Een Spark-cluster maken in HDInsight in AKS (preview)
Belangrijk
Deze functie is momenteel beschikbaar in preview. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews bevatten meer juridische voorwaarden die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet beschikbaar zijn in algemene beschikbaarheid. Zie Azure HDInsight op AKS Preview-informatie voor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight met de details en volgt u ons voor meer updates in de Azure HDInsight-community.
Zodra de stappen voor abonnementsvereisten en resourcevereisten zijn voltooid en u een clustergroep hebt geïmplementeerd, kunt u azure Portal blijven gebruiken om een Spark-cluster te maken. U kunt Azure Portal gebruiken om een Apache Spark-cluster te maken in de clustergroep. Vervolgens kunt u een Jupyter Notebook maken en deze gebruiken om Spark SQL-query's uit te voeren op Apache Hive-tabellen.
Typ in Azure Portal clustergroepen en selecteer clustergroepen om naar de pagina clustergroepen te gaan. Selecteer op de pagina clustergroepen de clustergroep waarin u een nieuw Spark-cluster kunt toevoegen.
Klik op de pagina specifieke clustergroep op + Nieuw cluster.
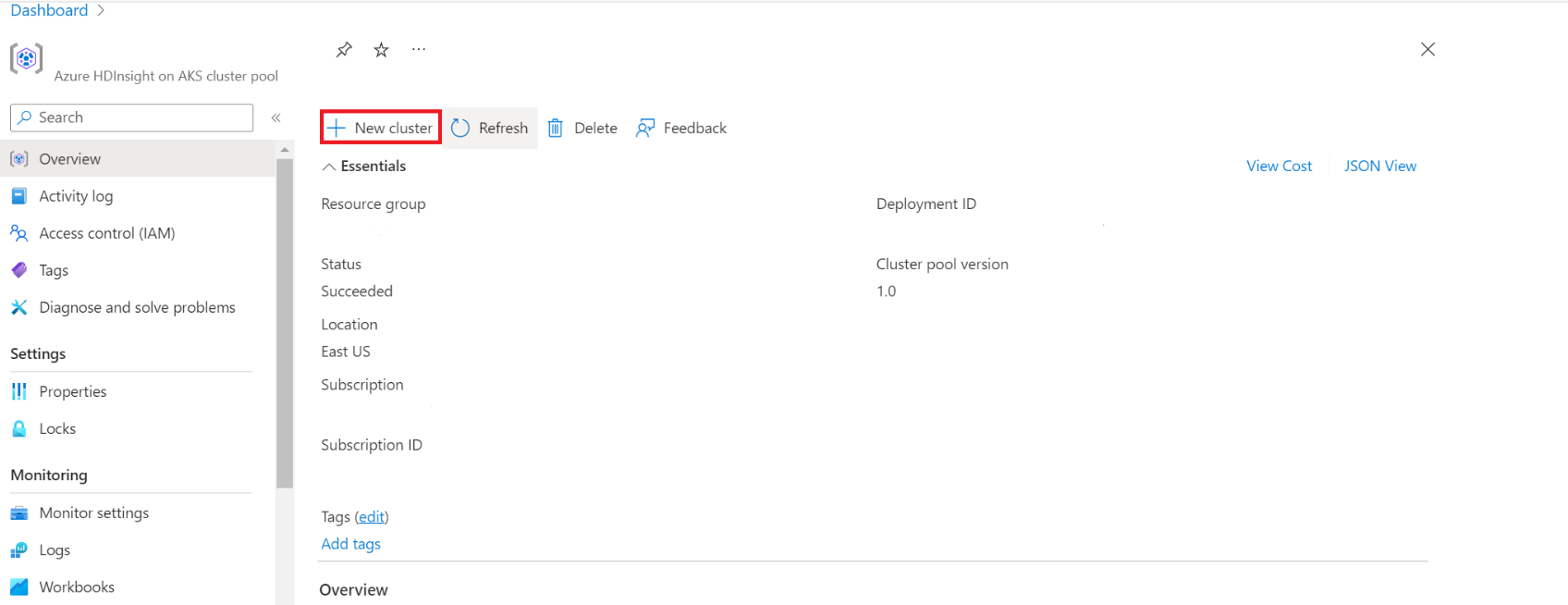
Met deze stap opent u de pagina cluster maken.
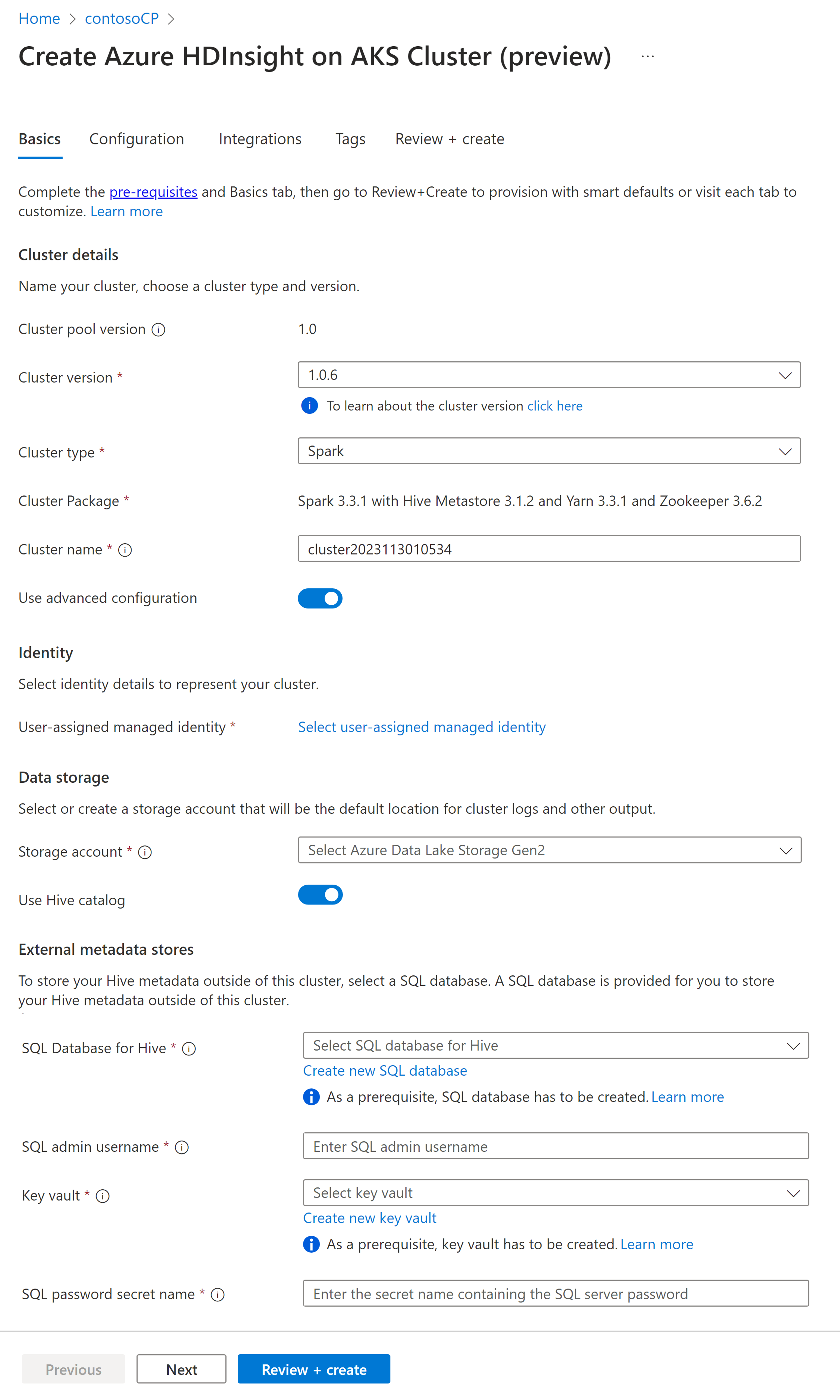
Eigenschappen Beschrijving Abonnement Het Azure-abonnement dat is geregistreerd voor gebruik met HDInsight op AKS in de sectie Vereisten, met vooraf ingevuld Resourcegroep Dezelfde resourcegroep als de clustergroep wordt vooraf ingevuld Regio Dezelfde regio als de clustergroep en virtuele worden vooraf ingevuld Clustergroep De naam van de clustergroep wordt vooraf ingevuld HDInsight-poolversie De versie van de clustergroep wordt vooraf ingevuld vanuit de selectie voor het maken van de pool HDInsight in AKS-versie De HDI op AKS-versie opgeven Clustertype Selecteer Spark in de vervolgkeuzelijst Clusterversie Selecteer de versie van de versie van de installatiekopieën die u wilt gebruiken Clusternaam Voer de naam van het nieuwe cluster in Door de gebruiker toegewezen beheerde identiteit Selecteer de door de gebruiker toegewezen beheerde identiteit die werkt als een verbindingsreeks met de opslag Opslagaccount Selecteer het vooraf gemaakte opslagaccount dat moet worden gebruikt als primaire opslag voor het cluster Containernaam Selecteer de containernaam (uniek) als u vooraf een nieuwe