Aanbevolen procedures voor Azure Machine Learning voor bedrijfsbeveiliging
In dit artikel worden aanbevolen beveiligingsprocedures beschreven voor het plannen of beheren van een beveiligde Azure Machine Learning-implementatie. Best practices zijn afkomstig van Microsoft en de klantervaring met Azure Machine Learning. Elke richtlijn legt de praktijk en de logica ervan uit. Het artikel bevat ook koppelingen naar procedures en referentiedocumentatie.
Aanbevolen netwerkbeveiligingsarchitectuur (beheerd netwerk)
De aanbevolen architectuur voor machine learning-netwerkbeveiliging is een beheerd virtueel netwerk. Een door Azure Machine Learning beheerd virtueel netwerk beveiligt de werkruimte, gekoppelde Azure-resources en alle beheerde rekenresources. Het vereenvoudigt de configuratie en het beheer van netwerkbeveiliging door vereiste uitvoer vooraf te configureren en automatisch beheerde resources binnen het netwerk te maken. U kunt privé-eindpunten gebruiken om Azure-services toegang te geven tot het netwerk en u kunt eventueel uitgaande regels definiëren om het netwerk toegang te geven tot internet.
Het beheerde virtuele netwerk heeft twee modi waarvoor het kan worden geconfigureerd:
Uitgaand internet toestaan- Deze modus staat uitgaande communicatie toe met resources die zich op internet bevinden, zoals de openbare PyPi- of Anaconda-pakketopslagplaatsen.

Alleen goedgekeurd uitgaand verkeer toestaan. In deze modus is alleen de minimale uitgaande communicatie toegestaan die is vereist voor de werkruimte. Deze modus wordt aanbevolen voor werkruimten die moeten worden geïsoleerd van internet. Of waarbij uitgaande toegang alleen is toegestaan voor specifieke resources via service-eindpunten, servicetags of volledig gekwalificeerde domeinnamen.

Zie Isolatie van beheerde virtuele netwerken voor meer informatie.
Aanbevolen architectuur voor netwerkbeveiliging (Azure Virtual Network)
Als u een beheerd virtueel netwerk niet kunt gebruiken vanwege uw bedrijfsvereisten, kunt u een virtueel Azure-netwerk gebruiken met de volgende subnetten:
- Training bevat rekenresources die worden gebruikt voor training, zoals machine learning-rekeninstanties of rekenclusters.
