게임 개발용 CPUSets
소개
UWP(유니버설 Windows 플랫폼)는 광범위한 소비자 전자 디바이스의 핵심입니다. 따라서 게임에서 임베디드 앱, 서버에서 실행되는 엔터프라이즈 소프트웨어에 이르기까지 모든 유형의 애플리케이션의 요구를 해결하기 위해 범용 API가 필요합니다. API에서 제공하는 올바른 정보를 활용하여 모든 하드웨어에서 게임이 최상의 상태로 실행되도록 할 수 있습니다.
CPUSets API
CPUSets API는 예약할 스레드에 사용할 수 있는 CPU 집합을 제어합니다. 스레드가 예약되는 위치를 제어하는 데 사용할 수 있는 두 가지 함수는 다음과 같습니다.
- SetProcessDefaultCpuSets – 이 함수를 사용하여 특정 CPU 집합에 할당되지 않은 경우 새 스레드가 실행될 수 있는 CPU 집합을 지정할 수 있습니다.
- SetThreadSelectedCpuSets – 이 함수를 사용하면 특정 스레드가 실행될 수 있는 CPU 집합을 제한할 수 있습니다.
SetProcessDefaultCpuSets 함수를 사용하지 않는 경우 프로세스에 사용할 수 있는 모든 CPU 집합에서 새로 만든 스레드가 예약될 수 있습니다. 이 섹션에서는 CPUSets API의 기본 사항을 설명합니다.
GetSystemCpuSetInformation
정보를 수집하는 데 사용되는 첫 번째 API는 GetSystemCpuSetInformation 함수입니다. 이 함수는 타이틀 코드에서 제공하는 SYSTEM_CPU_SET_INFORMATION 개체 배열의 정보를 채웁니다. 대상의 메모리는 게임 코드에 의해 할당되어야 하며, 크기는 GetSystemCpuSetInformation 자체를 호출하여 결정됩니다. 다음 예제와 같이 GetSystemCpuSetInformation에 대한 두 가지 호출이 필요합니다.
unsigned long size;
HANDLE curProc = GetCurrentProcess();
GetSystemCpuSetInformation(nullptr, 0, &size, curProc, 0);
std::unique_ptr<uint8_t[]> buffer(new uint8_t[size]);
PSYSTEM_CPU_SET_INFORMATION cpuSets = reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(buffer.get());
GetSystemCpuSetInformation(cpuSets, size, &size, curProc, 0);
반환된 SYSTEM_CPU_SET_INFORMATION 각 인스턴스에는 CPU 집합이라고도 하는 하나의 고유한 처리 장치에 대한 정보가 포함되어 있습니다. 그렇다고 해서 하드웨어의 고유한 물리적 부분을 나타내는 것은 아닙니다. 하이퍼스레딩을 활용하는 CPU에는 단일 물리적 처리 코어에서 실행되는 여러 논리 코어가 있습니다. 동일한 물리적 코어에 상주하는 다른 논리 코어에서 여러 스레드를 예약하면 하드웨어 수준 리소스 최적화가 가능하며, 그렇지 않으면 커널 수준에서 추가 작업을 수행해야 합니다. 동일한 물리적 코어의 별도 논리 코어에 예약된 두 스레드는 CPU 시간을 공유해야 하지만 동일한 논리 코어로 예약된 경우보다 더 효율적으로 실행됩니다.
SYSTEM_CPU_SET_INFORMATION
GetSystemCpuSetInformation에서 반환된 이 데이터 구조의 각 인스턴스에 있는 정보에는 스레드가 예약될 수 있는 고유한 처리 장치에 대한 정보가 포함되어 있습니다. 가능한 대상 디바이스 범위를 감안할 때 SYSTEM_CPU_SET_INFORMATION 데이터 구조의 많은 정보가 게임 개발에 적용되지 않을 수 있습니다. 표 1에서는 게임 개발에 유용한 데이터 멤버에 대한 설명을 제공합니다.
