I/O 문제로 인한 느린 SQL Server 성능 문제 해결
적용 대상: SQL Server
이 문서에서는 느린 SQL Server 성능 저하를 일으키는 I/O 문제와 문제를 해결하는 방법에 대한 지침을 제공합니다.
느린 I/O 성능 정의
성능 모니터 카운터는 느린 I/O 성능을 결정하는 데 사용됩니다. 이러한 카운터는 I/O 하위 시스템이 시계 시간 측면에서 각 I/O 요청을 평균으로 서비스하는 속도를 측정합니다. Windows에서 I/O 대기 시간을 측정하는 특정 성능 모니터 카운터는 Avg Disk sec/ Read, Avg. Disk sec/Write및 (읽기 및 Avg. Disk sec/Transfer 쓰기 모두의 누적)입니다.
SQL Server 상황은 같은 방식으로 작동합니다. 일반적으로 SQL Server 클록 시간(밀리초)으로 측정된 I/O 병목 상태를 보고하는지 여부를 확인합니다. SQL Server , , ReadFile()WriteFileGather()ReadFileScatter()및 와 같은 WriteFile()Win32 함수를 호출하여 OS에 대한 I/O 요청을 수행합니다. I/O 요청을 게시할 때 요청의 시간을 SQL Server 대기 유형을 사용하여 요청 기간을 보고합니다. SQL Server 대기 유형을 사용하여 제품의 다른 위치에서 I/O 대기를 나타냅니다. I/O 관련 대기는 다음과 같습니다.
- / PAGEIOLATCH_SHPAGEIOLATCH_EX
- WRITELOG
- IO_COMPLETION
- ASYNC_IO_COMPLETION
- BACKUPIO
이러한 대기가 일관되게 10-15밀리초를 초과하는 경우 I/O는 병목 현상으로 간주됩니다.
참고
컨텍스트와 관점을 제공하기 위해 문제 해결 SQL Server 환경에서 Microsoft CSS는 I/O 요청이 1초 이상, 전송과 같은 I/O 시스템당 최대 15초가 최적화가 필요한 경우를 관찰했습니다. 반대로 Microsoft CSS는 처리량이 1밀리초/전송 미만인 시스템을 확인했습니다. 오늘날의 SSD/NVMe 기술을 통해 전송당 수십 마이크로초의 처리량 속도 범위를 보급했습니다. 따라서 10-15밀리초/전송 수치는 지난 몇 년 동안 Windows와 SQL Server 엔지니어 간의 집단 경험을 기반으로 선택한 매우 대략적인 임계값입니다. 일반적으로 숫자가 이 대략적인 임계값을 초과하면 SQL Server 사용자가 워크로드의 대기 시간을 보고하기 시작합니다. 궁극적으로 I/O 하위 시스템의 예상 처리량은 제조업체, 모델, 구성, 워크로드 및 잠재적으로 여러 다른 요인에 의해 정의됩니다.
방법론
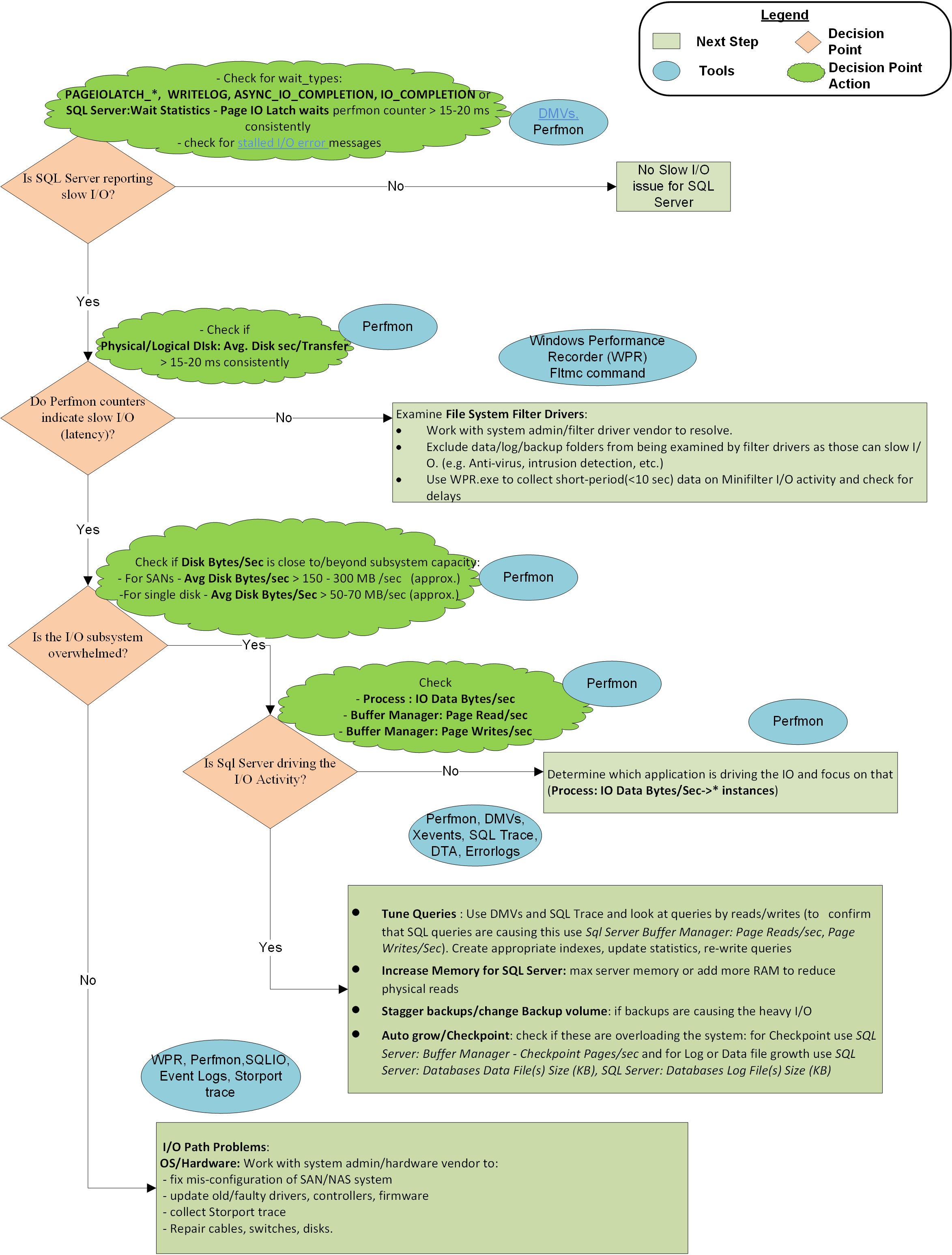
이 문서의 끝에 있는 흐름도에서는 Microsoft CSS가 SQL Server 느린 I/O 문제에 접근하는 데 사용하는 방법론을 설명합니다. 완전하거나 배타적인 접근 방식은 아니지만 문제를 격리하고 해결하는 데 유용하다는 것이 입증되었습니다.
다음 두 가지 옵션 중 하나를 선택하여 문제를 resolve 수 있습니다.
옵션 1: Azure Data Studio를 통해 Notebook에서 직접 단계 실행
참고
이 Notebook을 열기 전에 Azure Data Studio가 로컬 컴퓨터에 설치되어 있는지 확인합니다. 설치하려면 Azure Data Studio 설치 방법 알아보기로 이동하세요.
옵션 2: 수동으로 단계 수행
방법론은 다음 단계에 설명되어 있습니다.
1단계: SQL Server 보고 속도가 느린 I/O인가요?
SQL Server 여러 가지 방법으로 I/O 대기 시간을 보고할 수 있습니다.
- I/O 대기 유형
- Dmv
sys.dm_io_virtual_file_stats - 오류 로그 또는 애플리케이션 이벤트 로그
I/O 대기 유형
SQL Server 대기 유형에서 보고한 I/O 대기 시간이 있는지 확인합니다. 일반적으로 덜 일반적인 여러 대기 형식의 값 PAGEIOLATCH_*, WRITELOG및 ASYNC_IO_COMPLETION 값은 I/O 요청당 10~15밀리초 미만으로 유지되어야 합니다. 이러한 값이 일관되게 더 큰 경우 I/O 성능 문제가 존재하며 추가 조사가 필요합니다. 다음 쿼리는 시스템에서 이 진단 정보를 수집하는 데 도움이 될 수 있습니다.
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
sys.dm_io_virtual_file_stats 파일 통계
SQL Server 보고된 데이터베이스 파일 수준 대기 시간을 보려면 다음 쿼리를 실행합니다.
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
및 LatencyAssessment 열을 확인 AvgLatency 하여 대기 시간 세부 정보를 이해합니다.
오류 833이 Errorlog 또는 애플리케이션 이벤트 로그에 보고됨
경우에 따라 오류 로그에서 오류 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) 이 발생할 수 있습니다. 다음 PowerShell 명령을 실행하여 시스템에 오류 로그를 검사 SQL Server 수 있습니다.
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
또한 이 오류에 대한 자세한 내용은 MSSQLSERVER_833 섹션을 참조하세요.
2단계: Perfmon 카운터에서 I/O 대기 시간을 나타내나요?
SQL Server I/O 대기 시간을 보고하는 경우 OS 카운터를 참조하세요. 대기 시간 카운터 Avg Disk Sec/Transfer를 검사하여 I/O 문제가 있는지 확인할 수 있습니다. 다음 코드 조각은 PowerShell을 통해 이 정보를 수집하는 한 가지 방법을 나타냅니다. "_total" 모든 디스크 볼륨에 카운터를 수집합니다. 특정 드라이브 볼륨(예: "D:")으로 변경합니다. 데이터베이스 파일을 호스트하는 볼륨을 찾으려면 SQL Server 다음 쿼리를 실행합니다.
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Avg Disk Sec/Transfer 선택한 볼륨에 대한 메트릭 수집:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
이 카운터의 값이 지속적으로 10-15밀리초보다 높은 경우 문제를 추가로 확인해야 합니다. 간헐적인 스파이크는 대부분의 경우 계산되지 않지만 스파이크 기간을 두 번 검사 합니다. 스파이크가 1분 이상 지속된다면, 그것은 스파이크보다 고원에 가 만듭니다.
성능 모니터 카운터가 대기 시간을 보고하지 않지만 SQL Server 경우 문제는 SQL Server 파티션 관리자, 즉 필터 드라이버 사이입니다. 파티션 관리자는 OS가 Perfmon 카운터를 수집하는 I/O 계층입니다. 대기 시간을 해결하려면 필터 드라이버 및 필터 드라이버 문제를 적절히 제외하고 resolve. 필터 드라이버는 바이러스 백신 소프트웨어, 백업 솔루션, 암호화, 압축 등과 같은 프로그램에서 사용됩니다. 이 명령을 사용하여 시스템 및 연결된 볼륨의 필터 드라이버를 나열할 수 있습니다. 그런 다음 할당된 필터 고도 문서에서 드라이버 이름 및 소프트웨어 공급업체를 조회할 수 있습니다.
fltmc instances
자세한 내용은 SQL Server 실행 중인 컴퓨터에서 실행할 바이러스 백신 소프트웨어를 선택하는 방법을 참조하세요.
비동기 I/O가 동기적으로 느려지므로 EFS(파일 시스템 암호화) 및 파일 시스템 압축을 사용하지 마세요. 자세한 내용은 Windows에서 비동기 디스크 I/O가 동기로 표시 됨 문서를 참조하세요.
3단계: I/O 하위 시스템이 용량을 초과하여 과부하가 발생하나요?
SQL Server OS에서 I/O 하위 시스템이 느리다는 것을 나타내는 경우 검사 원인이 시스템이 용량을 초과하여 과부하되는 경우 입니다. I/O 카운터 , Disk Read Bytes/Sec또는 Disk Write Bytes/Sec를 보고 용량을 검사 수 있습니다Disk Bytes/Sec. SAN(또는 기타 I/O 하위 시스템)에 대한 예상 처리량 사양에 대해 시스템 관리자 또는 하드웨어 공급업체와 검사 합니다. 예를 들어 SAN 스위치에서 2GB/초 HBA 카드 또는 2GB/초 전용 포트를 통해 200MB/초 이하의 I/O를 푸시할 수 있습니다. 하드웨어 제조업체에서 정의한 예상 처리량 용량은 여기에서 진행하는 방법을 정의합니다.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
4단계: SQL Server 무거운 I/O 활동을 주도하고 있나요?
I/O 하위 시스템이 용량을 초과하여 과부하가 발생하는 경우 특정 instance 대한 (가장 일반적인 원인 Buffer Manager: Page Reads/Sec ) 및 Page Writes/Sec (훨씬 덜 일반적인) SQL Server 원인인지 확인합니다. SQL Server 기본 I/O 드라이버이고 I/O 볼륨이 시스템에서 처리할 수 있는 것 이상인 경우 애플리케이션 개발 팀 또는 애플리케이션 공급업체와 협력하여 다음을 수행합니다.
- 쿼리를 조정합니다(예: 더 나은 인덱스, 통계 업데이트, 쿼리 다시 작성 및 데이터베이스 다시 디자인).
- 최대 서버 메모리를 늘리거나 시스템에 RAM을 더 추가합니다. 더 많은 RAM은 디스크에서 자주 다시 읽지 않고 더 많은 데이터 또는 인덱스 페이지를 캐시하므로 I/O 작업이 줄어듭니다.
원인
일반적으로 다음과 같은 문제는 SQL Server 쿼리에 I/O 대기 시간이 발생하는 높은 수준의 이유입니다.
하드웨어 문제:
SAN 잘못된 구성(스위치, 케이블, HBA, 스토리지)
초과된 I/O 용량(백 엔드 스토리지뿐만 아니라 전체 SAN 네트워크 전체에서 불균형)
드라이버 또는 펌웨어 문제
하드웨어 공급업체 및/또는 시스템 관리자는 이 단계에서 참여해야 합니다.
쿼리 문제: SQL Server I/O 요청으로 디스크 볼륨을 포화시키고 I/O 하위 시스템을 용량 이상으로 푸시하여 I/O 전송 속도가 높아집니다. 이 경우 솔루션은 많은 수의 논리적 읽기(또는 쓰기)를 유발하는 쿼리를 찾고 해당 쿼리를 조정하여 적절한 인덱스를 사용하는 디스크 I/O를 최소화하는 것이 첫 번째 단계입니다. 또한 최상의 계획을 선택할 수 있는 충분한 정보를 쿼리 최적화 프로그램에 제공하므로 통계를 업데이트된 상태로 유지합니다. 또한 잘못된 데이터베이스 디자인 및 쿼리 디자인으로 인해 I/O 문제가 증가할 수 있습니다. 따라서 쿼리 및 테이블을 다시 디자인하면 향상된 I/O에 도움이 될 수 있습니다.
필터 드라이버: 파일 시스템 필터 드라이버가 많은 I/O 트래픽을 처리하는 경우 SQL Server I/O 응답에 심각한 영향을 미칠 수 있습니다. I/O 성능에 영향을 주지 않도록 소프트웨어 공급업체의 바이러스 백신 검사 및 올바른 필터 드라이버 디자인에서 적절한 파일 제외를 사용하는 것이 좋습니다.
기타 애플리케이션: SQL Server 있는 동일한 컴퓨터의 다른 애플리케이션은 과도한 읽기 또는 쓰기 요청으로 I/O 경로를 포화시킬 수 있습니다. 이 경우 I/O 하위 시스템이 용량 제한을 초과하여 SQL Server I/O 속도가 느려질 수 있습니다. 애플리케이션을 식별하고 조정하거나 다른 곳으로 이동하여 I/O 스택에 미치는 영향을 제거합니다.
방법론의 그래픽 표현
I/O 관련 대기 유형에 대한 정보
다음은 디스크 I/O 문제가 보고될 때 SQL Server 관찰되는 일반적인 대기 유형에 대한 설명입니다.
PAGEIOLATCH_EX
태스크가 I/O 요청의 데이터 또는 인덱스 페이지(버퍼)에 대한 래치에서 대기하는 경우에 발생합니다. 래치 요청이 배타적 모드에 있습니다. 버퍼가 디스크에 기록될 때 배타적 모드가 사용됩니다. 긴 대기는 디스크 하위 시스템에 문제가 있음을 나타낼 수 있습니다.
PAGEIOLATCH_SH
태스크가 I/O 요청의 데이터 또는 인덱스 페이지(버퍼)에 대한 래치에서 대기하는 경우에 발생합니다. 래치 요청이 공유 모드에 있습니다. 공유 모드는 디스크에서 버퍼를 읽을 때 사용됩니다. 긴 대기는 디스크 하위 시스템에 문제가 있음을 나타낼 수 있습니다.
PAGEIOLATCH_UP
태스크가 I/O 요청에서 버퍼에 대한 래치를 대기할 때 발생합니다. 래치 요청이 업데이트 모드에 있습니다. 긴 대기는 디스크 하위 시스템에 문제가 있음을 나타낼 수 있습니다.
WRITELOG
태스크가 트랜잭션 로그 플러시 완료를 기다리는 경우에 발생합니다. 플러시 는 Log Manager가 임시 콘텐츠를 디스크에 쓸 때 발생합니다. 로그 플러시를 유발하는 일반적인 작업은 트랜잭션 커밋 및 검사점입니다.
대기 시간이 긴 WRITELOG 일반적인 이유는 다음과 같습니다.
트랜잭션 로그 디스크 대기 시간: 대기의
WRITELOG가장 일반적인 원인입니다. 일반적으로 데이터 및 로그 파일을 별도의 볼륨에 유지하는 것이 좋습니다. 트랜잭션 로그 쓰기는 데이터 파일에서 데이터를 읽거나 쓰는 동안 순차적 쓰기입니다. 데이터와 로그 파일을 하나의 드라이브 볼륨(특히 기존의 회전 디스크 드라이브)에 혼합하면 디스크 헤드 이동이 과도하게 발생합니다.VLL이 너무 많음: VLLF(가상 로그 파일)가 너무 많으면 대기가 발생할
WRITELOG수 있습니다. VLF가 너무 많으면 장기 복구와 같은 다른 유형의 문제가 발생할 수 있습니다.너무 많은 작은 트랜잭션: 큰 트랜잭션이 차단으로 이어질 수 있지만 너무 많은 작은 트랜잭션이 다른 문제 집합으로 이어질 수 있습니다. 트랜잭션을 명시적으로 시작하지 않으면 삽입, 삭제 또는 업데이트로 인해 트랜잭션이 발생합니다(이 자동 트랜잭션이라고 함). 루프에서 1,000개의 삽입을 수행하는 경우 1,000개의 트랜잭션이 생성됩니다. 이 예제의 각 트랜잭션은 커밋해야 하므로 트랜잭션 로그가 플러시되고 1,000개의 트랜잭션이 플러시됩니다. 가능하면 개별 업데이트, 삭제 또는 삽입을 더 큰 트랜잭션에 그룹화하여 트랜잭션 로그 플러시를 줄이고 성능을 향상시킵니다. 이 작업을 수행하면 대기 시간이 줄어들
WRITELOG수 있습니다.예약 문제로 인해 로그 기록기 스레드가 충분히 빠르게 예약되지 않습니다. 2016년 SQL Server 이전에는 단일 로그 기록기 스레드가 모든 로그 쓰기를 수행했습니다. 스레드 예약(예: 높은 CPU)에 문제가 있는 경우 로그 기록기 스레드와 로그 플러시 모두 지연될 수 있습니다. 2016년 SQL Server 로그 쓰기 처리량을 늘리기 위해 최대 4개의 로그 기록기 스레드가 추가되었습니다. SQL 2016 - 더 빠르게 실행: 여러 로그 기록기 작업자를 참조하세요. 2019년 SQL Server 최대 8개의 로그 기록기 스레드가 추가되어 처리량이 더욱 향상되었습니다. 또한 2019년 SQL Server 각 일반 작업자 스레드는 로그 기록기 스레드에 게시하는 대신 직접 로그 쓰기를 수행할 수 있습니다. 이러한 개선 사항으로 인해
WRITELOG예약 문제로 인해 대기가 거의 트리거되지 않습니다.
ASYNC_IO_COMPLETION
다음 I/O 작업 중 일부가 발생할 때 발생합니다.
- 대량 삽입 공급자("대량 삽입")는 I/O를 수행할 때 이 대기 유형을 사용합니다.
- LogShipping에서 실행 취소 파일을 읽고 로그 전달을 위해 비동기 I/O를 지시합니다.
- 데이터 백업 중에 데이터 파일에서 실제 데이터를 읽습니다.
IO_COMPLETION
I/O 작업이 완료되길 기다리는 동안 발생합니다. 이 대기 유형에는 일반적으로 데이터 페이지(버퍼)와 관련이 없는 I/O가 포함됩니다. 예를 들면 다음과 같습니다.
- 유출(tempdb 스토리지의 성능 검사) 동안 디스크에서/디스크로 정렬/해시 결과를 읽고 씁니다.
- 디스크에 대한 열성 스풀 읽기 및 쓰기(tempdb 스토리지 검사).
- 트랜잭션 로그에서 로그 블록을 읽습니다(디스크에서 로그를 읽게 하는 작업(예: 복구).
- 데이터베이스가 아직 설정되지 않은 경우 디스크에서 페이지를 읽습니다.
- 데이터베이스 스냅샷 페이지 복사(쓰기에 복사).
- 데이터베이스 파일 및 파일 압축 해제를 닫습니다.
BACKUPIO
백업 작업이 데이터를 대기하거나 버퍼가 데이터를 저장하기를 기다리는 경우에 발생합니다. 태스크가 테이프 탑재를 기다리는 경우를 제외하고 이 형식은 일반적이지 않습니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기