- Scoren bevat rekenresources die worden gebruikt voor scoren, zoals Azure Kubernetes Service (AKS).
- Firewall bevat de firewall waarmee verkeer van en naar het openbare internet, zoals Azure Firewall, is toegestaan.
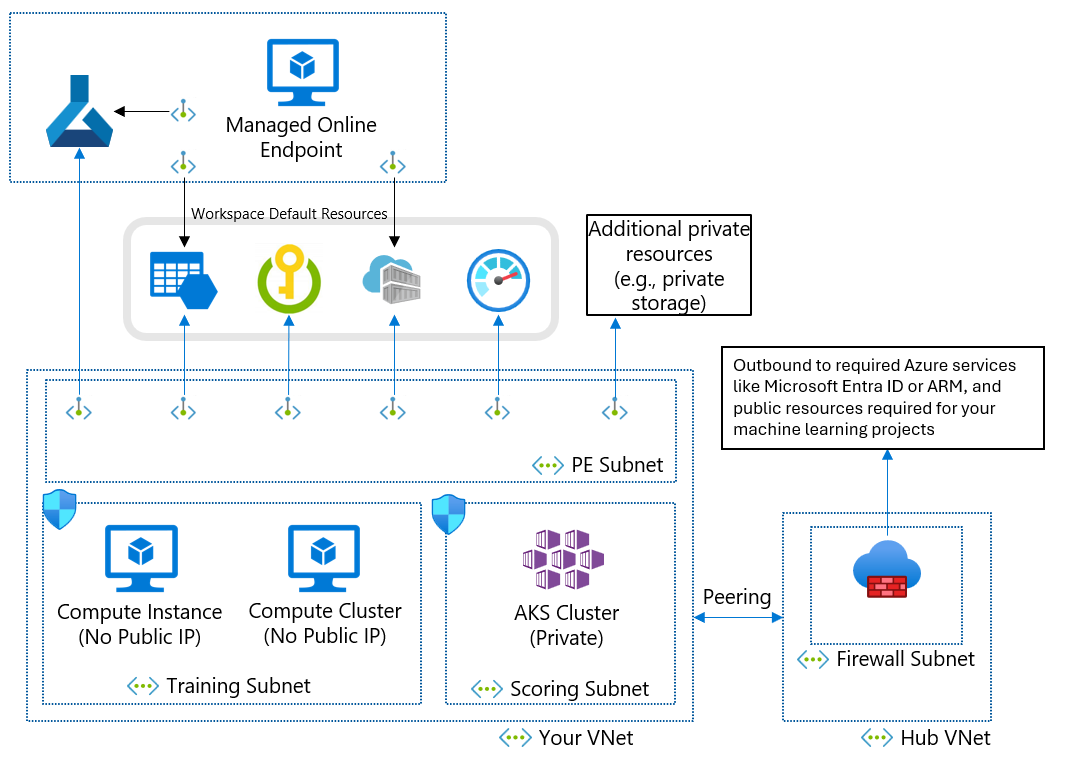
Het virtuele netwerk bevat ook een privé-eindpunt voor uw machine learning-werkruimte en de volgende afhankelijke services:
- Azure Storage-account
- Azure Key Vault
- Azure Container Registry
Uitgaande communicatie van het virtuele netwerk moet de volgende Microsoft-services kunnen bereiken:
- Machinelearning
- Microsoft Entra ID
- Azure Container Registry en specifieke registers die Microsoft onderhoudt
- Azure Front Door
- Azure Resource Manager
- Azure Storage
Externe clients maken verbinding met het virtuele netwerk met behulp van Azure ExpressRoute of een VPN-verbinding (virtual private network).
Ontwerp van virtueel netwerk en privé-eindpunt
Houd bij het ontwerpen van een virtueel Azure-netwerk, subnetten en privé-eindpunten rekening met de volgende vereisten:
In het algemeen maakt u afzonderlijke subnetten voor training en score en gebruikt u het trainingssubnet voor alle privé-eindpunten.
Voor IP-adressering hebben rekeninstanties elk één privé-IP nodig. Rekenclusters hebben één privé-IP per knooppunt nodig. AKS-clusters hebben veel privé-IP-adressen nodig, zoals beschreven in IP-adressering plannen voor uw AKS-cluster. Een afzonderlijk subnet voor ten minste AKS helpt uitputting van IP-adressen te voorkomen.
De rekenresources in de trainings- en scoresubnetten moeten toegang hebben tot het opslagaccount, de sleutelkluis en het containerregister. Maak privé-eindpunten voor het opslagaccount, de sleutelkluis en het containerregister.
Standaardopslag voor machine learning-werkruimten heeft twee privé-eindpunten nodig, één voor Azure Blob Storage en een andere voor Azure File Storage.
Als u Azure Machine Learning-studio gebruikt, moeten de privé-eindpunten voor werkruimten en opslag zich in hetzelfde virtuele netwerk bevinden.
Als u meerdere werkruimten hebt, gebruikt u een virtueel netwerk voor elke werkruimte om een expliciete netwerkgrens tussen werkruimten te maken.