표 1. 게임 개발에 유용한 데이터 멤버입니다.
| 멤버 이름 | 데이터 형식 | 설명 |
|---|---|---|
| Type | CPU_SET_INFORMATION_TYPE | 구조체의 정보 유형입니다. 이 값이 CpuSetInformation이 아니면 무시해야 합니다. |
| ID | unsigned long | 지정된 CPU 집합의 ID입니다. SetThreadSelectedCpuSets와 같은 CPU 집합 함수와 함께 사용해야 하는 ID입니다. |
| 그룹 | unsigned short | CPU 집합의 "프로세서 그룹"을 지정합니다. 프로세서 그룹을 사용하면 PC에 64개 이상의 논리 코어가 있으며 시스템이 실행되는 동안 CPU를 핫 스왑할 수 있습니다. 둘 이상의 그룹이 있는 서버가 아닌 PC를 보는 것은 드문 일입니다. 대규모 서버 또는 서버 팜에서 실행하기 위한 애플리케이션을 작성하지 않는 한 대부분의 소비자 PC에는 프로세서 그룹이 하나만 있으므로 단일 그룹에서 CPU 집합을 사용하는 것이 가장 좋습니다. 이 구조의 다른 모든 값은 그룹을 기준으로 합니다. |
| LogicalProcessorIndex | unsigned char | CPU 집합의 그룹 상대 인덱스 |
| CoreIndex | unsigned char | CPU 집합이 있는 실제 CPU 코어의 상대 인덱스 그룹화 |
| LastLevelCacheIndex | unsigned char | 이 CPU 집합과 연결된 마지막 캐시의 상대 인덱스 그룹화 시스템이 NUMA 노드(일반적으로 L2 또는 L3 캐시)를 사용하지 않는 한 가장 느린 캐시입니다. |
다른 데이터 멤버는 소비자 PC 또는 다른 소비자 디바이스에서 CPU를 설명할 가능성이 낮고 유용하지 않은 정보를 제공합니다. 반환된 데이터에서 제공하는 정보를 사용하여 다양한 방법으로 스레드를 구성할 수 있습니다. 이 백서의 게임 개발 고려 사항 섹션에서는 이 데이터를 활용하여 스레드 할당을 최적화하는 몇 가지 방법을 자세히 설명합니다.
다음은 다양한 유형의 하드웨어에서 실행되는 UWP 애플리케이션에서 수집된 정보 형식의 몇 가지 예입니다.
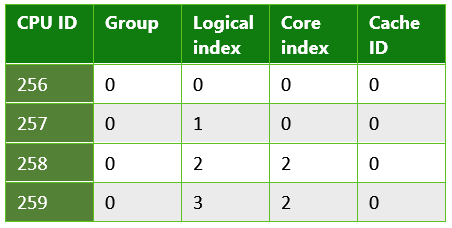
표 2. Microsoft Lumia 950에서 실행되는 UWP 앱에서 반환된 정보입니다. 마지막 수준 캐시가 여러 대 있는 시스템의 예입니다. Lumia 950은 듀얼 코어 Arm Cortex A57 및 쿼드 코어 Arm Cortex A53 CPU를 포함하는 퀄컴 808 스냅드래곤 프로세스를 갖추고 있습니다.
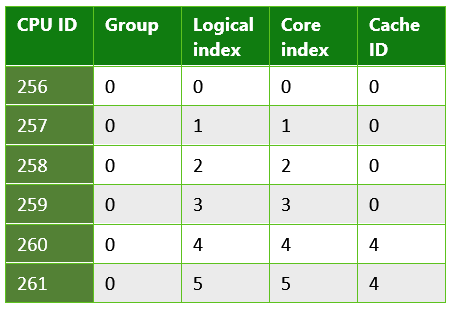
표 3. 일반적인 PC에서 실행되는 UWP 앱에서 반환되는 정보입니다. 하이퍼스레딩을 사용하는 시스템의 예입니다. 각 물리적 코어에는 스레드를 예약할 수 있는 두 개의 논리 코어가 있습니다. 이 경우 시스템에 Intel Xenon CPU E5-2620이 포함되어 있습니다.
