 조정) 및 여러 자식 태스크 를 사용하여 직렬로 실행되는 대신 동시에 실행되는 여러 활성 작업이 있습니다. 병렬 요청에 대한 실행 계획에는 병렬로 실행되지 않는 연산자를 사용하는 계획의 일련 분기 영역이 포함되기도 합니다. 부모 작업은 해당 직렬 연산자를 실행하는 작업도 담당합니다.
- 직렬 요청에는 실행 중에 지정된 특정 시점에 하나의 활성 작업만 있습니다. 작업은 수명 동안 다양한 상태에 존재합니다. 작업 상태에 대한 자세한 내용은 sys.dm_os_tasks 참조하세요. 작업이 일시 중단됨 상태일 경우 작업을 실행하는 데 필요한 리소스가 사용 가능해질 때까지 기다리고 있는 것입니다. 대기 태스크에 대한 자세한 내용은 sys.dm_os_waiting_tasks를 참조하세요.
작업자
작업자 또는 스레드라고도 하는 SQL Server 작업자 스레드는 운영 체제 스레드의 논리적 표현입니다. 직렬 요청을 실행할 때 SQL Server 데이터베이스 엔진 작업자를 생성하여 활성 작업(1:1)을 실행합니다. 행 모드에서 병렬 요청을 실행할 때 SQL Server 데이터베이스 엔진 부모 스레드(또는 조정 스레드)라고 하는 할당된 작업(1:1)을 완료하는 작업을 담당하는 자식 작업자를 조정하도록 작업자를 할당합니다. 부모 스레드에는 연결된 부모 작업이 있습니다. 부모 스레드는 요청의 진입점이며 엔진이 쿼리를 구문 분석하기 전에도 존재합니다. 부모 스레드의 기본 책임은 다음과 같습니다.
- 병렬 검색을 조정합니다.
- 병렬 자식 작업자를 시작합니다.
- 병렬 스레드에서 행을 수집하고 클라이언트로 보냅니다.
- 로컬 및 전역 집계를 수행합니다.
참고 항목
쿼리 계획에 직렬 및 병렬 분기가 있는 경우 병렬 작업 중 하나가 직렬 분기 실행을 담당합니다.
각 작업에 대해 생성된 작업자 스레드의 수는 다음에 따라 달라집니다.
쿼리 최적화 프로그램에서 결정한 대로 요청이 병렬 처리에 적합한지 여부입니다.
시스템의 실제 사용 가능한 병렬 처리 수준(DOP) 은 현재 부하를 기준으로 합니다. 이는 MAXDOP(최대 병렬 처리 수준)에 대한 서버 구성을 기반으로 하는 예상 DOP와 다를 수 있습니다. 예를 들어 MAXDOP에 대한 서버 구성은 8이지만 런타임에 사용 가능한 DOP는 단지 2일 수 있습니다. 이것이 쿼리 성능에 영향을 미칩니다. 메모리 압력과 작업자 부족은 런타임에 사용 가능한 DOP를 줄이는 두 가지 조건입니다.
참고 항목
MAXDOP(최대 병렬 처리 수준) 제한은 요청별이 아니라 태스크별로 설정됩니다. 즉, 병렬 쿼리를 실행하는 동안 단일 요청은 MAXDOP 제한까지 여러 작업을 생성할 수 있으며 각 태스크는 하나의 작업자를 사용합니다. MAXDOP에 대한 자세한 내용은 최대 병렬 처리 수준 서버 구성 옵션 구성을 참조하세요.
스케줄러
SOS 스케줄러라고도 하는 스케줄러는 작업을 대신하여 작업을 수행하는 데 처리 시간이 필요한 작업자 스레드를 관리합니다. 각 스케줄러는 개별 프로세서(CPU)에 매핑됩니다. 스케줄러에서 작업자가 다시 활성화될 수 기본 시간을 OS 양자라고 하며 최대 4ms입니다. 양자 시간이 만료되면 작업자는 CPU 리소스에 액세스해야 하는 다른 작업자에게 시간을 제공하고 상태를 변경합니다. CPU 리소스에 대한 액세스를 최대화하기 위한 작업자 간의 협력은 비선점적 일정이라고도 하는 협조적 일정이라고 합니다. 작업자 상태 변경은 해당 작업자와 연결된 태스크, 그리고 해당 태스크와 연결된 요청에 전파됩니다. 작업자 상태에 대한 자세한 내용은 sys.dm_os_workers 참조하세요. 스케줄러에 대한 자세한 내용은 sys.dm_os_schedulers 참조하세요.
요약하자면, 요청은 작업 단위를 수행하기 위해 하나 이상의 작업을 생성할 수 있습니다. 각 작업은 작업 완료를 담당하는 작업자 스레드 에 할당됩니다. 작업의 활성 실행을 위해 각 작업자 스레드를 스케줄러에 배치해야 합니다.
다음 시나리오를 살펴 보십시오.
- 작업자 1은 디스크 기반 테이블에 대한 미리 읽기를 사용하는 읽기 쿼리처럼 오래 실행되는 작업입니다. 작업자 1은 필요한 데이터 페이지가 버퍼 풀에 이미 있으므로 I/O 작업을 기다리기 위해 양보할 필요가 없으며 생성하기 전에 전체 양자를 사용할 수 있습니다.
- 작업자 2는 밀리초 미만의 짧은 작업을 수행하므로 전체 양자가 소진되기 전에 산출해야 합니다.
이 시나리오와 SQL Server 2014(12.x)까지 작업자 1은 기본적으로 전체 양자 시간을 더 많이 사용하여 스케줄러를 독점할 수 있습니다.
SQL Server 2016(13.x)부터 협력 일정에는 LDF(대규모 적자 우선) 일정이 포함됩니다. LDF 예약을 사용하면 양자 사용 패턴이 모니터링되고 하나의 작업자 스레드가 스케줄러를 독점하지 않습니다. 동일한 시나리오에서 작업자 2는 작업자 1이 더 많은 양자를 허용하기 전에 반복 양자를 사용할 수 있으므로 작업자 1이 비우호적인 패턴으로 스케줄러를 독점하지 못하게 합니다.
병렬 작업 일정
MaxDOP 8로 구성된 SQL Server와 NUMA 노드 0 및 1에서 CPU 선호도가 24 CPU(스케줄러)에 대해 구성되어 있다고 상상해 보세요. 스케줄러 0~11은 NUMA 노드 0에 속하며, 스케줄러 12~23은 NUMA 노드 1에 속합니다. 애플리케이션은 다음 쿼리(요청)를 데이터베이스 엔진 보냅니다.
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
팁
예제 쿼리는 AdventureWorks2016_EXT 샘플 데이터베이스를 사용하여 실행할 수 있습니다. 테이블 Sales.SalesOrderHeader 이 Sales.SalesOrderDetail 50번 확대되고 이름이 바뀝 Sales.SalesOrderHeaderBulkSales.SalesOrderDetailBulk니다.
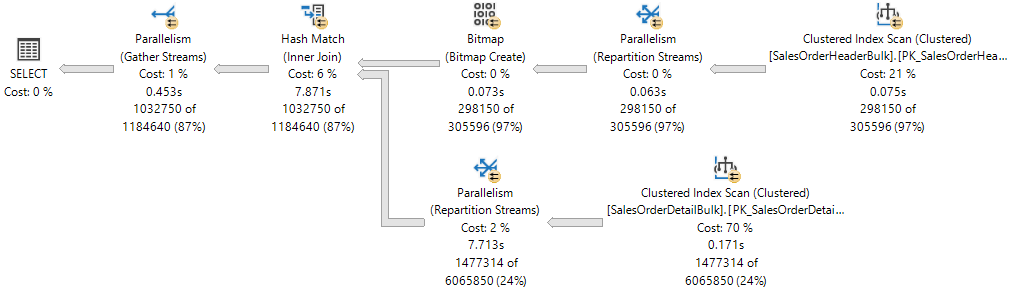
실행 계획은 두 테이블 간의 해시 조인을 표시하며, 화살표 두 개가 있는 노란색 원을 보면 알 수 있듯이 각 연산자는 병렬로 실행됩니다. 각 병렬 처리 연산자는 계획의 다른 분기입니다. 따라서 다음 실행 계획에는 세 개의 분기가 있습니다.
참고 항목
실행 계획을 트리 로 간주하는 경우 분기 는 Exchange 반복기라고도 하는 병렬 처리 연산자 간에 하나 이상의 연산자를 그룹화한 계획의 영역입니다. 계획 연산자에 대한 자세한 내용은 Showplan 논리 및 물리 연산자 참조를 참조하세요.
실행 계획에는 분기 세 개가 있지만 이 실행 계획에서는 실행 중 다음 분기 두 개만 동시에 실행할 수 있습니다.
- (조인의 빌드 입력)에서
Sales.SalesOrderHeaderBulk클러스터형 인덱스 검색이 사용되는 분기는 단독으로 실행됩니다. - 그런 다음( 조인의 프로브 입력)에서
Sales.SalesOrderDetailBulk클러스터형 인덱스 검색이 사용되는 분기는 비트맵이 생성되고 현재 해시 일치가 실행 중인 분기와 동시에 실행됩니다.
실행 계획 XML은 16개의 작업자 스레드가 NUMA 노드 0에서 예약되고 사용되었음을 보여 줍니다.
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
스레드 예약을 통해 데이터베이스 엔진 요청에 필요한 모든 작업을 수행할 수 있는 충분한 작업자 스레드가 있는지 확인합니다. 스레드는 여러 NUMA 노드에서 예약하거나 하나의 NUMA 노드에서만 예약할 수 있습니다. 스레드 예약은 실행이 시작되기 전에 런타임에 수행되며 스케줄러 로드에 따라 달라집니다. 예약된 작업자 스레드의 수는 일반적으로 수식 concurrent branches * runtime DOP 에서 파생되며 부모 작업자 스레드를 제외합니다. 각 분기는 MaxDOP와 같은 작업자 스레드 수로 제한됩니다. 이 예제에는 두 개의 동시 분기가 있으며 MaxDOP는 8로 설정됩니다 2 * 8 = 16.
참조를 위해 한 분기가 완료되고 두 개의 분기가 동시에 실행되는 라이브 쿼리 통계의 라이브 실행 계획을 관찰합니다.
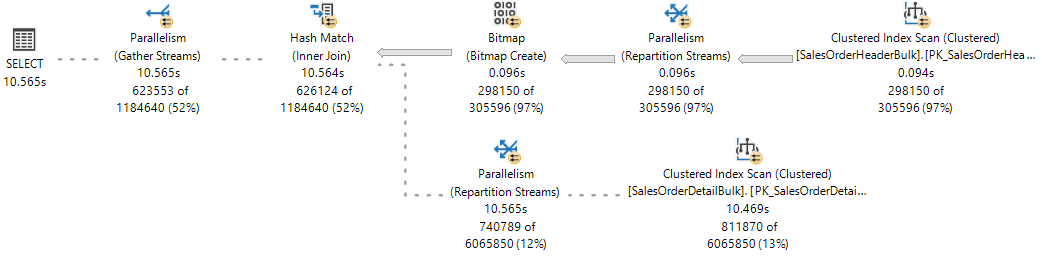
SQL Server 데이터베이스 엔진 다음 예제와 같이 sys.dm_os_tasks DMV를 쿼리하여 쿼리 실행 중에 관찰할 수 있는 활성 작업(1:1)을 실행하는 작업자 스레드를 할당합니다.
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
팁
열 parent_task_address 은 항상 부모 작업에 대해 NULL입니다.
팁
사용량이 많은 SQL Server 데이터베이스 엔진 예약된 스레드에서 설정한 제한을 초과하여 많은 활성 작업을 볼 수 있습니다. 이러한 작업은 더 이상 사용되지 않고 일시적 상태인 분기에 속할 수 있으며 클린 대기합니다.
결과 집합은 다음과 같습니다. 현재 실행 중인 분기의 활성 작업은 17개입니다. 예약된 스레드에 해당하는 자식 작업 16개와 부모 작업 또는 조정 작업입니다.
| parent_task_address | task_address | task_state | scheduler_id | worker_address |
|---|---|---|---|---|
| NULL | 0x000001EF4758ACA8 |
SUSPENDED | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | SUSPENDED | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | SUSPENDED | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | SUSPENDED | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | SUSPENDED | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | SUSPENDED | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | SUSPENDED | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | SUSPENDED | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | SUSPENDED | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | SUSPENDED | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | SUSPENDED | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | SUSPENDED | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | SUSPENDED | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | SUSPENDED | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | SUSPENDED | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | SUSPENDED | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | SUSPENDED | 11 | 0x000001EF6BD72160 |
16개의 자식 작업 각각에 다른 작업자 스레드가 할당되어 있지만(열에 worker_address 표시됨) 모든 작업자가 동일한 8개의 스케줄러 풀(0,5,6,7,8,8,9,10,11)에 할당되고 부모 작업이 이 풀 외부의 스케줄러에 할당됩니다(3).
Important
지정된 분기의 첫 번째 병렬 작업 집합이 예약되면 데이터베이스 엔진 다른 분기의 추가 작업에 동일한 스케줄러 풀을 사용합니다. 즉, MaxDOP에서만 제한되는 전체 실행 계획의 모든 병렬 작업에 동일한 스케줄러 집합이 사용됩니다.
SQL Server 데이터베이스 엔진 항상 동일한 NUMA 노드에서 작업 실행을 위해 스케줄러를 할당하고 스케줄러를 사용할 수 있는 경우 순차적으로 할당합니다(라운드 로빈 방식으로). 그러나 부모 태스크에 할당된 작업자 스레드는 다른 태스크와 다른 NUMA 노드에 배치할 수 있습니다.
작업자 스레드는 퀀텀(4ms) 동안 스케줄러에서만기본 다시 활성화할 수 있으며, 다른 작업에 할당된 작업자 스레드가 활성화될 수 있도록 해당 양자가 경과한 후에 스케줄러를 생성해야 합니다. 작업자의 양자가 만료되고 더 이상 활성 상태가 아닌 경우 해당 작업은 실행 상태로 다시 이동할 때까지 FIFO 큐에 배치됩니다. 이 경우 태스크가 현재 사용할 수 없는 리소스(예: 래치 또는 잠금)에 액세스할 필요가 없다고 가정합니다. 이 경우 작업은 RUNNABLE 대신 SUSPENDED 상태로 배치됩니다. 이러한 시간까지 해당 리소스를 사용할 수 있습니다.
팁
위에 표시된 DMV의 출력의 경우 모든 활성 작업은 SUSPENDED 상태입니다. 대기 태스크에 대한 자세한 내용은 dm_os_waiting_tasks DMV를 쿼리하여 확인할 수 있습니다.
요약하면 병렬 요청은 여러 작업을 생성합니다. 각 작업은 단일 작업자 스레드에 할당되어야 합니다. 각 작업자 스레드는 단일 스케줄러에 할당되어야 합니다. 따라서 사용 중인 스케줄러 수는 MaxDOP 구성 또는 쿼리 힌트에 의해 설정된 분기당 병렬 작업 수를 초과할 수 없습니다. 조정 스레드는 MaxDOP 제한에 영향을 주지 않습니다.
CPU에 스레드 할당
기본적으로 SQL Server의 각 인스턴스는 각 스레드를 시작하고 운영 체제는 부하에 따라 컴퓨터의 CPU(프로세서) 간에 SQL Server 인스턴스의 스레드를 분산합니다. affinity 프로세스가 운영 체제 수준에서 사용하도록 설정된 경우, 운영 체제에서 각 스레드를 특정 CPU에 할당합니다. 반면 SQL Server 데이터베이스 엔진 CPU 간에 스레드를 균등하게 분산하는 스케줄러에 SQL Server 작업자 스레드를 라운드 로빈 방식으로 할당합니다.
멀티태스킹을 수행하기 위해 예를 들어 여러 애플리케이션이 동일한 CPU 집합에 액세스하는 경우 운영 체제는 경우에 따라 작업자 스레드를 다른 CPU 간에 이동합니다. 운영 체제 측면에서는 효율적이지만 각 프로세서 캐시에 데이터가 반복적으로 다시 로드되어 시스템 로드가 많은 경우 이 활동으로 인해 SQL Server 성능이 저하될 수 있습니다. CPU를 특정 스레드에 할당하면 프로세서 다시 로드를 제거하고 CPU 간에 스레드 마이그레이션을 줄여(컨텍스트 전환 감소) 이러한 조건에서 성능을 향상시킬 수 있습니다. 스레드와 프로세서 간의 연결을 프로세서 선호도라고 합니다. 선호도가 설정된 경우 운영 체제는 각 스레드를 특정 CPU에 할당합니다.
선호도 마스크 옵션은 ALTER SERVER CONFIGURATION을 사용하여 설정됩니다. 선호도 마스크가 설정되지 않은 경우 SQL Server 인스턴스는 마스킹되지 않은 스케줄러 간에 작업자 스레드를 균등하게 할당합니다.
주의
운영 체제에서 CPU 선호도를 구성하지 않고 SQL Server에서 선호도 마스크도 구성하지 마세요. 이러한 설정은 동일한 결과를 달성하려고 시도하고 있으며 구성이 일치하지 않으면 예측할 수 없는 결과가 발생할 수 있습니다. 자세한 내용은 선호도 마스크 옵션을 참조 하세요.
스레드 풀링을 사용하면 많은 수의 클라이언트가 서버에 연결된 경우 성능을 최적화할 수 있습니다. 일반적으로 각 쿼리 요청에 대해 별도의 운영 체제 스레드가 만들어집니다. 그러나 서버에 대한 수백 개의 연결에서 쿼리 요청당 하나의 스레드를 사용하면 많은 양의 시스템 리소스를 사용할 수 있습니다. 최대 작업자 스레드 옵션을 사용하면 SQL Server에서 더 많은 수의 쿼리 요청을 서비스하는 작업자 스레드 풀을 만들어 성능을 향상시킬 수 있습니다.
경량 풀링 옵션 사용
스레드 컨텍스트 전환과 관련된 오버헤드는 그리 크지 않을 수 있습니다. SQL Server의 대부분의 인스턴스는 경량 풀링 옵션을 0 또는 1로 설정하는 것 사이에 성능 차이가 없습니다. 간단한 풀링을 활용할 수 있는 SQL Server의 유일한 인스턴스는 다음과 같은 특성을 가진 컴퓨터에서 실행되는 인스턴스입니다.
- 대규모 다중 CPU 서버
- 모든 CPU가 거의 최대 용량으로 실행되고 있습니다.
- 높은 수준의 컨텍스트 전환이 있습니다.
이러한 시스템은 경량 풀링 값이 1로 설정된 경우 성능이 약간 향상되는 것을 볼 수 있습니다.
Important
일상 작업을 예약하는 데에는 파이버 모드를 사용하지 않습니다. 이렇게 하면 컨텍스트 전환의 일반적인 이점을 억제하고 SQL Server의 일부 구성 요소가 파이버 모드에서 제대로 작동하지 않으므로 성능이 저하될 수 있습니다. 자세한 내용은 경량 풀링을 참조 하세요.
스레드 및 파이버 실행
Microsoft Windows는 1에서 31까지의 숫자 우선 순위 시스템을 사용하여 스레드 실행을 예약합니다. 0은 운영 체제용으로 예약됩니다. 여러 스레드가 실행되기를 기다리는 경우 Windows는 우선 순위가 가장 높은 스레드를 디스패치합니다.
기본적으로 SQL Server의 각 인스턴스는 기본 우선 순위라고 하는 7의 우선 순위입니다. 이 기본값은 SQL Server 스레드가 다른 애플리케이션에 부정적인 영향을 주지 않으면서 충분한 CPU 리소스를 얻을 수 있는 높은 우선 순위를 제공합니다.
Important
이 기능은 이후 버전의 SQL Server에서 제거됩니다. 새 개발 작업에서는 이 기능을 사용하지 않도록 하고, 현재 이 기능을 사용하는 애플리케이션은 수정하세요.
우선 순위 상승 구성 옵션을 사용하여 SQL Server 인스턴스에서 스레드의 우선 순위를 13으로 늘릴 수 있습니다. 이를 높은 우선 순위라고 합니다. 이 설정은 대부분의 다른 애플리케이션보다 높은 우선 순위를 SQL Server 스레드에 제공합니다. 따라서 SQL Server 스레드는 일반적으로 실행할 준비가 되어 있고 다른 애플리케이션의 스레드에 의해 선점되지 않을 때마다 디스패치됩니다. 이렇게 하면 서버가 SQL Server 인스턴스만 실행하고 다른 애플리케이션은 실행하지 않을 때 성능이 향상될 수 있습니다. 그러나 SQL Server에서 메모리 집약적 작업이 발생하는 경우 다른 애플리케이션은 SQL Server 스레드를 선점하기에 충분한 우선 순위를 가질 가능성이 없습니다.
컴퓨터에서 여러 SQL Server 인스턴스를 실행하고 일부 인스턴스에 대해서만 우선 순위 향상을 설정하는 경우 정상 우선 순위에서 실행되는 인스턴스의 성능에 부정적인 영향을 줄 수 있습니다. 또한 우선 순위 향상을 켜면 서버의 다른 애플리케이션 및 구성 요소 성능이 저하할 수 있습니다. 따라서 엄격하게 제어되는 환경에서만 이 설정을 사용해야 합니다.
Hot add CPU
Hot add CPU는 실행 중인 시스템에 CPU를 동적으로 추가할 수 있는 기능입니다. CPU는 새 하드웨어를 추가하여 물리적으로 추가하거나, 온라인으로 하드웨어를 분할하여 논리적으로 추가하거나, 가상화 계층을 통해 가상으로 추가할 수 있습니다. SQL Server는 핫 추가 CPU를 지원합니다.
hot add CPU 요구 사항
- 핫 추가 CPU를 지원하는 하드웨어가 필요합니다.
- 지원되는 버전의 Windows Server Datacenter 또는 Enterprise 버전이 필요합니다. Windows Server 2012부터 핫 추가는 Standard 버전에서 지원됩니다.
- SQL Server Enterprise 버전이 필요합니다.
- 소프트 NUMA를 사용하도록 SQL Server를 구성할 수 없습니다. 소프트 NUMA에 대한 자세한 내용은 Soft-NUMA(SQL Server)를 참조 하세요.
SQL Server는 추가된 후 CPU를 자동으로 사용하지 않습니다. 이렇게 하면 SQL Server에서 다른 용도로 추가될 수 있는 CPU를 사용할 수 없습니다. CPU를 추가한 후 RECONFIGURE 문을 실행하면 SQL Server에서 새로운 CPU를 사용할 수 있는 리소스로 인식하게 됩니다.
참고 항목
affinity64 마스크가 구성된 경우 새 CPU를 사용하도록 affinity64 마스크를 수정해야 합니다.
CPU가 64개 이상인 컴퓨터에서 SQL Server를 실행하는 모범 사례
CPU에 하드웨어 스레드 할당
선호도 마스크 및 affinity64 마스크 서버 구성 옵션을 사용하여 프로세서를 특정 스레드에 바인딩하지 마세요. 이러한 옵션은 CPU가 최대 64개일 때만 사용할 수 있습니다. SET PROCESS AFFINITY 대신 ALTER SERVER CONFIGURATION 옵션을 사용합니다.
트랜잭션 로그 파일 크기 관리
자동 증가에 의존하여 트랜잭션 로그 파일의 크기를 늘리지 마세요. 트랜잭션 로그를 늘리는 것은 직렬 프로세스여야 합니다. 로그를 확장하면 로그 확장이 완료될 때까지 트랜잭션 쓰기 작업이 진행되지 않도록 할 수 있습니다. 대신, 파일 크기를 환경의 일반적인 워크로드를 지원할 수 있을 만큼 큰 값으로 설정하여 로그 파일의 공간을 미리 할당합니다.
인덱스 작업에 대한 최대 병렬 처리 수준 설정
데이터베이스의 복구 모델을 대량 로그 또는 단순 복구 모델로 일시적으로 설정하여 CPU가 많은 컴퓨터에서 인덱스 만들기 또는 다시 작성과 같은 인덱스 작업의 성능을 향상시킬 수 있습니다. 이러한 인덱스 작업은 상당한 로그 작업을 생성할 수 있으며 로그 경합은 SQL Server에서 선택한 최상의 DOP(병렬 처리 수준)에 영향을 줄 수 있습니다.
MAXDOP(최대 병렬 처리 수준) 서버 구성 옵션을 조정하는 것 외에도 MAXDOP 옵션을 사용하여 인덱스 작업에 대한 병렬 처리를 조정하는 것이 좋습니다. 자세한 내용은 병렬 인덱스 작업 구성을 참조하세요. 최대 병렬 처리 수준 서버 구성 옵션 조정에 대한 자세한 내용 및 지침은 최대 병렬 처리 수준 서버 구성 옵션을 참조하세요.
최대 작업자 스레드 수 옵션
SQL Server는 시작할 때 최대 작업자 스레드 서버 구성 옵션을 동적으로 구성합니다 . SQL Server는 사용 가능한 CPU 수와 시스템 아키텍처를 사용하여 문서화된 수식을 사용하여 시작하는 동안 이 서버 구성을 결정합니다.
