Kunstmatige intelligentie biedt het potentieel om retailing te transformeren zoals we dat vandaag kennen. Het is redelijk om te geloven dat retailers een architectuur voor klantervaringen ontwikkelen die wordt ondersteund door AI. Sommige verwachtingen zijn dat een platform dat is verbeterd met AI, een omzetstoot biedt vanwege hyper-personalisatie. Digitale handel blijft de verwachtingen, voorkeuren en gedrag van klanten verder verhoogd. Eisen zoals realtime betrokkenheid, relevante aanbevelingen en hyper-personalisatie zijn de rijsnelheid en het gemak met een klik op een knop. We maken intelligentie in toepassingen mogelijk via natuurlijke spraak, visie, enzovoort. Deze intelligentie maakt verbeteringen in de detailhandel mogelijk die de waarde verhogen en tegelijkertijd verstoren hoe klanten winkelen.
Dit document richt zich op het AI-concept van visuele zoekopdrachten en biedt enkele belangrijke overwegingen voor de implementatie ervan. Het biedt een voorbeeld van een werkstroom en wijst de fasen ervan toe aan de relevante Azure-technologieën. Het concept is gebaseerd op klanten die gebruik kunnen maken van een installatiekopieën die zijn gemaakt met hun mobiele apparaat of die zich op internet bevinden. Ze voeren een zoekopdracht uit van relevante en dergelijke items, afhankelijk van de bedoeling van de ervaring. Visuele zoekopdrachten verbeteren de snelheid van tekstinvoer naar een afbeelding met meerdere metagegevenspunten om snel alle toepasselijke items weer te geven die beschikbaar zijn.
Visuele zoekmachines
Visuele zoekmachines halen informatie op met behulp van afbeeldingen als invoer, maar niet uitsluitend als uitvoer.
Motoren worden steeds vaker gebruikt in de detailhandel en om zeer goede redenen:
- Ongeveer 75% van de internetgebruikers zoeken naar foto's of video's van een product voordat ze een aankoop doen, volgens een Emarketer-rapport dat in 2017 is gepubliceerd.
- 74% van de consumenten vindt tekstzoekopdrachten ook inefficiënt, volgens een Slyce -rapport (een visueel zoekbedrijf) 2015.
Daarom zal de beeldherkenningsmarkt meer dan $ 25 miljard in 2019 waard zijn, volgens onderzoek door Markets & Markets.
De technologie heeft zich al bezig gehouden met grote e-commercemerken, die ook aanzienlijk hebben bijgedragen aan de ontwikkeling ervan. De meest prominente vroege gebruikers zijn waarschijnlijk:
- eBay met hun afbeeldingen zoeken en 'Zoeken op eBay' hulpmiddelen in hun app (dit is momenteel alleen een mobiele ervaring).
- Pinterest met hun Lens visuele detectiehulpmiddel.
- Microsoft met Bing Visual Search.
Aannemen en aanpassen
Gelukkig hebt u geen grote hoeveelheden rekenkracht nodig om te profiteren van visuele zoekopdrachten. Elk bedrijf met een afbeeldingscatalogus kan profiteren van de AI-expertise van Microsoft die is ingebouwd in de Azure-services.
Bing Visual Search-API biedt een manier om contextinformatie te extraheren uit afbeeldingen, het identificeren van bijvoorbeeld woninginrichting, mode, verschillende soorten producten, enzovoort.
Het retourneert ook visueel vergelijkbare afbeeldingen uit een eigen catalogus, producten met relatieve winkelbronnen, gerelateerde zoekopdrachten. Hoewel dit interessant is, is dit van beperkt gebruik als uw bedrijf geen van deze bronnen is.
Bing biedt ook het volgende:
- Tags waarmee u objecten of concepten in de afbeelding kunt verkennen.
- Begrenzingsvakken voor interessegebieden in de afbeelding (zoals voor kleding of meubelartikelen).
U kunt deze informatie gebruiken om de zoekruimte (en tijd) aanzienlijk te beperken tot de productcatalogus van een bedrijf, waardoor deze wordt beperkt tot objecten zoals die in de regio en categorie van belang.
Uw eigen implementeren
Er zijn enkele belangrijke onderdelen waarmee u rekening moet houden bij het implementeren van visuele zoekopdrachten:
- Afbeeldingen opnemen en filteren
- Opslag- en ophaaltechnieken
- Featurization, codering of hashing
- Overeenkomsten metingen of afstanden en rangschikking
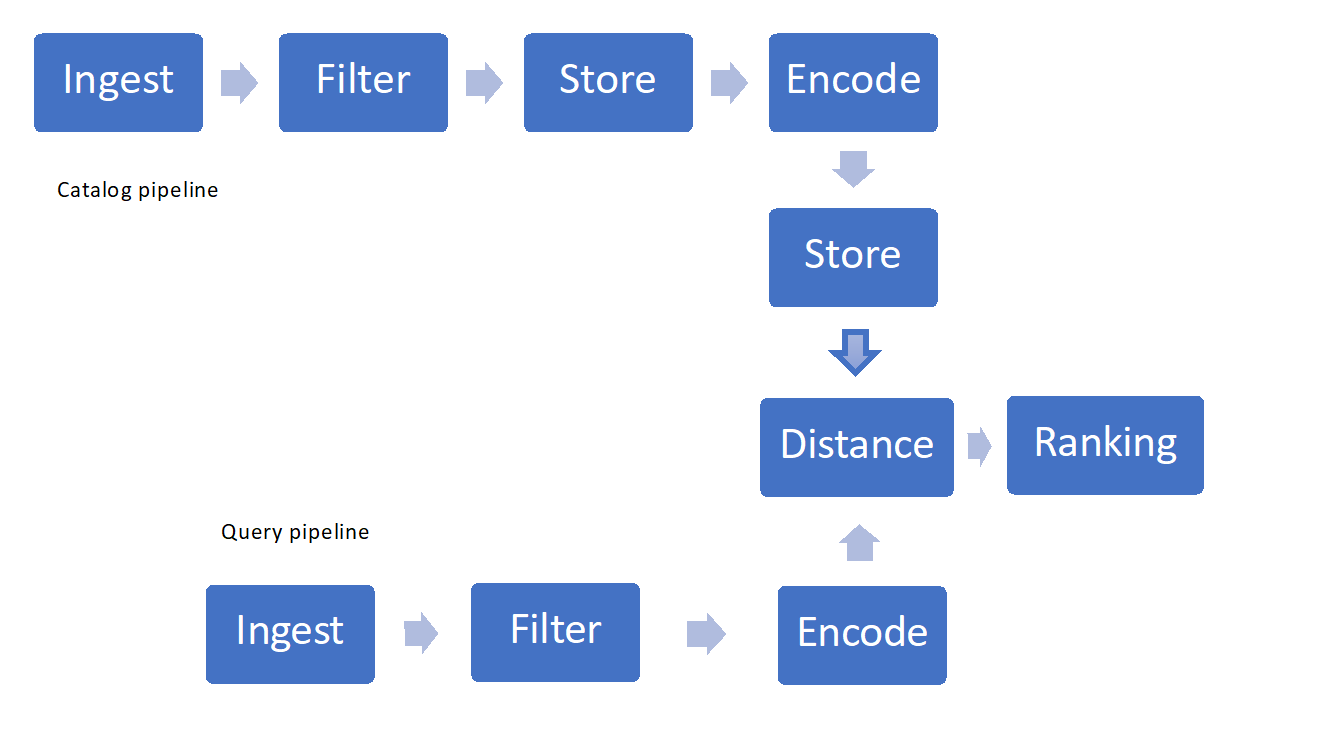
Afbeelding 1: Voorbeeld van Visual Search Pipeline
De afbeeldingen kopen
Als u geen afbeeldingscatalogus hebt, moet u mogelijk de algoritmen trainen op open beschikbare gegevenssets, zoals mode MNIST, deep fashion, enzovoort. Ze bevatten verschillende categorieën producten en worden vaak gebruikt voor het benchmarken van afbeeldingscategorisatie- en zoekalgoritmen.

