Een big data-architectuur is ontworpen om de opname, verwerking en analyse van gegevens te verwerken die te groot of complex zijn voor traditionele databasesystemen.

Bij big data-oplossingen is meestal sprake van minstens een van de volgende typen workloads:
- Batchverwerking van ongebruikte big data-bronnen.
- Realtimeverwerking van actieve big data.
- Interactieve verkenning van big data.
- Predictive Analytics en Machine Learning.
De meeste big data-architecturen bevatten een of meer van de volgende onderdelen:
Gegevensbronnen: alle big data-oplossingen hebben een of meer gegevensbronnen als uitgangspunt. Voorbeelden zijn:
- Toepassingsgegevensopslag, zoals relationele databases.
- Statische bestanden die zijn geproduceerd met toepassingen, zoals logboekbestanden van webservers.
- Realtimegegevensbronnen, zoals IoT-apparaten.
Gegevensopslag: gegevens voor batchverwerking worden meestal opgeslagen in een gedistribueerde bestandsopslag dat hoge aantallen grote bestanden kan bevatten in verschillende indelingen. Dit soort opslag wordt ook wel een data lake genoemd. Opties voor het implementeren van deze opslag zijn Azure Data Lake Store of blobcontainers in Azure Storage.
Batchverwerking: omdat de gegevenssets zo groot zijn, moeten met een big data-oplossing vaak gegevensbestanden worden verwerkt met behulp van langlopende batchtaken om de gegevens te filteren, samen te voegen en anderszins voor te bereiden voor analyse. Deze taken omvatten meestal het lezen van bronbestanden, het verwerken ervan, en het schrijven van de uitvoer naar nieuwe bestanden. Opties zijn onder andere het uitvoeren van U-SQL-taken in Azure Data Lake Analytics, met behulp van Hive-taken, Pig-taken of aangepaste taken voor toewijzen/verminderen in een HDInsight Hadoop-cluster, of met behulp van Java-, Scala- of Python-programma’s in een HDInsight Spark-cluster.
Berichtopname in realtime: als de oplossing realtimebronnen omvat, moet de architectuur een methode bieden om berichten in realtime vast te leggen en op te slaan voor stroomverwerking. Dit kan een eenvoudige gegevensopslag zijn, waar binnenkomende berichten voor verwerking worden bewaard in een map. Veel oplossingen vereisen echter een berichtopnameopslag die als buffer optreedt voor berichten, en die ondersteuning biedt voor uitschalen, betrouwbare bezorging en andere zaken op het gebied van berichtwachtrijen. Opties zijn onder andere Azure Event Hubs, Azure IoT Hubs en Kafka.
Verwerking van stromen: na het vastleggen van realtimeberichten, moeten deze worden verwerkt door ze te filteren, samen te voegen en anderszins voor te bereiden voor analyse. De verwerkte stroom met gegevens wordt vervolgens naar een uitvoer-sink geschreven. Azure Stream Analytics biedt een beheerde service voor het verwerken van stromen, gebaseerd op de doorlopende uitvoering van SQL-query’s voor niet-gebonden stromen. U kunt ook open source Apache-streamingtechnologieën zoals Spark Streaming gebruiken in een HDInsight-cluster.
Analytische gegevensopslag: in veel big data-oplossingen worden gegevens voorbereid en worden de verwerkte gegevens vervolgens in een gestructureerde indeling aangeboden, die kan worden doorzocht met behulp van analysehulpprogramma’s. De analytische gegevensopslag waarmee deze query’s worden aangeboden, kunnen relationele datawarehouses in Kimball-stijl zijn, zoals bij de meeste traditionele BI-oplossingen (Business Intelligence). De gegevens kunnen ook worden gepresenteerd met behulp van een NoSQL-technologie met lage latentie, zoals HBase, of met een interactieve Hive-database die een metagegevensabstractie biedt van gegevensbestanden in de gedistribueerde gegevensopslag. Azure Synapse Analytics biedt een beheerde service voor grootschalige datawarehousing in de cloud. HDInsight biedt ondersteuning voor Interactive Hive, HBase en Spark SQL, dat ook kan worden gebruikt om de gegevens aan te bieden voor analyse.
Analyse en rapportage: het doel van de meeste big data-oplossingen is het bieden van inzicht in de gegevens via analyse en rapportage. De architectuur kan ook een gegevensmodellaag bevatten, zoals een multidimensionale OLAP-kubus of tabelvormig gegevensmodel in Azure Analysis Services, om gebruikers in staat te stellen de gegevens te analyseren. Selfservice-BI wordt mogelijk ook ondersteund, met behulp van modellerings- en visualisatietechnologieën in Microsoft Power BI of Microsoft Excel. Onder analyse en rapportage wordt ook verstaan het interactief verkennen van gegevens door wetenschappers of gegevensanalisten. Voor deze scenario's bieden veel Azure-services ondersteuning voor analytische notitieblokken, zoals Jupyter. De gebruikers kunnen hierdoor hun vaardigheden ook gebruiken in Python of R. Voor grootschalige gegevensverkenning kunt u Microsoft R Server gebruiken, als zelfstandige versie of met Spark.
Indeling: de meeste big data-oplossingen bestaan uit herhaalde gegevensverwerking, ingekapseld in werkstromen, waarmee brongegevens worden getransformeerd, gegevens worden verplaatst tussen meerdere bronnen en sinks, de verwerkte gegevens in een analytische gegevensopslag worden geladen, of de resultaten rechtstreeks naar een rapport of een dashboard worden gepusht. U kunt een indelingstechnologie zoals Azure Data Factory of Apache Oozie en Sqoop gebruiken om deze werkstromen te automatiseren.
Azure bevat veel services die kunnen worden gebruikt in een big data-architectuur. Deze zijn grofweg in te delen in twee categorieën:
- Beheerde services, waaronder Azure Data Lake Store, Azure Data Lake Analytics, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub en Azure Data Factory.
- Open source-technologieën op basis van het Apache Hadoop-platform, waaronder HDFS, HBase, Hive, Spark, Oozie, Sqoop en Kafka. Deze technologieën zijn beschikbaar voor Azure in de Azure HDInsight-service.
Deze opties sluiten elkaar niet uit. Veel oplossingen zijn een combinatie van open-source technologieën en Azure-services.
Wanneer gebruikt u deze architectuur?
Overweeg om deze architectuurstijl te gebruiken als u een van de volgende dingen wilt doen:
- Hoeveelheden gegevens opslaan en verwerken die te groot zijn voor een traditionele database.
- Ongestructureerde gegevens voorbereiden voor analyse en rapportage.
- Niet-gebonden gegevensstromen vastleggen, verwerken en analyseren, in realtime of met lage latentie.
- Gebruik Azure Machine Learning of Azure Cognitive Services.
Vergoedingen
- Technologieopties. U kunt voor HDInsight-clusters een combinatie gebruiken van beheerde Azure-services en Apache-technologieën. Op deze manier haalt u het meeste uit de bestaande vaardigheden en technologische investeringen.
- Prestaties via parallelle uitvoering. Big data-oplossingen profiteren van parallelle uitvoering, waardoor oplossingen met hoge prestaties mogelijk zijn voor het schalen van grote hoeveelheden gegevens.
- Elastisch schalen. Alle onderdelen van de big data-architectuur bieden ondersteuning voor inrichting bij uitschalen. U kunt de oplossing dus aanpassen aan kleine of grote workloads, terwijl u alleen betaalt voor de resources die u daadwerkelijk gebruikt.
- Interoperabiliteit met bestaande oplossingen. De onderdelen van de big data-architectuur worden ook gebruikt voor IoT-verwerking en BI-oplossingen voor bedrijven. Hierdoor kunt u een geïntegreerde oplossing maken voor alle workloads.
Uitdagingen
- Complexiteit. Big data-oplossingen kunnen zeer complex zijn en vele onderdelen bevatten waarmee de berichtopname uit meerdere gegevensbronnen worden verwerkt. Het kan een hele uitdaging zijn om big data-processen te bouwen en te testen, en om problemen ermee op te lossen. Bovendien moeten mogelijk veel configuratie-instellingen in verschillende systemen worden gebruikt om de prestaties te optimaliseren.
- Vaardigheden. Veel big data-technologieën zijn zeer gespecialiseerd, en maken gebruik van frameworks en talen die niet karakteristiek zijn voor meer algemene toepassingsarchitecturen. Aan de andere kant worden er nieuwe API's ontwikkeld voor big data-technologieën die zijn gebaseerd op meer gebruikelijke talen. De U-SQL-taal in Azure Data Lake Analytics is bijvoorbeeld gebaseerd op een combinatie van Transact-SQL en C#. Zo zijn er ook API’s op basis van SQL beschikbaar voor Hive, HBase en Spark.
- Technologische vervaldatum. Veel technologieën die worden gebruikt voor big data, zijn nog in ontwikkeling. Kerntechnologieën van Hadoop, zoals Hive en Pig zijn ondertussen stabiel, maar voor technologieën die nog in ontwikkeling zijn, zoals Spark, worden bij elke release uitgebreide wijzigingen en verbeteringen geïntroduceerd. Beheerde services zoals Azure Data Lake Analytics en Azure Data Factory zijn nog relatief jong, vergeleken met andere Azure-services, en worden mettertijd waarschijnlijk nog verder ontwikkeld.
- Beveiliging. Bij big data-oplossingen worden alle statische gegevens meestal opgeslagen in een gecentraliseerd data lake. Het kan een uitdaging zijn om de toegang tot deze gegevens te beveiligen, met name wanneer de gegevens moeten worden opgenomen en verbruikt in meerdere toepassingen en op meerdere platforms.
Aanbevolen procedures
Gebruikmaken van parallelle uitvoering. Met de meeste technologieën voor het verwerken van big data wordt de workload gedistribueerd over meerdere verwerkingseenheden. Hiervoor moeten statistische gegevensbestanden worden gemaakt en opgeslagen in een splitsbare indeling. Lees- en schrijfvaardigheden kunnen worden geoptimaliseerd met gedistribueerde bestandssystemen zoals HDFS, en de werkelijke verwerking wordt parallel uitgevoerd op meerdere clusterknooppunten, wat de algemene tijden voor taken inkort.
Partitiegegevens. Batchverwerking vindt meestal plaats volgens een terugkerend schema, bijvoorbeeld wekelijks of maandelijks. Verdeel gegevensbestanden, en gegevensstructuren zoals tabellen, op basis van tijdsperiode die overeenkomen met het verwerkingsschema. Dit vereenvoudigt de gegevensopname en taakplanning, en maakt het eenvoudiger om problemen op te lossen. Bovendien kunnen de prestaties van query’s aanzienlijk worden verbeterd met behulp van partitietabellen die worden gebruikt in Hive-, U-SQL- of SQL-query’s.
Semantiek toepassen voor planning tijdens het lezen. Met behulp van een data lake kunt u opslag voor bestanden in meerdere indelingen combineren, ongeacht of ze gestructureerd, semigestructureerd of ongestructureerd zijn. Gebruik semantiek voor planning tijdens het lezen, waarmee een planning wordt geprojecteerd op de gegevens tijdens de verwerking ervan, en niet wanneer de gegevens zijn opgeslagen. Dit maakt de oplossing flexibeler, en voorkomt knelpunten gedurende de gegevensopname die worden veroorzaakt door gegevensvalidatie en typecontrole.
Gegevens in-place verwerken. Traditionele BI-oplossingen maken vaak gebruik van een ETL-proces (uitpakken, transformeren, laden) om gegevens te verplaatsen naar datawarehouses. Bij grotere hoeveelheden gegevens en een grotere verscheidenheid aan indelingen, maken big data-oplossingen gewoonlijk gebruik van variaties op ETL, zoals TEL (transformeren, uitpakken en laden). Met deze methode worden de gegevens verwerkt in de gedistribueerde gegevensopslag, waar ze worden getransformeerd in de vereiste structuur. Vervolgens worden de getransformeerde gegevens verplaatst naar een analytische gegevensopslag.
Balans houden tussen gebruik en kosten voor tijd. Bij taken voor batchverwerking moet u twee factoren in overweging nemen: de kosten voor rekenknooppunten per eenheid en de kosten per minuut voor het gebruik van deze knooppunten om de taak te voltooien. Een batchtaak kan bijvoorbeeld acht uur duren bij vier knooppunten. Het kan echter zo zijn dat de taak alleen gedurende de eerste twee uur gebruikmaakt van alle vier de knooppunten, en dat er daarna slechts twee knooppunten zijn vereist. Als de hele taak op twee knooppunten wordt uitgevoerd, zou dit de totale duur van de taak verlengen, maar niet verdubbelen, zodat de totale kosten lager zijn. In sommige bedrijfsscenario's kan een langere verwerkingstijd beter zijn dan de hogere kosten voor het gebruik van onderbenutte clusterbronnen.
Afzonderlijke clusterresources. Bij het implementeren van HDInsight-clusters zijn de prestaties gewoonlijk beter als u afzonderlijke clusterresources inricht voor elke type workload. Hoewel Hive is opgenomen in Spark-clusters, moet u, als u een uitgebreide verwerking wilt uitvoeren met zowel Hive als Spark, bijvoorbeeld overwegen om afzonderlijke toegewijde Spark- en Hadoop-clusters te implementeren. Ook moet u overwegen om, als u HBase en Storm gebruikt voor de verwerking van stromen met een lage latentie en Hive gebruikt voor batchverwerking, afzonderlijke clusters te gebruiken voor Storm, HBase en Hadoop.
Gegevensopname organiseren. In sommige gevallen kunnen gegevensbestanden voor batchverwerking met bestaande bedrijfstoepassingen rechtstreeks in Azure Storage-blobcontainers worden geschreven, waar ze kunnen worden gebruikt in HDInsight of Azure Data Lake Analytics. U moet dan echter vaak de gegevensopname organiseren vanuit on-premises of externe gegevensbronnen in een data lake. Gebruik een indelingswerkstroom of pijplijn, zoals ondersteund in Azure Data Factory of Oozie, om dit op een voorspelbare en centraal beheerde manier te bereiken.
Gevoelige gegevens in een vroeg stadium wissen. Met de werkstroom voor gegevensopname moeten gevoelige gegevens in een vroeg stadium worden gewist, om te voorkomen dat ze worden opgeslagen in de data lake.
IoT-architectuur
Internet of Things (IoT) is een gespecialiseerde subset van big data-oplossingen. Het volgende diagram toont een mogelijke logische architectuur voor IoT. In het diagram ligt de nadruk op de onderdelen van de architectuur die gebeurtenisstromen verwerken.
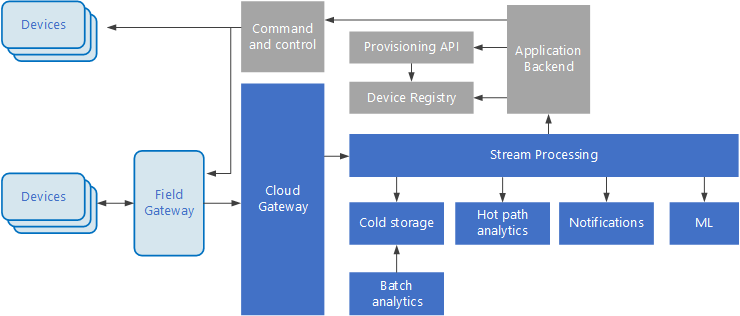
De cloudgateway neemt apparaatgebeurtenissen op bij de cloudgrens met behulp van een betrouwbaar berichtensysteem met lage latentie.
Apparaten kunnen gebeurtenissen rechtstreeks naar de cloudgateway of via een veldgateway verzenden. Een veldgateway is een speciaal apparaat of speciale software, meestal op dezelfde locatie als de apparaten, die gebeurtenissen ontvangt en doorstuurt naar de cloudgateway. De veldgateway mogelijk kan ook de ongecodeerde apparaatgebeurtenissen voorverwerken, waarbij functies worden uitgevoerd als filteren, aggregeren of protocoltransformatie.
Als de gebeurtenissen zijn opgenomen, gaan ze door een of meer streamprocessors die de gegevens kunnen routeren (bijvoorbeeld naar de opslag), analyseren of op een andere manier verwerken.
Hieronder vindt u enkele algemene typen verwerking. (Deze lijst is niet volledig.)
Het schrijven van gebeurtenisgegevens naar koude opslag, voor archivering of batchanalyse.
Analyse van het langzame pad, waarbij de gebeurtenisstroom nagenoeg in realtime wordt geanalyseerd om afwijkingen te detecteren, patronen in voortschrijdende tijdvensters te herkennen of alarmen te activeren als zich een bepaalde toestand in de stream voordoet.
Afhandelen van speciale typen niet-telemetrieberichten van apparaten, zoals meldingen en alarmen.
Machine learning.
De grijze vakken tonen onderdelen van een IoT-systeem die niet direct verband houden met het streamen van gebeurtenissen, maar zijn ter verduidelijking opgenomen.
Het apparaatregister is een database van de ingerichte apparaten, waaronder apparaat-id's en gewoonlijk metagegevens van apparaten, zoals de locatie.
De inrichtings-API is een normale, externe interface voor het inrichten en registreren van nieuwe apparaten.
In sommige IoT-oplossingen kunnen berichten met opdrachten en besturingsgegevens naar apparaten worden verzonden.
Deze sectie presenteert een zeer hoog niveau van IoT. U dient rekening te houden met een groot aantal finesses en uitdagingen. Zie Microsoft Azure IoT Reference Architecture (Referentiearchitectuur voor Microsoft Azure IoT, te downloaden als PDF) voor meer informatie en discussie.
Volgende stappen
- Meer informatie over big data-architecturen.
- Meer informatie over het ontwerp van ioT-architectuur (Internet of Things).