Privé-IP-adressen gebruiken
Privé-IP-adressen minimaliseren de blootstelling van uw Azure-resources aan internet. Machine learning maakt gebruik van veel Azure-resources en het privé-eindpunt van de machine learning-werkruimte is niet voldoende voor end-to-end privé-IP-adressen. In de volgende tabel ziet u de belangrijkste resources die machine learning gebruikt en hoe u privé-IP-adressen voor de resources inschakelt. Rekeninstanties en rekenclusters zijn de enige resources die geen privé-IP-functie hebben.
| Resources | Privé-IP-oplossing | Documentatie |
|---|---|---|
| Werkplek | Privé-eindpunt | Een privé-eindpunt configureren voor een Azure Machine Learning werkruimte |
| Register | Privé-eindpunt | Netwerkisolatie met Azure Machine Learning-registers |
| Gekoppelde resources | ||
| Storage | Privé-eindpunt | Azure Storage-accounts beveiligen met service-eindpunten |
| Key Vault | Privé-eindpunt | Azure Key Vault beveiligen |
| Container Registry | Privé-eindpunt | Azure Container Registry inschakelen |
| Trainingsmateriaal | ||
| Rekenproces | Privé-IP (geen openbaar IP-adres) | Beveiligde trainingsomgevingen |
| Rekencluster | Privé-IP (geen openbaar IP-adres) | Beveiligde trainingsomgevingen |
| Hostingbronnen | ||
| Beheerd online-eindpunt | Privé-eindpunt | Netwerkisolatie met beheerde online-eindpunten |
| Online-eindpunt (Kubernetes) | Privé-eindpunt | Online-eindpunten van Azure Kubernetes Service beveiligen |
| Batch-eindpunten | Privé-IP (overgenomen van rekencluster) | Netwerkisolatie in batch-eindpunten |
Binnenkomend en uitgaand verkeer van virtueel netwerk beheren
Gebruik een firewall of Azure-netwerkbeveiligingsgroep (NSG) om inkomend en uitgaand verkeer van een virtueel netwerk te beheren. Zie Inkomend en uitgaand netwerkverkeer configureren voor meer informatie over binnenkomende en uitgaande vereisten. Zie De netwerkverkeersstroom in een beveiligde werkruimte voor meer informatie over verkeersstromen tussen onderdelen.
Toegang tot uw werkruimte garanderen
Voer de volgende stappen uit om ervoor te zorgen dat uw privé-eindpunt toegang heeft tot uw machine learning-werkruimte:
Zorg ervoor dat u toegang hebt tot uw virtuele netwerk met behulp van een VPN-verbinding, ExpressRoute of jump box virtual machine (VM) met Toegang tot Azure Bastion. De openbare gebruiker heeft geen toegang tot de machine learning-werkruimte met het privé-eindpunt, omdat deze alleen toegankelijk is vanuit uw virtuele netwerk. Zie Uw werkruimte beveiligen met virtuele netwerken voor meer informatie.
Zorg ervoor dat u de FQDN's (Fully Qualified Domain Names) van de werkruimte kunt omzetten met uw privé-IP-adres. Als u uw eigen DNS-server (Domain Name System) of een gecentraliseerde DNS-infrastructuur gebruikt, moet u een DNS-doorstuurserver configureren. Zie Uw werkruimte gebruiken met een aangepaste DNS-server voor meer informatie.
Toegangsbeheer voor werkruimten
Wanneer u besturingselementen voor machine learning-identiteiten en toegangsbeheer definieert, kunt u besturingselementen scheiden die toegang tot Azure-resources definiëren, van besturingselementen die de toegang tot gegevensassets beheren. Afhankelijk van uw use-case kunt u overwegen om selfservice, gegevensgericht of projectgericht identiteits- en toegangsbeheer te gebruiken.
Selfservicepatroon
In een selfservicepatroon kunnen gegevenswetenschappers werkruimten maken en beheren. Dit patroon is het meest geschikt voor proof-of-concept-situaties die flexibiliteit vereisen om verschillende configuraties uit te proberen. Het nadeel is dat gegevenswetenschappers de expertise nodig hebben om Azure-resources in te richten. Deze benadering is minder geschikt wanneer strikt beheer, resourcegebruik, controletraceringen en gegevenstoegang vereist zijn.
