Een niet-relationele database is een database die geen gebruik maakt van het tabellaire schema van rijen en kolommen in de meeste traditionele databasesystemen. In plaats daarvan gebruiken niet-relationele databases een opslagmodel dat is geoptimaliseerd voor de specifieke vereisten van het type gegevens dat wordt opgeslagen. Gegevens kunnen bijvoorbeeld worden opgeslagen als eenvoudige sleutel-waardeparen, als JSON-documenten of als een grafiek die bestaat uit randen en hoekpunten.
Wat al deze gegevensarchieven gemeen hebben, is dat ze geen relationeel model gebruiken. Bovendien zijn ze meestal specifieker in het type gegevens dat ze ondersteunen en hoe gegevens kunnen worden opgevraagd. Tijdreeksgegevensarchieven zijn bijvoorbeeld geoptimaliseerd voor query's in op tijd gebaseerde reeksen gegevens. Grafiekgegevensarchieven zijn echter geoptimaliseerd voor het verkennen van gewogen relaties tussen entiteiten. Geen van beide indelingen generaliseert de taak van het beheren van transactionele gegevens.
De term NoSQL verwijst naar gegevensarchieven die geen SQL gebruiken voor query's. In plaats daarvan gebruiken de gegevensarchieven andere programmeertalen en constructies om query's uit te voeren op de gegevens. In de praktijk betekent 'NoSQL' 'niet-relationele database', ook al ondersteunen veel van deze databases wel SQL-compatibele query's. De onderliggende strategie voor het uitvoeren van query's verschilt meestal erg van de manier waarop een traditionele RDBMS dezelfde SQL-query zou uitvoeren.
In de volgende secties worden de belangrijkste categorieën van niet-relationele of NoSQL-database beschreven.
Documentgegevensarchieven
Een documentgegevensarchief beheert een set benoemde tekenreeksvelden en objectgegevenswaarden in een entiteit die wordt aangeduid als een document. In deze gegevensarchieven worden doorgaans gegevens opgeslagen in de vorm van JSON-documenten. Elke veldwaarde kan een scalaire item zijn, zoals een getal of een samengesteld element, zoals een lijst of een bovenliggende/onderliggende verzameling. De gegevens in de velden van een document kunnen op verschillende manieren worden gecodeerd, zoals XML, YAML, JSON, BSON of zelfs opgeslagen als tekst zonder opmaak. De velden in documenten worden blootgesteld aan het opslagbeheersysteem, waardoor een toepassing gegevens kan opvragen en filteren met behulp van de waarden in deze velden.
Normaal gesproken bevat een document de volledige gegevens voor een entiteit. Welke items een entiteit vormen, is toepassingsspecifiek. Een entiteit kan bijvoorbeeld de details van een klant, een order of een combinatie van beide bevatten. Een enkel document kan informatie bevatten die zou worden verspreid over verschillende relationele tabellen in een relationeel databasebeheersysteem (RDBMS). Een documentarchief vereist niet dat alle documenten dezelfde structuur hebben. Deze vrije-vormbenadering biedt veel flexibiliteit. Toepassingen kunnen bijvoorbeeld verschillende gegevens opslaan in documenten als reactie op een wijziging in bedrijfsvereisten.
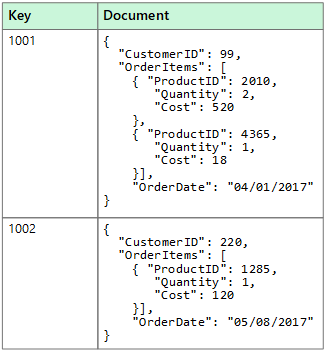
De toepassing kan documenten ophalen met behulp van de documentsleutel. De sleutel is een unieke id voor het document, dat vaak wordt gehasht, om gegevens gelijkmatig te distribueren. Sommige documentdatabases maken de documentsleutel automatisch. Bij andere kunt u een kenmerk van het document opgeven dat als sleutel moet worden gebruikt. De toepassing kan ook een query op documenten uitvoeren op basis van de waarde van een of meer velden. Sommige documentdatabases ondersteunen indexering zodat documenten snel kunnen worden gezocht op basis van een of meer geïndexeerde velden.
Veel documentdatabases ondersteunen directe updates, zodat een toepassing de waarden van bepaalde velden in een document kan wijzigen zonder het hele document te herschrijven. Lees- en schrijfbewerkingen over meerdere velden in één document zijn doorgaans atomisch.
Relevante Azure-service:
Kolomgegevensarchieven
Een kolom- of kolomfamiliegegevensarchief ordent gegevens in kolommen en rijen. In de eenvoudigste vorm kan een gegevensarchief uit de kolomfamilie sterk lijken op een relationele database, in ieder geval conceptueel. De echte kracht van een kolomfamiliedatabase ligt in de gedenormaliseerde benadering van het structureren van sparse-gegevens, die voortkomt uit de kolomgerichte benadering voor het opslaan van gegevens.
U kunt een kolomfamiliegegevensarchief beschouwen als het opslaan van tabelgegevens met rijen en kolommen, maar de kolommen zijn onderverdeeld in groepen die kolomfamilies worden genoemd. Elke kolomfamilie bevat een set kolommen die logisch zijn gerelateerd en die doorgaans worden opgehaald of bewerkt als een eenheid. Andere gegevens die afzonderlijk worden geopend, kunnen in aparte kolomfamilies worden opgeslagen. Binnen een kolomfamilie kunnen nieuwe kolommen dynamisch worden toegevoegd en rijen kunnen verspreid zijn (dat wil zeggen dat een rij geen waarde voor elke kolom hoeft te hebben).
In het volgende diagram wordt een voorbeeld getoond met twee kolomfamilies, Identity en Contact Info. De gegevens voor één entiteit hebben dezelfde rijsleutel in elke kolomfamilie. Deze structuur, waarbij de rijen voor een bepaald object in een kolomfamilie dynamisch kunnen variëren, is een belangrijk voordeel van de benadering van de kolomfamilie, waardoor deze vorm van gegevensarchief zeer geschikt is voor het opslaan van gegevens met verschillende schema's.

In tegenstelling tot een sleutel-/waardearchief of een documentdatabase slaan de meeste kolomfamiliedatabases gegevens fysiek op in sleutelvolgorde in plaats van door een hash te berekenen. De rijsleutel wordt beschouwd als de primaire index en maakt toegang op basis van sleutels mogelijk via een specifieke sleutel of een reeks sleutels. Met sommige implementaties kunt u secundaire indexen maken voor specifieke kolommen in een kolomfamilie. Met secundaire indexen kunt u gegevens ophalen op basis van de waarde van kolommen in plaats van rijsleutel.
Op schijf worden alle kolommen binnen een kolomfamilie samen opgeslagen in hetzelfde bestand, met een specifiek aantal rijen in elk bestand. Met grote gegevenssets creëert deze benadering een prestatievoordeel door de hoeveelheid gegevens te verminderen die van schijf moet worden gelezen wanneer slechts een paar kolommen tegelijk worden opgevraagd.
Lees- en schrijfbewerkingen voor een rij zijn doorgaans atomisch binnen één kolomfamilie, hoewel sommige implementaties atomiciteit bieden in de hele rij, die meerdere kolomfamilies omvatten.
Relevante Azure-service:
Sleutel-/waardegegevensarchieven
Een sleutel-/waardearchief is in feite een grote hash-tabel. U koppelt elke gegevenswaarde aan een unieke sleutel en de sleutel-/waardearchief gebruikt deze sleutel om de gegevens op te slaan met behulp van een geschikt hash-algoritme. Het hash-algoritme wordt zodanig geselecteerd dat er een evenredige verdeling van gehashte sleutels in het gegevensarchief plaatsvindt.
De meeste sleutel-/waardearchieven ondersteunen slechts eenvoudige zoek-, invoeg- en verwijder-bewerkingen. Als er een waarde (deels of volledig) moet worden gewijzigd, moeten de bestaande gegevens voor de hele waarde worden overschreven. Bij de meeste implementaties is het lezen of schrijven van één waarde een atomische bewerking. Als de waarde hoog is, kan het schrijven enige tijd in beslag nemen.
Een toepassing kan willekeurige gegevens als een gegevensset opslaan, hoewel sommige sleutel-/waardearchieven beperkingen aan de maximum grootte van de waarden kunnen opleggen. De opgeslagen waarden zijn niet transparant voor de software van het opslagsysteem. Schema-informatie moet door de toepassing beschikbaar worden gemaakt en geïnterpreteerd. Waarden zijn in wezen blobs en de sleutel-/waardearchief haalt de waarden op sleutel op (of slaat ze op).

Sleutel-/waardearchieven zijn zeer geoptimaliseerd voor toepassingen die eenvoudige zoekacties uitvoeren met behulp van de waarde van de sleutel of met een reeks sleutels, maar zijn minder geschikt voor systemen die gegevens moeten opvragen in verschillende tabellen met sleutels/waarden, zoals het samenvoegen van gegevens in meerdere tabellen.
Sleutel-/waardearchieven zijn ook niet geoptimaliseerd voor scenario's waarbij het uitvoeren van query's of filteren op niet-sleutelwaarden belangrijk is, in plaats van zoekopdrachten alleen uit te voeren op basis van sleutels. Met een relationele database kunt u bijvoorbeeld een record vinden met behulp van een WHERE-component voor het filteren van de niet-sleutelkolommen, maar sleutel-/waardenarchieven hebben meestal niet dit type opzoekmogelijkheid voor waarden, of als dat het gebeurt, is een langzame scan van alle waarden vereist.
Een sleutel-/waardearchief kan zeer schaalbaar zijn, omdat het opslagarchief makkelijk gegevens kan verdelen over meerde knooppunten op verschillende computers.
Relevante Azure-services:
Grafiekgegevensarchieven
Een grafiekgegevensarchief beheert twee soorten informatie, knooppunten en randen. Knooppunten vertegenwoordigen entiteiten en randen geven de relaties tussen deze entiteiten op. Zowel knooppunten als randen kunnen eigenschappen hebben die informatie bieden over het knooppunt of de edge, net zoals bij kolommen in een tabel. Randen kunnen ook een richting hebben die op de aard van de relatie duidt.
Het doel van een grafiekgegevensarchief is om een toepassing in staat te stellen efficiënt query's uit te voeren die het netwerk van knooppunten en randen doorlopen en om de relaties tussen entiteiten te analyseren. In het volgende diagram ziet u de personeelsgegevens van een organisatie die zijn gestructureerd als een grafiek. De entiteiten zijn werknemers en afdelingen. De randen geven de rapportagerelaties en de afdelingen weer waarin de werknemers werken. In deze grafiek geven de pijlen op de randen de richting van de relaties aan.

Deze structuur maakt het eenvoudig om query's uit te voeren, zoals 'Zoek alle werknemers die direct of indirect rapporteren aan Sarah' of 'Wie werkt op dezelfde afdeling als John?' Voor grote grafieken met veel entiteiten en relaties kunt u snel complexe analyses uitvoeren. Vele diagramdatabases hebben een querytaal waarmee u een netwerk van relaties efficiënt kunt doorlopen.
Relevante Azure-service:
Tijdreeksgegevensarchieven
Tijdreeksgegevens zijn een reeks waarden die zijn geordend op tijd en een tijdreeksgegevensarchief is geoptimaliseerd voor dit type gegevens. Tijdreeksgegevensarchieven moeten een zeer groot aantal schrijfbewerkingen ondersteunen, omdat ze meestal grote hoeveelheden gegevens in realtime verzamelen uit een groot aantal bronnen. Tijdreeksgegevensarchieven zijn geoptimaliseerd voor het opslaan van telemetriegegevens. Scenario's zijn onder meer IoT-sensoren en tellers van toepassingen of systemen. Updates worden zelden uitgevoerd en verwijderingen worden vaak als een bulkbewerking uitgevoerd.
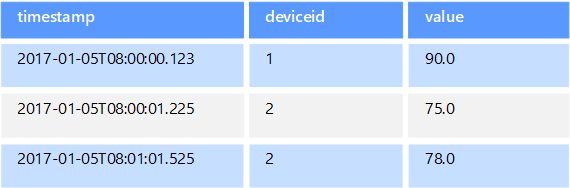
Hoewel de records die naar een tijdreeksdatabase zijn geschreven, over het algemeen klein zijn, zijn er vaak een groot aantal records en kan de totale gegevensgrootte snel toenemen. Tijdreeksgegevensarchieven verwerken ook out-of-order- en late-arriveringsgegevens, automatische indexering van gegevenspunten en optimalisaties voor query's die worden beschreven in termen van tijdvensters. Met deze laatste functie kunnen query's snel worden uitgevoerd op miljoenen gegevenspunten en meerdere gegevensstromen om visualisaties van tijdreeksen te ondersteunen. Dit is een veelgebruikte manier waarop tijdreeksgegevens worden gebruikt.
Relevante Azure-services:
Objectgegevensarchieven
Objectgegevensarchieven zijn geoptimaliseerd voor het opslaan en ophalen van grote binaire objecten of blobs, zoals afbeeldingen, tekstbestanden, video- en audiostreams, grote toepassingsgegevensobjecten en documenten en schijfinstallatiekopieën van virtuele machines. Een object bestaat uit de opgeslagen gegevens, enkele metagegevens en een unieke id voor toegang tot het object. Objectarchieven zijn ontworpen ter ondersteuning van bestanden die afzonderlijk zeer groot zijn, en bieden grote hoeveelheden totale opslag om alle bestanden te beheren.
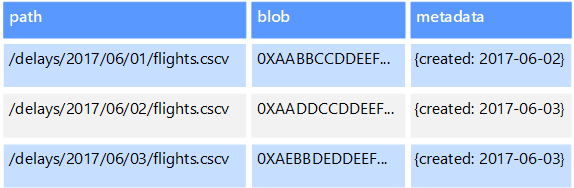
Sommige objectgegevensarchieven repliceren een bepaalde blob over meerdere serverknooppunten, waardoor snelle parallelle leesbewerkingen mogelijk zijn. Dit proces maakt het op zijn beurt mogelijk om uitschalen van gegevens in grote bestanden uit te schalen, omdat meerdere processen, die doorgaans op verschillende servers worden uitgevoerd, tegelijkertijd een query kunnen uitvoeren op het grote gegevensbestand.
Een speciaal geval van objectgegevensarchieven is de netwerkbestandsshare. Als u bestandsshares gebruikt, kunnen bestanden via een netwerk worden geopend met behulp van standaardnetwerkprotocollen zoals server message block (SMB). Gezien de juiste beveiligings- en gelijktijdige mechanismen voor toegangsbeheer kan het delen van gegevens op deze manier gedistribueerde services in staat stellen om zeer schaalbare gegevenstoegang te bieden voor eenvoudige bewerkingen op laag niveau, zoals eenvoudige lees- en schrijfaanvragen.
Relevante Azure-services:
Externe indexgegevensarchieven
Externe indexgegevensarchieven bieden de mogelijkheid om te zoeken naar informatie in andere gegevensarchieven en -services. Een externe index fungeert als een secundaire index voor elk gegevensarchief en kan worden gebruikt om enorme hoeveelheden gegevens te indexeren en bijna realtime toegang tot deze indexen te bieden.
U hebt bijvoorbeeld tekstbestanden opgeslagen in een bestandssysteem. Het vinden van een bestand op basis van het bestandspad is snel, maar zoeken op basis van de inhoud van het bestand vereist een scan van alle bestanden, wat traag is. Met een externe index kunt u secundaire zoekindexen maken en vervolgens snel het pad vinden naar de bestanden die voldoen aan uw criteria. Een andere voorbeeldtoepassing van een externe index is met sleutel/waardearchieven die alleen door de sleutel worden geïndexeerd. U kunt een secundaire index maken op basis van de waarden in de gegevens en snel de sleutel opzoeken waarmee elk overeenkomend item uniek wordt geïdentificeerd.
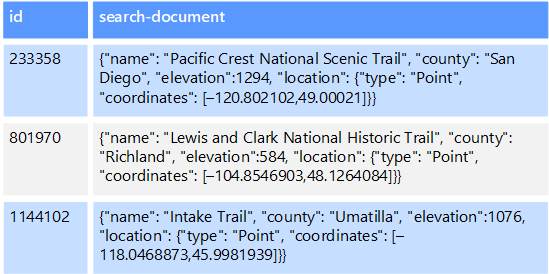
De indexen worden gemaakt door een indexeringsproces uit te voeren. Dit kan worden uitgevoerd met behulp van een pull-model, geactiveerd door het gegevensarchief of met behulp van een pushmodel, geïnitieerd door toepassingscode. Indexen kunnen multidimensionaal zijn en kunnen zoekopdrachten in vrije tekst ondersteunen voor grote hoeveelheden tekstgegevens.
Externe indexgegevensarchieven worden vaak gebruikt ter ondersteuning van volledige tekst en zoeken op internet. In dergelijke gevallen kan zoeken exact of fuzzy zijn. Bij een fuzzy zoekopdracht worden documenten gevonden die met een verzameling termen overeenkomen en wordt berekend wat de overeenkomst is. Sommige externe indexen ondersteunen ook taalkundige analyse die overeenkomsten kan retourneren op basis van synoniemen, genre-uitbreidingen (bijvoorbeeld het koppelen van "honden" aan "huisdieren") en stemming (bijvoorbeeld zoeken naar 'run' komt ook overeen met "ran" en "running").
Relevante Azure-service:
Typische vereisten
Niet-relationele gegevensarchieven gebruiken vaak een andere opslagarchitectuur dan die wordt gebruikt door relationele databases. Ze hebben de neiging om geen vast schema te hebben. Bovendien ondersteunen ze meestal geen transacties, of beperken ze het bereik van transacties en bevatten ze over het algemeen geen secundaire indexen om schaalbaarheidsredenen.
Hieronder worden de vereisten voor elk van de niet-relationele gegevensarchieven vergeleken:
| Vereiste | Documentgegevens | Kolomfamiliegegevens | Sleutel-/waardegegevens | Graph-gegevens |
|---|---|---|---|---|
| Normalisatie | Gedenormaliseerd | Gedenormaliseerd | Gedenormaliseerd | Genormaliseerd |
| Schema | Schema bij lezen | Kolomfamilies gedefinieerd voor schrijven, kolomschema bij lezen | Schema bij lezen | Schema bij lezen |
| Consistentie (voor gelijktijdige transacties) | Niet-consistente consistentie, garanties op documentniveau | Garanties op kolomfamilieniveau | Garanties op sleutelniveau | Garanties op graph-niveau |
| Atomiciteit (transactiebereik) | Verzameling | Table | Table | Grafiek |
| Strategie voor vergrendelen | Optimistisch (vergrendelingsvrij) | Pessimistisch (rijvergrendelingen) | Optimistisch (ETag) | |
| Toegangspatroon | Willekeurige toegang | Aggregaties voor lange/brede gegevens | Willekeurige toegang | Willekeurige toegang |
| Indexeren | Primaire en secundaire indexen | Primaire en secundaire indexen | Alleen primaire index | Primaire en secundaire indexen |
| Gegevensshape | Document | Tabelvorm met kolomfamilies met kolommen | Sleutel en waarde | Grafiek met randen en hoekpunten |
| Sparse | Ja | Ja | Ja | Nr. |
| Breed (veel kolommen/kenmerken) | Ja | Ja | No | Nr. |
| Datumgrootte | Klein (KB's) tot gemiddeld (lage MB's) | Gemiddeld (MB's) tot groot (lage GB's) | Klein (KB's) | Klein (KB's) |
| Algemene maximale schaal | Zeer groot (BS) | Zeer groot (BS) | Zeer groot (BS) | Groot (TB's) |
| Vereiste | Tijdreeksgegevens | Objectgegevens | Externe indexgegevens |
|---|---|---|---|
| Normalisatie | Genormaliseerd | Gedenormaliseerd | Gedenormaliseerd |
| Schema | Schema bij lezen | Schema bij lezen | Schema bij schrijven |
| Consistentie (voor gelijktijdige transacties) | N.v.t. | N.v.t. | N.v.t. |
| Atomiciteit (transactiebereik) | N.v.t. | Object | N.v.t. |
| Strategie voor vergrendelen | N.v.t. | Pessimistisch (blobvergrendelingen) | N.v.t. |
| Toegangspatroon | Willekeurige toegang en aggregatie | Sequentiële toegang | Willekeurige toegang |
| Indexeren | Primaire en secundaire indexen | Alleen primaire index | N.v.t. |
| Gegevensshape | Tabellair | Blob en metagegevens | Document |
| Sparse | Nee | N.v.t. | Nee |
| Breed (veel kolommen/kenmerken) | Nr. | Ja | Ja |
| Datumgrootte | Klein (KB's) | Groot (GB's) tot zeer groot (TB's) | Klein (KB's) |
| Algemene maximale schaal | Groot (lage TB's) | Zeer groot (BS) | Groot (lage TB's) |
Bijdragers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Zoiner Tejada | CEO en architect
Volgende stappen
- Relationele versus NoSQL-gegevens
- Gedistribueerde NoSQL-databases begrijpen
- Basisinformatie over Microsoft Azure-gegevens: niet-relationele gegevens verkennen in Azure
- Een niet-relationeel gegevensmodel implementeren