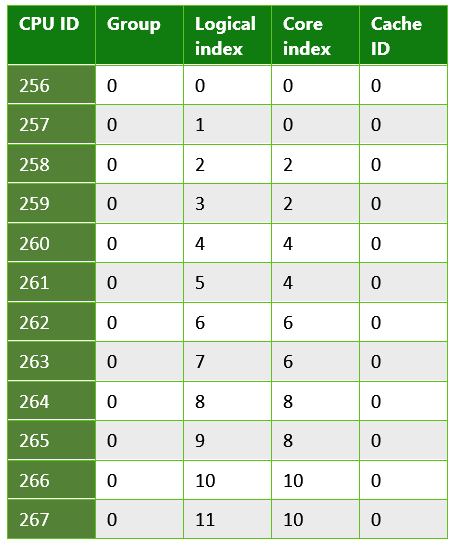
표 4. 쿼드 코어 Microsoft Surface Pro 4에서 실행되는 UWP 앱에서 반환된 정보입니다. 이 시스템에는 Intel Core i5-6300 CPU가 있습니다.
SetThreadSelectedCpuSets
이제 CPU 집합에 대한 정보를 사용할 수 있으므로 스레드를 구성하는 데 사용할 수 있습니다. CreateThread를 사용하여 만든 스레드의 핸들은 스레드를 예약할 수 있는 CPU 집합의 ID 배열과 함께 이 함수에 전달됩니다. 해당 사용의 한 가지 예는 다음 코드에 설명되어 있습니다.
HANDLE audioHandle = CreateThread(nullptr, 0, AudioThread, nullptr, 0, nullptr);
unsigned long cores [] = { cpuSets[0].CpuSet.Id, cpuSets[1].CpuSet.Id };
SetThreadSelectedCpuSets(audioHandle, cores, 2);
이 예제에서는 AudioThread로 선언된 함수를 기반으로 스레드가 만들어집니다. 그런 다음 두 CPU 집합 중 하나에서 이 스레드를 예약할 수 있습니다. CPU 집합의 스레드 소유권은 배타적이지 않습니다. 특정 CPU 집합에 잠기지 않고 만든 스레드는 AudioThread에서 시간이 걸릴 수 있습니다. 마찬가지로 생성된 다른 스레드도 나중에 이러한 CPU 집합 중 하나 또는 둘 다에 잠글 수 있습니다.
SetProcessDefaultCpuSets
SetThreadSelectedCpuSets의 반대는 SetProcessDefaultCpuSets입니다. 스레드를 만들 때 특정 CPU 집합에 잠글 필요가 없습니다. 이러한 스레드가 특정 CPU 집합(예: 렌더링 스레드 또는 오디오 스레드에서 사용되는)에서 실행되지 않도록 하려면 이 함수를 사용하여 이러한 스레드를 예약할 수 있는 코어를 지정할 수 있습니다.
게임 개발 고려 사항
앞에서 설명한 것처럼 CPUSets API는 스레드 예약과 관련하여 많은 정보와 유연성을 제공합니다. 이 데이터에 대한 사용을 찾기 위해 상향식 접근 방식을 취하는 대신 일반적인 시나리오를 수용하는 데 데이터를 사용할 수 있는 방법을 찾는 하향식 접근 방식을 사용하는 것이 더 효과적입니다.
시간이 중요한 스레드 및 하이퍼스레딩 작업
이 방법은 게임에 CPU 시간이 상대적으로 적은 다른 작업자 스레드와 함께 실시간으로 실행되어야 하는 몇 개의 스레드가 있는 경우에 효과적입니다. 연속 배경 음악과 같은 일부 작업은 최적의 게임 환경을 위해 중단 없이 실행되어야 합니다. 오디오 스레드에 대한 단일 프레임이 부족해도 터지거나 결함이 발생할 수 있으므로 프레임마다 필요한 양의 CPU 시간을 수신하는 것이 중요합니다.
SetProcessDefaultCpuSets와 함께 SetThreadSelectedCpuSets를 사용하면 작업자 스레드에서 많은 스레드가 관여받지 않게 할 수 있습니다. SetThreadSelectedCpuSets 를 사용하여 특정 CPU 집합에 무거운 스레드를 할당할 수 있습니다. 그런 다음 SetProcessDefaultCpuSets 를 사용하여 만든 할당되지 않은 스레드가 다른 CPU 집합에 배치되도록 할 수 있습니다. 하이퍼스레딩을 활용하는 CPU의 경우 동일한 물리적 코어에서 논리 코어를 고려하는 것도 중요합니다. 작업자 스레드는 실시간 응답성으로 실행하려는 스레드와 동일한 물리적 코어를 공유하는 논리 코어에서 실행할 수 없습니다. 다음 코드는 PC에서 하이퍼스레딩을 사용하는지 여부를 확인하는 방법을 보여 줍니다.
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::set<DWORD> cores;
std::vector<DWORD> processors;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
processors.push_back( info->CpuSet.Id );
cores.insert( info->CpuSet.CoreIndex );
}
ptr += info->Size;
size += info->Size;
}
bool hyperthreaded = processors.size() != cores.size();
시스템에서 하이퍼스레딩을 사용하는 경우 기본 CPU 집합 집합에 실시간 스레드와 동일한 물리적 코어에 논리 코어가 포함되지 않는 것이 중요합니다. 시스템이 하이퍼스레딩하지 않는 경우 기본 CPU 집합에 오디오 스레드를 실행하는 CPU 집합과 동일한 코어가 포함되지 않도록 해야 합니다.
물리적 코어를 기반으로 스레드를 구성하는 예제는 추가 리소스 섹션에 연결된 GitHub 리포지토리에서 사용할 수 있는 CPUSets 샘플에서 찾을 수 있습니다 .
마지막 수준 캐시와의 캐시 일관성 비용 절감
캐시 일관성은 캐시된 메모리가 동일한 데이터에 대해 작동하는 여러 하드웨어 리소스에서 동일하다는 개념입니다. 스레드가 서로 다른 코어에서 예약되지만 동일한 데이터에서 작동하는 경우 서로 다른 캐시에 있는 해당 데이터의 별도 복사본에서 작업할 수 있습니다. 올바른 결과를 얻으려면 이러한 캐시를 서로 일관되게 유지해야 합니다. 여러 캐시 간의 일관성 유지는 비교적 비용이 많이 들지만 모든 다중 코어 시스템이 작동하려면 필요합니다. 또한 클라이언트 코드를 완전히 제어할 수 없습니다. 기본 시스템은 코어 간의 공유 메모리 리소스에 액세스하여 캐시를 최신 상태로 유지하기 위해 독립적으로 작동합니다.
게임에 특히 많은 양의 데이터를 공유하는 여러 스레드가 있는 경우 마지막 수준 캐시를 공유하는 CPU 집합에서 예약되도록 하여 캐시 일관성 비용을 최소화할 수 있습니다. 마지막 수준 캐시는 NUMA 노드를 활용하지 않는 시스템의 코어에서 사용할 수 있는 가장 느린 캐시입니다. 게임 PC에서 NUMA 노드를 활용하는 경우는 극히 드뭅니다. 코어가 마지막 수준 캐시를 공유하지 않는 경우 기본 일관성을 유지하려면 더 높은 수준의 메모리 리소스에 액세스해야 하므로 속도가 느려집니다. 캐시와 물리적 코어를 공유하는 별도의 CPU 집합에 두 스레드를 잠그면 지정된 프레임에서 50% 이상의 시간이 필요하지 않은 경우 별도의 물리적 코어에서 예약하는 것보다 성능이 훨씬 향상될 수 있습니다.
이 코드 예제에서는 자주 통신하는 스레드가 마지막 수준 캐시를 공유할 수 있는지 여부를 확인하는 방법을 보여 줍니다.
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation(nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data(new uint8_t[retsize]);
if (!GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(data.get()),
retsize, &retsize, GetCurrentProcess(), 0))
{
// Error!
}
unsigned long count = retsize / sizeof(SYSTEM_CPU_SET_INFORMATION);
bool sharedcache = false;
std::map<unsigned char, std::vector<SYSTEM_CPU_SET_INFORMATION>> cachemap;
for (size_t i = 0; i < count; ++i)
{
auto cpuset = reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(data.get())[i];
if (cpuset.Type == CPU_SET_INFORMATION_TYPE::CpuSetInformation)
{
if (cachemap.find(cpuset.CpuSet.LastLevelCacheIndex) == cachemap.end())
{
std::pair<unsigned char, std::vector<SYSTEM_CPU_SET_INFORMATION>> newvalue;
newvalue.first = cpuset.CpuSet.LastLevelCacheIndex;
newvalue.second.push_back(cpuset);
cachemap.insert(newvalue);
}
else
{
sharedcache = true;
cachemap[cpuset.CpuSet.LastLevelCacheIndex].push_back(cpuset);
}
}
}
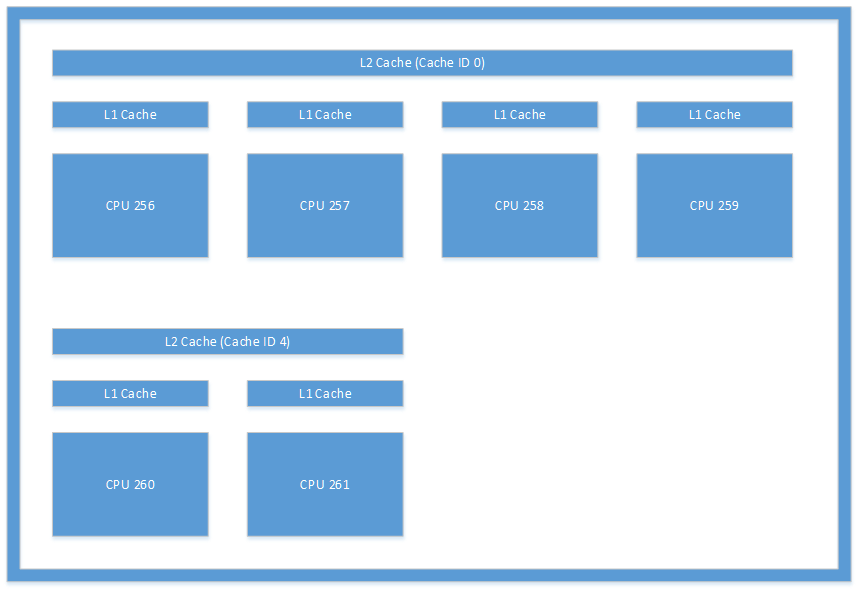
그림 1에 표시된 캐시 레이아웃은 시스템에서 볼 수 있는 레이아웃 형식의 예입니다. 이 그림은 Microsoft Lumia 950에 있는 캐시의 그림입니다. CPU 256과 CPU 260 사이에 발생하는 스레드 간 통신은 시스템이 L2 캐시를 일관되게 유지해야 하므로 상당한 오버헤드가 발생합니다.
그림 1. Microsoft Lumia 950 디바이스에 있는 캐시 아키텍처입니다.
요약
UWP 개발에 사용할 수 있는 CPUSets API는 다중 스레딩 옵션에 대한 상당한 정보와 제어를 제공합니다. Windows 개발을 위한 이전 다중 스레드 API에 비해 복잡성이 더해졌지만, 유연성이 향상되면 궁극적으로 다양한 소비자 PC 및 기타 하드웨어 대상에서 성능이 향상됩니다.
추가 리소스
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기