Zelfstudie: Een query uitvoeren op een SQL Server Linux Docker-container in een virtueel netwerk vanuit een Azure Databricks-notebook
In deze zelfstudie leert u hoe u Azure Databricks integreert met een SQL Server Linux Docker-container in een virtueel netwerk.
In deze zelfstudie leert u het volgende:
- Een Azure Databricks-werkruimte implementeren in een virtueel netwerk
- Een virtuele Linux-machine installeren in een openbaar netwerk
- Docker installeren
- Microsoft SQL Server on Linux Docker-container installeren
- Een query uitvoeren op de SQL Server met JDBC vanuit een Databricks-notebook
Voorwaarden
Installeer Ubuntu voor Windows.
Download SQL Server Management Studio.
Een virtuele Linux-machine maken
Selecteer in de Azure Portal het pictogram voor Virtual Machines. Selecteer vervolgens + Toevoegen.
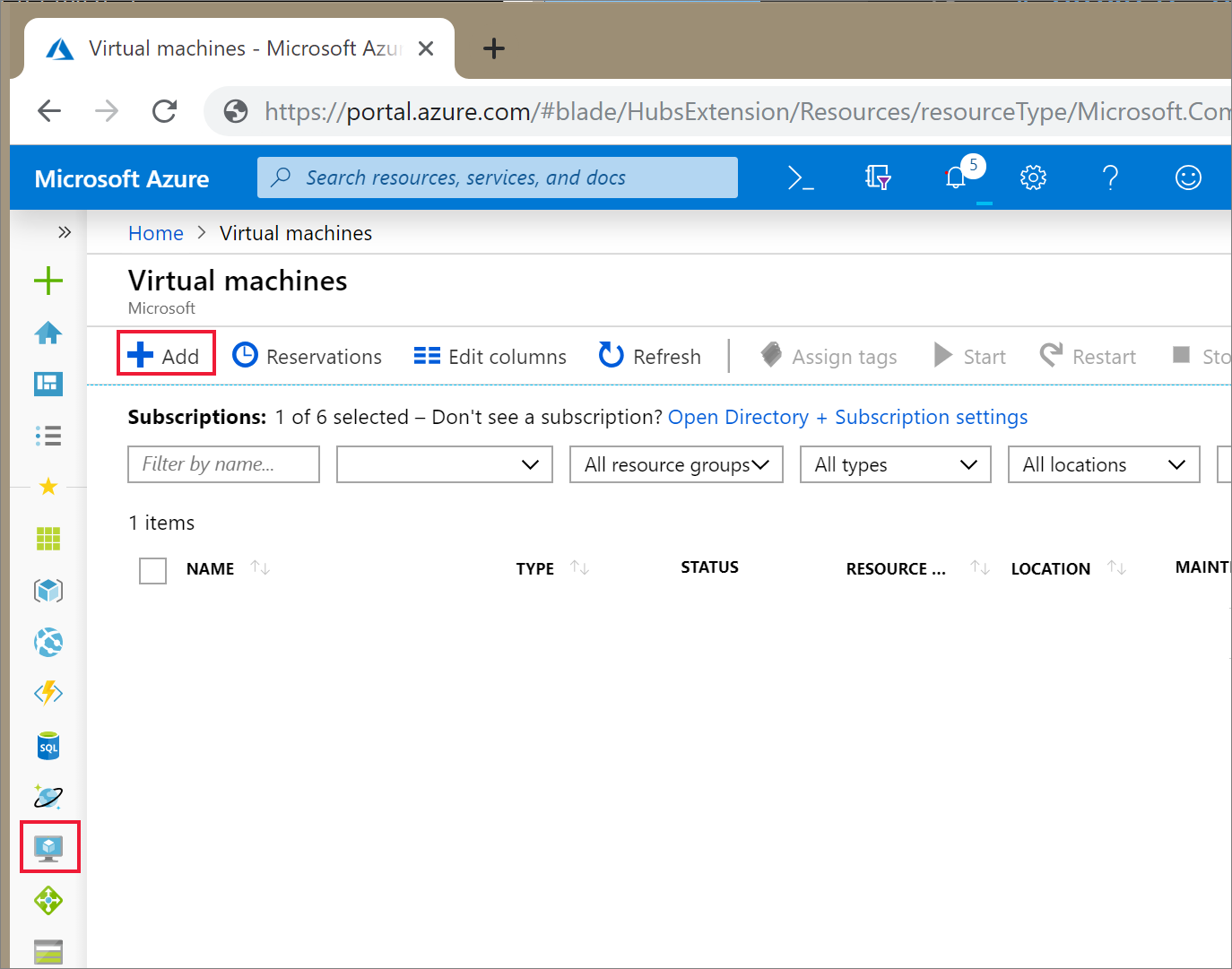
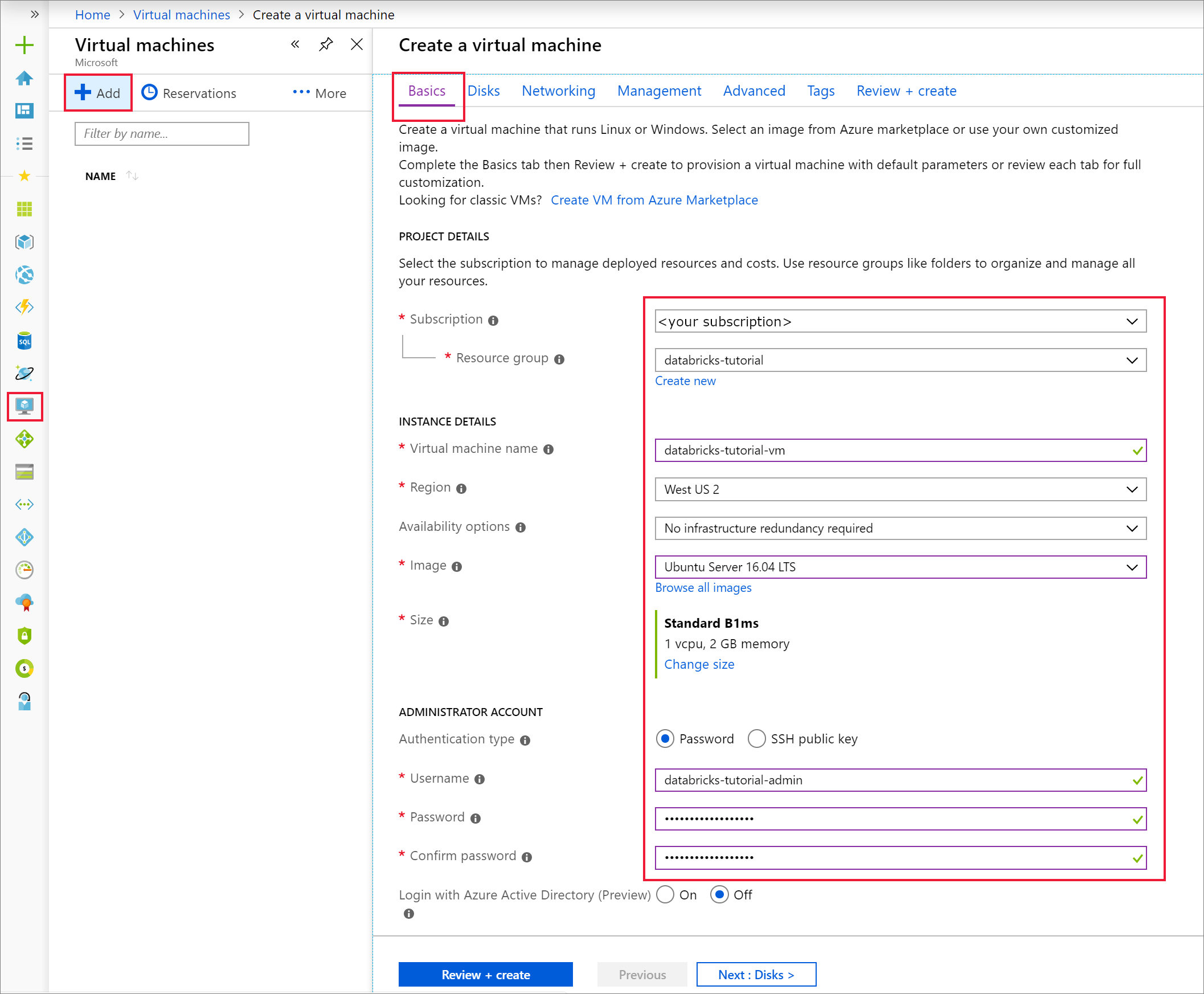
Kies Ubuntu Server 18.04 LTS op het tabblad Basisinformatie en wijzig de VM-grootte in B2s. Kies een gebruikersnaam en wachtwoord voor de beheerder.
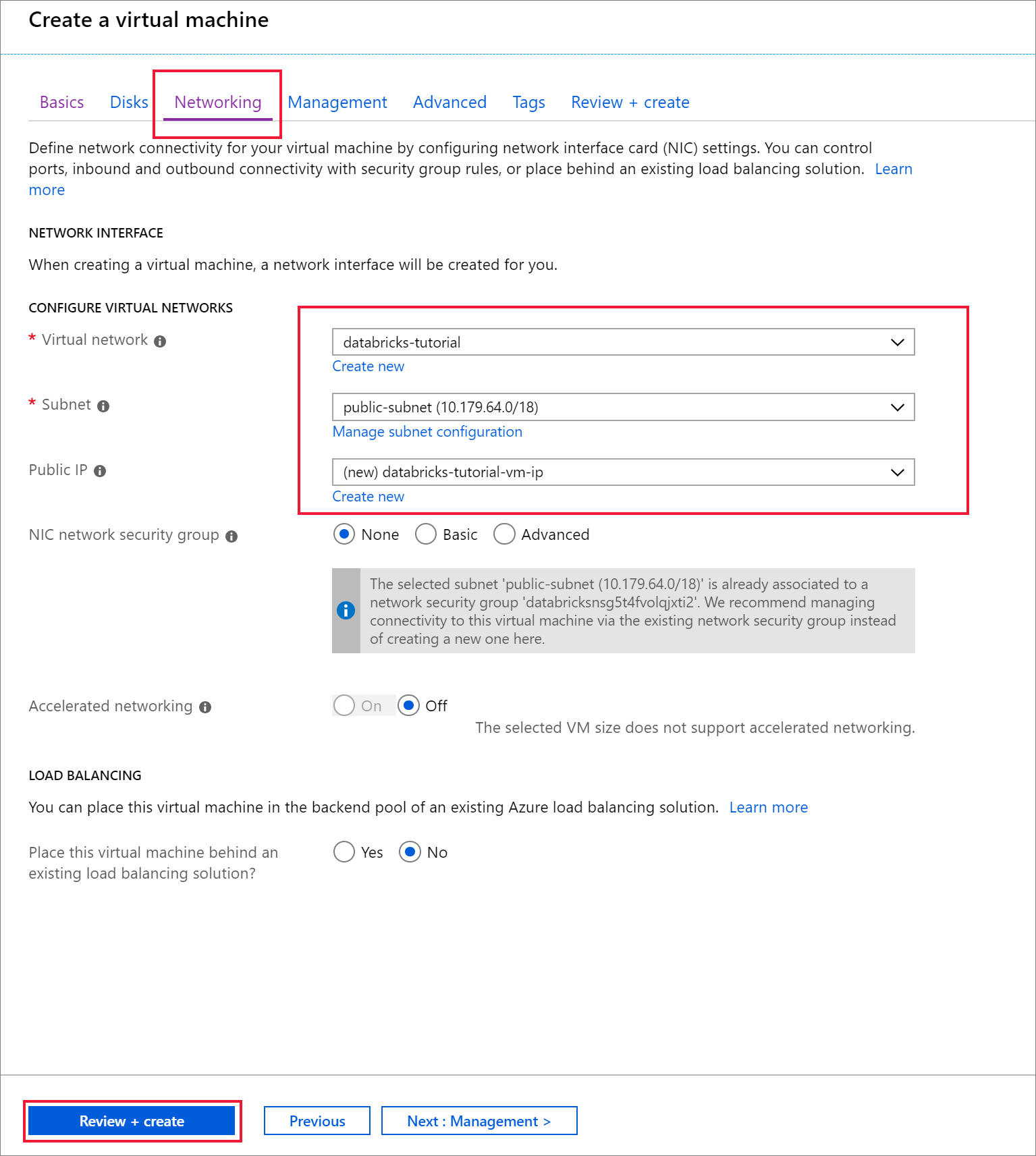
Ga naar het tabblad Netwerken . Kies het virtuele netwerk en het openbare subnet dat uw Azure Databricks-cluster bevat. Selecteer Beoordelen en maken en vervolgens Maken om de virtuele machine te implementeren.
