Deze referentiearchitectuur laat zien hoe u een aanbevelingsmodel traint met behulp van Azure Databricks en het model vervolgens implementeert als EEN API met behulp van Azure Cosmos DB, Azure Machine Learning en Azure Kubernetes Service (AKS). Zie Een realtime aanbevelings-API bouwen op GitHub voor een referentie-implementatie van deze architectuur.
Architectuur
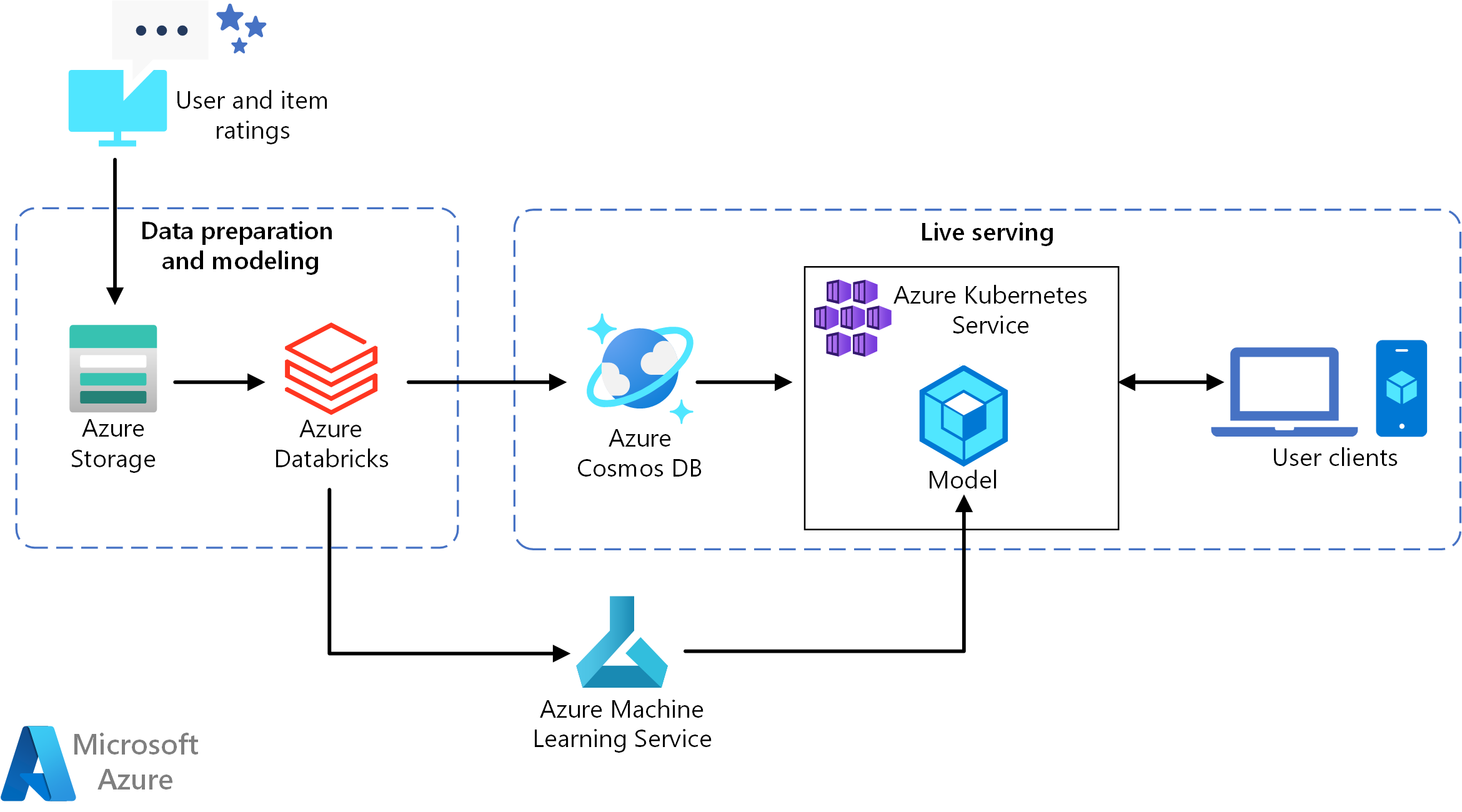
Een Visio-bestand van deze architectuur downloaden.
Deze referentiearchitectuur is bedoeld voor het trainen en implementeren van een realtime aanbevelingsservice-API die de top 10 filmaanbeveling voor een gebruiker kan bieden.
Gegevensstroom
- Gebruikersgedrag bijhouden. Een back-endservice kan bijvoorbeeld worden vastgelegd wanneer een gebruiker een film bekijkt of op een product- of nieuwsartikel klikt.
- Laad de gegevens in Azure Databricks vanuit een beschikbare gegevensbron.
- Bereid de gegevens voor en splitst deze op in trainings- en testsets om het model te trainen. (In deze handleiding worden opties beschreven voor het splitsen van gegevens.)
- Pas het Spark Collaborative Filtering-model aan de gegevens toe.
- Evalueer de kwaliteit van het model met behulp van classificatie- en classificatiegegevens. (Deze handleiding bevat details over de metrische gegevens die u kunt gebruiken om uw aanbeveling te evalueren.)
- De tien belangrijkste aanbevelingen per gebruiker vooraf compileren en opslaan als een cache in Azure Cosmos DB.
- Implementeer een API-service in AKS met behulp van de Machine Learning-API's om de API in een container te zetten en te implementeren.
- Wanneer de back-endservice een aanvraag van een gebruiker ontvangt, roept u de aanbevelingen-API aan die wordt gehost in AKS om de tien belangrijkste aanbevelingen te krijgen en weer te geven aan de gebruiker.
Onderdelen
- Azure Databricks. Databricks is een ontwikkelomgeving die wordt gebruikt om invoergegevens voor te bereiden en het aanbevelingsmodel op een Spark-cluster te trainen. Azure Databricks biedt ook een interactieve werkruimte voor het uitvoeren en samenwerken aan notebooks voor gegevensverwerking of machine learning-taken.
- Azure Kubernetes Service (AKS). AKS wordt gebruikt voor het implementeren en operationeel maken van een machine learning-modelservice-API op een Kubernetes-cluster. AKS fungeert als host voor het containermodel en biedt schaalbaarheid die voldoet aan uw doorvoervereisten, identiteits- en toegangsbeheer, en logboekregistratie en statuscontrole.
- Azure Cosmos DB. Azure Cosmos DB is een wereldwijd gedistribueerde databaseservice die wordt gebruikt om de tien aanbevolen films voor elke gebruiker op te slaan. Azure Cosmos DB is geschikt voor dit scenario, omdat het lage latentie (10 ms bij 99e percentiel) biedt om de aanbevolen items voor een bepaalde gebruiker te lezen.
- Machine Learning. Deze service wordt gebruikt voor het bijhouden en beheren van machine learning-modellen en vervolgens het verpakken en implementeren van deze modellen in een schaalbare AKS-omgeving.
- Microsoft-aanbevelingen. Deze opensource-opslagplaats bevat hulpprogrammacode en voorbeelden om gebruikers te helpen aan de slag te gaan met het bouwen, evalueren en operationeel maken van een aanbevelingssysteem.
Scenariodetails
Deze architectuur kan worden gegeneraliseerd voor de meeste scenario's met aanbevelingsengines, waaronder aanbevelingen voor producten, films en nieuws.
Potentiële gebruikscases
Scenario: Een mediaorganisatie wil aanbevelingen voor films of video's aan de gebruikers geven. Door persoonlijke aanbevelingen te bieden, voldoet de organisatie aan verschillende bedrijfsdoelen, waaronder verhoogde klik-through-tarieven, verhoogde betrokkenheid op de website en hogere gebruikerstevredenheid.
Deze oplossing is geoptimaliseerd voor de detailhandel en voor de media- en entertainmentindustrie.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Batchgewijs scoren van Spark-modellen in Azure Databricks beschrijft een referentiearchitectuur die gebruikmaakt van Spark en Azure Databricks om geplande batchscoreprocessen uit te voeren. We raden deze methode aan voor het genereren van nieuwe aanbevelingen.
Prestatie-efficiëntie
Prestatie-efficiëntie is de mogelijkheid om op efficiënte wijze uw werkbelasting te schalen om te voldoen aan de vereisten die gebruikers eraan stellen. Zie overzicht van de pijler Prestatie-efficiëntie voor meer informatie.
Prestaties zijn een belangrijke overweging voor realtime aanbevelingen, omdat aanbevelingen meestal in het kritieke pad van een gebruikersaanvraag op uw website vallen.
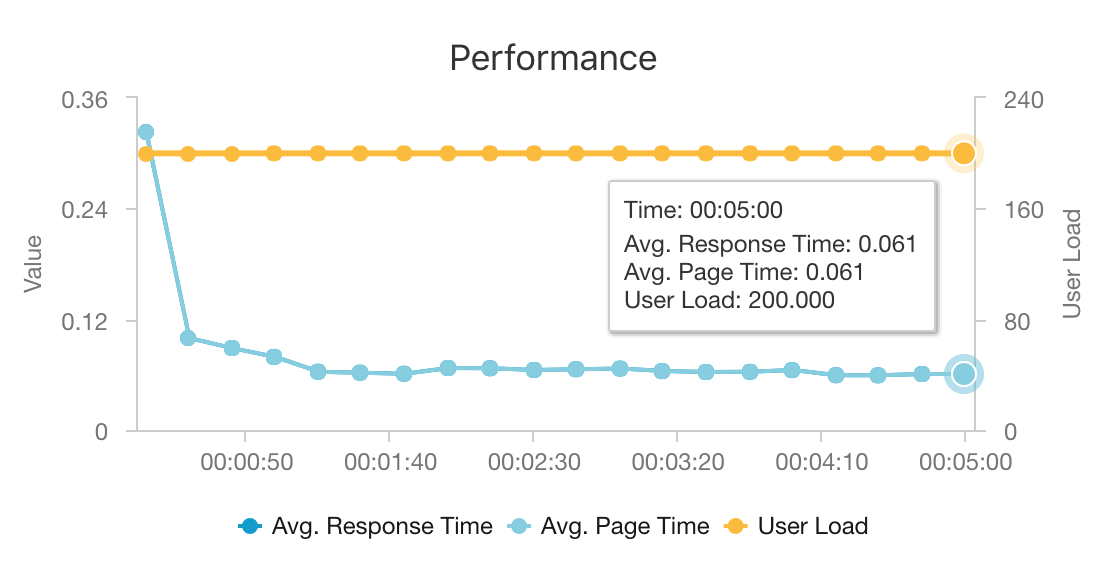
Met de combinatie van AKS en Azure Cosmos DB kan deze architectuur een goed startpunt bieden om aanbevelingen te doen voor een middelgrote workload met minimale overhead. Bij een belastingstest met 200 gelijktijdige gebruikers biedt deze architectuur aanbevelingen voor een mediaanlatentie van ongeveer 60 ms en wordt uitgevoerd bij een doorvoer van 180 aanvragen per seconde. De belastingstest is uitgevoerd op basis van de standaardimplementatieconfiguratie (een 3x D3 v2 AKS-cluster met 12 vCPU's, 42 GB geheugen en 11.000 aanvraageenheden (RU's) per seconde ingericht voor Azure Cosmos DB.

Azure Cosmos DB wordt aanbevolen voor de kant-en-klare wereldwijde distributie en bruikbaarheid bij het voldoen aan de databasevereisten die uw app heeft. Als u de latentie enigszins wilt verminderen, kunt u overwegen om Azure Cache voor Redis te gebruiken in plaats van Azure Cosmos DB om zoekopdrachten te verwerken. Azure Cache voor Redis kan de prestaties van systemen verbeteren die sterk afhankelijk zijn van gegevens in back-endarchieven.
Schaalbaarheid
Als u geen Spark wilt gebruiken of als u een kleinere workload hebt die geen distributie nodig heeft, kunt u overwegen om een Datawetenschap Virtuele Machine (DSVM) te gebruiken in plaats van Azure Databricks. Een DSVM is een virtuele Azure-machine met deep learning-frameworks en hulpprogramma's voor machine learning en gegevenswetenschap. Net als bij Azure Databricks kan elk model dat u in een DSVM maakt, worden operationeel als een service op AKS via Machine Learning.
Tijdens de training richt u een groter Spark-cluster met vaste grootte in Azure Databricks in of configureert u automatisch schalen. Wanneer automatisch schalen is ingeschakeld, controleert Databricks de belasting van uw cluster en wordt naar behoefte omhoog en omlaag geschaald. Een groter cluster inrichten of uitschalen als u een grote gegevensgrootte hebt en u de hoeveelheid tijd wilt beperken die nodig is voor het voorbereiden of modelleren van taken.
Schaal het AKS-cluster om te voldoen aan uw prestatie- en doorvoervereisten. Zorg ervoor dat u het aantal pods omhoog schaalt om het cluster volledig te gebruiken en om de knooppunten van het cluster te schalen om te voldoen aan de vraag van uw service. U kunt automatisch schalen ook instellen op een AKS-cluster. Zie Een model implementeren in een Azure Kubernetes Service-cluster voor meer informatie.
Als u de prestaties van Azure Cosmos DB wilt beheren, schat u het aantal leesbewerkingen dat per seconde is vereist en richt u het aantal RU's per seconde (doorvoer) in. Gebruik aanbevolen procedures voor partitioneren en horizontaal schalen.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
De belangrijkste kostenfactoren in dit scenario zijn:
- De Azure Databricks-clustergrootte die is vereist voor de training.
- De AKS-clustergrootte die nodig is om te voldoen aan uw prestatievereisten.
- Azure Cosmos DB RU's die zijn ingericht om te voldoen aan uw prestatievereisten.
Beheer de kosten van Azure Databricks door minder vaak opnieuw te trainen en het Spark-cluster uit te schakelen wanneer dit niet wordt gebruikt. De AKS- en Azure Cosmos DB-kosten zijn gekoppeld aan de doorvoer en prestaties die uw site nodig heeft en worden omhoog en omlaag geschaald, afhankelijk van het volume van het verkeer naar uw site.
Dit scenario implementeren
Als u deze architectuur wilt implementeren, volgt u de Azure Databricks-instructies in het installatiedocument. Kort gezegd, voor de instructies moet u het volgende doen:
- Maak een Azure Databricks-werkruimte.
- Maak een nieuw cluster met de volgende configuratie in Azure Databricks:
- Clustermodus: Standaard
- Databricks Runtime-versie: 4.3 (inclusief Apache Spark 2.3.1, Scala 2.11)
- Python-versie: 3
- Type stuurprogramma: Standard_DS3_v2
- Werkroltype: Standard_DS3_v2 (min en max zoals vereist)
- Automatische beëindiging: (indien vereist)
- Spark-configuratie: (indien vereist)
- Omgevingsvariabelen: (indien vereist)
- Maak een persoonlijk toegangstoken in de Azure Databricks-werkruimte. Raadpleeg de documentatie voor Azure Databricks-verificatie voor meer informatie.
- Kloon de opslagplaats Microsoft Recommenders in een omgeving waar u scripts kunt uitvoeren (bijvoorbeeld uw lokale computer).
- Volg de installatie-instructies voor snelle installatie om de relevante bibliotheken in Azure Databricks te installeren.
- Volg de installatie-instructies voor snelle installatie om Azure Databricks voor te bereiden op operationalisatie.
- Importeer het NOTITIEblok voor ALS Movie Operationalization in uw werkruimte. Nadat u zich hebt aangemeld bij uw Azure Databricks-werkruimte, gaat u als volgt te werk:
- Klik aan de linkerkant van de werkruimte op Start .
- Klik met de rechtermuisknop op witruimte in uw basismap. Selecteer Importeren.
- Selecteer de URL en plak het volgende in het tekstveld:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Klik op Importeren.
- Open het notebook in Azure Databricks en koppel het geconfigureerde cluster.
- Voer het notebook uit om de Azure-resources te maken die nodig zijn om een aanbevelings-API te maken die de top-10 filmaanbeveling biedt voor een bepaalde gebruiker.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Miguel Fierro | Principal Datawetenschapper Manager
- Nikhil Joglekar | Product Manager, Azure-algoritmen en gegevenswetenschap
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Een REALTIME aanbevelings-API bouwen
- Wat is Azure Databricks?
- Azure Kubernetes Service
- Welkom bij Azure Cosmos DB
- Wat is Azure Machine Learning?