Deze referentie-architectuur heeft in de praktijk bewezen geschikt te zijn voor het uitvoeren van een toepassing met n-aantal lagen in meerdere Azure-regio's en biedt een hoge mate van beschikbaarheid en een robuuste infrastructuur voor noodherstel.
Architectuur
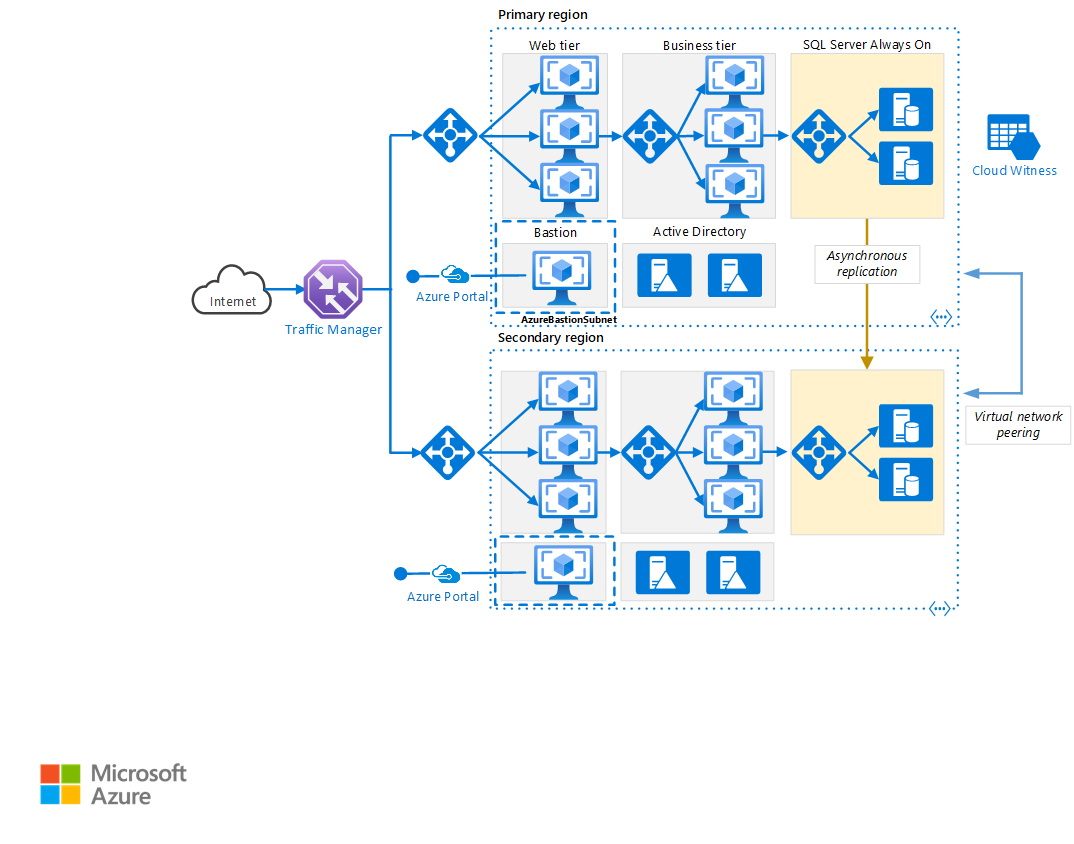
Een Visio-bestand van deze architectuur downloaden.
Werkstroom
Primaire en secundaire regio. Gebruik twee regio's voor hogere beschikbaarheid. De ene regio is de primaire regio. De andere regio is voor failover.
Azure Traffic Manager. Met Traffic Manager worden binnenkomende aanvragen gerouteerd naar een van de regio's. Normaliter worden aanvragen gerouteerd naar de primaire regio. Als de primaire regio niet beschikbaar is, wordt in Traffic Manager een Failover-schakeling naar de secundaire regio uitgevoerd. Zie de sectie Configuratie van Traffic Manager voor meer informatie.
Resourcegroepen. Maak afzonderlijke resourcegroepen voor de primaire regio, de secundaire regio en Traffic Manager. Deze methode biedt u de flexibiliteit om elke regio te beheren als één verzameling resources. U kunt bijvoorbeeld één regio opnieuw implementeren zonder de andere regio offline te nemen. Koppel de resourcegroepen, zodat u een query voor het weergeven van alle resources voor de toepassing kunt uitvoeren.
Virtuele netwerken. Maak een afzonderlijk virtueel netwerk voor elke regio. Zorg ervoor dat de adresruimten niet overlappen.
AlwaysOn-beschikbaarheidsgroep van SQL Server. Als u SQL Server gebruikt, raden we u aan SQL AlwaysOn-beschikbaarheidsgroepen te gebruiken voor hoge beschikbaarheid. Maak één beschikbaarheidsgroep met de SQL Server-exemplaren in beide regio's.
Notitie
Overweeg ook of u Azure SQL Database, een relationele database als een cloudservice, wilt gebruiken. Met SQL Database hoeft u geen beschikbaarheidsgroep te configureren of failover te beheren.
Peering van virtuele netwerken. Koppel de twee virtuele netwerken om gegevensreplicatie van de primaire regio naar de secundaire regio toe te staan. Zie Peering voor virtuele netwerken voor meer informatie.
Onderdelen
- Beschikbaarheidssets zorgen ervoor dat de VM's die u in Azure implementeert over meerdere geïsoleerde hardwareknooppunten in een cluster worden verdeeld. Als er een hardware- of softwarefout optreedt in Azure, wordt alleen een subset van uw VM's beïnvloed en blijft uw hele oplossing beschikbaar en operationeel.
- Beschikbaarheidszones beschermen uw toepassingen en gegevens tegen datacenterfouten. Beschikbaarheidszones zijn afzonderlijke fysieke locaties binnen een Azure-regio. Elke zone bestaat uit een of meer datacenters die zijn uitgerust met onafhankelijke voeding, koeling en netwerken.
- Azure Traffic Manager is een load balancer op basis van DNS die verkeer optimaal distribueert. Het biedt services in wereldwijde Azure-regio's, met hoge beschikbaarheid en reactiesnelheid.
- Azure Load Balancer distribueert inkomend verkeer volgens gedefinieerde regels en statustests. Een load balancer biedt lage latentie en hoge doorvoer, omhoog schalen naar miljoenen stromen voor alle TCP- en UDP-toepassingen. In dit scenario wordt een openbare load balancer gebruikt om binnenkomend clientverkeer te distribueren naar de weblaag. In dit scenario wordt een interne load balancer gebruikt om verkeer van de bedrijfslaag naar het BACK-end-SQL Server-cluster te distribueren.
- Azure Bastion biedt beveiligde RDP- en SSH-connectiviteit met alle VM's, in het virtuele netwerk waarin het is ingericht. Gebruik Azure Bastion om uw virtuele machines te beschermen tegen het blootstellen van RDP-/SSH-poorten aan de buitenwereld, terwijl u nog steeds beveiligde toegang biedt met behulp van RDP/SSH.
Aanbevelingen
Een architectuur met meerdere regio's kan zorgen voor een hogere beschikbaarheid dan een implementatie in één regio. Als een regionale storing van invloed is op de primaire regio, kunt u met Traffic Manager een Failover-schakeling naar de secundaire regio uitvoeren. Deze architectuur kan ook helpen als een afzonderlijk subsysteem van de toepassing uitvalt.
Er zijn verschillende algemene methoden voor het bereiken van maximale beschikbaarheid in regio's:
- Actief/passief met hot stand-by. Het verkeer wordt gerouteerd naar één regio, terwijl de andere regio wacht in hot stand-by. Hot stand-by betekent dat de VIRTUELE machines in de secundaire regio worden toegewezen en altijd worden uitgevoerd.
- Actief/passief met koude stand-by. Het verkeer wordt gerouteerd naar de ene regio, terwijl de andere regio wacht in koude stand-by. Koude stand-by betekent dat de VM's in de secundaire regio pas worden toegewezen als deze nodig zijn voor failover. Deze methode is goedkoper qua uitvoering, maar het duurt langer om het systeem weer online te brengen na uitval.
- Actief/actief. Beide regio's zijn actief en aanvragen worden gelijkmatig verdeeld tussen beide regio's. Als één regio niet meer beschikbaar is, wordt deze uit de rotatie gehaald.
Deze referentiearchitectuur is gericht op actief/passief met hot stand-by, en Traffic Manager voor failover. U kunt enkele VM's implementeren voor hot stand-by en vervolgens naar behoefte uitschalen.
Regioparen
Elke Azure-regio is gekoppeld aan een andere regio binnen dezelfde geografie. Over het algemeen kiest u regioparen uit dezelfde regio (bijvoorbeeld VS - oost 2 en VS - centraal). Dit heeft de volgende voordelen:
- Als er sprake is van een grote storing, krijgt herstel van ten minste één regio van elk paar prioriteit.
- Geplande Azure-systeemupdates worden na elkaar uitgerold voor gekoppelde regio's, om eventuele downtime tot een minimum te beperken.
- Regioparen bevinden zich vaak binnen dezelfde geografie, om te voldoen aan gegevenslocatievereisten.
Controleer wel of alle Azure-services die nodig zijn voor uw toepassing in beide regio's worden ondersteund (zie Services per regio). Zie Bedrijfscontinuïteit en herstel na noodgevallen (BCDR): gekoppelde Azure-regio's voor meer informatie over regioparen.
Configuratie van Traffic Manager
Houd rekening met de volgende punten bij het configureren van Traffic Manager:
- Routering. Traffic Manager biedt ondersteuning voor diverse routeringsalgoritmen. Voor het scenario dat in dit artikel wordt beschreven, gebruikt u routering voor prioriteit (voorheen routering voor failover). Bij deze instelling worden alle aanvragen door Traffic Manager verzonden naar de primaire regio, tenzij de primaire regio onbereikbaar wordt. Op dat moment wordt automatisch een Failover-schakeling naar de secundaire regio uitgevoerd. Zie Methode voor failover-routering configureren.
- Statustest. Traffic Manager maakt gebruik van een HTTP- (of HTTPS-)test om de beschikbaarheid van elke regio te controleren. Met de test wordt gecontroleerd op een HTTP 200-respons van een opgegeven URL-pad. Maak, als een best practice, een eindpunt waarmee de algemene status van de toepassing wordt gerapporteerd en gebruik dit eindpunt voor de statustest. Anders wordt mogelijk een gezond eindpunt (testresultaat Geslaagd) gerapporteerd, terwijl essentiële onderdelen van de toepassing in werkelijkheid niet correct functioneren. Zie het patroon Statuseindpuntbewaking voor meer informatie.
Wanneer Traffic Manager een failover uitvoert, is er een periode waarin clients de toepassing niet kunnen bereiken. Hoe lang dit duurt, is afhankelijk van de volgende factoren:
- Met de statustest moet worden gedetecteerd dat de primaire regio onbereikbaar is geworden.
- DNS-servers moeten de DNS-records voor het IP-adres in de cache bijwerken. Hoe lang dit duurt, is afhankelijk van de DNS TTL (Time To Live). Standaard is de TTL-waarde 300 seconden (5 minuten), maar u kunt deze waarde configureren wanneer u het Traffic Manager-profiel maakt.
Zie Traffic Manager-controle voor meer informatie.
Bij een failover van Traffic Manager raden wij u aan een handmatige failback uit te voeren in plaats van een automatische failback te implementeren. Anders ontstaat er een situatie waarin de toepassing steeds van de ene naar de andere regio wordt overgeschakeld. Voer een statuscontrole van alle subsystemen voor de toepassing uit voordat u een failback uitvoert.
Traffic Manager voert standaard automatisch een failback uit. U kunt dit probleem voorkomen door de prioriteit van de primaire regio handmatig te verlagen na een failover-gebeurtenis. Stel, de primaire regio heeft prioriteit 1 en de secundaire regio heeft prioriteit 2. Na een failover stelt u de primaire regio in op prioriteit 3, zodat er niet automatisch een failback wordt uitgevoerd. Wanneer u klaar bent om terug te schakelen, werkt u de prioriteit bij naar 1.
U wijzigt de prioriteit met de volgende Azure CLI-opdracht:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Een andere methode is om het eindpunt tijdelijk uit te schakelen totdat u klaar bent om failback uit te schakelen:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
Afhankelijk van de oorzaak van een failover, moet u de resources in een regio mogelijk opnieuw implementeren. Voordat u een failback uitvoert, moet u een operationele gereedheidstest uitvoeren. Tijdens de test moet onder meer het volgende worden gecontroleerd:
- Virtuele machines zijn juist geconfigureerd. (Alle vereiste software is geïnstalleerd, IIS is actief, enzovoort.)
- Subsystemen van de toepassing zijn in orde.
- Functionele testen. (Bijvoorbeeld: de databaselaag is bereikbaar vanaf de weblaag.)
AlwaysOn-beschikbaarheidsgroepen in SQL Server configureren
Vóór Windows Server 2016 vereisten AlwaysOn-beschikbaarheidsgroepen in SQL Server een domeincontroller en moesten alle knooppunten in de beschikbaarheidsgroep zich in hetzelfde AD-domein (Active Directory) bevinden.
De beschikbaarheidsgroep configureren:
Plaats ten minste twee domeincontrollers in elke regio.
Geef elke domeincontroller een statisch IP-adres.
Koppel de twee virtuele netwerken om communicatie tussen deze netwerken mogelijk te maken.
Voeg voor elk virtueel netwerk de IP-adressen van de domeincontrollers (van beide regio's) toe aan de lijst met DNS-servers. U kunt hiervoor de volgende opdracht in de opdrachtregelinterface gebruiken. Zie DNS-servers wijzigen voor meer informatie.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Maak een WSFC-cluster (Windows Server-failoverclustering) met de SQL Server-exemplaren in beide regio's.
Maak een AlwaysOn-beschikbaarheidsgroep in SQL Server met de SQL Server-exemplaren in de primaire en secundaire regio's. Zie Extending Always On Availability Group to Remote Azure Datacenter (PowerShell) (AlwaysOn-beschikbaarheidsgroep uitbreiden naar extern Azure-datacenter) voor de benodigde stappen.
Plaats de primaire replica in de primaire regio.
Plaats een of meer secundaire replica's in de primaire regio. Configureer deze replica's voor het gebruik van synchrone doorvoer met automatische failover.
Plaats een of meer secundaire replica's in de secundaire regio. Configureer deze replica's om asynchrone doorvoer te gebruiken om prestatieredenen. (Anders moeten alle T-SQL-transacties wachten op een retour via het netwerk naar de secundaire regio.)
Notitie
Asynchrone doorvoerreplica's bieden geen ondersteuning voor automatische failover.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Beschikbaarheid
Bij een complexe app met n-aantal lagen hoeft u wellicht niet hele toepassing in de secundaire regio te repliceren. In plaats daarvan kunt u ook alleen een kritiek subsysteem repliceren dat vereist is voor de bedrijfscontinuïteit.
Traffic Manager is een mogelijk punt van mislukken in het systeem. Als de Traffic Manager-service mislukt, hebben clients tijdens de downtime geen toegang tot uw toepassing. Controleer de SLA voor Traffic Manager en bepaal of het gebruik van alleen Traffic Manager voldoet aan uw zakelijke vereisten voor hoge beschikbaarheid. Als dat niet het geval is, overweeg dan een andere oplossing voor het beheer van verkeer toe te voegen als failback. Als de service Azure Traffic Manager uitvalt, wijzigt u de CNAME-records in DNS zodanig dat ze verwijzen naar de andere service voor verkeerbeheer. (Deze stap moet handmatig worden uitgevoerd en uw toepassing pas weer beschikbaar als de DNS-wijzigingen zijn doorgegeven.)
Voor de SQL Server-cluster moet u rekening houden met twee failoverscenario's:
Alle SQL Server-databasereplica's in de primaire regio mislukken. Deze fout kan bijvoorbeeld optreden tijdens een regionale storing. In dat geval moet u handmatig een Failover-schakeling van de beschikbaarheidsgroep uitvoeren, ook al wordt automatisch een Failover-schakeling van Traffic Manager uitgevoerd op de front-end. Volg de stappen in Perform a Forced Manual Failover of a SQL Server Availability Group (Engelstalig) uit. Hierin wordt beschreven hoe u een geforceerde failover kunt uitvoeren met SQL Server Management Studio, Transact-SQL of PowerShell in SQL Server 2016.
Waarschuwing
Bij geforceerde failover bestaat er een risico op gegevensverlies. Zodra de primaire regio weer online is, maakt u een momentopname van de database en gebruikt u tablediff om de verschillen te zoeken.
Er wordt een Failover-schakeling van Traffic Manager naar de secundaire regio uitgevoerd, maar de primaire replica van de SQL Server-database is nog steeds beschikbaar. De front-endlaag kan bijvoorbeeld mislukken, zonder de virtuele SQL Server-machines te beïnvloeden. In dat geval wordt het internetverkeer omgeleid naar de secundaire regio, en die regio kan nog steeds verbinding maken met de primaire replica. De latentie zal echter toenemen, vanwege de SQL Server-verbindingen tussen de verschillende regio's. In dit geval moet u als volgt een handmatige failover uitvoeren:
- Schakel een replica van de SQL Server-database in de secundaire regio tijdelijk over naar synchrone doorvoer. Deze stap zorgt ervoor dat er geen gegevens verloren gaan tijdens de failover.
- Voer een Failover-overschakeling naar die replica uit.
- Als u een failback naar de primaire regio uitvoert, herstelt u de instelling voor asynchrone doorvoer.
Beheerbaarheid
Werk, als u de implementatie wilt bijwerken, slechts één regio tegelijk bij om de kans op algehele uitval wegens een onjuiste configuratie of een fout in de toepassing te verkleinen.
Test de fouttolerantie van het systeem. Hier volgen enkele veelvoorkomende foutscenario's die u kunt testen:
- VM-exemplaren afsluiten.
- CPU- en geheugenresources zwaar belasten.
- Netwerkverbinding verbreken/vertragen.
- Processen laten vastlopen.
- Certificaten laten verlopen.
- Hardwarefouten simuleren.
- De DNS-service op de domeincontrollers afsluiten.
Meet de hersteltijden en controleer of deze voldoen aan de vereisten van uw bedrijf. Test ook combinaties van foutmodi.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
Gebruik de Azure-prijscalculator om de kosten te schatten. Hier volgen enkele andere overwegingen.
Virtuele-machineschaalsets
Virtuele-machineschaalsets zijn beschikbaar op alle Windows-VM-grootten. Er worden alleen kosten in rekening gebracht voor de Azure-VM's die u implementeert en eventuele toegevoegde onderliggende infrastructuurresources die worden verbruikt, zoals opslag en netwerken. Er worden geen incrementele kosten in rekening gebracht voor de service Virtuele-machineschaalsets.
Zie prijzen voor windows-VM's voor prijsopties voor enkele VM's.
SQL-server
Als u Azure SQL DBaas kiest, kunt u besparen op kosten omdat u geen AlwaysOn-beschikbaarheidsgroep en domeincontrollermachines hoeft te configureren. Er zijn verschillende implementatieopties vanaf één database tot een beheerd exemplaar of elastische pools. Zie De prijzen van Azure SQL voor meer informatie.
Zie prijzen voor SQL Server-VM's voor prijsopties voor SQL Server-VM's.
Load balancers
Er worden alleen kosten in rekening gebracht voor het aantal geconfigureerde taakverdelings- en uitgaande regels. Binnenkomende NAT-regels zijn gratis. Er worden geen uurkosten in rekening gebracht voor de Standard Load Balancer wanneer er geen regels zijn geconfigureerd.
Prijzen van Traffic Manager
Facturering voor Traffic Manager is gebaseerd op het aantal ontvangen DNS-query's, waarbij een korting geldt voor services die maandelijks meer dan 1 miljard query's ontvangen. Er worden ook kosten in rekening gebracht voor elk bewaakt eindpunt.
Raadpleeg de kostensectie in Microsoft Azure Well-Architected Framework voor meer informatie.
Prijzen voor VNET-peering
Een implementatie met hoge beschikbaarheid die gebruikmaakt van meerdere Azure-regio's, maakt gebruik van VNET-peering. Er zijn verschillende kosten voor VNET-peering binnen dezelfde regio en voor globale VNET-peering.
Zie Prijzen voor Virtual Network voor meer informatie.
DevOps
Gebruik één Azure Resource Manager-sjabloon voor het inrichten van de Azure-resources en de bijbehorende afhankelijkheden. Gebruik dezelfde sjabloon om de resources te implementeren in zowel primaire als secundaire regio's. Neem alle resources in hetzelfde virtuele netwerk op, zodat ze worden geïsoleerd in dezelfde basisworkload. Door alle resources op te slaan, kunt u de specifieke resources van de workload eenvoudiger koppelen aan een DevOps-team, zodat het team alle aspecten van deze resources onafhankelijk kan beheren. Dankzij deze isolatie kunnen DevOps Team en Services continue integratie en continue levering (CI/CD) uitvoeren.
U kunt ook verschillende Azure Resource Manager-sjablonen gebruiken en integreren met Azure DevOps Services om binnen enkele minuten verschillende omgevingen in te richten, bijvoorbeeld om productie te repliceren, zoals scenario's of belastingtestomgevingen, alleen wanneer dat nodig is, wat kosten bespaart.
Overweeg het gebruik van de Azure Monitor voor het analyseren en optimaliseren van de prestaties van uw infrastructuur, het bewaken en diagnosticeren van netwerkproblemen zonder u aan te melden bij uw virtuele machines. Application Insights is eigenlijk een van de onderdelen van Azure Monitor, waarmee u uitgebreide metrische gegevens en logboeken krijgt om de status van uw volledige Azure-landschap te controleren. Met Azure Monitor kunt u de status van uw infrastructuur volgen.
Zorg ervoor dat u niet alleen uw rekenelementen bewaakt die uw toepassingscode ondersteunen, maar ook uw gegevensplatform, met name uw databases, omdat een lage prestaties van de gegevenslaag van een toepassing ernstige gevolgen kunnen hebben.
Als u de Azure-omgeving wilt testen waarop de toepassingen worden uitgevoerd, moet deze versiebeheerd zijn en worden geïmplementeerd via dezelfde mechanismen als toepassingscode. Vervolgens kan deze ook worden getest en gevalideerd met behulp van DevOps-testparadigma's.
Zie de sectie Operational Excellence in Microsoft Azure Well-Architected Framework voor meer informatie.
Bijdragers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Donnie Trumpower | Senior Cloud Solution Architect
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
Verwante resources
In de volgende architectuur worden enkele van dezelfde technologieën gebruikt: