학습
학습 경로
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
이 브라우저는 더 이상 지원되지 않습니다.
최신 기능, 보안 업데이트, 기술 지원을 이용하려면 Microsoft Edge로 업그레이드하세요.
Service Manager에서 데이터 웨어하우스에 있는 데이터는 다양한 원본에서 통합할 수 있습니다. 미리 정의되고 사용자 지정된 MICROSOFT OLAP(온라인 분석 처리) 데이터 큐브를 사용하여 Service Manager를 통해 제공됩니다. 간단히 말해서 Service Manager의 고급 분석은 일반적으로 Microsoft Excel 또는 Microsoft SharePoint에서 큐브 데이터를 게시, 보기 및 조작하는 것으로 구성됩니다. Excel은 주로 데이터를 확인하고 조작하는 데 사용됩니다. SharePoint는 주로 큐브 데이터 게시 및 공유 수단으로 사용됩니다.
Service Manager에는 System Center 전체 데이터 웨어하우스가 포함되어 있습니다. 따라서 Operations Manager, Configuration Manager 및 Service Manager의 데이터를 데이터 웨어하우스로 통합하여 여러 데이터 뷰를 쉽게 사용하여 원하는 정보를 가져올 수 있습니다. 또한 데이터 웨어하우스는 SAP 애플리케이션 또는 타사 인사 관리 애플리케이션과 같은 사용자만의 사용자 지정 원본에서 동일한 데이터 웨어하우스에 데이터를 입력할 수 있는 인터페이스입니다. 이러한 통합을 통해 공용 데이터 모델을 만들고 다양한 분석을 사용할 수 있으므로 모든 비즈니스 인텔리전스 및 보고 요구를 지원할 수 있는 IT(정보 기술) 조직에서 데이터 웨어하우스를 구축할 수 있습니다.
데이터가 공용 모델에 있는 경우 정보를 조작할 수 있으며 전체 기업에 대해 공용 정의 및 공용 분류법을 사용할 수 있습니다. Excel 및 SharePoint와 같은 표준 도구를 사용하여 OLAP 데이터 큐브를 배포하고 큐브에서 정보에 액세스하여 이를 수행할 수 있습니다. 따라서 사용자는 이미 알고 있는 기술을 활용할 수 있습니다. 중앙 집중식으로 비즈니스 논리의 정의를 제어합니다. 예를 들어 핵심 성과 지표(예: 인시던트 해결 시간 임계값)와 녹색, 노랑 또는 빨강 임계값에 대한 값을 정의할 수 있습니다. 중앙 집중식으로 이러한 선택을 제어하고 사용자가 데이터를 쉽게 사용할 수 있도록 지원하는 한편 Excel 보고서 또는 SharePoint 대시보드에 공용 정의를 표시할 수 있습니다.
OLAP(온라인 분석 처리) 큐브는 기존 데이터 웨어하우스 인프라를 사용하여 최종 사용자에게 셀프 서비스 비즈니스 인텔리전스 기능을 제공하는 Service Manager의 기능입니다.
OLAP 큐브는 데이터의 신속한 분석을 제공하여 관계형 데이터베이스의 한계를 극복하는 데이터 구조입니다. 큐브는 사용자에게 어떠한 데이터 요소에 대해서도 검색 가능한 액세스를 제공하는 한편 많은 데이터를 표시 및 총합할 수 있습니다. 이렇게 하면 데이터를 요약, 조각화 및 세분화하여 사용자의 관심 분야와 관련된 다양한 질문을 처리할 수 있도록 할 수 있습니다.
OLAP 큐브에 대한 실무 지식을 갖춘 소프트웨어 공급업체 또는 IT(정보 기술) 개발자는 관리 팩을 만들어 데이터 웨어하우스 인프라를 기반으로 구축된 확장 가능하고 사용자 지정 가능한 OLAP 큐브를 정의할 수 있습니다. 이러한 큐브는 SSAS(SQL Server Analysis Services)에 저장됩니다. Excel, SSRS(SQL Server Reporting Services) 등 셀프 서비스 비즈니스 인텔리전스 도구에서 SSAS의 이러한 큐브를 사용할 수 있으며 이러한 도구를 사용하여 여러 관점에서 데이터를 분석할 수 있습니다.
기업에서 모든 트랜잭션 및 레코드를 저장하는 데 사용하는 데이터베이스를 OLTP(온라인 트랜잭션 처리) 데이터베이스라고 합니다. 이러한 데이터베이스에는 주로 한 번에 1개가 입력되는 레코드가 있으며, 이러한 레코드는 정보를 바탕으로 비즈니스에 대한 의사를 결정하는 전략에 사용될 수 있는 다양한 정보를 포함합니다. 그러나 데이터를 저장하는 데 사용되는 데이터베이스는 분석을 위해 설계되지 않았습니다. 따라서 이러한 데이터베이스에서 답변을 검색할 때는 시간과 노력이 많이 듭니다. OLAP 데이터베이스는 데이터에서 이런 비즈니스 인텔리전스 정보를 추출할 수 있도록 설계된 특수한 데이터베이스입니다.
OLAP 큐브는 데이터 웨어하우스 솔루션 퍼즐의 마지막 조각으로 간주할 수 있습니다. 다차원 큐브 또는 하이퍼큐브로도 알려진 OLAP 큐브는 OLAP 데이터베이스를 사용하여 데이터가 거의 분석될 수 있도록 구축된 SSAS(SQL Server Analysis Services)의 데이터 구조입니다. 이 시스템의 토폴로지가 다음 그림에 나와 있습니다.
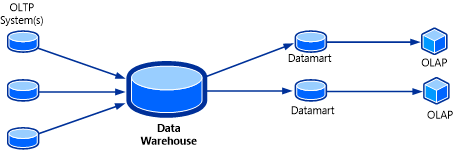
OLAP 큐브의 유용한 기능은 큐브의 데이터가 집계된 형태에 포함될 수 있는 것입니다. 값의 분류가 이미 사전 계산되었기 때문에 사용자에게 큐브는 미리 답을 포함한 것처럼 보입니다. 원본 OLAP 데이터베이스에 쿼리하지 않아도 큐브는 거의 즉시 다양한 범위의 질문에 대한 답을 반환할 수 있습니다.
Service Manager OLAP 큐브의 주요 목표는 소프트웨어 공급업체 또는 IT(정보 기술) 개발자에게 기록 분석 및 추세 분석 모두에 대해 거의 즉각적인 데이터 분석을 수행할 수 있는 기능을 제공하는 것입니다. Service Manager는 다음을 통해 이 작업을 수행합니다.
Service Manager 콘솔에서 데이터 웨어하우스 큐브가 표시되는 방식을 확인하려면 데이터 웨어하우스 작업 영역으로 이동하고 큐브를 선택합니다.
다음 그림은 OLAP(온라인 분석 처리) 큐브에 필요한 주요 구성 요소를 설명하는 SQL Server BIDS(Business Intelligence Development Studio)의 이미지를 보여 줍니다. 이러한 구성 요소는 데이터 원본, 데이터 원본 뷰, 큐브 및 차원입니다. 다음 섹션에서는 OLAP 큐브 구성 요소와 사용자가 사용하여 수행할 수 있는 작업을 설명합니다.
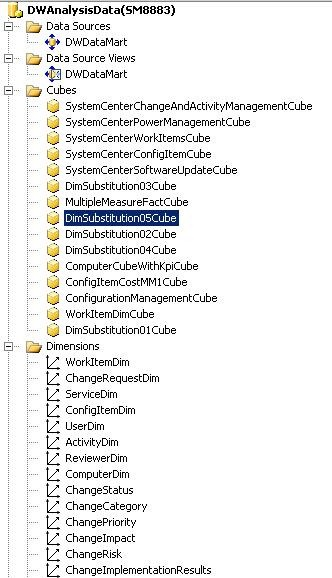
데이터 원본은 OLAP 큐브 내에 포함된 모든 데이터의 원본입니다. OLAP 큐브는 데이터 원본에 연결하여 원시 데이터를 읽고 처리함으로써 관련 측정값에 대한 집계 및 계산을 수행합니다. 모든 Service Manager OLAP 큐브의 데이터 원본은 Operations Manager와 Configuration Manager 모두에 대한 데이터 마트를 포함하는 데이터 마트입니다. 올바른 수준의 권한을 설정하려면 데이터 원본에 대한 인증 정보를 SSAS(SQL Server Analysis Services)에 저장해야 합니다.
DSV(데이터 원본 뷰)는 Service Manager 데이터 마트와 같은 데이터 원본의 차원, 팩트 및 아웃트리거 테이블을 나타내는 뷰의 컬렉션입니다. DSV에는 기본 키, 외래 키 등 테이블 간의 모든 관계가 포함됩니다. 즉, DSV는 SSAS 데이터베이스가 관계 스키마에 매핑하는 방법을 지정하고 관계 데이터베이스 위에 추상 계층을 제공합니다. 이 추상 계층을 사용하여 원본 관계 데이터베이스 내에 관계가 존재하지 않는 경우에도 팩트와 차원 테이블 간에 관계를 정의할 수 있습니다. 또한 데이터 웨어하우스 차원 스키마에 기본적으로 존재하지 않는 DSV에서 명명된 계산, 사용자 지정 측정값 및 새로운 특성을 정의할 수 있습니다. 예를 들어, 인시던트 해결에 대한 불리언 값을 정의하는 특정 계산은 인시던트의 상태가 해결되거나 닫힌 경우 값을 참으로 계산합니다. 그런 다음 Service Manager는 명명된 계산을 사용하여 해결된 인시던트 비율, 해결된 총 인시던트 수 및 확인되지 않은 총 인시던트 수와 같은 유용한 정보를 표시하는 측정값을 정의할 수 있습니다.