이 옵션은 고급 옵션으로, 숙련된 데이터베이스 관리자나 공인된 SQL Server 전문가만이 변경해야 합니다. 성능 문제가 있다고 의심되는 경우 작업자 스레드의 가용성이 아닐 수 있습니다. 원인은 작업자 스레드가 대기하게 하는 I/O와 같은 것일 가능성이 높습니다. 최대 작업자 스레드 설정을 변경하기 전에 성능 문제의 근본 원인을 찾는 것이 가장 좋습니다. 그러나 최대 작업자 스레드 수를 수동으로 설정해야 하는 경우 이 구성 값은 항상 시스템에 있는 CPU 수의 7배 이상의 값으로 설정해야 합니다. 자세한 내용은 최대 작업자 스레드 구성을 참조 하세요.
SQL 추적 및 SQL Server 프로파일러 사용 방지
프로덕션 환경에서는 SQL 추적 및 SQL Profiler를 사용하지 않는 것이 좋습니다. CPU 수가 늘어날수록 이러한 도구의 실행으로 인한 오버헤드도 늘어납니다. 프로덕션 환경에서 SQL 추적을 사용해야 하는 경우 추적 이벤트의 수를 최소로 제한합니다. 로드 중인 각 추적 이벤트를 신중하게 프로파일 및 테스트하고 성능에 큰 영향을 주는 이벤트 조합을 사용하지 않도록 합니다.
Important
SQL 추적 및 SQL Server Profiler는 사용되지 않습니다. SQL Server 추적 및 재생 개체를 포함하는 Microsoft.SqlServer.Management.Trace 네임스페이스도 더 이상 사용되지 않습니다.
이 기능은 이후 버전의 SQL Server에서 제거됩니다. 새 개발 작업에서는 이 기능을 사용하지 않도록 하고, 현재 이 기능을 사용하는 애플리케이션은 수정하세요.
대신 확장 이벤트를 사용합니다. 확장 이벤트에 대한 자세한 내용은 빠른 시작: SQL Server의 확장 이벤트 및 SSMS XEvent Profiler를 참조하세요.
참고 항목
Analysis Services 워크로드용 SQL Server Profiler는 더 이상 사용되지 않으며 계속 지원됩니다.
데이터 파일 수 tempdb 설정
파일 수는 컴퓨터의 (논리적) 프로세서 수에 따라 달라집니다. 일반적으로 논리 프로세서 수가 8보다 작거나 같은 경우 논리 프로세서와 동일한 수의 데이터 파일을 사용합니다. 논리 프로세서 수가 8개보다 큰 경우 8개의 데이터 파일을 사용한 다음 경합이 계속되는 경우 경합이 허용 가능한 수준으로 줄어들거나 워크로드/코드를 변경할 때까지 데이터 파일 수를 4의 배수로 늘립니다. SQL Server에서 tempdb 성능 최적화에서 사용할 수 있는 다른 권장 사항tempdb도 염두에 두어야 합니다.
그러나 동시성 요구 사항을 tempdb신중하게 고려하여 데이터베이스 관리 오버헤드를 줄일 수 있습니다. 예를 들어 시스템에 64개의 CPU가 있고 일반적으로 32개의 쿼리만 사용하는 tempdb경우 파일 수를 tempdb 64로 늘리면 성능이 향상되지 않습니다.
64개를 초과하는 CPU를 사용할 수 있는 SQL Server 구성 요소
다음 표에서는 SQL Server 구성 요소를 나열하고 64개 CPU를 더 많이 사용할 수 있는지 여부를 나타냅니다.
| 프로세스 이름 | 실행 프로그램 | 64개 이상의 CPU 사용 |
|---|---|---|
| SQL Server 데이터베이스 엔진 | Sqlserver.exe | 예 |
| Reporting Services | Rs.exe | 아니요 |
| Analysis Services | As.exe | 아니요 |
| Integration Services | Is.exe | 아니요 |
| Service Broker | Sb.exe | 아니요 |
| 전체 텍스트 검색 | Fts.exe | 아니요 |
| SQL Server 에이전트 | Sqlagent.exe | 아니요 |
| SQL Server Management Studio | Ssms.exe | 아니요 |
| SQL Server 설치 | Setup.exe | 아니요 |
피드백
출시 예정: 2024년 내내 콘텐츠 피드백 메커니즘인 GitHub 문제를 단계적으로 폐지하고 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 https://aka.ms/ContentUserFeedback을 참조하세요.
다음에 대한 사용자 의견 제출 및 보기