Afbeelding 2: Een voorbeeld van de DeepFashion-gegevensset
De afbeeldingen filteren
De meeste benchmarkgegevenssets, zoals eerder vermeld, zijn al vooraf verwerkt.
Als u uw eigen benchmark bouwt, wilt u minimaal dat de afbeeldingen allemaal dezelfde grootte hebben, meestal bepaald door de invoer waarvoor uw model is getraind.
In veel gevallen is het ook het beste om de helderheid van de afbeeldingen te normaliseren. Afhankelijk van het detailniveau van uw zoekopdracht, kan kleur ook redundante informatie zijn, waardoor het verminderen van zwart-wit helpt bij de verwerkingstijden.
Ten slotte moet de afbeeldingsgegevensset worden verdeeld over de verschillende klassen die deze vertegenwoordigt.
Afbeeldingsdatabase
De gegevenslaag is een bijzonder gevoelig onderdeel van uw architectuur. Deze bevat:
- Afbeeldingen
- Metagegevens over de afbeeldingen (grootte, tags, product-SKU's, beschrijving)
- Gegevens die worden gegenereerd door het machine learning-model (bijvoorbeeld een numerieke vector van 4096-elementen per afbeelding)
Wanneer u afbeeldingen ophaalt uit verschillende bronnen of verschillende machine learning-modellen gebruikt voor optimale prestaties, verandert de structuur van de gegevens. Het is daarom belangrijk om een technologie of combinatie te kiezen die kan omgaan met semi-gestructureerde gegevens en geen vast schema.
Mogelijk wilt u ook een minimum aantal nuttige gegevenspunten vereisen (zoals een afbeeldings-id of -sleutel, een product-sKU, een beschrijving of een tagveld).
Azure Cosmos DB biedt de vereiste flexibiliteit en een verscheidenheid aan toegangsmechanismen voor toepassingen die erop zijn gebouwd (die u helpen bij het zoeken in uw catalogus). Een moet echter voorzichtig zijn om de beste prijs/prestaties te rijden. Met Azure Cosmos DB kunnen documentbijlagen worden opgeslagen, maar er is een totale limiet per account en dit kan een kostbare propositie zijn. Het is gebruikelijk om de werkelijke afbeeldingsbestanden in blobs op te slaan en een koppeling naar deze bestanden in de database in te voegen. In het geval van Azure Cosmos DB betekent dit dat u een document maakt dat de cataloguseigenschappen bevat die zijn gekoppeld aan die afbeelding (zoals een SKU, tag, enzovoort) en een bijlage die de URL van het afbeeldingsbestand bevat (bijvoorbeeld in Azure Blob Storage, OneDrive enzovoort).
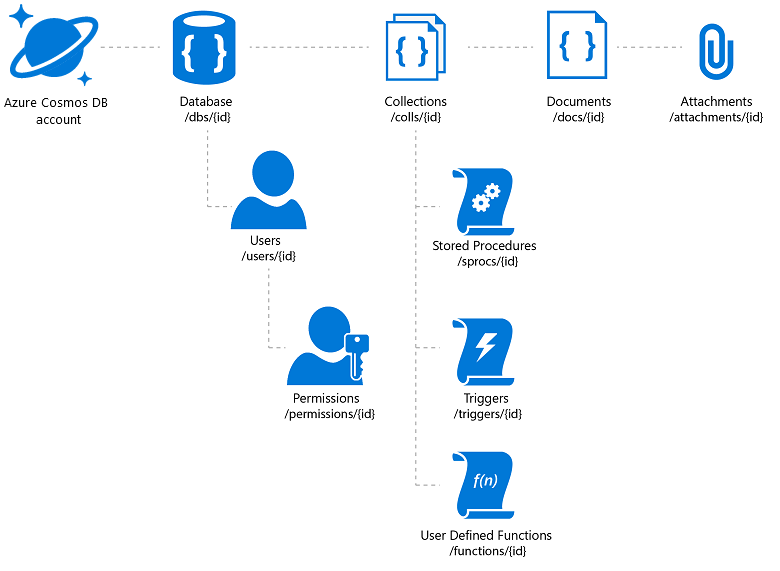
Afbeelding 3: Hiërarchisch resourcemodel van Azure Cosmos DB
Als u van plan bent om te profiteren van de wereldwijde distributie van Azure Cosmos DB, moet u er rekening mee houden dat de documenten en bijlagen worden gerepliceerd, maar niet de gekoppelde bestanden. U kunt een netwerk voor inhoudsdistributie overwegen.
Andere toepasselijke technologieën zijn een combinatie van Azure SQL Database (indien vast schema acceptabel) en blobs, of zelfs Azure Tables en blobs voor goedkope en snelle opslag en ophalen.
Functieextractie en codering
Het coderingsproces extraheert opvallende kenmerken uit afbeeldingen in de database en wijst ze allemaal toe aan een parserende 'functie'-vector (een vector met veel nullen) die duizenden onderdelen kan bevatten. Deze vector is een numerieke weergave van de kenmerken (zoals randen en vormen) die de afbeelding karakteriseren. Het is vergelijkbaar met een code.
Functieextractietechnieken maken doorgaans gebruik van overdrachtsleermechanismen. Dit gebeurt wanneer u een vooraf getraind neuraal netwerk selecteert, elke afbeelding er doorheen uitvoert en de functievector opslaat die wordt geproduceerd in uw afbeeldingsdatabase. Op die manier 'brengt u' het leerproces over van degene die het netwerk heeft getraind. Microsoft heeft verschillende vooraf getrainde netwerken ontwikkeld en gepubliceerd die veel zijn gebruikt voor afbeeldingsherkenningstaken, zoals ResNet50.
Afhankelijk van het neurale netwerk is de functievector meer of minder lang en parserend, waardoor de geheugen- en opslagvereisten variëren.
Het is ook mogelijk dat verschillende netwerken van toepassing zijn op verschillende categorieën, waardoor een implementatie van visuele zoekopdrachten in feite functievectors van verschillende grootte kan genereren.
Vooraf getrainde neurale netwerken zijn relatief eenvoudig te gebruiken, maar zijn mogelijk niet zo efficiënt als een aangepast model dat is getraind in uw afbeeldingscatalogus. Deze vooraf getrainde netwerken zijn doorgaans ontworpen voor het classificeren van benchmarkgegevenssets in plaats van te zoeken in uw specifieke verzameling afbeeldingen.
U kunt ze wijzigen en opnieuw trainen, zodat ze zowel een categorievoorspelling als een compacte vector (dus kleinere, niet parse) vector produceren, die erg nuttig is om de zoekruimte te beperken, geheugen- en opslagvereisten te verminderen. Binaire vectoren kunnen worden gebruikt en worden vaak aangeduid als ' semantische hash': een term die is afgeleid van documentcoderings- en ophaaltechnieken. De binaire weergave vereenvoudigt verdere berekeningen.

Afbeelding 4: Wijzigingen in ResNet voor Visual Search – F. Yang et al., 2017
Of u nu vooraf getrainde modellen kiest of zelf wilt ontwikkelen, u moet nog steeds bepalen waar u de featurization en/of training van het model zelf moet uitvoeren.
Azure biedt verschillende opties: VM's, Azure Batch, Batch AI, Databricks-clusters. In alle gevallen wordt echter de beste prijs/prestaties gegeven door het gebruik van GPU's.
Microsoft heeft onlangs ook de beschikbaarheid van FPGA's aangekondigd voor snelle berekeningen met een fractie van de GPU-kosten (project Brainwave). Op het moment van schrijven is dit aanbod echter beperkt tot bepaalde netwerkarchitecturen, dus u moet hun prestaties nauwkeurig evalueren.
Gelijkenismeting of afstand
Wanneer de afbeeldingen worden weergegeven in de functievectorruimte, wordt het zoeken naar overeenkomsten een kwestie van het definiëren van een afstandsmeting tussen punten in die ruimte. Zodra een afstand is gedefinieerd, kunt u clusters met vergelijkbare afbeeldingen berekenen en/of overeenkomsten matrices definiëren. Afhankelijk van de geselecteerde metrische afstand kunnen de resultaten variëren. De meest voorkomende Euclidean afstandsmeting over reële getalvectoren is bijvoorbeeld gemakkelijk te begrijpen: het legt de grootte van de afstand vast. Het is echter nogal inefficiënt in termen van berekeningen.
Cosinusafstand wordt vaak gebruikt om de richting van de vector vast te leggen, in plaats van de grootte ervan.
Alternatieven zoals Hamming-afstand over binaire representaties ruilen enige nauwkeurigheid voor efficiëntie en snelheid.
De combinatie van vectorgrootte en afstandsmeting bepaalt hoe rekenintensief en geheugenintensief de zoekopdracht zal zijn.
Zoeken en rangschikking
Zodra overeenkomsten zijn gedefinieerd, moeten we een efficiënte methode bedenken om de dichtstbijzijnde N-items op te halen die als invoer zijn doorgegeven en vervolgens een lijst met id's retourneren. Dit wordt ook wel 'afbeeldingsclassificatie' genoemd. Voor een grote gegevensset is de tijd die nodig is om elke afstand te berekenen verboden, dus we gebruiken geschatte algoritmen voor dichtstbijzijnde buren. Er bestaan verschillende opensource-bibliotheken voor die bibliotheken, dus u hoeft ze niet helemaal opnieuw te codeeren.
Ten slotte bepalen geheugen- en rekenvereisten de keuze van implementatietechnologie voor het getrainde model, evenals hoge beschikbaarheid. Normaal gesproken wordt de zoekruimte gepartitioneerd en worden verschillende exemplaren van het classificatie-algoritme parallel uitgevoerd. Een optie die schaalbaarheid en beschikbaarheid mogelijk maakt, is Azure Kubernetes-clusters . In dat geval is het raadzaam om het classificatiemodel in verschillende containers te implementeren (elk een partitie van de zoekruimte verwerken) en verschillende knooppunten (voor hoge beschikbaarheid).
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Giovanni Marchetti | Manager, Azure Solution Architects
- Mariya Zorotovich | Head of Customer Experience, HLS & Emerging Technology
Andere Inzenders:
- Scott Seely | Softwarearchitect
Volgende stappen
Het implementeren van visuele zoekopdrachten hoeft niet complex te zijn. U kunt Bing gebruiken of zelf bouwen met Azure-services, terwijl u profiteert van ai-onderzoek en hulpprogramma's van Microsoft.
Ontwikkelen
- Als u een aangepaste service wilt maken, raadpleegt u het overzicht van de Bing Visual Search-API
- Als u uw eerste aanvraag wilt maken, raadpleegt u de quickstarts: C# | Java | node.js Python |
- Maak uzelf vertrouwd met de Visual Search API Reference.
Achtergrond
- Deep Learning Image Segmentation: Microsoft Paper beschrijft het proces van het scheiden van afbeeldingen van achtergronden
- Visual Search op Ebay: Onderzoek van De Universiteit van Azure
- Onderzoek van Visual Discovery aan De Universiteit Van Pinterest
- Semantic Hashing University of Toronto research