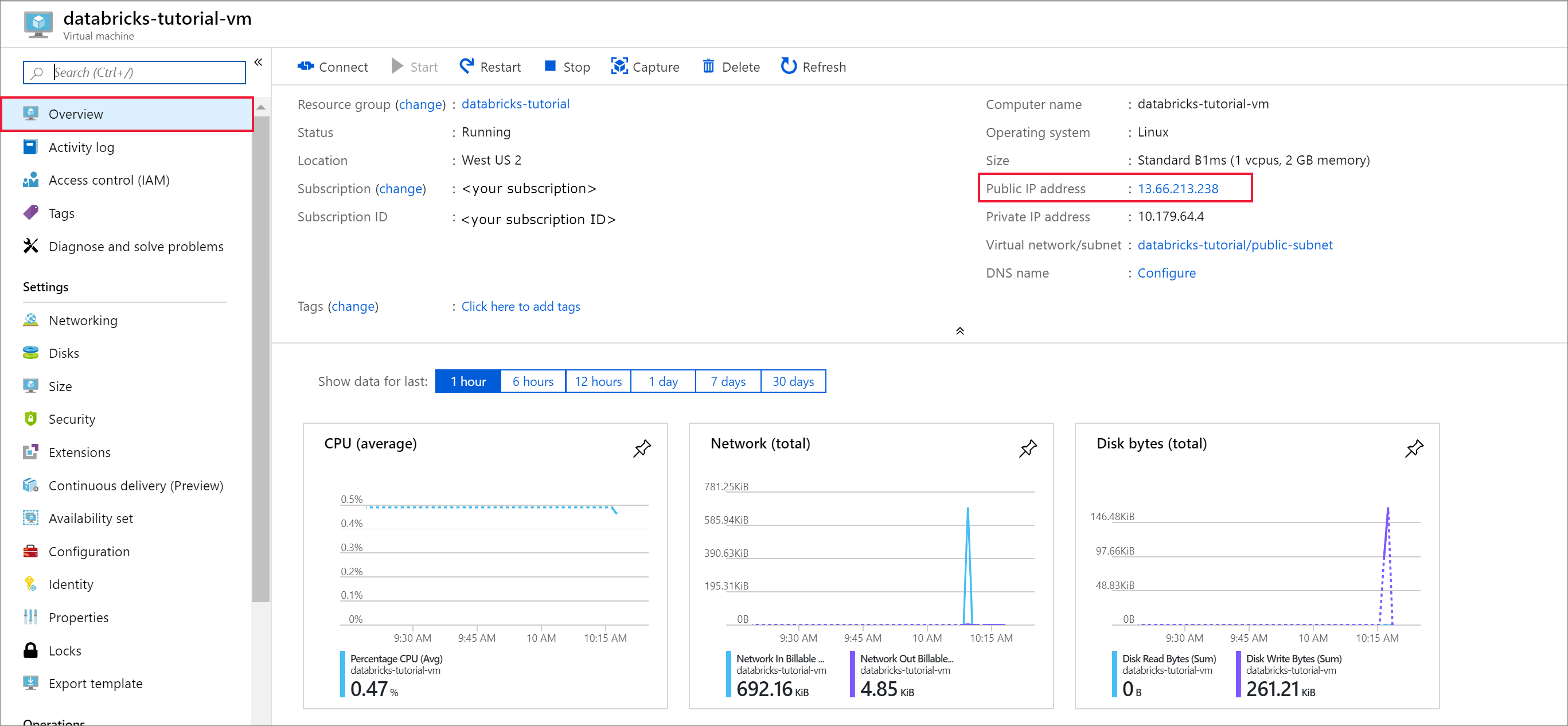
Wanneer de implementatie is voltooid, gaat u naar de virtuele machine. Let op het openbare IP-adres en het virtuele netwerk/subnet in het overzicht. Selecteer het openbare IP-adres
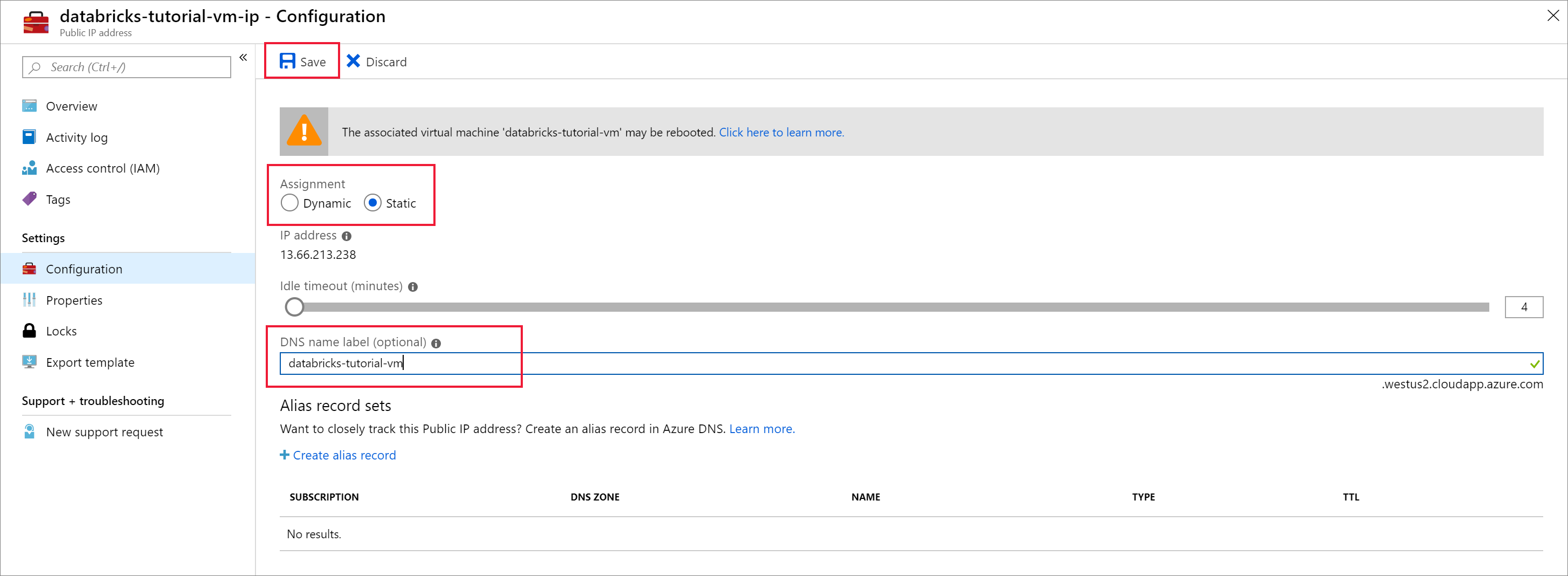
Wijzig de Toewijzing in Statisch en voer een DNS-naamlabel in. Selecteer Opslaan en start de virtuele machine opnieuw op.
Selecteer het tabblad Netwerken onder Instellingen. U ziet dat de netwerkbeveiligingsgroep die is gemaakt tijdens de Implementatie van Azure Databricks, is gekoppeld aan de virtuele machine. Selecteer Regel voor binnenkomende poort toevoegen.
Voeg een regel toe om poort 22 voor SSH te openen. Gebruik de volgende instellingen:
Instelling Voorgestelde waarde Beschrijving Bron IP-adressen IP-adressen geeft aan dat binnenkomend verkeer van een specifiek bron-IP-adres wordt toegestaan of geweigerd door deze regel. Bron-IP-adressen <uw openbare IP-adres> Voer het openbare IP-adres in. U kunt uw openbare IP-adres vinden door naar bing.com te gaan en te zoeken naar 'mijn IP'. Bronpoortbereiken * Verkeer vanaf elke poort toestaan. Bestemming IP-adressen IP-adressen geeft aan dat uitgaand verkeer voor een specifiek bron-IP-adres wordt toegestaan of geweigerd door deze regel. Doel-IP-adressen <openbaar IP-adres van uw vm> Voer het openbare IP-adres van de virtuele machine in. U vindt dit op de pagina Overzicht van uw virtuele machine. Poortbereiken van doel 22 Open poort 22 voor SSH. Prioriteit 290 Geef de regel een prioriteit. Naam ssh-databricks-tutorial-vm Geef de regel een naam. 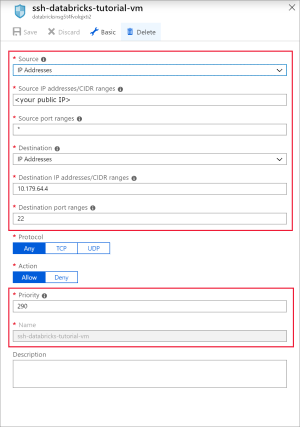
Voeg een regel toe om poort 1433 voor SQL te openen met de volgende instellingen:
Instelling Voorgestelde waarde Beschrijving Bron Alle Bron geeft aan dat binnenkomend verkeer van een specifiek bron-IP-adres wordt toegestaan of geweigerd door deze regel. Bronpoortbereiken * Verkeer vanaf elke poort toestaan. Bestemming IP-adressen IP-adressen geeft aan dat uitgaand verkeer voor een specifiek bron-IP-adres wordt toegestaan of geweigerd door deze regel. Doel-IP-adressen <openbaar IP-adres van uw vm> Voer het openbare IP-adres van de virtuele machine in. U vindt dit op de pagina Overzicht van uw virtuele machine. Poortbereiken van doel 1433 Open poort 22 voor SQL Server. Prioriteit 300 Geef de regel een prioriteit. Naam sql-databricks-tutorial-vm Geef de regel een naam. 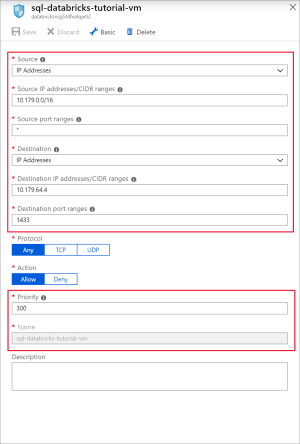
SQL Server uitvoeren in een Docker-container
Open Ubuntu voor Windows of een ander hulpprogramma waarmee u SSH kunt uitvoeren op de virtuele machine. Navigeer naar uw virtuele machine in de Azure Portal en selecteer Verbinding maken om de SSH-opdracht op te halen die u nodig hebt om verbinding te maken.
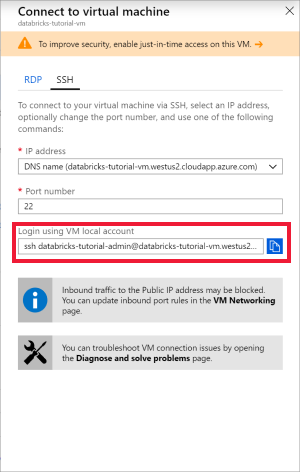
Voer de opdracht in uw Ubuntu-terminal in en voer het beheerderswachtwoord in dat u hebt gemaakt tijdens het configureren van de virtuele machine.
Gebruik de volgende opdracht om Docker te installeren op de virtuele machine.
sudo apt-get install docker.ioControleer de installatie van Docker met de volgende opdracht:
sudo docker --versionInstalleer de installatiekopieën.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestControleer de afbeeldingen.
sudo docker imagesVoer de container uit vanuit de installatiekopieën.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestControleer of de container wordt uitgevoerd.
sudo docker ps -a
Een SQL-database maken
Open SQL Server Management Studio en maak verbinding met de server met behulp van de servernaam en SQL-verificatie. De gebruikersnaam voor aanmelding is SA en het wachtwoord is het wachtwoord dat is ingesteld in de Docker-opdracht. Het wachtwoord in de voorbeeldopdracht is
Password1234.
Zodra u verbinding hebt gemaakt, selecteert u Nieuwe query en voert u het volgende codefragment in om een database en een tabel te maken en enkele records in de tabel in te voegen.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO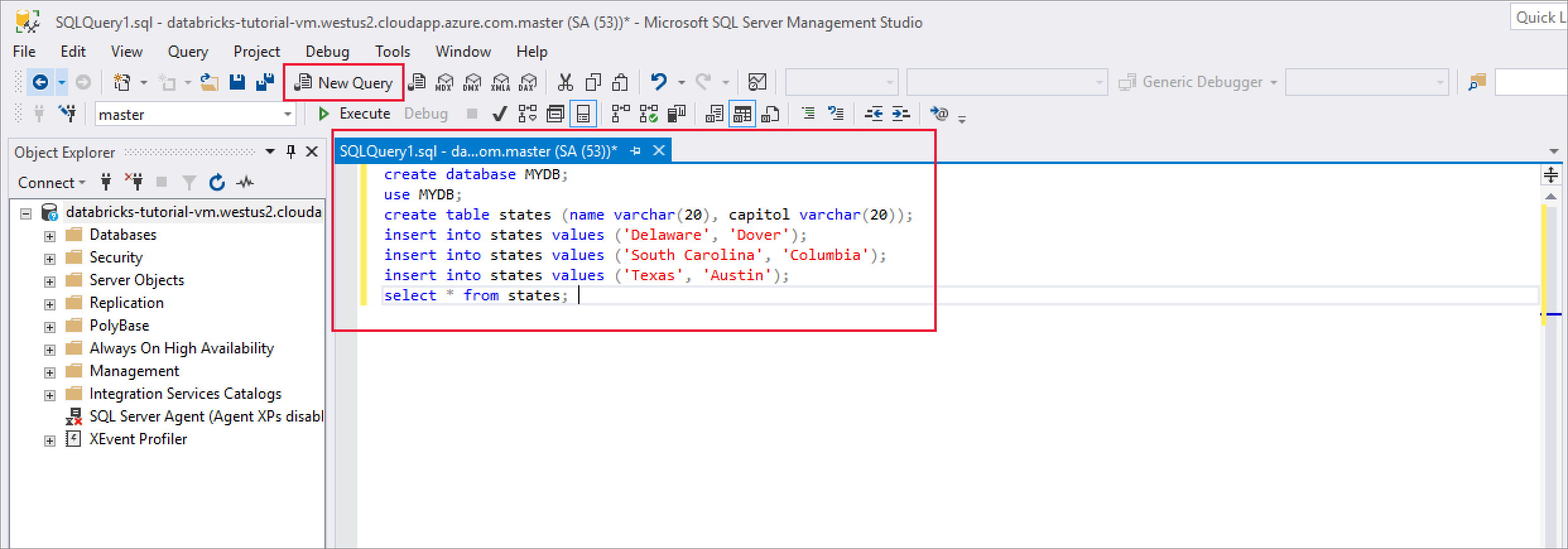
Query's uitvoeren op SQL Server van Azure Databricks
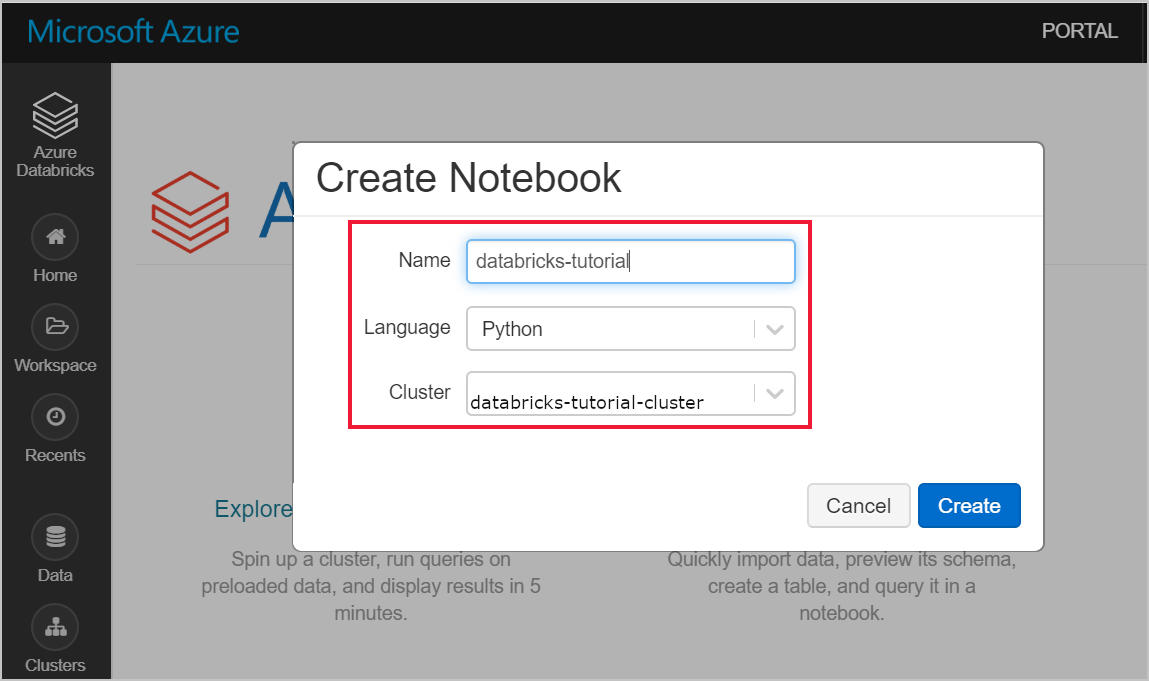
Navigeer naar uw Azure Databricks-werkruimte en controleer of u een cluster hebt gemaakt als onderdeel van de vereisten. Selecteer vervolgens Een notitieblok maken. Geef het notitieblok een naam, selecteer Python als taal en selecteer het cluster dat u hebt gemaakt.
Gebruik de volgende opdracht om het interne IP-adres van de SQL Server virtuele machine te pingen. Deze ping zou moeten lukken. Zo niet, controleert u of de container wordt uitgevoerd en controleert u de configuratie van de netwerkbeveiligingsgroep (NSG).
%sh ping 10.179.64.4U kunt ook de opdracht nslookup gebruiken om te controleren.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comZodra u de SQL Server hebt gepingd, kunt u een query uitvoeren op de database en tabellen. Voer de volgende Python-code uit:
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Resources opschonen
Verwijder de resourcegroep, de Azure Databricks-werkruimte en alle gerelateerde resources wanneer u deze niet meer nodig hebt. Als u de taak verwijdert, voorkomt u onnodige facturering. Als u van plan bent om de Azure Databricks-werkruimte in de toekomst te gebruiken, kunt u het cluster stoppen en later opnieuw opstarten. Als u deze Azure Databricks-werkruimte niet meer gaat gebruiken, verwijdert u alle resources die u in deze zelfstudie hebt gemaakt met behulp van de volgende stappen:
Klik in het linkermenu in de Azure Portal op Resourcegroepen en klik vervolgens op de naam van de resourcegroep die u hebt gemaakt.
Selecteer verwijderen op de pagina van de resourcegroep, typ de naam van de resource die u wilt verwijderen in het tekstvak en selecteer vervolgens opnieuw Verwijderen .
Volgende stappen
Ga naar het volgende artikel voor meer informatie over het extraheren, transformeren en laden van gegevens met behulp van Azure Databricks.