Xamarin.iOS의 음성 인식
이 문서에서는 새 Speech API를 제공하고 Xamarin.iOS 앱에서 이를 구현하여 연속 음성 인식을 지원하고 음성(라이브 또는 녹음된 오디오 스트림에서)을 텍스트로 전사하는 방법을 보여 줍니다.
iOS 10을 처음 접하는 Apple은 iOS 앱이 연속 음성 인식을 지원하고 음성을 라이브 또는 녹음된 오디오 스트림에서 텍스트로 전사할 수 있도록 하는 음성 인식 API를 릴리스했습니다.
Apple에 따르면 Speech Recognition API에는 다음과 같은 기능과 이점이 있습니다.
- 매우 정확도
- 최첨단
- 사용 용이
- 고속
- 여러 언어 지원
- 사용자 개인 정보 보호 존중
음성 인식 작동 방식
음성 인식은 라이브 또는 미리 녹음된 오디오(API에서 지원하는 음성 언어)를 획득하고 음성 단어의 일반 텍스트 전사를 반환하는 Speech Recognizer에 전달하여 iOS 앱에서 구현됩니다.

키보드 받아쓰기
대부분의 사용자가 iOS 디바이스에서 음성 인식을 생각할 때 iOS 5의 키보드 받아쓰기와 함께 i전화 4S와 함께 출시된 기본 제공 Siri 음성 도우미 생각합니다.
키보드 받아쓰기는 TextKit(예: UITextField 또는 UITextArea)을 지원하는 모든 인터페이스 요소에서 지원되며 iOS 가상 키보드에서 받아쓰기 단추(스페이스바의 왼쪽에 직접)를 클릭하면 활성화됩니다.
Apple은 다음과 같은 키보드 받아쓰기 통계(2011년부터 수집됨)를 발표했습니다.
- 키보드 받아쓰기 iOS에서 출시 된 이후 널리 사용 되었습니다 5.
- 하루에 약 65,000개의 앱이 이 앱을 사용합니다.
- 모든 iOS 받아쓰기의 약 3분의 1은 타사 앱에서 수행됩니다.
키보드 받아쓰기는 앱의 UI 디자인에서 TextKit 인터페이스 요소를 사용하는 것 외에는 개발자가 노력하지 않아도 되므로 사용하기가 매우 쉽습니다. 키보드 받아쓰기 기능을 사용하기 전에 앱에서 특별한 권한 요청을 요구하지 않는다는 장점도 있습니다.
음성 인식에는 Apple 서버의 데이터를 전송하고 임시로 저장해야 하므로 새 음성 인식 API를 사용하는 앱에는 사용자가 특별한 권한을 부여해야 합니다. 자세한 내용은 보안 및 개인 정보 향상 설명서를 참조하세요.
키보드 받아쓰기는 쉽게 구현할 수 있지만 다음과 같은 몇 가지 제한 사항과 단점이 있습니다.
- 텍스트 입력 필드를 사용하고 키보드를 표시해야 합니다.
- 라이브 오디오 입력에서만 작동하며 앱은 오디오 녹음 프로세스를 제어할 수 없습니다.
- 사용자의 음성을 해석하는 데 사용되는 언어를 제어할 수 없습니다.
- 사용자가 받아쓰기 단추를 사용할 수 있는지 앱을 알 수 있는 방법은 없습니다.
- 앱에서 오디오 녹음 프로세스를 사용자 지정할 수 없습니다.
- 타이밍 및 신뢰도와 같은 정보가 부족한 매우 얕은 결과 집합을 제공합니다.
음성 인식 API
iOS 10을 새롭게 출시한 Apple은 iOS 앱이 음성 인식을 구현할 수 있는 보다 강력한 방법을 제공하는 음성 인식 API를 출시했습니다. 이 API는 Apple이 Siri와 키보드 받아쓰기를 모두 구동하는 데 사용하는 것과 동일하며 최신 정확도로 빠른 전사를 제공할 수 있습니다.
Speech Recognition API에서 제공하는 결과는 앱이 개인 사용자 데이터를 수집하거나 액세스할 필요 없이 개별 사용자에게 투명하게 사용자 지정됩니다.
음성 인식 API는 사용자가 말하는 동안 거의 실시간으로 호출 앱에 결과를 다시 제공하며 텍스트보다 번역 결과에 대한 자세한 정보를 제공합니다. 여기에는 다음이 포함됩니다.