Definieer Azure-beleid om beveiligingen in te stellen voor het inrichten en gebruiken van resources, zoals toegestane clustergrootten en VM-typen.
Maak een resourcegroep voor het opslaan van de werkruimten en verdeel gegevenswetenschappers een rol Inzender in de resourcegroep.
Gegevenswetenschappers kunnen nu werkruimten maken en resources in de resourcegroep op een selfservice manier koppelen.
Als u toegang wilt krijgen tot gegevensopslag, maakt u door de gebruiker toegewezen beheerde identiteiten en verleent u de identiteiten leestoegangsrollen in de opslag.
Wanneer gegevenswetenschappers rekenresources maken, kunnen ze de beheerde identiteiten toewijzen aan de rekeninstanties om toegang te krijgen tot gegevens.
Zie Verificatie voor analyses op cloudschaal voor aanbevolen procedures.
Gegevensgericht patroon
In een gegevensgericht patroon behoort de werkruimte tot één data scientist die mogelijk aan meerdere projecten werkt. Het voordeel van deze aanpak is dat de data scientist code- of trainingspijplijnen in projecten opnieuw kan gebruiken. Zolang de werkruimte beperkt is tot één gebruiker, kan gegevenstoegang worden teruggezet naar die gebruiker bij het controleren van opslaglogboeken.
Het nadeel is dat gegevenstoegang niet per project is gecompartimentaliseerd of beperkt, en elke gebruiker die aan de werkruimte is toegevoegd, toegang heeft tot dezelfde assets.
Maak de werkruimte.
Rekenresources maken waarvoor door het systeem toegewezen beheerde identiteiten zijn ingeschakeld.
Wanneer een data scientist toegang nodig heeft tot de gegevens voor een bepaald project, verleent u de door compute beheerde identiteit leestoegang tot de gegevens.
Verdeel de beheerde identiteit voor berekeningen toegang tot andere vereiste resources, zoals een containerregister met aangepaste Docker-installatiekopieën voor training.
Ververleent de rol beheerde identiteit van de werkruimte ook leestoegang tot de gegevens om een voorbeeld van gegevens in te schakelen.
Verdeel de data scientist toegang tot de werkruimte.
De data scientist kan nu gegevensarchieven maken voor toegang tot gegevens die vereist zijn voor projecten en trainingsuitvoeringen indienen die gebruikmaken van de gegevens.
Maak desgewenst een Microsoft Entra-beveiligingsgroep en verdeel deze leestoegang tot gegevens en voeg vervolgens beheerde identiteiten toe aan de beveiligingsgroep. Deze aanpak vermindert het aantal directe roltoewijzingen voor resources om te voorkomen dat de abonnementslimiet voor roltoewijzingen wordt bereikt.
Projectgericht patroon
Een projectgericht patroon maakt een machine learning-werkruimte voor een specifiek project en veel gegevenswetenschappers werken samen binnen dezelfde werkruimte. Gegevenstoegang is beperkt tot het specifieke project, waardoor de aanpak geschikt is voor het werken met gevoelige gegevens. Het is ook eenvoudig om gegevenswetenschappers toe te voegen aan of te verwijderen uit het project.
Het nadeel van deze aanpak is dat het delen van assets tussen projecten lastig kan zijn. Het is ook moeilijk om gegevenstoegang tot specifieke gebruikers te traceren tijdens controles.
De werkruimte maken
Identificeer gegevensopslagexemplaren die vereist zijn voor het project, maak een door de gebruiker toegewezen beheerde identiteit en verdeel de identiteit leestoegang tot de opslag.
U kunt desgewenst de beheerde identiteit van de werkruimte toegang verlenen tot gegevensopslag om een voorbeeld van gegevens toe te staan. U kunt deze toegang weglaten voor gevoelige gegevens die niet geschikt zijn voor preview.
Maak referentieloze gegevensarchieven voor de opslagbronnen.
Maak rekenresources in de werkruimte en wijs de beheerde identiteit toe aan de rekenresources.
Verdeel de beheerde identiteit voor berekeningen toegang tot andere vereiste resources, zoals een containerregister met aangepaste Docker-installatiekopieën voor training.
Verdeel gegevenswetenschappers die aan het project werken een rol in de werkruimte.
Met behulp van op rollen gebaseerd toegangsbeheer van Azure (RBAC) kunt u beperken dat gegevenswetenschappers nieuwe gegevensarchieven of nieuwe rekenresources met verschillende beheerde identiteiten maken. Deze procedure voorkomt dat toegang tot gegevens die niet specifiek zijn voor het project.
Als u het beheer van projectlidmaatschappen wilt vereenvoudigen, kunt u een Microsoft Entra-beveiligingsgroep maken voor projectleden en de groep toegang verlenen tot de werkruimte.
Azure Data Lake Storage met referentiepassthrough
U kunt microsoft Entra-gebruikersidentiteit gebruiken voor interactieve opslagtoegang vanuit Machine Learning Studio. Data Lake Storage waarvoor hiërarchische naamruimte is ingeschakeld, biedt een verbeterde organisatie van gegevensassets voor opslag en samenwerking. Met de hiërarchische naamruimte van Data Lake Storage kunt u gegevenstoegang opsplitsen door verschillende gebruikers toegangsbeheerlijsten (ACL) te geven tot verschillende mappen en bestanden. U kunt bijvoorbeeld alleen een subset van gebruikers toegang verlenen tot vertrouwelijke gegevens.
RBAC en aangepaste rollen
Met Azure RBAC kunt u beheren wie toegang heeft tot machine learning-resources en kunt configureren wie bewerkingen kan uitvoeren. U wilt bijvoorbeeld alleen specifieke gebruikers de rol werkruimtebeheerder verlenen voor het beheren van rekenresources.
Het toegangsbereik kan verschillen tussen omgevingen. In een productieomgeving wilt u mogelijk de mogelijkheid beperken van gebruikers om deductie-eindpunten bij te werken. In plaats daarvan kunt u die machtiging verlenen aan een geautoriseerde service-principal.
Machine learning heeft verschillende standaardrollen: eigenaar, inzender, lezer en data scientist. U kunt ook uw eigen aangepaste rollen maken, bijvoorbeeld om machtigingen te maken die overeenkomen met uw organisatiestructuur. Zie Toegang tot azure Machine Learning-werkruimte beheren voor meer informatie.
Na verloop van tijd kan de samenstelling van uw team veranderen. Als u een Microsoft Entra-groep maakt voor elke teamrol en werkruimte, kunt u een Azure RBAC-rol toewijzen aan de Microsoft Entra-groep en resourcetoegang en gebruikersgroepen afzonderlijk beheren.
Gebruikers-principals en service-principals kunnen deel uitmaken van dezelfde Microsoft Entra-groep. Wanneer u bijvoorbeeld een door de gebruiker toegewezen beheerde identiteit maakt die door Azure Data Factory wordt gebruikt om een machine learning-pijplijn te activeren, kunt u de beheerde identiteit opnemen in een ML-pijplijnexecutor Microsoft Entra-groep.
Centraal Beheer van Docker-installatiekopieën
Azure Machine Learning biedt gecureerde Docker-installatiekopieën die u kunt gebruiken voor training en implementatie. Het is echter mogelijk dat uw bedrijfsnalevingsvereisten het gebruik van installatiekopieën uit een privéopslagplaats die uw bedrijf beheert, verplicht stellen. Machine learning heeft twee manieren om een centrale opslagplaats te gebruiken:
Gebruik de installatiekopieën uit een centrale opslagplaats als basisinstallatiekopieën. Het machine learning-omgevingsbeheer installeert pakketten en maakt een Python-omgeving waarin de trainings- of deductiecode wordt uitgevoerd. Met deze methode kunt u pakketafhankelijkheden eenvoudig bijwerken zonder de basisinstallatiekopieën te wijzigen.
Gebruik de installatiekopieën als zodanig, zonder machine learning-omgevingsbeheer te gebruiken. Deze benadering biedt u een hogere mate van controle, maar vereist ook dat u de Python-omgeving zorgvuldig samenstelt als onderdeel van de installatiekopieën. U moet voldoen aan alle benodigde afhankelijkheden om de code uit te voeren. Voor nieuwe afhankelijkheden moet de installatiekopieën opnieuw worden opgebouwd.
Zie Omgevingen beheren voor meer informatie.
Gegevensversleuteling
Machine learning-data-at-rest heeft twee gegevensbronnen:
Uw opslag bevat al uw gegevens, inclusief training en getrainde modelgegevens, met uitzondering van de metagegevens. U bent verantwoordelijk voor uw opslagversleuteling.
Azure Cosmos DB bevat uw metagegevens, waaronder uitvoeringsgeschiedenisinformatie, zoals de naam van het experiment en de datum en tijd waarop het experiment wordt verzonden. In de meeste werkruimten bevindt Azure Cosmos DB zich in het Microsoft-abonnement en versleuteld door een door Microsoft beheerde sleutel.
Als u uw metagegevens wilt versleutelen met uw eigen sleutel, kunt u een werkruimte met door de klant beheerde sleutels gebruiken. Het nadeel is dat u Azure Cosmos DB in uw abonnement moet hebben en de bijbehorende kosten moet betalen. Zie Gegevensversleuteling met Azure Machine Learning voor meer informatie.
Zie Versleuteling in transit voor informatie over hoe Azure Machine Learning gegevens in transit versleutelt.
Controleren
Wanneer u machine learning-resources implementeert, stelt u besturingselementen voor logboekregistratie en controle in voor waarneembaarheid. Motivaties voor het observeren van gegevens kunnen variëren op basis van wie de gegevens bekijkt. Scenario's zijn onder andere:
Machine learning-beoefenaars of operationele teams willen de status van machine learning-pijplijnen bewaken. Deze waarnemers moeten inzicht hebben in problemen met geplande uitvoering of problemen met gegevenskwaliteit of verwachte trainingsprestaties. U kunt Azure-dashboards bouwen waarmee Azure Machine Learning-gegevens worden bewaakt of gebeurtenisgestuurde werkstromen worden gemaakt.
Capaciteitsmanagers, machine learning-beoefenaars of operationele teams willen mogelijk een dashboard maken om het reken- en quotumgebruik te observeren. Als u een implementatie met meerdere Azure Machine Learning-werkruimten wilt beheren, kunt u een centraal dashboard maken om inzicht te hebben in het quotumgebruik. Quota worden beheerd op abonnementsniveau, zodat de omgevingsbrede weergave belangrijk is om optimalisatie te stimuleren.
IT- en operations-teams kunnen diagnostische logboekregistratie instellen om toegang tot resources te controleren en gebeurtenissen in de werkruimte te wijzigen.
Overweeg om dashboards te maken die de algehele infrastructuurstatus bewaken voor machine learning en afhankelijke resources, zoals opslag. Als u bijvoorbeeld metrische gegevens van Azure Storage combineert met pijplijnuitvoeringsgegevens, kunt u de infrastructuur optimaliseren voor betere prestaties of de hoofdoorzaken van problemen detecteren.
Azure verzamelt en slaat automatisch metrische platformgegevens en activiteitenlogboeken op. U kunt de gegevens naar andere locaties routeren met behulp van een diagnostische instelling. Stel diagnostische logboekregistratie in voor een gecentraliseerde Log Analytics-werkruimte voor waarneembaarheid in verschillende werkruimte-exemplaren. Gebruik Azure Policy om logboekregistratie automatisch in te stellen voor nieuwe machine learning-werkruimten in deze centrale Log Analytics-werkruimte.
Azure Policy
U kunt het gebruik van beveiligingsfuncties in werkruimten afdwingen en controleren via Azure Policy. Aanbevelingen zijn onder andere:
- Versleuteling van aangepaste beheerde sleutels afdwingen.
- Azure Private Link en privé-eindpunten afdwingen.
- Privé-DNS-zones afdwingen.
- Schakel niet-Azure AD-verificatie uit, zoals Secure Shell (SSH).
Zie ingebouwde beleidsdefinities voor Azure Machine Learning voor meer informatie.
U kunt ook aangepaste beleidsdefinities gebruiken om de beveiliging van werkruimten op een flexibele manier te beheren.
Rekenclusters en exemplaren
De volgende overwegingen en aanbevelingen zijn van toepassing op machine learning-rekenclusters en -exemplaren.
Schijfversleuteling
De besturingssysteemschijf voor een rekenproces of rekenclusterknooppunt wordt opgeslagen in Azure Storage en versleuteld met door Microsoft beheerde sleutels. Elk knooppunt heeft ook een lokale tijdelijke schijf. De tijdelijke schijf wordt ook versleuteld met door Microsoft beheerde sleutels als de werkruimte is gemaakt met de hbi_workspace = True parameter. Zie Gegevensversleuteling met Azure Machine Learning voor meer informatie.
Beheerde identiteit
Rekenclusters ondersteunen het gebruik van beheerde identiteiten voor verificatie bij Azure-resources. Door een beheerde identiteit voor het cluster te gebruiken, kunt u verificatie naar resources uitvoeren zonder referenties in uw code weer te geven. Zie Een Azure Machine Learning-rekencluster maken voor meer informatie.
Installatiescript
U kunt een installatiescript gebruiken om de aanpassing en configuratie van rekeninstanties bij het maken te automatiseren. Als beheerder kunt u een aanpassingsscript schrijven dat moet worden gebruikt bij het maken van alle rekeninstanties in een werkruimte. U kunt Azure Policy gebruiken om het gebruik van het installatiescript af te dwingen om elk rekenproces te maken. Zie Een Azure Machine Learning-rekenproces maken en beheren voor meer informatie.
Maken namens
Als u niet wilt dat gegevenswetenschappers rekenresources inrichten, kunt u namens hen rekeninstanties maken en deze toewijzen aan de gegevenswetenschappers. Zie Een Azure Machine Learning-rekenproces maken en beheren voor meer informatie.
Werkruimte met privé-eindpunt
Gebruik rekeninstanties met een werkruimte met een privé-eindpunt. Het rekenproces weigert alle openbare toegang van buiten het virtuele netwerk. Met deze configuratie voorkomt u ook dat pakketten worden gefilterd.
Ondersteuning voor Azure Policy
Wanneer u een virtueel Azure-netwerk gebruikt, kunt u Azure Policy gebruiken om ervoor te zorgen dat elk rekencluster of exemplaar wordt gemaakt in een virtueel netwerk en het standaard-virtuele netwerk en subnet opgeeft. Het beleid is niet nodig wanneer u een beheerd virtueel netwerk gebruikt, omdat de rekenresources automatisch worden gemaakt in het beheerde virtuele netwerk.
U kunt ook een beleid gebruiken om niet-Azure AD-verificatie uit te schakelen, zoals SSH.
Volgende stappen
Meer informatie over machine learning-beveiligingsconfiguraties:
Aan de slag met een implementatie op basis van een machine learning-sjabloon:
Lees meer artikelen over architecturale overwegingen voor het implementeren van machine learning:
Meer informatie over hoe teamstructuur, omgeving of regionale beperkingen van invloed zijn op het instellen van de werkruimte.
Bekijk hoe u de rekenkosten en het budget voor teams en gebruikers beheert.
Meer informatie over Machine Learning DevOps (MLOps), waarbij gebruik wordt gemaakt van een combinatie van mensen, processen en technologie om robuuste, betrouwbare en geautomatiseerde machine learning-oplossingen te leveren.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor