De replicatie van schemawijzigingen in Azure SQL Data Sync automatiseren
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
Met SQL Data Sync kunnen gebruikers gegevens synchroniseren tussen databases in Azure SQL Database en SQL Server-exemplaren in één richting of in beide richtingen. Een van de huidige beperkingen van SQL Data Sync is een gebrek aan ondersteuning voor de replicatie van schemawijzigingen. Telkens wanneer u het tabelschema wijzigt, moet u de wijzigingen handmatig toepassen op alle eindpunten, inclusief de hub en alle leden, en vervolgens het synchronisatieschema bijwerken.
In dit artikel wordt een oplossing geïntroduceerd om schemawijzigingen automatisch te repliceren naar alle SQL Data Sync-eindpunten.
- Deze oplossing maakt gebruik van een DDL-trigger om schemawijzigingen bij te houden.
- Met de trigger worden de opdrachten voor schemawijziging ingevoegd in een traceringstabel.
- Deze traceringstabel wordt gesynchroniseerd met alle eindpunten met behulp van de Data Sync-service.
- DML-triggers na invoeging worden gebruikt om de schemawijzigingen op de andere eindpunten toe te passen.
In dit artikel wordt ALTER TABLE gebruikt als voorbeeld van een schemawijziging, maar deze oplossing werkt ook voor andere typen schemawijzigingen.
Belangrijk
We raden u aan dit artikel zorgvuldig te lezen, met name de secties over probleemoplossing en andere overwegingen, voordat u begint met het implementeren van automatische schemawijzigingsreplicatie in uw synchronisatieomgeving. U wordt ook aangeraden synchronisatiegegevens te lezen in meerdere cloud- en on-premises databases met SQL Data Sync. Sommige databasebewerkingen kunnen de oplossing die in dit artikel wordt beschreven, verbreken. Aanvullende domeinkennis van SQL Server en Transact-SQL is mogelijk vereist om deze problemen op te lossen.
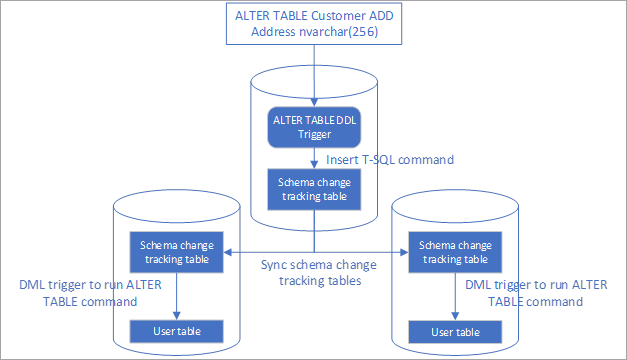
Automatische schemawijzigingsreplicatie instellen
Een tabel maken om schemawijzigingen bij te houden
Maak een tabel om schemawijzigingen in alle databases in de synchronisatiegroep bij te houden:
CREATE TABLE SchemaChanges (
ID bigint IDENTITY(1,1) PRIMARY KEY,
SqlStmt nvarchar(max),
[Description] nvarchar(max)
)
Deze tabel heeft een identiteitskolom om de volgorde van schemawijzigingen bij te houden. U kunt indien nodig meer velden toevoegen om meer informatie te registreren.
Een tabel maken om de geschiedenis van schemawijzigingen bij te houden
Maak op alle eindpunten een tabel om de id van de laatst toegepaste opdracht voor schemawijziging bij te houden.
CREATE TABLE SchemaChangeHistory (
LastAppliedId bigint PRIMARY KEY
)
GO
INSERT INTO SchemaChangeHistory VALUES (0)
Een ALTER TABLE DDL-trigger maken in de database waarin schemawijzigingen worden aangebracht
Maak een DDL-trigger voor ALTER TABLE-bewerkingen. U hoeft deze trigger alleen te maken in de database waarin schemawijzigingen worden aangebracht. Om conflicten te voorkomen, staat u alleen schemawijzigingen toe in één database in een synchronisatiegroep.
CREATE TRIGGER AlterTableDDLTrigger
ON DATABASE
FOR ALTER_TABLE
AS
-- You can add your own logic to filter ALTER TABLE commands instead of replicating all of them.
IF NOT (EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]', 'nvarchar(512)') like 'DataSync')
INSERT INTO SchemaChanges (SqlStmt, Description)
VALUES (EVENTDATA().value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]', 'nvarchar(max)'), 'From DDL trigger')
Met de trigger wordt een record ingevoegd in de schematabel voor wijzigingen bijhouden voor elke opdracht ALTER TABLE. In dit voorbeeld wordt een filter toegevoegd om te voorkomen dat schemawijzigingen die zijn aangebracht onder schema DataSync, worden gerepliceerd, omdat deze waarschijnlijk worden gemaakt door de Data Sync-service. Voeg meer filters toe als u alleen bepaalde typen schemawijzigingen wilt repliceren.
U kunt ook meer triggers toevoegen om andere typen schemawijzigingen te repliceren. Maak bijvoorbeeld CREATE_PROCEDURE, ALTER_PROCEDURE en DROP_PROCEDURE triggers om wijzigingen in opgeslagen procedures te repliceren.
Een trigger maken op andere eindpunten om schemawijzigingen toe te passen tijdens het invoegen
Met deze trigger wordt de opdracht voor schemawijziging uitgevoerd wanneer deze wordt gesynchroniseerd met andere eindpunten. U moet deze trigger maken op alle eindpunten, behalve de trigger waarin schemawijzigingen worden aangebracht (dat wil gezegd, in de database waarin de DDL-trigger AlterTableDDLTrigger in de vorige stap wordt gemaakt).
CREATE TRIGGER SchemaChangesTrigger
ON SchemaChanges
AFTER INSERT
AS
DECLARE @lastAppliedId bigint
DECLARE @id bigint
DECLARE @sqlStmt nvarchar(max)
SELECT TOP 1 @lastAppliedId=LastAppliedId FROM SchemaChangeHistory
SELECT TOP 1 @id = id, @SqlStmt = SqlStmt FROM SchemaChanges WHERE id > @lastAppliedId ORDER BY id
IF (@id = @lastAppliedId + 1)
BEGIN
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
WHILE (1 = 1)
BEGIN
SET @id = @id + 1
IF exists (SELECT id FROM SchemaChanges WHERE ID = @id)
BEGIN
SELECT @sqlStmt = SqlStmt FROM SchemaChanges WHERE ID = @id
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
END
ELSE
BREAK;
END
END
Deze trigger wordt uitgevoerd na de invoeging en controleert of de huidige opdracht volgende moet worden uitgevoerd. De codelogica zorgt ervoor dat er geen schemawijzigingsinstructie wordt overgeslagen en dat alle wijzigingen worden toegepast, zelfs als de invoeging niet in orde is.
De schematabel voor het bijhouden van wijzigingen synchroniseren met alle eindpunten
U kunt de schematabel voor wijzigingen bijhouden synchroniseren met alle eindpunten met behulp van de bestaande synchronisatiegroep of een nieuwe synchronisatiegroep. Zorg ervoor dat de wijzigingen in de traceringstabel kunnen worden gesynchroniseerd met alle eindpunten, met name wanneer u eenrichtingssynchronisatie gebruikt.
Synchroniseer de geschiedenistabel voor schemawijziging niet, omdat die tabel de status van verschillende eindpunten behoudt.
De schemawijzigingen in een synchronisatiegroep toepassen
Alleen schemawijzigingen die zijn aangebracht in de database waarin de DDL-trigger wordt gemaakt, worden gerepliceerd. Schemawijzigingen in andere databases worden niet gerepliceerd.
Nadat de schemawijzigingen zijn gerepliceerd naar alle eindpunten, moet u ook extra stappen uitvoeren om het synchronisatieschema bij te werken om de nieuwe kolommen te starten of te stoppen.
Nieuwe kolommen toevoegen
Breng de schemawijziging aan.
Vermijd gegevenswijziging waarbij de nieuwe kolommen betrokken zijn totdat u de stap hebt voltooid waarmee de trigger wordt gemaakt.
Wacht totdat de schemawijzigingen worden toegepast op alle eindpunten.
Vernieuw het databaseschema en voeg de nieuwe kolom toe aan het synchronisatieschema.
Gegevens in de nieuwe kolom worden gesynchroniseerd tijdens de volgende synchronisatiebewerking.
Kolommen verwijderen
Verwijder de kolommen uit het synchronisatieschema. Data Sync stopt met het synchroniseren van gegevens in deze kolommen.
Breng de schemawijziging aan.
Vernieuw het databaseschema.
Gegevenstypen bijwerken
Breng de schemawijziging aan.
Wacht totdat de schemawijzigingen worden toegepast op alle eindpunten.
Vernieuw het databaseschema.
Als de nieuwe en oude gegevenstypen niet volledig compatibel zijn, bijvoorbeeld als u overgaat van
int-bigintsynchronisatie kan mislukken voordat de stappen voor het maken van de triggers zijn voltooid. Synchroniseren slaagt na een nieuwe poging.
De naam van kolommen of tabellen wijzigen
Als u de naam van kolommen of tabellen wijzigt, werkt Data Sync niet meer. Maak een nieuwe tabel of kolom, vul de gegevens in en verwijder de oude tabel of kolom in plaats van de naam te wijzigen.
Andere typen schemawijzigingen
Voor andere typen schemawijzigingen, bijvoorbeeld het maken van opgeslagen procedures of het verwijderen van een index, is het bijwerken van het synchronisatieschema niet vereist.
Problemen met automatische replicatie van schemawijziging oplossen
De replicatielogica die in dit artikel wordt beschreven, werkt in sommige situaties niet meer, bijvoorbeeld als u een schemawijziging hebt aangebracht in een on-premises database die niet wordt ondersteund in Azure SQL Database. In dat geval mislukt het synchroniseren van de schematabel voor het bijhouden van wijzigingen. U moet dit probleem handmatig oplossen:
Schakel de DDL-trigger uit en vermijd verdere schemawijzigingen totdat het probleem is opgelost.
Schakel in de eindpuntdatabase waar het probleem zich voordoet de trigger AFTER INSERT uit op het eindpunt waar de schemawijziging niet kan worden aangebracht. Met deze actie kan de opdracht schemawijziging worden gesynchroniseerd.
Activeer synchronisatie om de schematabel voor het bijhouden van wijzigingen te synchroniseren.
In de eindpuntdatabase waar het probleem zich voordoet, voert u een query uit op de schemawijzigingsgeschiedenistabel om de id op te halen van de laatste opdracht voor schemawijziging.
Voer een query uit op de schematabel voor wijzigingen bijhouden om alle opdrachten weer te geven met een id die groter is dan de id-waarde die u in de vorige stap hebt opgehaald.
a. Negeer deze opdrachten die niet kunnen worden uitgevoerd in de eindpuntdatabase. U moet omgaan met de inconsistentie van het schema. Wijzig het oorspronkelijke schema als de inconsistentie van invloed is op uw toepassing.
b. Pas deze opdrachten handmatig toe die moeten worden toegepast.
Werk de geschiedenistabel voor schemawijziging bij en stel de laatst toegepaste id in op de juiste waarde.
Controleer of het schema up-to-date is.
Schakel de TRIGGER AFTER INSERT opnieuw in, uitgeschakeld in de tweede stap.
Schakel de DDL-trigger in de eerste stap opnieuw in.
Als u de records in de schematabel voor wijzigingen bijhouden wilt opschonen, gebruikt u DELETE in plaats van TRUNCATE. Wijzig de identiteitkolom nooit in de tabel voor het bijhouden van schemawijziging met behulp van DBCC CHECKIDENT. U kunt nieuwe schemawijzigingstabellen maken en de tabelnaam in de DDL-trigger bijwerken als het opnieuw verzenden is vereist.
Andere overwegingen
Databasegebruikers die de hub- en liddatabases configureren, moeten voldoende machtigingen hebben om de opdrachten voor schemawijziging uit te voeren.
U kunt meer filters toevoegen in de DDL-trigger om alleen schemawijziging in geselecteerde tabellen of bewerkingen te repliceren.
U kunt alleen schemawijzigingen aanbrengen in de database waarin de DDL-trigger wordt gemaakt.
Als u een wijziging aanbrengt in een SQL Server-database, moet u ervoor zorgen dat de schemawijziging wordt ondersteund in Azure SQL Database.
Als schemawijzigingen worden aangebracht in andere databases dan de database waarin de DDL-trigger wordt gemaakt, worden de wijzigingen niet gerepliceerd. U kunt dit probleem voorkomen door DDL-triggers te maken om wijzigingen op andere eindpunten te blokkeren.
Als u het schema van de schematabel voor wijzigingen bijhouden wilt wijzigen, schakelt u de DDL-trigger uit voordat u de wijziging aanbrengt en past u de wijziging vervolgens handmatig toe op alle eindpunten. Het bijwerken van het schema in een AFTER INSERT-trigger in dezelfde tabel werkt niet.
Wijzig het formaat van de identiteitskolom niet met DBCC CHECKIDENT.
Gebruik TRUNCATE niet om gegevens op te schonen in de schematabel voor wijzigingen bijhouden.
Volgende stappen
Zie de volgende onderwerpen voor meer informatie over SQL Data Sync:
- Overzicht: Gegevens synchroniseren tussen meerdere cloud- en on-premises databases met SQL Data Sync
- Data Sync instellen
- In de portal - Zelfstudie: SQL Data Sync instellen om gegevens te synchroniseren tussen Azure SQL Database en SQL Server
- Met PowerShell
- Data Sync-agent: Data Sync-agent voor Azure SQL Data Sync
- Best practices: Best practices voor Azure SQL Data Sync
- Bewaken: SQL Data Sync bewaken met Azure Monitor-logboeken
- Problemen oplossen: Problemen met Azure SQL Data Sync oplossen
- Het synchronisatieschema bijwerken
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor