Natuurlijke taalverwerking (NLP) heeft veel toepassingen: sentimentanalyse, onderwerpdetectie, taaldetectie, sleuteltermextractie en documentcategorisatie.
U kunt NLP gebruiken voor het volgende:
- Documenten classificeren. U kunt bijvoorbeeld documenten labelen als gevoelig of spam.
- Voer de volgende verwerking of zoekopdrachten uit. Voor deze doeleinden kunt u NLP-uitvoer gebruiken.
- U kunt tekst samenvatten door de entiteiten te identificeren die aanwezig zijn in het document.
- Documenten taggen met trefwoorden. Voor de trefwoorden kan NLP geïdentificeerde entiteiten gebruiken.
- Zoek en ophaal op basis van inhoud. Taggen maakt deze functionaliteit mogelijk.
- De belangrijke onderwerpen van een document samenvatten. NLP kan geïdentificeerde entiteiten combineren tot onderwerpen.
- Documenten categoriseren voor navigatie. Voor dit doel maakt NLP gebruik van gedetecteerde onderwerpen.
- Gerelateerde documenten opsommen op basis van een geselecteerd onderwerp. Voor dit doel maakt NLP gebruik van gedetecteerde onderwerpen.
- Scoretekst voor gevoel. Met deze functionaliteit kunt u de positieve of negatieve toon van een document beoordelen.
Apache, Apache® Spark en het vlamlogo zijn gedeponeerde handelsmerken of handelsmerken van de Apache Software Foundation in de Verenigde Staten en/of andere landen. Er wordt geen goedkeuring door De Apache Software Foundation geïmpliceerd door het gebruik van deze markeringen.
Potentiële gebruikscases
Bedrijfsscenario's die kunnen profiteren van aangepaste NLP zijn onder andere:
- Documentinformatie voor handgeschreven of door machines gemaakte documenten in financiën, gezondheidszorg, detailhandel, overheid en andere sectoren.
- Brancheonafhankelijke NLP-taken voor tekstverwerking, zoals NER (Naamentiteitsherkenning), classificatie, samenvatting en relatieextractie. Met deze taken wordt het proces voor het ophalen, identificeren en analyseren van documentinformatie, zoals tekst en ongestructureerde gegevens, geautomatiseerd. Voorbeelden van deze taken zijn risicostratificatiemodellen, ontologieclassificatie en samenvattingen van de detailhandel.
- Het ophalen van informatie en het maken van kennisgrafiek voor semantische zoekopdrachten. Deze functionaliteit maakt het mogelijk om medische kennisgrafieken te maken die ondersteuning bieden voor geneesmiddelendetectie en klinische proeven.
- Tekstomzetting voor conversationele AI-systemen in klantgerichte toepassingen in detailhandel, financiën, reizen en andere branches.
Apache Spark als een aangepast NLP-framework
Apache Spark is een framework voor parallelle verwerking dat ondersteuning biedt voor in-memory verwerking om de prestaties van toepassingen voor de analyse van big data te verbeteren. Azure Synapse Analytics, Azure HDInsight en Azure Databricks bieden toegang tot Spark en profiteren van de verwerkingskracht.
Voor aangepaste NLP-workloads fungeert Spark NLP als een efficiënt framework voor het verwerken van een grote hoeveelheid tekst. Deze opensource NLP-bibliotheek biedt Python-, Java- en Scala-bibliotheken die de volledige functionaliteit van traditionele NLP-bibliotheken bieden, zoals spaCy, NLTK,CoreNLP en Open NLP. Spark NLP biedt ook functionaliteit zoals spellingcontrole, sentimentanalyse en documentclassificatie. Spark NLP verbetert de eerdere inspanningen door geavanceerde nauwkeurigheid, snelheid en schaalbaarheid te bieden.