- 사용자가 말한 내용에 대한 여러 해석입니다.
- 개별 번역에 대한 신뢰 수준입니다.
- 타이밍 정보입니다.
위에서 설명한 대로 번역 오디오는 라이브 피드 또는 미리 녹음된 원본 및 iOS 10에서 지원하는 50개 이상의 언어 및 방언으로 제공할 수 있습니다.
음성 인식 API는 iOS 10을 실행하는 모든 iOS 디바이스에서 사용할 수 있으며 대부분의 경우 Apple 서버에서 대량의 번역이 수행되므로 라이브 인터넷 연결이 필요합니다. 즉, 일부 최신 iOS 디바이스는 특정 언어의 온-디바이스 번역을 항상 지원합니다.
Apple은 현재 지정된 언어를 번역에 사용할 수 있는지 확인하기 위해 가용성 API를 포함했습니다. 앱은 인터넷 연결 자체를 직접 테스트하는 대신 이 API를 사용해야 합니다.
키보드 받아쓰기 섹션에서 위에서 설명한 것처럼 음성 인식은 인터넷을 통해 Apple 서버의 데이터를 전송하고 임시로 저장해야 하며, 따라서 앱은 파일에 키를 Info.plist 포함하고 NSSpeechRecognitionUsageDescription 메서드를 호출 SFSpeechRecognizer.RequestAuthorization 하여 사용자의 인식 권한을 요청해야 합니다.
음성 인식에 사용되는 오디오의 원본에 따라 앱 파일의 Info.plist 다른 변경이 필요할 수 있습니다. 자세한 내용은 보안 및 개인 정보 향상 설명서를 참조하세요.
앱에서 음성 인식 채택
개발자가 iOS 앱에서 음성 인식을 채택하기 위해 수행해야 하는 네 가지 주요 단계가 있습니다.
- 키를 사용하여
NSSpeechRecognitionUsageDescription앱Info.plist파일에 사용 설명을 제공합니다. 예를 들어 카메라 앱에는 "'cheese'라는 단어를 말하는 것만으로 사진을 찍을 수 있습니다."라는 설명 이 포함될 수 있습니다. - 앱이
SFSpeechRecognizer.RequestAuthorization대화 상자에서 사용자에게 음성 인식 액세스를 원하는 이유에 대한 설명(위의 키에NSSpeechRecognitionUsageDescription제공됨)을 표시하고 수락 또는 거부를 허용하는 방법을 호출하여 권한 부여를 요청합니다. - 음성 인식 요청을 만듭니다.
- 디스크에서 미리 녹음된 오디오의 경우 클래스를
SFSpeechURLRecognitionRequest사용합니다. - 라이브 오디오(또는 메모리의 오디오)의 경우 클래스를
SFSPeechAudioBufferRecognitionRequest사용합니다.
- 디스크에서 미리 녹음된 오디오의 경우 클래스를
- 음성 인식 요청을 음성 인식기(
SFSpeechRecognizer)에 전달하여 인식을 시작합니다. 앱은 필요에 따라 반환SFSpeechRecognitionTask된 내용을 유지하여 인식 결과를 모니터링하고 추적할 수 있습니다.
이러한 단계는 아래에서 자세히 설명합니다.
사용 설명 제공
파일에 필요한 NSSpeechRecognitionUsageDescription 키를 Info.plist 제공하려면 다음을 수행합니다.
파일을 두 번 클릭하여
Info.plist편집용으로 엽니다.원본 보기로 전환합니다.
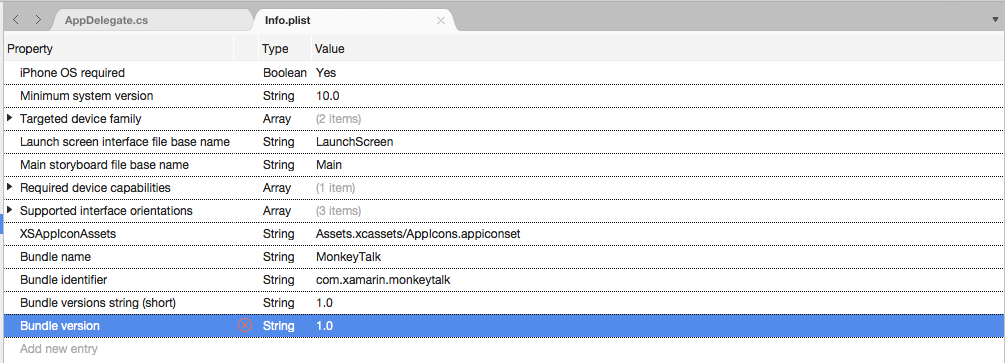
새 항목 추가를 클릭하고 속성
String에 대해 형식 및 사용 설명을 값으로 입력NSSpeechRecognitionUsageDescription합니다. 예시: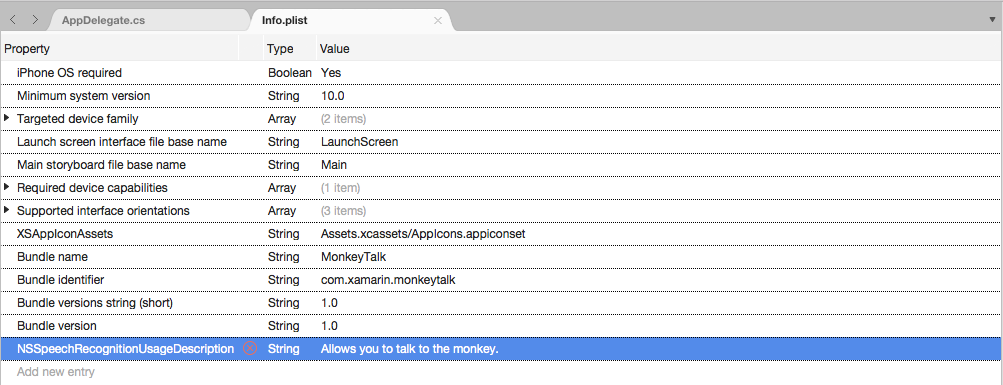
앱이 라이브 오디오 전사를 처리하는 경우 마이크 사용 설명도 필요합니다. 새 항목 추가를 클릭하고 속성
String에 대해 형식 및 사용 설명을 값으로 입력NSMicrophoneUsageDescription합니다. 예시:
변경 내용을 파일에 저장합니다.





Important
위의 Info.plist 키(NSSpeechRecognitionUsageDescription 또는 NSMicrophoneUsageDescription)를 제공하지 못하면 음성 인식 또는 라이브 오디오용 마이크에 액세스하려고 할 때 경고 없이 앱이 실패할 수 있습니다.
권한 부여 요청
앱이 음성 인식에 액세스할 수 있도록 하는 필수 사용자 권한 부여를 요청하려면 기본 View Controller 클래스를 편집하고 다음 코드를 추가합니다.
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
클래스의 메서드는 RequestAuthorization 개발자가 파일의 키 Info.plist 에 제공한 이유를 사용하여 음성 인식에 액세스할 수 있는 NSSpeechRecognitionUsageDescription 권한을 사용자에게 요청 SFSpeechRecognizer 합니다.
SFSpeechRecognizerAuthorizationStatus 결과는 사용자의 권한에 RequestAuthorization 따라 작업을 수행하는 데 사용할 수 있는 메서드의 콜백 루틴으로 반환됩니다.
Important
Apple은 사용자가 이 권한을 요청하기 전에 음성 인식이 필요한 앱에서 작업을 시작할 때까지 기다리는 것이 좋습니다.
사전 녹음된 음성 인식
앱이 미리 녹음된 WAV 또는 MP3 파일에서 음성을 인식하려는 경우 다음 코드를 사용할 수 있습니다.
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
이 코드를 자세히 살펴보면 먼저 Speech Recognizer(SFSpeechRecognizer)를 만들려고 시도합니다. 기본 언어가 음성 인식 null 에 지원되지 않는 경우 반환되고 함수가 종료됩니다.
기본 언어에 Speech Recognizer를 사용할 수 있는 경우 앱은 속성을 사용하여 Available 현재 인식할 수 있는지 확인하는 검사. 예를 들어 디바이스에 활성 인터넷 연결이 없는 경우 인식을 사용할 수 없을 수 있습니다.
A SFSpeechUrlRecognitionRequest 는 iOS 디바이스에서 미리 기록된 파일의 위치에서 만들어 NSUrl 지고 콜백 루틴으로 처리하도록 Speech Recognizer에 전달됩니다.
콜백이 호출될 때 처리해야 하는 오류가 없는 null 경우 NSError 음성 인식은 증분 방식으로 수행되므로 콜백 루틴이 두 번 이상 호출될 수 있으므로 SFSpeechRecognitionResult.Final 변환이 완료되고 번역의 최상의 버전이 기록되는지 확인하기 위해 속성이 테스트됩니다(BestTranscription).
Live Speech 인식
앱이 라이브 음성을 인식하려는 경우 프로세스는 미리 녹음된 음성을 인식하는 것과 매우 유사합니다. 예시:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
이 코드를 자세히 살펴보면 인식 프로세스를 처리하는 몇 가지 프라이빗 변수를 만듭니다.
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
AV Foundation을 사용하여 인식 요청을 처리하기 위해 전달될 오디오를 SFSpeechAudioBufferRecognitionRequest 녹음합니다.
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
앱은 녹음/녹화를 시작하려고 시도하며 기록을 시작할 수 없는 경우 오류가 처리됩니다.
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
인식 작업이 시작되고 핸들이 인식 태스크()SFSpeechRecognitionTask에 유지됩니다.
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
콜백은 미리 녹음된 음성에서 위에서 사용한 것과 비슷한 방식으로 사용됩니다.
사용자가 녹음을 중지하는 경우 오디오 엔진과 음성 인식 요청 모두에 다음 정보를 제공합니다.
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
사용자가 인식을 취소하면 오디오 엔진 및 인식 태스크에 다음 알림이 표시됩니다.
AudioEngine.Stop ();
RecognitionTask.Cancel ();
사용자가 변환을 취소하여 메모리와 디바이스의 프로세서를 모두 해제하는 경우 호출 RecognitionTask.Cancel 하는 것이 중요합니다.
Important
NSSpeechRecognitionUsageDescription 음성 인식 또는 NSMicrophoneUsageDescriptionInfo.plist 라이브 오디오(var node = AudioEngine.InputNode;)용 마이크에 액세스하려고 할 때 경고 없이 앱이 실패할 수 있습니다. 자세한 내용은 위의 사용 설명 제공 섹션을 참조하세요.
음성 인식 제한
Apple은 iOS 앱에서 음성 인식을 사용할 때 다음과 같은 제한 사항을 적용합니다.
- 음성 인식은 모든 앱에서 무료로 사용할 수 있지만 사용량은 제한되지 않습니다.
- 개별 iOS 디바이스에는 하루에 수행할 수 있는 인식 수가 제한되어 있습니다.
- 앱은 요청별로 전역적으로 제한됩니다.
- 앱은 음성 인식 네트워크 연결 및 사용률 제한 오류를 처리할 준비가 되어 있어야 합니다.
- 음성 인식은 사용자의 iOS 장치에서 배터리 드레이닝과 높은 네트워크 트래픽 모두에서 높은 비용을 가질 수 있습니다. 이 때문에 Apple은 음성 최대 약 1분의 엄격한 오디오 지속 시간 제한을 적용합니다.
앱이 정기적으로 속도 제한 한도에 도달하면 Apple은 개발자에게 문의하도록 요청합니다.
개인 정보 보호 및 유용성 고려 사항
Apple은 iOS 앱에 음성 인식을 포함할 때 투명하고 사용자의 개인 정보를 존중하는 다음과 같은 제안을 제공합니다.
- 사용자의 음성을 녹음할 때는 앱의 사용자 인터페이스에서 녹음이 진행되고 있음을 명확하게 표시해야 합니다. 예를 들어 앱은 "녹음" 소리를 재생하고 녹음 표시기를 표시할 수 있습니다.
- 암호, 상태 데이터 또는 재무 정보와 같은 중요한 사용자 정보에 음성 인식을 사용하지 마세요.
- 작업을 실행하기 전에 인식 결과를 표시합니다. 이렇게 하면 앱이 수행하는 일에 대한 피드백을 제공 할뿐만 아니라 사용자가 인식 오류를 처리 할 수 있습니다.
요약
이 문서에서는 새로운 Speech API를 제공하고 Xamarin.iOS 앱에서 이를 구현하여 연속 음성 인식을 지원하고 음성(라이브 또는 녹음된 오디오 스트림에서)을 텍스트로 전사하는 방법을 보여 줍니다.