명명된 계산을 빠르게 살펴볼 수 있는 또 다른 예는 ReleasesImplementedOnSchedule입니다. 이 명명된 계산은 실제 종료 날짜가 예약된 종료 날짜보다 빠르거나 같은 릴리스 레코드의 수에 대해 빠른 상태 검사를 제공합니다.
OLAP 큐브는 데이터에 대한 신속한 분석을 제공하여 관계형 데이터베이스의 한계를 극복하는 데이터 구조입니다. OLAP 큐브는 많은 양의 데이터를 표시하고 합계를 계산하는 동시에 사용자에게 모든 데이터 요소에 대한 검색 가능한 액세스 권한을 제공하므로 사용자의 관심 영역과 관련된 다양한 질문을 처리하기 위해 필요에 따라 데이터를 롤업, 조각화 및 받아쓰기할 수 있습니다.
SSAS의 차원은 Service Manager 데이터 웨어하우스의 차원을 참조합니다. Service Manager에서 차원은 관리 팩 클래스와 거의 동일합니다. 각 관리 팩 클래스에는 속성 목록이 있으며, 각 차원에는 특성의 목록이 포함되고, 각 특성은 클래스의 한 속성에 매핑됩니다. 차원을 사용하여 데이터를 필터링 및 그룹화하고 레이블을 지정할 수 있습니다. 예를 들어 설치된 운영 체제별로 컴퓨터를 필터링하고 사용자를 성별 또는 연령별 범주로 그룹화할 수 있습니다. 그런 다음 데이터를 이러한 계층 및 범주로 자연스럽게 분류하여 보다 심층적인 분석을 허용하는 형식으로 데이터를 표시할 수 있습니다. 차원에는 사용자가 보다 자세한 세부 수준으로 "드릴다운"할 수 있는 자연스러운 계층 구조가 있을 수도 있습니다. 예를 들어 날짜 차원에는 연도, 분기, 월, 주 및 일별로 드릴다운할 수 있는 계층이 있습니다.
다음 그림은 날짜, 지역 및 제품 차원을 포함하는 OLAP 큐브를 보여 줍니다.
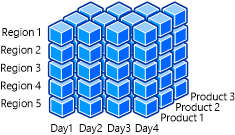
예를 들어 Microsoft 팀 구성원은 해당 버전에서 Xbox One 게임 콘솔의 판매에 대한 빠르고 간단한 요약을 원할 수 있습니다. 그들은 더 세분화하여 특정 기간의 판매 수치를 얻을 수 있습니다. 비즈니스 분석가는 새로운 콘솔 디자인과 Xbox One용 Kinect의 출시로 인해 Xbox One 본체의 판매가 어떻게 영향을 미쳤는지 검토할 수 있습니다. 이러한 조사는 현재 판매 추세와 잠재적으로 필요한 비즈니스 전략의 수정을 결정하는 데 도움이 됩니다. 날짜 차원을 필터링하면 정보를 빠르게 전달 및 사용할 수 있습니다. 사용자가 쉽게 필터링하고 그룹화할 수 있는 특성 및 데이터를 사용하여 차원이 설계되었기 때문에 데이터를 분리 및 분할할 수 있습니다.
Service Manager에서 모든 OLAP 큐브는 공통 차원 집합을 공유합니다. 모든 차원은 여러 데이터 마트 시나리오에서도 기본 데이터 웨어하우스의 단일 데이터 마트를 원본으로 사용합니다. 여러 데이터 마트 시나리오에서 큐브를 처리하는 동안 차원 키 오류가 발생할 수 있습니다.
측정값 그룹은 데이터 웨어하우스 용어의 팩트와 동일한 개념입니다. 팩트에 데이터 웨어하우스의 숫자 측정값이 포함되는 것처럼 측정값 그룹에는 OLAP 큐브의 측정값이 포함됩니다. 데이터 원본 뷰의 단일 팩트 테이블에서 파생되는 OLAP 큐브의 모든 측정값도 측정값 그룹으로 간주될 수 있습니다. 그러나 OLAP 큐브의 측정값이 파생되는 여러 팩트 테이블이 있는 경우가 있을 수 있습니다. 동일한 세부 수준의 측정값은 하나의 측정값 그룹으로 통합됩니다. 측정값 그룹은 시스템에 로드되는 데이터, 데이터가 로드되는 방법 및 데이터가 다차원 큐브에 바인딩되는 방법을 정의합니다.
각 측정값 그룹에는 실제 데이터를 겹치지 않는 섹션에 따로 보존하는 파티션 목록이 포함됩니다. 측정값 그룹에는 사용자 쿼리의 성능을 개선하기 위해 각 측정 그룹에 대해 계산되어 미리 요약된 데이터 집합을 정의하는 집계 설계도 포함되어 있습니다.
측정값은 사용자가 분할, 세분화, 집계 및 분석하려는 숫자 값입니다. 데이터 웨어하우스 인프라를 사용하여 OLAP 큐브를 빌드하려는 주요한 이유 중 하나입니다. SSAS를 사용하면 비즈니스 규칙 및 계산에 적용되는 OLAP 큐브를 작성하여 측정값을 사용자 지정 가능한 형식으로 지정하고 표시할 수 있습니다. 표시되는 측정값 및 계산 방법을 결정하고 정의하는 데 상당한 OLAP 큐브 개발 시간을 보냅니다.
데이터 웨어하우스 팩트 테이블의 숫자 열에 주로 매핑되는 측정값은 차원과 퇴행 차원 속성에서도 생성될 수 있습니다. 이러한 측정값은 분석되는 OLAP 큐브의 가장 중요한 값이며 OLAP 큐브를 찾아보는 최종 사용자의 기본 관심사입니다. 데이터 웨어하우스에 존재하는 측정값의 예는 ActivityTotalTimeMeasure입니다. ActivityTotalTimeMeasure는 각 작업이 특정 상태에 있는 시간을 나타내는 ActivityStatusDurationFact의 측정값입니다. 측정값의 세부 수준은 참조되는 모든 차원으로 구성됩니다. 예를 들어 ComputerHostsOperatingSystem 관계 팩트의 세부 수준은 컴퓨터 및 운영 체제 차원으로 구성됩니다.
집계 함수는 데이터를 더 자세히 분석할 수 있도록 측정값에 대해 계산됩니다. 가장 일반적인 집계 함수는 Sum입니다. 예를 들어 일반적인 OLAP 큐브 쿼리는 In Progress의 모든 작업에 대한 총 시간을 요약합니다. 다른 일반 집계 함수로는 Min, Max 및 Count가 있습니다.
원시 데이터가 OLAP 큐브에서 처리된 후 사용자는 MDX(Multidimensional Expression)를 사용하여 더욱 복잡한 계산 및 쿼리를 수행함으로써 고유한 측정값 식 또는 계산된 구성원을 정의할 수 있습니다. MDX는 OLAP 시스템에 저장되는 데이터를 쿼리 및 액세스할 수 있는 업계 표준입니다. SQL Server는 다차원 데이터베이스에서 지원하는 데이터 모델을 사용하도록 설계되지 않았습니다.
OLAP 큐브의 데이터로 드릴다운할 때 사용자는 요약의 여러 수준에서 데이터를 분석합니다. 데이터의 세부 수준은 사용자가 계층의 여러 수준으로 데이터를 검사하여 드릴다운할 때 변경됩니다. 사용자가 드릴다운할 때 더 좁은 포커스를 사용하여 요약 정보에서 데이터로 이동합니다. 드릴다운의 예는 다음과 같습니다.
사용자가 데이터를 드릴스루 할 때 OLAP 큐브의 집계 데이터에 기여한 모든 개별 트랜잭션을 확인하려고 합니다. 즉, 사용자는 제공된 측정값의 가장 낮은 세부 수준으로 데이터를 검색할 수 있습니다. 예를 들어 특정 월 및 제품 범주에 대한 판매 데이터가 제공되면 해당 데이터를 드릴스루하여 해당 데이터 셀에 포함된 각 테이블 행의 목록을 볼 수 있습니다.
용어 드릴다운과 드릴스루를 서로 혼동하는 것이 일반적입니다. 둘 사이의 주요 차이점은 드릴다운이 미리 정의된 데이터 계층 구조에서 작동한다는 점입니다. 예를 들어, 미국에서 워싱턴으로, 그리고 OLAP 큐브 내에서 시애틀로 이어지는 식입니다. 드릴다운은 데이터를 가장 낮은 세부 수준으로 직접 이동하여, 단일 셀에 집계된 데이터 소스에서 행 집합을 검색합니다.
조직은 KPI(핵심 성과 지표)를 통해 목표를 향한 진행률을 측정하여 기업 및 성과의 상태를 측정할 수 있습니다. KPI는 미리 정의된 특정 목표 및 목적을 향한 진행률을 모니터링하도록 정의할 수 있는 비즈니스 메트릭입니다. KPI에는 조직의 성공에 중요한 정량적 목표를 나타내는 대상 값과 실제 값이 있습니다. KPI는 성과 기록표의 그룹으로 표시되어 하나의 빠른 스냅샷에서 비즈니스의 전반적인 상태를 표시합니다.
KPI의 한 예를 들면 48시간 내에 모든 변경 요청을 완료하는 것입니다. KPI는 해당 시간 프레임 내에 해결되는 변경 요청의 백분율을 측정하는 데 사용할 수 있습니다. 대시보드를 만들어 KPI를 시각적으로 나타낼 수 있습니다. 예를 들어 48시간 내에 75%까지 모든 변경 요청을 완료하기 위한 KPI 대상 값을 정의할 수 있습니다.
파티션은 측정값 그룹에서 일부 또는 모든 데이터를 보존하는 데이터 구조입니다. 모든 측정값 그룹은 파티션으로 나뉩니다. 파티션은 측정값 그룹에 로드되는 팩트 데이터의 하위 집합을 정의합니다. SSAS Standard Edition에서는 측정값 그룹당 하나의 파티션만 허용되는 반면, SSAS Enterprise Edition에서는 측정값 그룹에 여러 파티션을 포함할 수 있습니다. 파티션은 최종 사용자에게 투명한 기능이지만 OLAP 큐브의 성능과 확장성 모두에 큰 영향을 줍니다. 측정값 그룹의 모든 파티션은 항상 실제 물리적 데이터베이스에 존재합니다.
파티션을 사용하면 관리자가 OLAP 큐브를 더 잘 관리하고 OLAP 큐브의 성능을 향상시킬 수 있습니다. 예를 들어 나머지 측정값 그룹에 영향을 주지 않고 측정값 그룹 중 한 파티션에 있는 데이터를 제거하거나 다시 처리할 수 있습니다. 팩트 테이블로 새 데이터를 로드할 때 새 데이터를 포함해야 하는 파티션만 영향을 받습니다.
또한 파티션은 OLAP 큐브에 대한 처리 및 쿼리 성능을 개선합니다. SSAS는 여러 파티션을 병렬로 처리할 수 있으므로, 서버의 CPU 및 메모리 리소스를 훨씬 더 효율적으로 사용할 수 있습니다. 쿼리를 실행하는 동안 SSAS는 여러 파티션에서 데이터를 가져오고, 처리하고, 집계하며, 쿼리와 관련된 데이터가 포함된 파티션만 검색되므로 전체 입력 및 출력 양이 줄어듭니다.
파티션 전략 중 한 예는 매달 팩트 데이터를 월별 파티션에 저장하는 것입니다. 월말에 모든 새 데이터가 새 파티션으로 이동되므로, 본질적으로 중첩되지 않은 값을 포함하는 데이터가 배포됩니다.
OLAP 큐브의 집계는 사전 요약된 데이터 집합입니다. GROUP BY 절이 있는 SQL SELECT 문과 유사합니다. SSAS는 쿼리에 응답할 때 이러한 집계를 사용하여 필요한 계산의 양을 줄이는 방법으로 사용자에게 응답을 빠르게 반환합니다. OLAP 큐브의 기본 제공된 집계를 통해 SSAS가 쿼리 시간에 수행해야 하는 집계의 양이 줄어듭니다. 올바른 집계를 작성하면 쿼리 성능이 상당히 개선될 수 있습니다. 이 프로세스는 쿼리와 사용량이 변화함에 따라 OLAP 큐브의 수명 동안 종종 진화합니다.
일반적으로 OLAP 큐브에 대한 대부분의 쿼리에 유용한 집계의 기본 집합을 만듭니다. 집계는 측정값 그룹 내 OLAP 큐브의 각 파티션에 대해 작성됩니다. 집계가 작성되면 특정 차원 특성이 사전 요약된 데이터 집합에 포함됩니다. 사용자는 OLAP 큐브를 검색할 때 이러한 집계에 기반하여 데이터를 빠르게 쿼리할 수 있습니다. 집계를 작성하는 데 드는 시간과 스토리지 공간이 비합리적으로 많이 필요할 정도로 집계 수가 많아질 수 있으므로 집계를 신중하게 설계해야 합니다.
Service Manager는 Service Manager OLAP 큐브에서 집계를 빌드하고 디자인할 때 다음 두 가지 옵션을 사용합니다.
"성능 향상 정도" 옵션은 작성되는 집계의 비율을 결정합니다. 예를 들어 이 옵션을 기본값이며 권장 값인 30%로 설정하면 OLAP 큐브에 30%의 예상 성능 향상을 제공하도록 집계가 작성됩니다. 그러나 이것이 가능한 집계의 30%가 빌드된다는 것을 의미하지는 않습니다.
사용 빈도 기반 최적화를 사용하면 쿼리가 실행될 때 정보가 집계 설계 프로세스로 피드되도록 SSAS에서 데이터에 대한 요청을 기록할 수 있습니다. 그런 다음 SSAS는 데이터를 검토하고 예상되는 최상의 성능 향상을 얻기 위해 작성해야 하는 집계를 권장합니다.
큐브의 각 측정값 그룹은 파티션으로 나뉘며 파티션은 측정값 그룹에 로드되는 팩트 데이터의 일부를 정의합니다. SQL Server Standard Edition의 SSAS(SQL Server Analysis Services)는 측정값 그룹당 하나의 파티션만 허용하지만 Enterprise Edition에서는 여러 파티션이 허용됩니다. 파티션은 최종 사용자에게 완전히 노출되지만 성능 및 확장성에 중요한 영향을 미칩니다. 예를 들어 파티션은 개별적으로 병렬 처리될 수 있습니다. 집계 디자인이 다를 수 있습니다. 측정값 그룹의 다른 모든 파티션에 영향을 주지 않고 파티션을 다시 처리할 수 있습니다. 또한 SSAS는 쿼리에 대한 필수 데이터를 포함하는 파티션만 자동으로 스캔하므로, 쿼리 성능을 방대하게 개선할 수 있습니다.
큐브 분할은 모든 데이터 웨어하우스 유지 관리 작업 실행 시, 기본적으로 매시간 수행됩니다. 실행되는 특정 프로세스 모듈의 이름은 ManageCubePartitions입니다. CreateMartPartitions 단계 후 항상 실행됩니다. 이 종속성 데이터는 infra.moduletriggercondition 테이블에 저장됩니다.
분할을 처리하는 기본 DLL(동적 연결 라이브러리)은 PartitionUtil 클래스의 웨어하우스 유틸리티 DLL인 Microsoft.EnterpriseManagement.Warehouse.Utility에 있습니다. 특히 클래스에는 모든 파티션 유지 관리를 처리하는 ManagePartitions() 메서드가 있습니다. 데이터 웨어하우스 유지 관리 DLL, Microsoft.EnterpriseManagement.Warehouse.Maintenance 및 데이터 웨어하우스 OLAP(온라인 분석 처리) DLL, Microsoft.EnterpriseManagement.Warehouse.Olap는 유지 관리 및 큐브 배포 중에 파티션을 처리하는 Microsoft.EnterpriseManagement.Warehouse.Utility로 호출됩니다. 이것이 바로 실제 파티션 처리가 논리 또는 코드 복제를 방지하기 위해 공용 웨어하우스 유틸리티 DLL에 있는 이유입니다.
큐브 분할 유지 관리는 다음과 같은 작업을 수행합니다.
이를 위해 구조적 쿼리 언어(SQL) 테이블인 etl.TablePartition을 읽어 측정값 그룹에 대해 생성된 모든 팩트 파티션을 결정합니다. 다음 행동이 발생합니다.
큐브 처리와 관련하여 다음에 유의하십시오.
OLAP(온라인 분석 처리) 큐브 배포는 Service Manager 배포 인프라를 사용하여 SSAS(SQL Server Analysis Services) 데이터베이스에 OLAP 큐브를 만듭니다.
요약하면 배포 가능한 요소는 직렬화되고 SSAS 데이터베이스의 OLAP 큐브를 만드는 데 사용되는 리소스 컬렉션과 함께 배포자를 반환합니다. OLAP 큐브의 경우 배포 가능한 개체의 이름은 SystemCenterCube 요소의 경우 CubeDeployable이고 CubeExtension 요소의 경우 CubeExtensionDeployable입니다. 두 요소에 대한 배포자는 CubeDeployer입니다.
DWStagingAndConfig 데이터베이스의 dbo.Selector 테이블에는 SystemCenterCube 및 CubeExtension 관리 팩 요소에 대한 항목이 포함됩니다. MPSync 작업을 사용하여 데이터 웨어하우스에 관리 팩을 가져올 때 관리 팩 요소에 대한 추가 배포 처리가 필요한 경우 배포 엔진에서 이 메타데이터를 사용합니다.
배포는 AMO(분석 관리 개체) API(응용 프로그래밍 인터페이스)를 사용하여 SSAS 데이터베이스의 모든 큐브 구성 요소를 만들고 수정합니다. 특히 CubeDeployable 요소에 SSAS 데이터베이스에 대한 연결이 없으므로 연결이 끊긴 모드의 AMO가 사용됩니다. 연결이 끊어진 모드에서 AMO로 작업하면 서버에 연결 하지 않고 AMO 개체의 전체 트리를 만들 수 있습니다. 그런 다음 Service Manager는 개체의 계층 구조를 스트림 리소스로 직렬화하고 배포 인프라에 다시 전달되는 배포자 개체에 연결합니다. 배포자 개체는 역직렬화되고 SSAD 데이터베이스에 연결된 후 서버에 적절한 요청을 전송하여 개체를 만듭니다.
주 개체만 직렬화할 수 있습니다. AMO에서 주 개체는 완전한 엔터티로 완전한 개체를 나타내며 다른 개체의 일부가 아닌 것으로 간주되는 클래스입니다. 예를 들어 주 개체에는 모두 독립 실행형 엔터티인 Server, Cube 및 Dimension이 포함됩니다. 그러나 DimensionAttribute는 Dimension의 부모 주 개체의 일부로만 만들 수 있으므로 주요 개체가 아닙니다. 따라서 DimensionAttribute는 부 개체입니다. OLAP 큐브 설계는 다른 종속 부 개체와 함께 큐브에 필요한 모든 주 개체 만들기에 중점을 둡니다. 이러한 주요 개체는 SSAS 데이터베이스에서 개체를 만들기 전에 직렬화되고 결국 역직렬화될 개체입니다.
주 개체를 래핑하는 리소스는 배포를 적절히 완료하고 OLAP 큐브 요소의 종속성 요구 사항을 충족하기 위해 특정 순서로 생성되어야 합니다. 다음 두 목록은 각각 SystemCenterCube 및 CubeExtension 요소의 배포 순서를 나타냅니다.
OLAP(온라인 분석 처리) 큐브가 배포되고 모든 파티션이 만들어지면 볼 수 있도록 처리할 준비가 된 것입니다. 큐브 처리는 ETL(추출, 변환 및 로드) 실행 후 최종 단계입니다. 이러한 단계는 다음과 같이 진행됩니다.
OLAP 큐브 처리는 큐브에 대한 모든 집계가 계산되고 큐브가 이러한 집계 및 데이터를 사용하여 로드될 때 발생합니다. 이때 차원 및 팩트 테이블을 읽고 데이터를 계산하여 큐브에 로드합니다. OLAP 큐브를 설계할 때 수백만 개의 레코드가 존재할 수 있는 프로덕션 환경에서는 처리가 인해 잠재적으로 큰 영향을 줄 수 있으므로 처리를 신중하게 고려해야 합니다. 이러한 환경에서 모든 파티션의 전체 프로세스는 며칠에서 몇 주까지 걸릴 수 있으며, 이로 인해 Service Manager 인프라 및 큐브를 최종 사용자에게 사용할 수 없게 될 수 있습니다. 한 가지 권장 사항은 시스템의 오버헤드를 줄이기 위해 사용되지 않는 큐브의 처리 일정을 사용하지 않도록 설정하는 것입니다.
OLAP 큐브 처리는 두 가지 별도의 작업으로 구성됩니다.
각 OLAP 큐브에는 Service Manager 콘솔에 해당 처리 작업이 있으며 사용자가 구성할 수 있는 일정에 따라 실행됩니다. 처리 작업의 각 유형에 대해서는 다음 섹션에서 설명합니다.
새로운 차원이 SSAS(SQL Server Analysis Server) 데이터베이스에 추가될 때마다 전체 프로세스가 완전 처리된 상태가 되도록 차원에 대해 실행되어야 합니다. 그러나 차원이 처리된 후에는 동일한 차원을 대상으로 하는 다른 큐브가 처리될 때 차원이 다시 처리된다는 보장은 없습니다. 차원을 자동으로 다시 처리하지 않으면 Service Manager가 모든 큐브의 모든 차원을 다시 처리할 수 없습니다. 차원이 최근에 처리된 경우에는 아직 처리되지 않은 새 데이터가 있을 가능성이 낮기 때문에 특히 그렇습니다. 처리 효율성을 최적화하기 위해 Microsoft.SystemCenter.Datawarehouse.OLAP.Base 관리 팩에 정의된 단일 클래스(Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval)가 있습니다. 다음은 이 클래스의 예입니다.
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
싱글턴 클래스는 속성 IntervalInMinutes를 포함하며, 이는 차원을 얼마나 자주 처리할지를 나타냅니다. 기본적으로 이 속성은 60분으로 설정됩니다. 예를 들어 차원이 오후 3시 05분에 처리되고 동일한 차원을 대상으로 하는 다른 큐브가 오후 3시 45분에 처리되는 경우 차원은 다시 처리되지 않습니다. 이 방법의 한 가지 단점은 차원 키 오류가 발생할 가능성이 높아지는 것입니다. 다시 시도 메커니즘은 차원 키 오류를 처리하여 차원 및 큐브 파티션을 다시 처리합니다. 오류 처리에 대한 자세한 내용은 "디버깅 및 문제 해결과 관련된 일반적인 문제" 섹션을 참조하세요.
차원을 완전히 처리한 후 ProcessUpdate 를 사용하여 증분 처리가 실행됩니다. ProcessFull 이 실행되는 또 다른 경우로는 차원 스키마가 변경되는 경우뿐입니다. 스키마가 변경되면 차원이 처리되지 않은 상태로 돌아가기 때문입니다. ProcessFull이 차원에 대해 수행될 경우, 영향받은 모든 큐브와 해당 파티션은 미처리 상태로 남아 있게 되며, 다음 예약 실행 때 완전하게 처리해야 합니다.
큰 파티션을 다시 처리하는 속도가 느리고 SSAS를 호스트하는 서버에서 많은 CPU 리소스를 사용하므로 파티션 처리를 신중하게 고려해야 합니다. 파티션 처리는 일반적으로 차원 처리보다 오래 걸립니다. 차원 처리와 달리 파티션 처리는 다른 개체에 대한 부작용이 없습니다. System Center - Service Manager OLAP 큐브에서 수행되는 두 가지 유형의 처리는 ProcessFull 및 ProcessAdd뿐입니다.
차원과 비슷하게 OLAP 큐브에 새로운 파티션을 만들려면 파티션이 쿼리 가능한 상태가 되도록 ProcessFull 작업이 필요합니다. ProcessFull 작업은 비용이 많이 들기 때문에 필요한 경우에만 ProcessFull 작업을 수행해야 합니다(예: 파티션을 만들거나 행이 업데이트된 경우). 행이 추가되고 행이 업데이트되지 않은 시나리오에서 Service Manager는 ProcessAdd 작업을 수행할 수 있습니다. 이를 위해 Service Manager는 워터마크 및 기타 메타데이터를 사용합니다. 특히 etl.cubepartition 테이블과 etl.tablepartition 테이블을 쿼리하여 어떤 유형의 처리를 수행할지 결정합니다.
다음 다이어그램에서는 Service Manager가 워터마크 데이터를 기반으로 수행할 처리 유형을 결정하는 방법을 보여 줍니다.
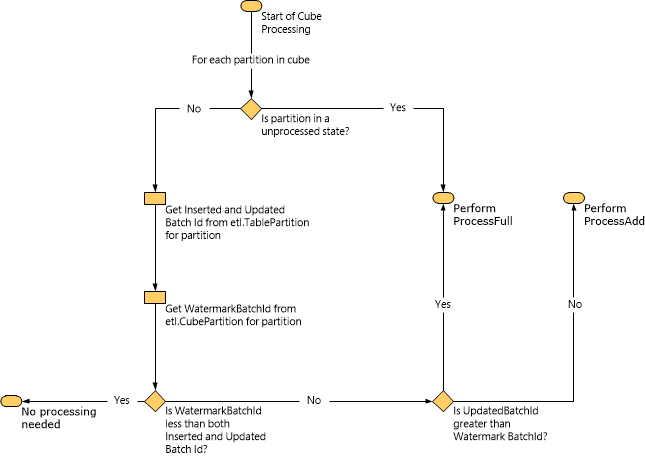
ProcessAdd 작업이 수행되면 Service Manager는 워터마크를 사용하여 쿼리 범위를 제한합니다. 예를 들어 InsertedBatchId 값이 100이고 WatermarkBatchId 값이 50인 경우, 쿼리는 InsertedBatchId가 50보다 크고 100보다 작은 데이터 마트에서만 데이터를 로드합니다.
마지막으로 Service Manager는 SSAS 또는 Business Intelligence Development Studio를 사용하여 OLAP 큐브의 수동 처리를 지원하지 않습니다. Service Manager 콘솔 및 Service Manager cmdlet을 포함하여 System Center - Service Manager에서 제공되는 메서드 외부에서 큐브를 처리하면 워터마크 테이블이 업데이트되지 않습니다. 따라서 데이터 무결성 문제가 발생할 수 있습니다. 실수로 큐브를 수동으로 다시 처리한 경우 한 가지 가능한 해결 방법은 OLAP 큐브를 동일한 방식으로 수동으로 처리 해제하는 것입니다. 그런 다음 Service Manager가 큐브를 처리할 때 파티션이 처리되지 않은 상태이므로 ProcessFull 작업을 자동으로 수행합니다. 따라서 모든 워터마크 및 메타데이터가 올바르게 업데이트되므로 가능한 모든 데이터 무결성 문제가 수정됩니다.
다음 섹션에서는 OLAP(온라인 분석 처리) 큐브에 대한 유지 관리 모범 사례를 설명합니다.
SSAS(SQL Server Analysis Services) 모범 사례에 따르면 SSAS 차원을 정기적으로 완전히 처리하는 것이 좋습니다. 차원을 완전히 처리하면 지수가 다시 구축되고 다차원 데이터의 데이터 스토리지가 최적화되어 시간이 지날 수록 저하될 수 있는 쿼리 및 큐브 성능이 향상됩니다. 이 작업은 컴퓨터의 하드 디스크를 정기적으로 조각 모음하는 것과 비슷합니다.
그러나 SSAS 차원 전체 처리의 단점은 영향받는 일부 OLAP 큐브는 처리되지 않는데, 쿼리할 수 있는 상태로 반환하려면 완전히 처리되어야 한다는 점입니다. Service Manager는 SSAS 차원에 대해 명시적으로 완전히 처리하지 않습니다. 따라서 이 유지 관리 작업을 언제 수행할지 결정해야 합니다.
모든 데이터 웨어하우스 ETL(추출, 변환 및 로드) 작업 및 OLAP 큐브 기능을 하나의 서버에서 실행하는 경우, 운영 체제, 데이터 웨어하우스 및 SSAS의 메모리 요구 사항을 신중히 고려하여 동시에 실행할 수 있는 모든 데이터 중심 작업을 서버가 처리할 수 있도록 합니다. 이는 OLAP 큐브 처리가 메모리 중심 작업이기 때문에 특히 중요합니다.
학습
학습 경로
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
이벤트
4월 29일 오후 2시 - 4월 30일 오후 7시
Join the ultimate Windows Server virtual event April 29-30 for deep-dive technical sessions and live Q&A with Microsoft engineers.
Sign up now