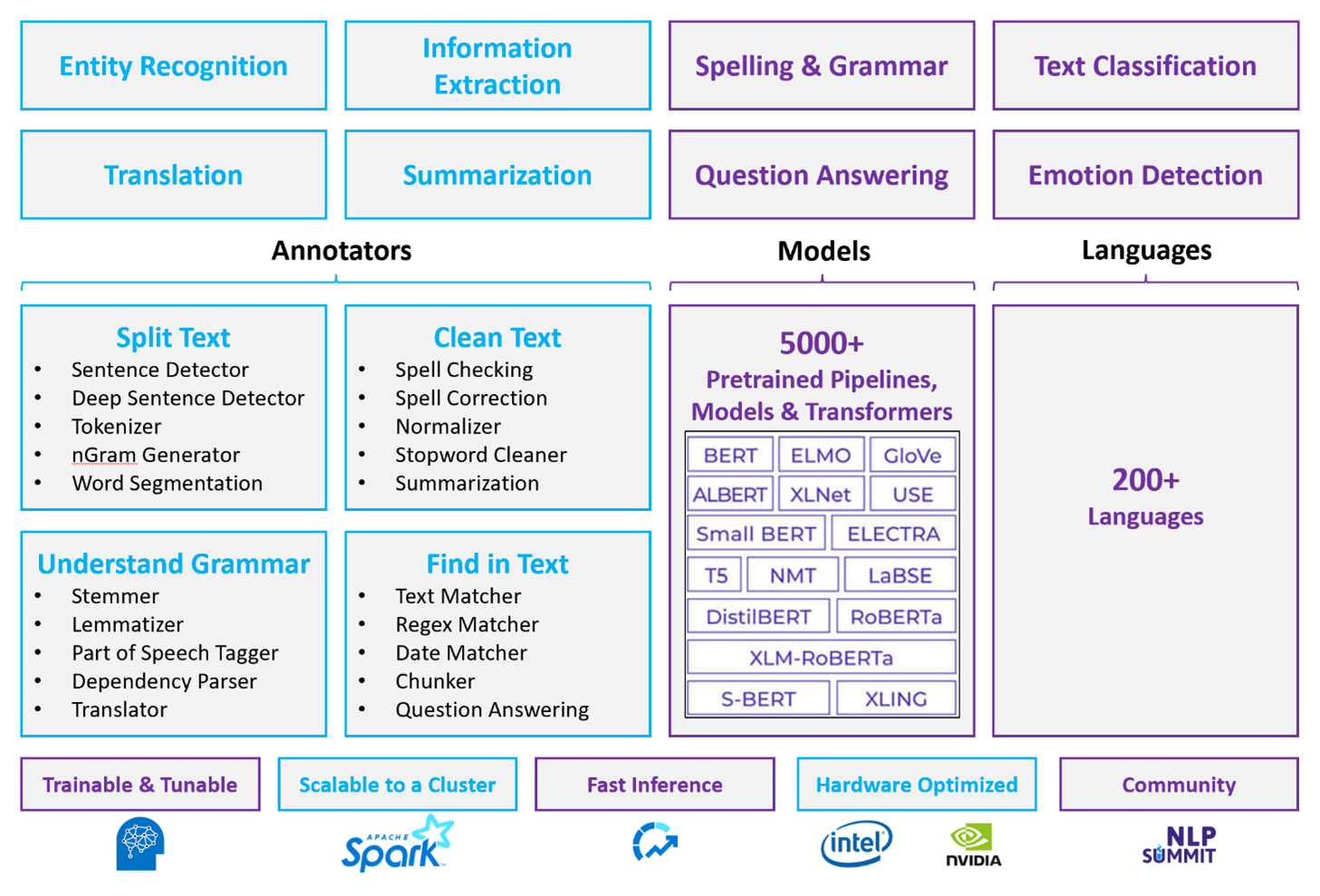
Recente openbare benchmarks tonen Spark NLP 38 en 80 keer sneller dan spaCy, met vergelijkbare nauwkeurigheid voor het trainen van aangepaste modellen. Spark NLP is de enige opensource-bibliotheek die een gedistribueerd Spark-cluster kan gebruiken. Spark NLP is een systeemeigen uitbreiding van Spark ML die rechtstreeks op gegevensframes werkt. Als gevolg hiervan resulteren versnellingen in een cluster in een andere volgorde van grootte van prestatiewinst. Omdat elke Spark NLP-pijplijn een Spark ML-pijplijn is, is Spark NLP geschikt voor het bouwen van geïntegreerde NLP- en machine learning-pijplijnen, zoals documentclassificatie, risicovoorspelling en aanbevolen pijplijnen.
Naast uitstekende prestaties levert Spark NLP ook state-of-the-art nauwkeurigheid voor een groeiend aantal NLP-taken. Het Spark NLP-team leest regelmatig de meest recente relevante academische documenten en implementeert state-of-the-art modellen. In de afgelopen twee tot drie jaar hebben de best presterende modellen deep learning gebruikt. De bibliotheek wordt geleverd met vooraf samengestelde Deep Learning-modellen voor benoemde entiteitsherkenning, documentclassificatie, sentiment- en emotiedetectie en zinsdetectie. De bibliotheek bevat ook tientallen vooraf getrainde taalmodellen met ondersteuning voor woord-, segment-, zin- en documentbesluitingen.
De bibliotheek heeft geoptimaliseerde builds voor CPU's, GPUS en de nieuwste Intel Xeon-chips. U kunt trainings- en deductieprocessen schalen om te profiteren van Spark-clusters. Deze processen kunnen worden uitgevoerd in productie op alle populaire analyseplatforms.
Uitdagingen
- Voor het verwerken van een verzameling vrije tekstdocumenten is een aanzienlijke hoeveelheid rekenkundige resources vereist. De verwerking is ook tijdrovend. Dergelijke processen omvatten vaak gpu-rekenimplementatie.
- Zonder een gestandaardiseerde documentindeling kan het lastig zijn om consistent nauwkeurige resultaten te bereiken wanneer u vrije tekstverwerking gebruikt om specifieke feiten uit een document te extraheren. Denk bijvoorbeeld aan een tekstweergave van een factuur. Het kan lastig zijn om een proces te bouwen waarmee het factuurnummer en de datum van facturen van verschillende leveranciers correct worden geëxtraheerd.
Criteria voor sleutelselectie
In Azure bieden Spark-services zoals Azure Databricks, Azure Synapse Analytics en Azure HDInsight NLP-functionaliteit wanneer u ze gebruikt met Spark NLP. Azure Cognitive Services is een andere optie voor NLP-functionaliteit. Als u wilt bepalen welke service u wilt gebruiken, moet u rekening houden met de volgende vragen:
Wilt u vooraf samengestelde of vooraf getrainde modellen gebruiken? Zo ja, overweeg dan de API's te gebruiken die Azure Cognitive Services biedt. Of download uw model naar keuze via Spark NLP.
Moet u aangepaste modellen trainen op basis van een groot aantal tekstgegevens? Zo ja, overweeg dan om Azure Databricks, Azure Synapse Analytics of Azure HDInsight te gebruiken met Spark NLP.
Hebt u NLP-mogelijkheden op laag niveau nodig, zoals tokenisatie, stemming, lemmatisatie en termfrequentie/inverse documentfrequentie (TF/IDF)? Zo ja, overweeg dan om Azure Databricks, Azure Synapse Analytics of Azure HDInsight te gebruiken met Spark NLP. Of gebruik een opensource-softwarebibliotheek in uw verwerkingshulpprogramma naar keuze.
Hebt u eenvoudige NLP-mogelijkheden op hoog niveau nodig, zoals entiteits- en intentieidentificatie, onderwerpdetectie, spellingcontrole of sentimentanalyse? Zo ja, overweeg dan de API's te gebruiken die Cognitive Services biedt. Of download uw model naar keuze via Spark NLP.
Mogelijkheidsmatrix
De volgende tabellen geven een overzicht van de belangrijkste verschillen in de mogelijkheden van NLP-services.
Algemene mogelijkheden
| Mogelijkheid | Spark-service (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) met Spark NLP | Azure Cognitive Services |
|---|---|---|
| Biedt vooraf getrainde modellen als een service | Ja | Ja |
| REST-API | Ja | Ja |
| Programmeerbaarheid | Python, Scala | Zie Aanvullende resources voor ondersteunde talen |
| Ondersteunt de verwerking van big data-sets en grote documenten | Ja | Nr. |
NLP-mogelijkheden op laag niveau
| Mogelijkheid van aantekeningen | Spark-service (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) met Spark NLP | Azure Cognitive Services |
|---|---|---|
| Zindetector | Ja | Nr. |
| Diepe zindetector | Ja | Ja |
| Tokenizer | Ja | Ja |
| N-gram generator | Ja | Nr. |
| Woordsegmentatie | Ja | Ja |
| Stemmer | Ja | Nr. |
| Lemmatizer | Ja | Nr. |
| Woordsoorten taggen | Ja | Nr. |
| Afhankelijkheidsparser | Ja | Nr. |
| Vertaling | Ja | Nr. |
| Stopword cleaner | Ja | Nr. |
| Spellingcorrectie | Ja | Nr. |
| Normalizer | Ja | Ja |
| Tekstovereenkomst | Ja | Nr. |
| TF/IDF | Ja | Nr. |
| Matcher voor reguliere expressies | Ja | Ingesloten in Language Understanding Service (LUIS). Niet ondersteund in Conversational Language Understanding (CLU), dat LUIS vervangt. |
| Datumovereenkomst | Ja | Mogelijk in LUIS en CLU via DateTime recognizers |
| Chunker | Ja | Nr. |
NLP-mogelijkheden op hoog niveau
| Mogelijkheid | Spark-service (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) met Spark NLP | Azure Cognitive Services |
|---|---|---|
| Spellingcontrole | Ja | Nr. |
| Samenvatting | Ja | Ja |
| Vragen beantwoorden | Ja | Ja |
| Gevoelsdetectie | Ja | Ja |
| Emotiedetectie | Ja | Ondersteunt meninganalyse |
| Tokenclassificatie | Ja | Ja, via aangepaste modellen |
| Tekstclassificatie | Ja | Ja, via aangepaste modellen |
| Tekstweergave | Ja | Nr. |
| NER | Ja | Ja: tekstanalyse biedt een set NER en aangepaste modellen bevinden zich in entiteitsherkenning |
| Herkenning van entiteiten | Ja | Ja, via aangepaste modellen |
| Taaldetectie | Ja | Ja |
| Ondersteunt talen naast Engels | Ja, ondersteunt meer dan 200 talen | Ja, ondersteunt meer dan 97 talen |
Spark NLP instellen in Azure
Als u Spark NLP wilt installeren, gebruikt u de volgende code, maar vervangt u door <version> het meest recente versienummer. Zie de Documentatie voor Spark NLP voor meer informatie.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
NLP-pijplijnen ontwikkelen
Voor de uitvoeringsvolgorde van een NLP-pijplijn volgt Spark NLP hetzelfde ontwikkelingsconcept als traditionele Spark ML-machine learning-modellen. Maar Spark NLP past NLP-technieken toe.
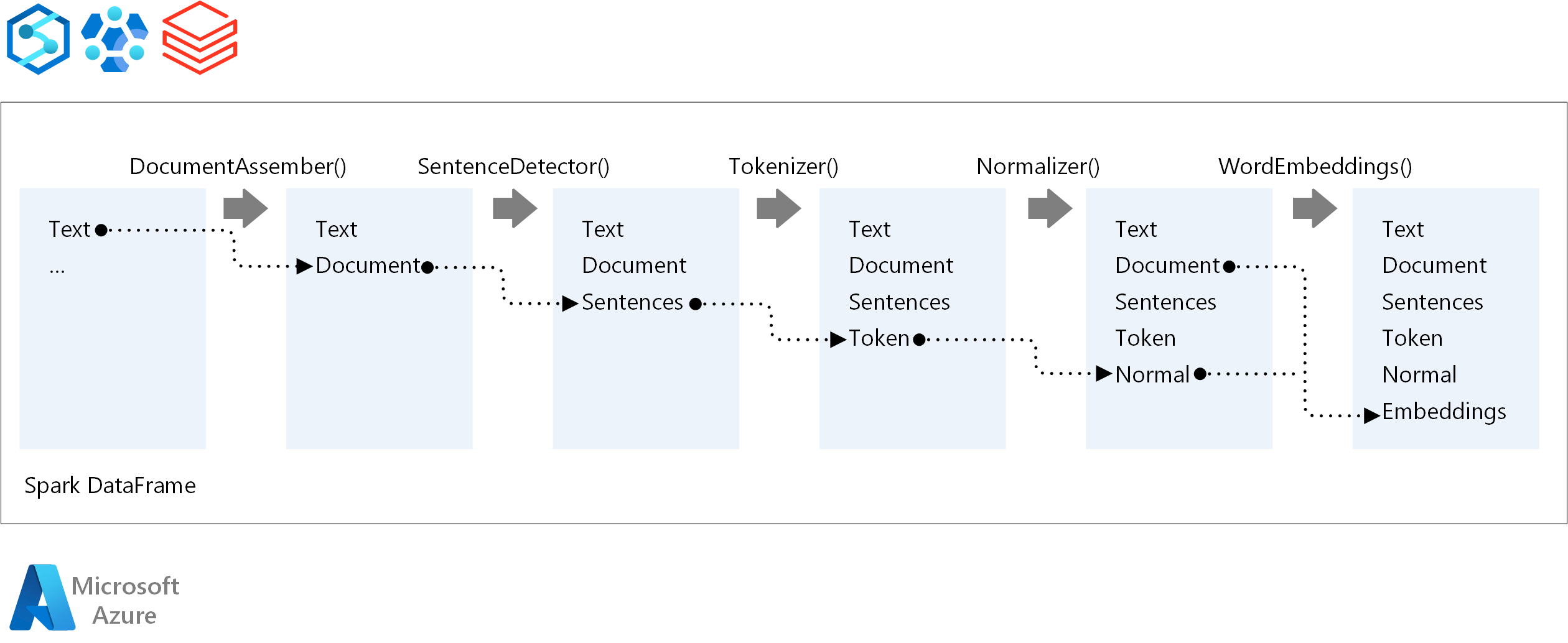
De belangrijkste onderdelen van een Spark NLP-pijplijn zijn:
DocumentAssembler: Een transformator die gegevens voorbereidt door deze te wijzigen in een indeling die Spark NLP kan verwerken. Deze fase is het toegangspunt voor elke Spark NLP-pijplijn. DocumentAssembler kan een
Stringkolom of eenArray[String]. U kuntsetCleanupModede tekst vooraf verwerken. Deze modus is standaard uitgeschakeld.Zindetector: Een annotator die zinsgrenzen detecteert met behulp van de methode die wordt gegeven. Deze annotator kan elke geëxtraheerde zin in een
Array. U kunt ook elke zin in een andere rij retourneren als u deze insteltexplodeSentencesop waar.Tokenizer: Een annotator die onbewerkte tekst scheidt in tokens of eenheden zoals woorden, getallen en symbolen, en retourneert de tokens in een
TokenizedSentencestructuur. Deze klasse is niet uitgerust. Als u een tokenizer past, gebruikt het interneRuleFactoryapparaat de invoerconfiguratie om tokenizingregels in te stellen. Tokenizer maakt gebruik van open standaarden om tokens te identificeren. Als de standaardinstellingen niet aan uw behoeften voldoen, kunt u regels toevoegen om tokenizer aan te passen.Normalizer: Een annotator die tokens schoont. Normalizer vereist stengels. Normalizer maakt gebruik van reguliere expressies en een woordenlijst om tekst te transformeren en vuile tekens te verwijderen.
WordEmbeddings: Aantekenaars opzoeken die tokens toewijzen aan vectoren. U kunt een
setStoragePathaangepaste tokenzoekwoordenlijst opgeven voor insluitingen. Elke regel van uw woordenlijst moet een token en de vectorweergave bevatten, gescheiden door spaties. Als een token niet wordt gevonden in de woordenlijst, is het resultaat een nulvector van dezelfde dimensie.
Spark NLP maakt gebruik van Spark MLlib-pijplijnen, die MLflow systeemeigen ondersteunt. MLflow is een opensource-platform voor de levenscyclus van machine learning. De onderdelen zijn onder andere:
- Mlflow Tracking: Registreert experimenten en biedt een manier om queryresultaten uit te voeren.
- MLflow Projects: Maakt het mogelijk om data science-code uit te voeren op elk platform.
- MLflow-modellen: implementeert modellen in diverse omgevingen.
- Modelregister: beheert modellen die u opslaat in een centrale opslagplaats.
MLflow is geïntegreerd in Azure Databricks. U kunt MLflow installeren in elke andere Spark-omgeving om uw experimenten bij te houden en te beheren. U kunt ook MLflow Model Registry gebruiken om modellen beschikbaar te maken voor productiedoeleinden.
Bijdragers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- De Steller van Microsoft | Senior Cloud Solution Architect
- Zoiner Tejada | CEO en architect
Volgende stappen
Documentatie voor Spark NLP:
Azure-onderdelen:
Informatiebronnen:
Verwante resources
- Grootschalige verwerking van aangepaste natuurlijke taal in Azure
- Een Technologie voor Microsoft Cognitive Services kiezen
- De machine learning-producten en -technologieën van Microsoft vergelijken
- MLflow en Azure Machine Learning
- AI-verrijking met verwerking van afbeeldingen en natuurlijke taal in Azure Cognitive Search
- Nieuwsfeeds analyseren met bijna realtime analyses met behulp van afbeeldings- en natuurlijke taalverwerking
- Inhoudstags voorstellen met NLP met behulp van Deep Learning