container hebt gemaakt of gemaakt Hive-catalogus (optioneel) Selecteer de vooraf gemaakte Hive-metastore (Azure SQL DB) SQL Database voor Hive Selecteer in de vervolgkeuzelijst de SQL Database waarin u hive-metastore-tabellen wilt toevoegen. SQL-gebruikersnaam van beheerder Voer de gebruikersnaam van de SQL-beheerder in Sleutelkluis Selecteer in de vervolgkeuzelijst de Sleutelkluis, die een geheim bevat met een wachtwoord voor de gebruikersnaam van de SQL-beheerder Sql-wachtwoordgeheimnaam Voer de geheime naam in van de Sleutelkluis waar het SQL DB-wachtwoord is opgeslagen Notitie
- Momenteel biedt HDInsight alleen ondersteuning voor MS SQL Server-databases.
- Vanwege hive-beperking wordt het teken '-' (afbreekstreepje) in de naam van de metastore-database niet ondersteund.
Selecteer Volgende: Configuratie + prijzen om door te gaan.
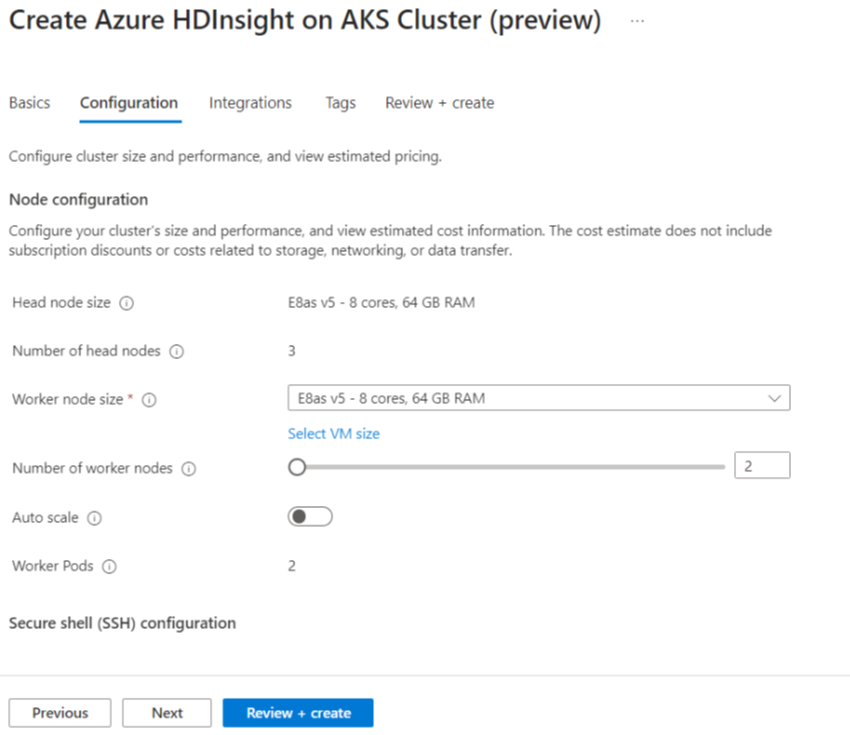
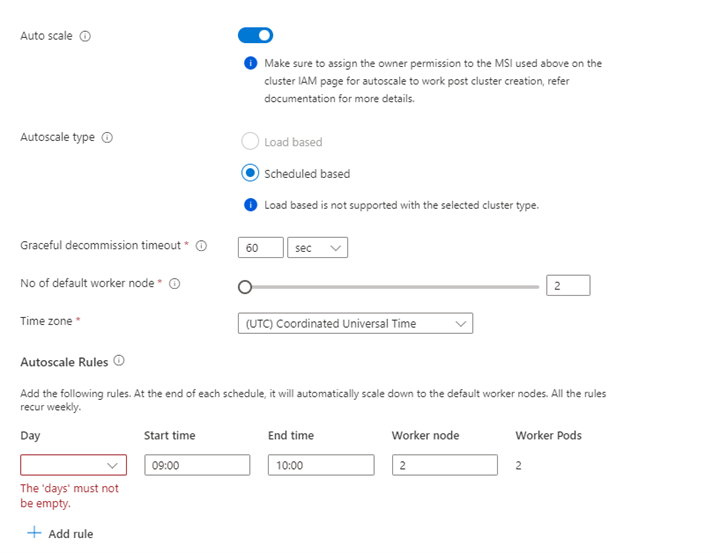

Eigenschappen Beschrijving Knooppuntgrootte Selecteer de knooppuntgrootte die u wilt gebruiken voor de Spark-knooppunten Aantal werkknooppunten Selecteer het aantal knooppunten voor een Spark-cluster. Drie knooppunten zijn gereserveerd voor coördinator- en systeemservices, resterende knooppunten zijn toegewezen aan Spark-werkrollen, één werkrol per knooppunt. In een cluster met vijf knooppunten zijn er bijvoorbeeld twee werkrollen Automatisch schalen Klik op de wisselknop om Automatisch schalen in te schakelen Type automatische schaalaanpassing Kiezen uit automatisch schalen op basis van belasting of planning Respijtende time-out voor de ontkoppeling Time-out voor respijtvolle buitengebruikstelling opgeven Geen standaardwerkknooppunt Selecteer het aantal knooppunten voor automatisch schalen Tijdzone Selecteer de tijdzone Regels voor automatisch schalen Selecteer de dag, begintijd, eindtijd, nee. van werkknooppunten SSH inschakelen Als dit is ingeschakeld, kunt u het voorvoegsel en het aantal SSH-knooppunten definiëren Klik op Volgende: Integraties om Log Analytics in te schakelen en te selecteren voor logboekregistratie.
Azure Prometheus voor bewaking en metrische gegevens kan worden ingeschakeld na het maken van clusters.
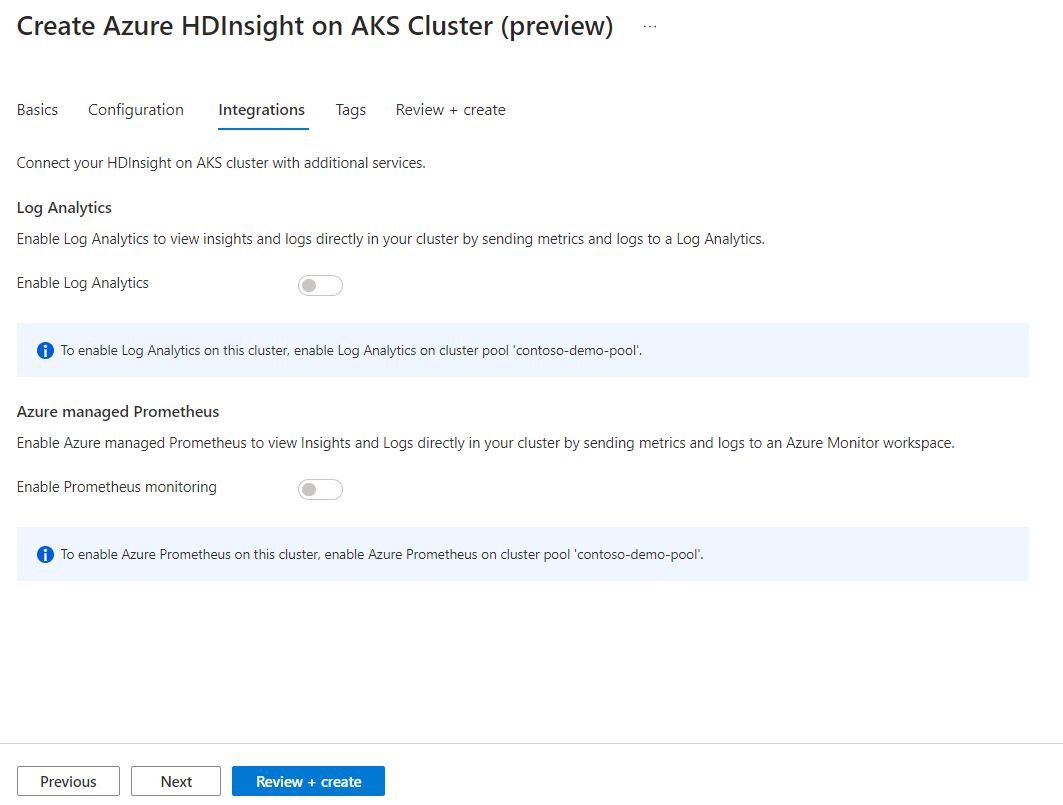
Klik op Volgende: Tags om door te gaan naar de volgende pagina.
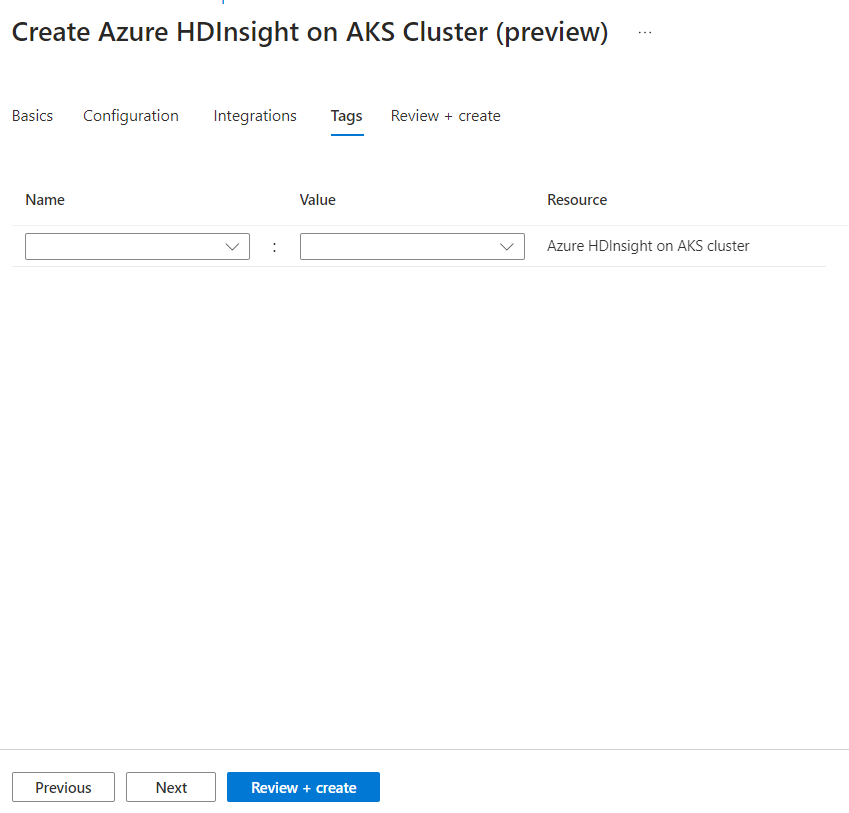
Voer op de pagina Tags alle tags in die u aan uw resource wilt toevoegen.
Eigenschappen Beschrijving Naam Optioneel. Voer een naam in, zoals HDInsight in AKS Private Preview, om eenvoudig alle resources te identificeren die zijn gekoppeld aan uw resources Weergegeven als Laat dit leeg Bron Alle resources selecteren geselecteerd Klik op Volgende: Controleren en maken.
Zoek op de pagina Controleren en maken naar het bericht Validatie voltooid boven aan de pagina en klik vervolgens op Maken.
De pagina Implementatie wordt weergegeven waarop het cluster wordt gemaakt. Het duurt 5-10 minuten om het cluster te maken. Zodra het cluster is gemaakt, wordt het bericht Uw implementatie voltooid weergegeven. Als u van de pagina weg navigeert, kunt u uw meldingen controleren op de status.
Ga naar de overzichtspagina van het cluster. Hier ziet u eindpuntkoppelingen.








