Een aangepast afbeeldingsanalysemodel maken (preview)
Met afbeeldingsanalyse 4.0 kunt u een aangepast model trainen met behulp van uw eigen trainingsafbeeldingen. Door uw afbeeldingen handmatig te labelen, kunt u een model trainen om aangepaste tags toe te passen op de afbeeldingen (afbeeldingsclassificatie) of aangepaste objecten (objectdetectie) te detecteren. Afbeeldingsanalyse 4.0-modellen zijn met name effectief bij weinig-shot learning, zodat u nauwkeurige modellen met minder trainingsgegevens kunt krijgen.
Deze handleiding laat zien hoe u een aangepast afbeeldingsclassificatiemodel maakt en traint. De weinige verschillen tussen het trainen van een afbeeldingsclassificatiemodel en het objectdetectiemodel worden genoteerd.
Vereisten
- Azure-abonnement: Krijg een gratis abonnement
- Zodra u uw Azure-abonnement hebt, maakt u een Vision-resource in Azure Portal om uw sleutel en eindpunt op te halen. Als u deze handleiding volgt met Behulp van Vision Studio, moet u uw resource maken in de regio VS - oost. Nadat de app is geïmplementeerd, selecteert u Ga naar resource. Kopieer de sleutel en het eindpunt naar een tijdelijke locatie om later te gebruiken.
- Een Azure Storage-resource - Maak er een
- Een set afbeeldingen waarmee u uw classificatiemodel kunt trainen. U kunt de reeks voorbeeldafbeeldingen op GitHub gebruiken. U kunt ook uw eigen afbeeldingen gebruiken. U hebt slechts ongeveer 3-5 installatiekopieën per klasse nodig.
Notitie
We raden u niet aan aangepaste modellen te gebruiken voor bedrijfskritieke omgevingen vanwege mogelijke hoge latentie. Wanneer klanten aangepaste modellen trainen in Vision Studio, behoren deze aangepaste modellen tot de Vision-resource waaronder ze zijn getraind en kan de klant die modellen aanroepen met behulp van de Analyze Image-API . Wanneer ze deze aanroepen doen, wordt het aangepaste model in het geheugen geladen en wordt de voorspellingsinfrastructuur geïnitialiseerd. Hoewel dit gebeurt, ervaren klanten mogelijk langer dan de verwachte latentie om voorspellingsresultaten te ontvangen.
Een nieuw aangepast model maken
Ga eerst naar Vision Studio en selecteer het tabblad Afbeeldingsanalyse. Selecteer vervolgens de tegel Modellen aanpassen.
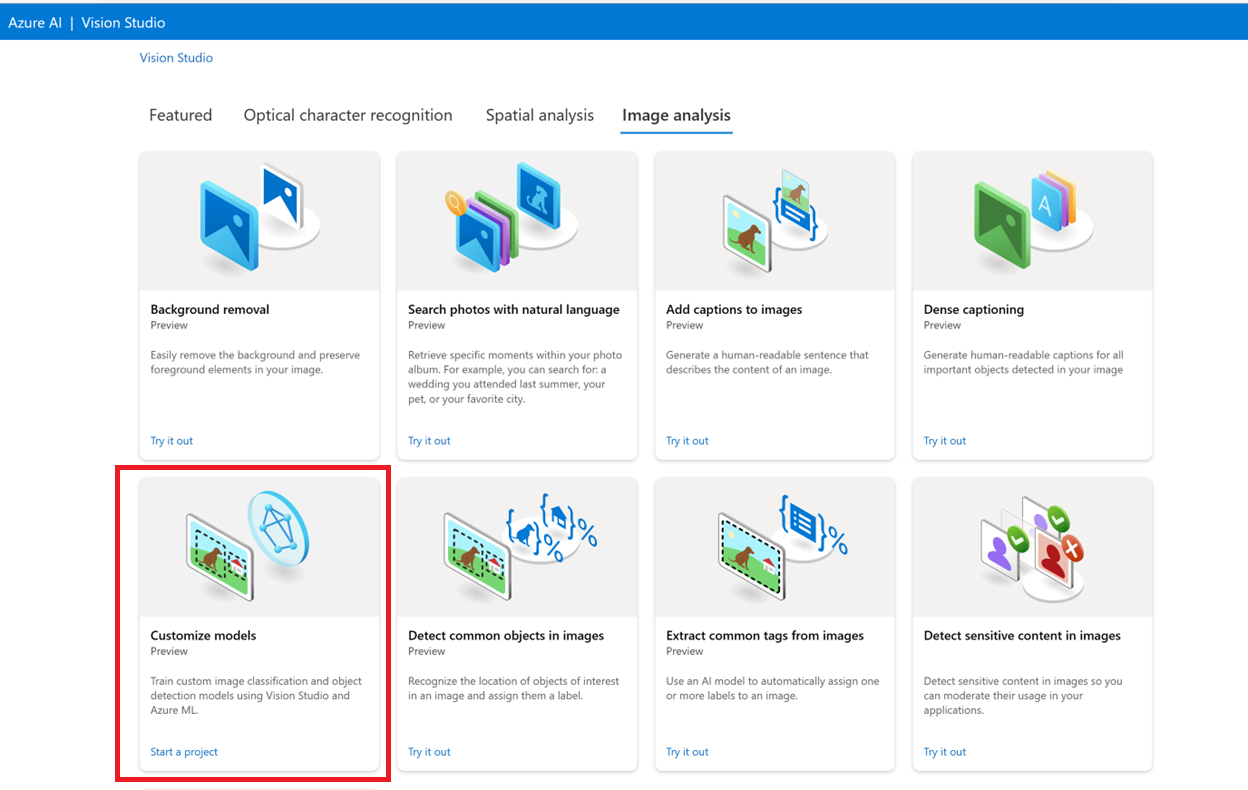
Meld u vervolgens aan met uw Azure-account en selecteer uw Vision-resource. Als u er nog geen hebt, kunt u er een maken op basis van dit scherm.
Belangrijk
Als u een aangepast model wilt trainen in Vision Studio, moet uw Azure-abonnement worden goedgekeurd voor toegang. Vraag toegang aan via dit formulier.
Trainingsafbeeldingen voorbereiden
U moet uw trainingsafbeeldingen uploaden naar een Azure Blob Storage-container. Ga naar uw opslagresource in Azure Portal en navigeer naar het tabblad Opslagbrowser . Hier kunt u een blobcontainer maken en uw afbeeldingen uploaden. Plaats ze allemaal in de hoofdmap van de container.
Een gegevensset toevoegen
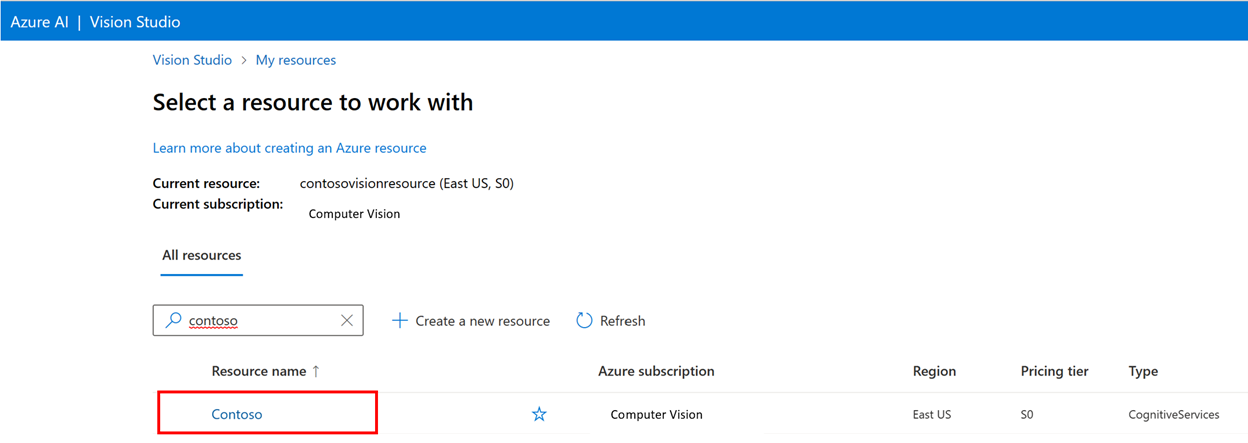
Als u een aangepast model wilt trainen, moet u het koppelen aan een gegevensset waarin u afbeeldingen en hun labelgegevens als trainingsgegevens opgeeft. Selecteer in Vision Studio het tabblad Gegevenssets om uw gegevenssets weer te geven.
Als u een nieuwe gegevensset wilt maken, selecteert u Nieuwe gegevensset toevoegen. Voer in het pop-upvenster een naam in en selecteer een gegevenssettype voor uw use-case. Afbeeldingsclassificatiemodellen passen inhoudslabels toe op de hele afbeelding, terwijl objectdetectiemodellen objectlabels toepassen op specifieke locaties in de afbeelding. Productherkenningsmodellen zijn een subcategorie van objectdetectiemodellen die zijn geoptimaliseerd voor het detecteren van retailproducten.
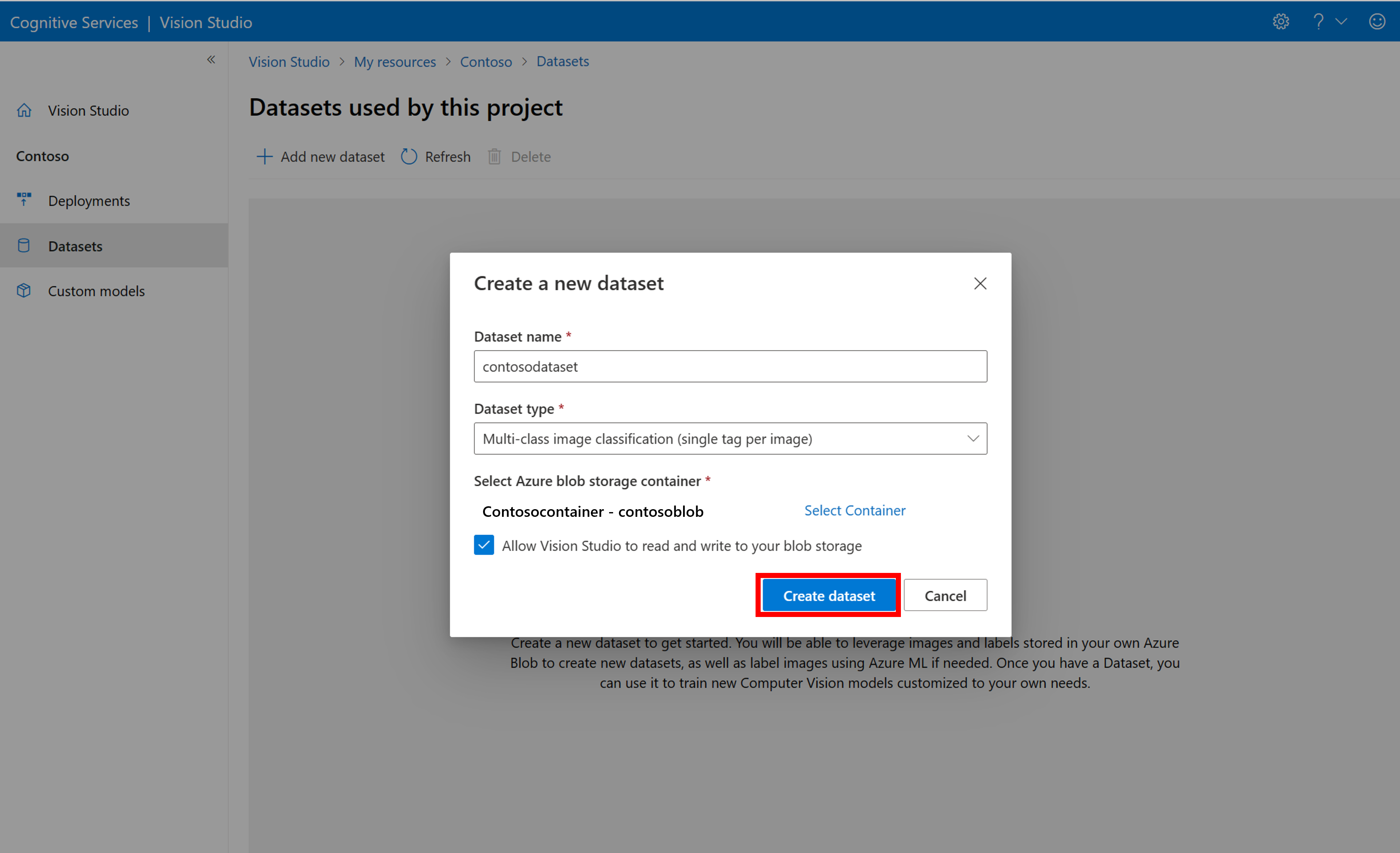
Selecteer vervolgens de container in het Azure Blob Storage-account waar u de trainingsinstallatiekopieën hebt opgeslagen. Schakel het selectievakje in om Vision Studio in staat te stellen om te lezen en schrijven naar de blobopslagcontainer. Dit is een noodzakelijke stap voor het importeren van gelabelde gegevens. Maak de gegevensset.
Een Azure Machine Learning-labelproject maken
U hebt een COCO-bestand nodig om de labelinformatie over te brengen. Een eenvoudige manier om een COCO-bestand te genereren, is door een Azure Machine Learning-project te maken dat wordt geleverd met een werkstroom voor gegevenslabels.
Selecteer een nieuw gegevenslabelproject toevoegen op de pagina met gegevenssetdetails. Geef deze een naam en selecteer Een nieuwe werkruimte maken. Hiermee opent u een nieuw azure-portaltabblad waarin u het Azure Machine Learning-project kunt maken.
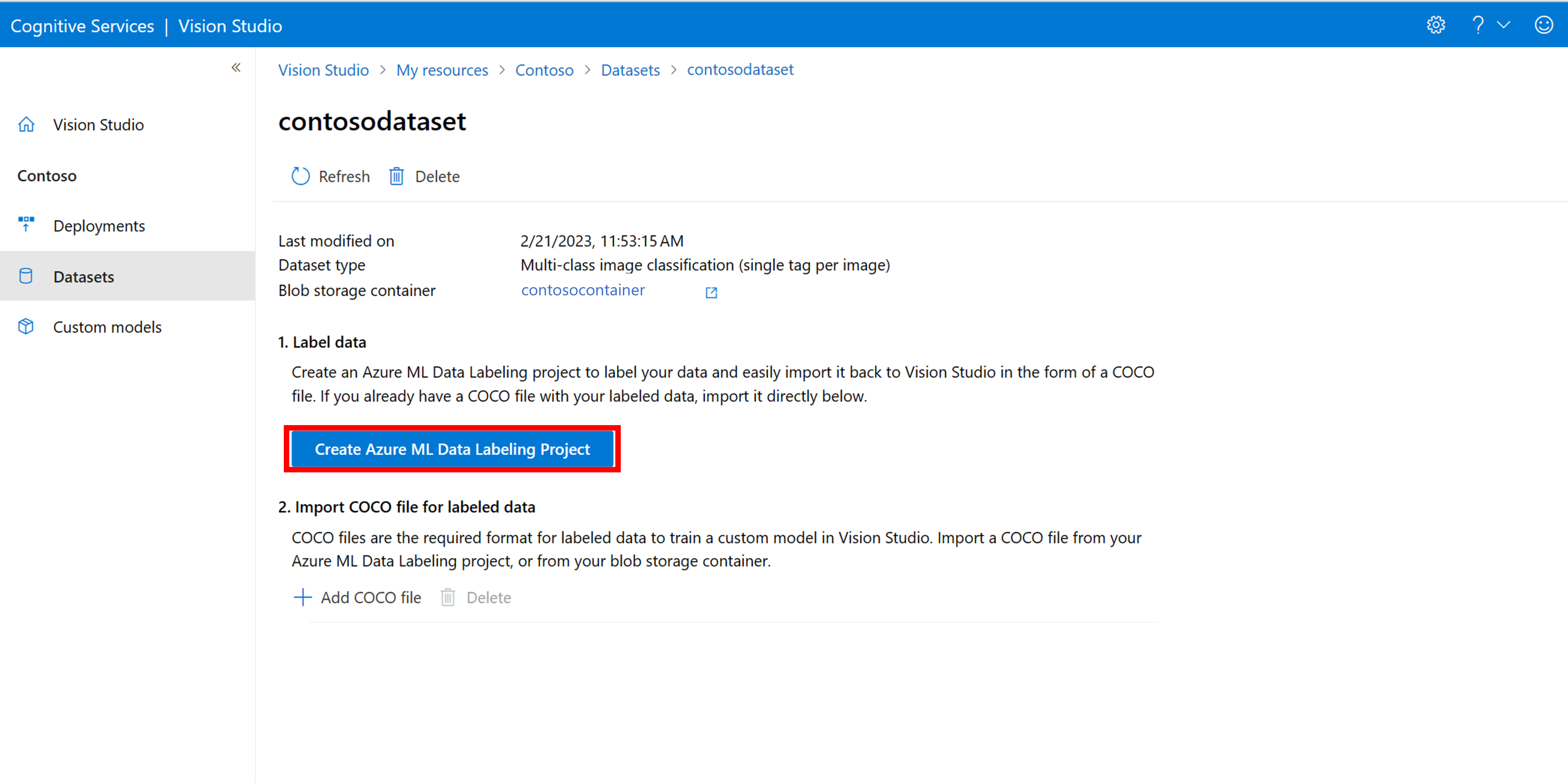
Zodra het Azure Machine Learning-project is gemaakt, gaat u terug naar het tabblad Vision Studio en selecteert u het onder Werkruimte. De Azure Machine Learning-portal wordt vervolgens geopend in een nieuw browsertabblad.
Azure Machine Learning: Labels maken
Als u wilt beginnen met labelen, volgt u de prompt Labelklassen toevoegen om labelklassen toe te voegen.
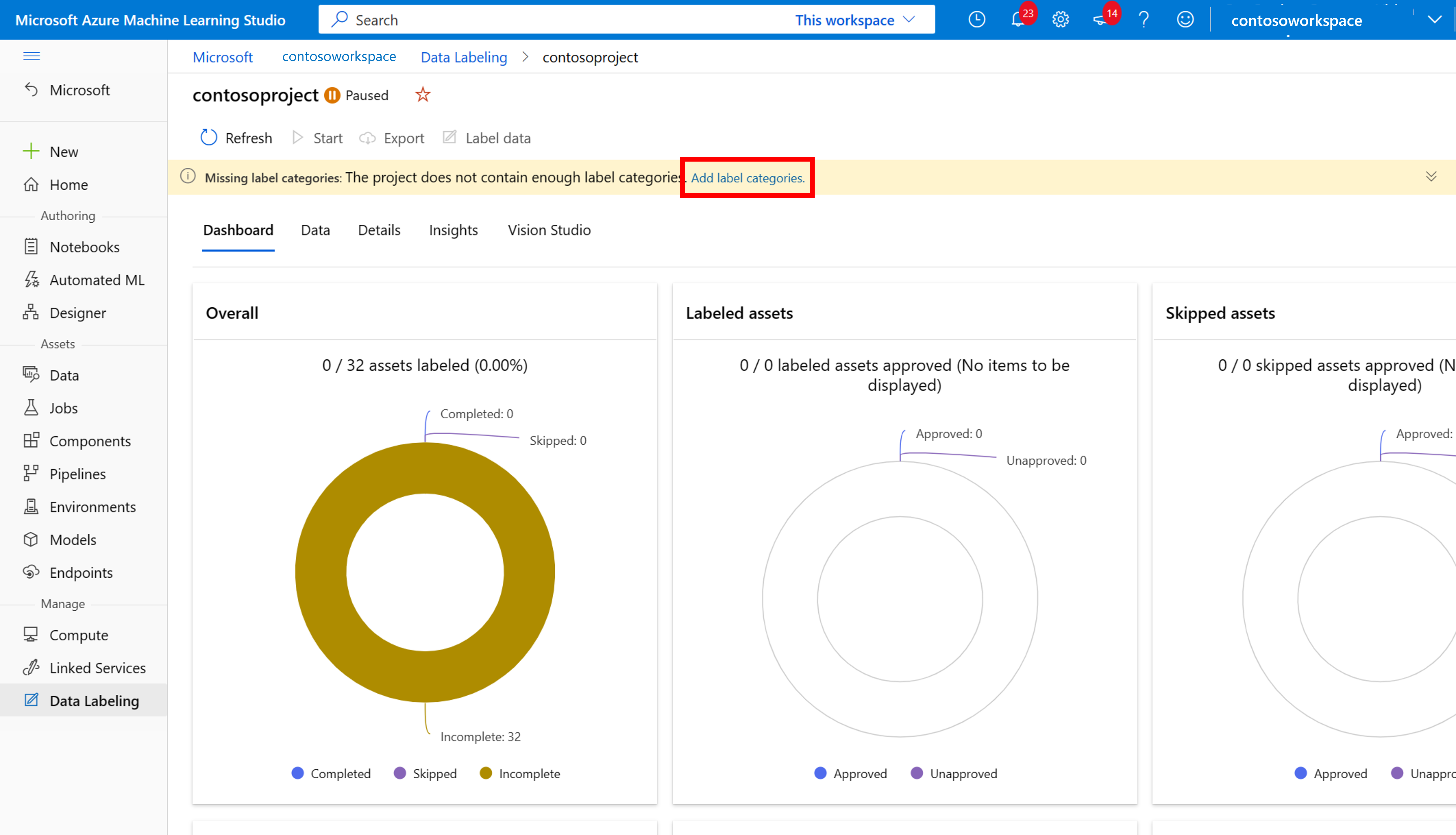
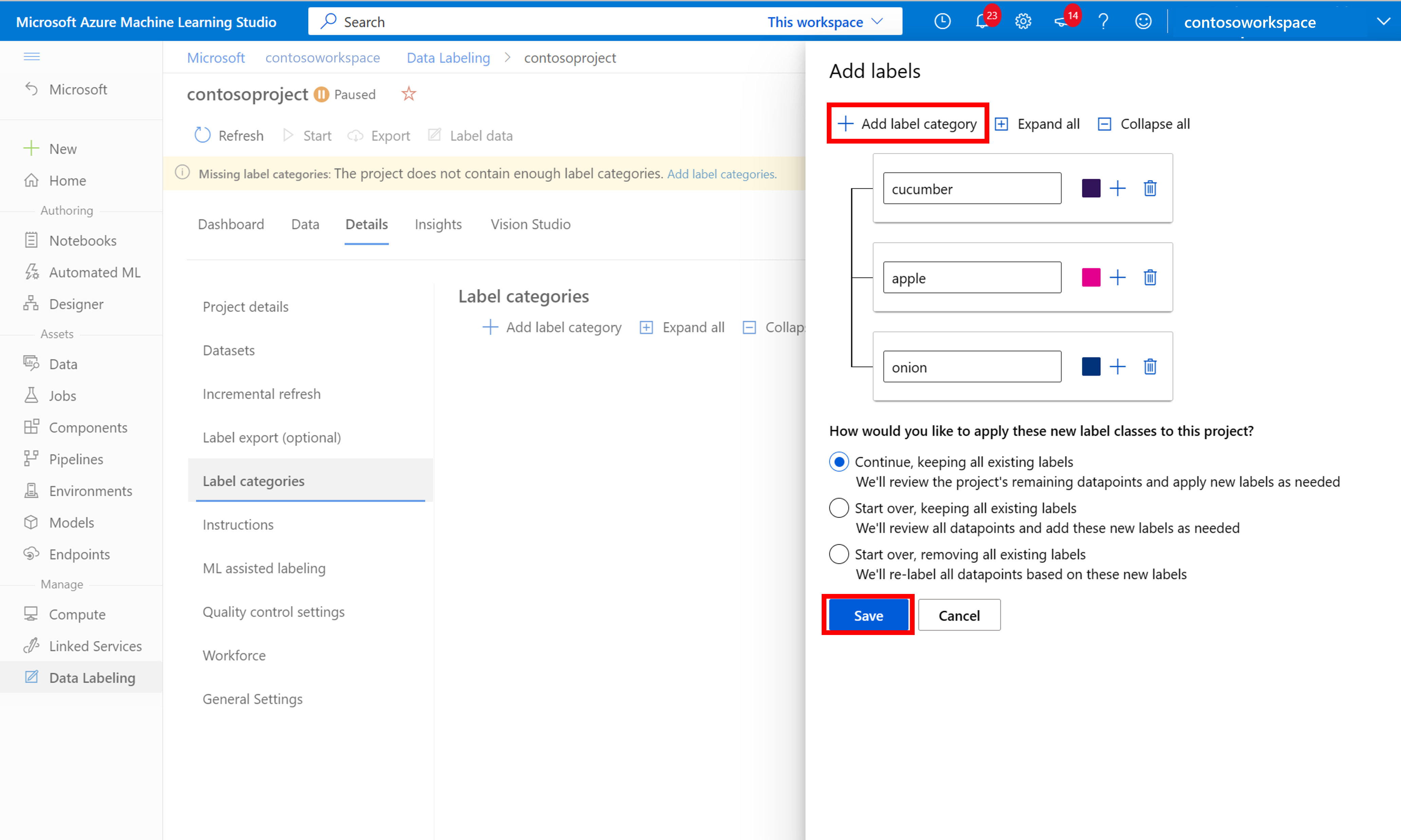
Nadat u alle klasselabels hebt toegevoegd, slaat u deze op, selecteert u beginnen in het project en selecteert u vervolgens Labelgegevens bovenaan.
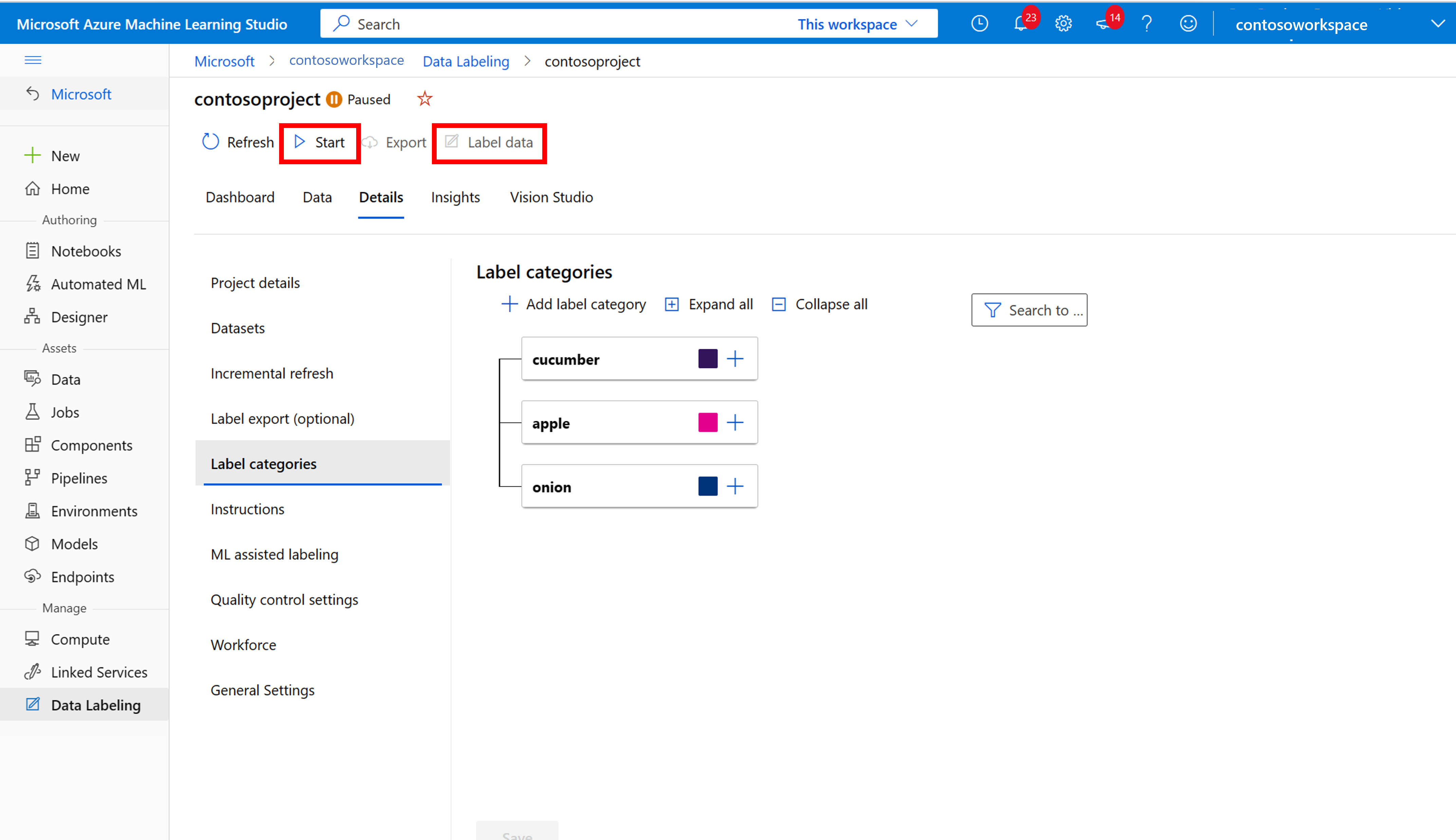
Azure Machine Learning: Trainingsgegevens handmatig labelen
Kies Labelen starten en volg de aanwijzingen om al uw afbeeldingen te labelen. Wanneer u klaar bent, gaat u terug naar het tabblad Vision Studio in uw browser.
Selecteer Nu COCO-bestand toevoegen en selecteer Vervolgens COCO-bestand importeren uit een Azure ML-gegevenslabelproject. Hiermee importeert u de gelabelde gegevens uit Azure Machine Learning.
Het COCO-bestand dat u zojuist hebt gemaakt, wordt nu opgeslagen in de Azure Storage-container die u aan dit project hebt gekoppeld. U kunt deze nu importeren in de werkstroom voor modelaanpassing. Selecteer deze in de vervolgkeuzelijst. Zodra het COCO-bestand in de gegevensset is geïmporteerd, kan de gegevensset worden gebruikt voor het trainen van een model.
Notitie
COCO-bestanden importeren van elders
Als u een kant-en-klaar COCO-bestand hebt dat u wilt importeren, gaat u naar het tabblad Gegevenssets en selecteert u Add COCO files to this dataset. U kunt ervoor kiezen om een specifiek COCO-bestand toe te voegen vanuit een Blob Storage-account of te importeren uit het Azure Machine Learning-labelproject.
Momenteel is Microsoft bezig met een probleem waardoor het importeren van COCO-bestanden mislukt met grote gegevenssets wanneer het in Vision Studio wordt gestart. Als u wilt trainen met behulp van een grote gegevensset, is het raadzaam om in plaats daarvan de REST API te gebruiken.

Over COCO-bestanden
COCO-bestanden zijn JSON-bestanden met specifieke vereiste velden: "images", "annotations"en "categories". Een voorbeeld van een COCO-bestand ziet er als volgt uit:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Naslaginformatie over COCO-bestandsvelden
Als u uw eigen COCO-bestand helemaal zelf genereert, moet u ervoor zorgen dat alle vereiste velden de juiste gegevens bevatten. In de volgende tabellen wordt elk veld in een COCO-bestand beschreven:
"afbeeldingen"
| Sleutel | Type | Description | Vereist? |
|---|---|---|---|
id |
geheel getal | Unieke afbeeldings-id, beginnend vanaf 1 | Ja |
width |
geheel getal | Breedte van de afbeelding in pixels | Ja |
height |
geheel getal | Hoogte van de afbeelding in pixels | Ja |
file_name |
tekenreeks | Een unieke naam voor de afbeelding | Ja |
absolute_url of coco_url |
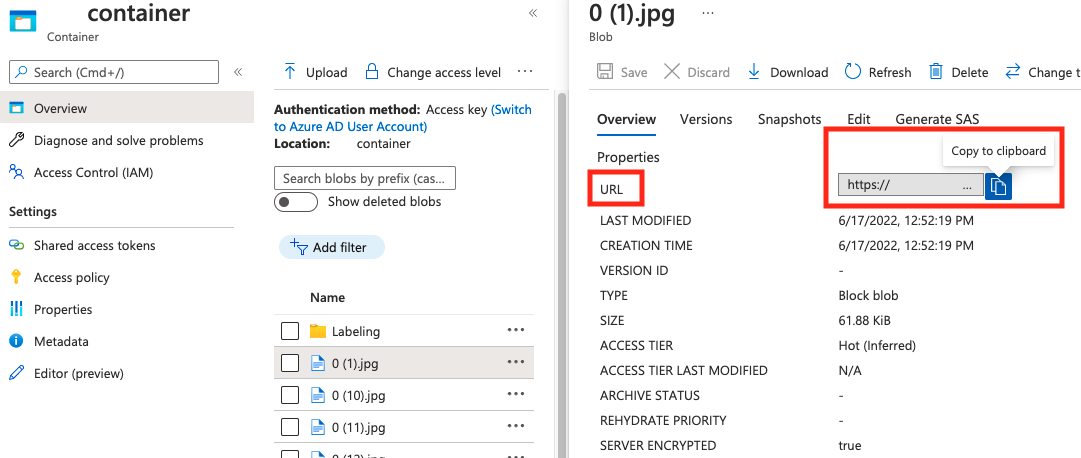
tekenreeks | Afbeeldingspad als een absolute URI naar een blob in een blobcontainer. De Vision-resource moet gemachtigd zijn om de annotatiebestanden en alle afbeeldingsbestanden waarnaar wordt verwezen te lezen. | Ja |
De waarde voor absolute_url vindt u in de eigenschappen van uw blobcontainer:
"aantekeningen"
| Sleutel | Type | Description | Vereist? |
|---|---|---|---|
id |
geheel getal | Id van de aantekening | Ja |
category_id |
geheel getal | Id van de categorie die is gedefinieerd in de categories sectie |
Ja |
image_id |
geheel getal | Id van de afbeelding | Ja |
area |
geheel getal | Waarde van 'Width' x 'Height' (derde en vierde waarde van bbox) |
Nee |
bbox |
list[float] | Relatieve coördinaten van het begrenzingsvak (0 tot 1), in de volgorde van 'Links', 'Boven', 'Breedte', 'Hoogte' | Ja |
"categorieën"
| Sleutel | Type | Description | Vereist? |
|---|---|---|---|
id |
geheel getal | Unieke id voor elke categorie (labelklasse). Deze moeten aanwezig zijn in de annotations sectie. |
Ja |
name |
tekenreeks | Naam van de categorie (labelklasse) | Ja |
COCO-bestandsverificatie
U kunt onze Python-voorbeeldcode gebruiken om de indeling van een COCO-bestand te controleren.
Het aangepaste model trainen
Als u een model wilt trainen met uw COCO-bestand, gaat u naar het tabblad Aangepaste modellen en selecteert u Een nieuw model toevoegen. Voer een naam in voor het model en selecteer Image classification of Object detection als het modeltype.
Selecteer uw gegevensset, die nu is gekoppeld aan het COCO-bestand met de labelinformatie.
Selecteer vervolgens een tijdbudget en train het model. Voor kleine voorbeelden kunt u een 1 hour budget gebruiken.
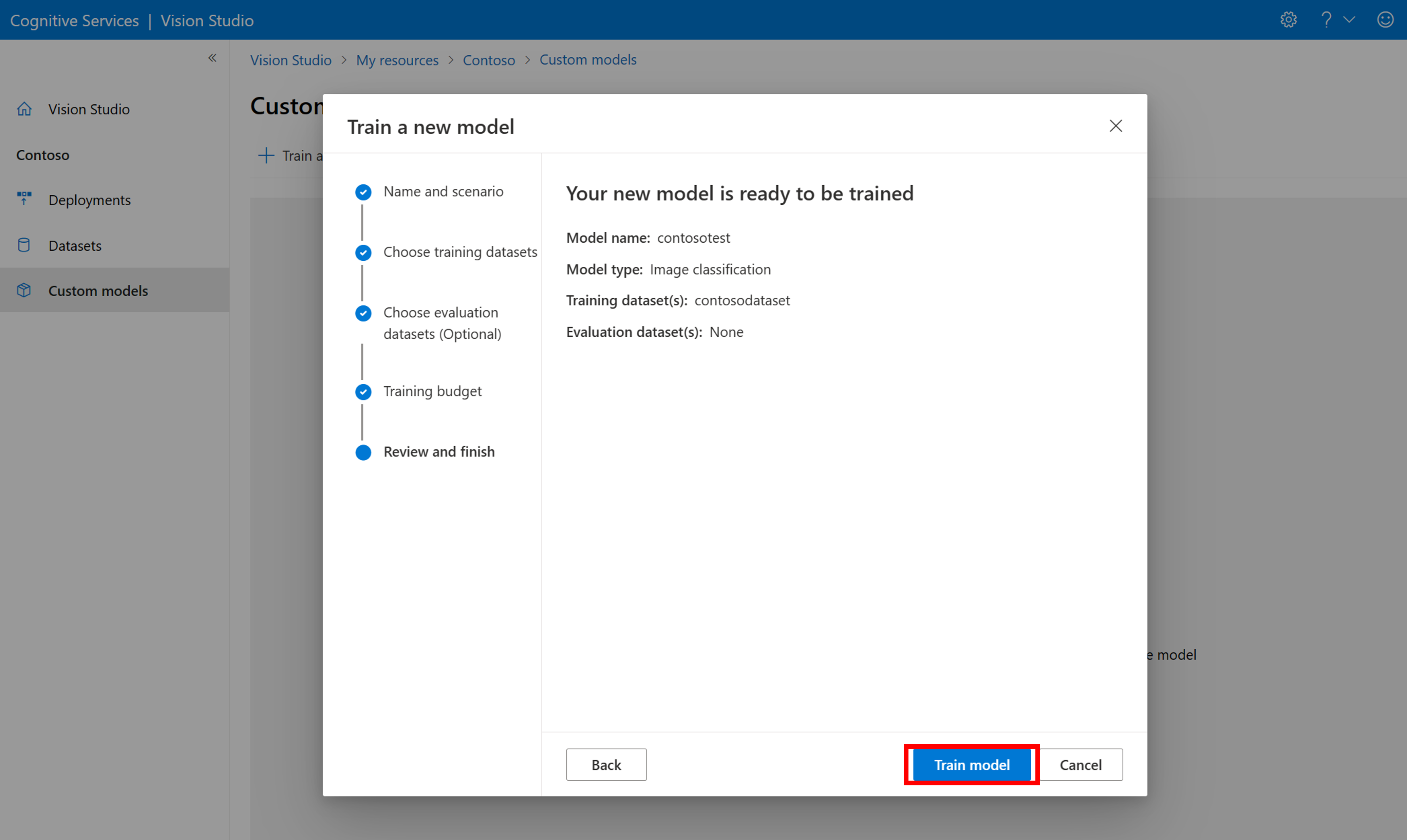
Het kan enige tijd duren voordat de training is voltooid. Afbeeldingsanalyse 4.0-modellen kunnen nauwkeurig zijn met slechts een kleine set trainingsgegevens, maar ze duren langer om te trainen dan eerdere modellen.
Het getrainde model evalueren
Nadat de training is voltooid, kunt u de prestatie-evaluatie van het model bekijken. De volgende metrische gegevens worden gebruikt:
- Afbeeldingsclassificatie: Gemiddelde precisie, nauwkeurigheid top 1, nauwkeurigheid top 5
- Objectdetectie: Gemiddelde precisie @ 30, gemiddelde gemiddelde precisie @ 50, gemiddelde precisie @ 75
Als er geen evaluatieset wordt opgegeven bij het trainen van het model, worden de gerapporteerde prestaties geschat op basis van een deel van de trainingsset. We raden u ten zeerste aan een evaluatiegegevensset te gebruiken (met hetzelfde proces als hierboven) om een betrouwbare schatting te maken van de prestaties van uw model.
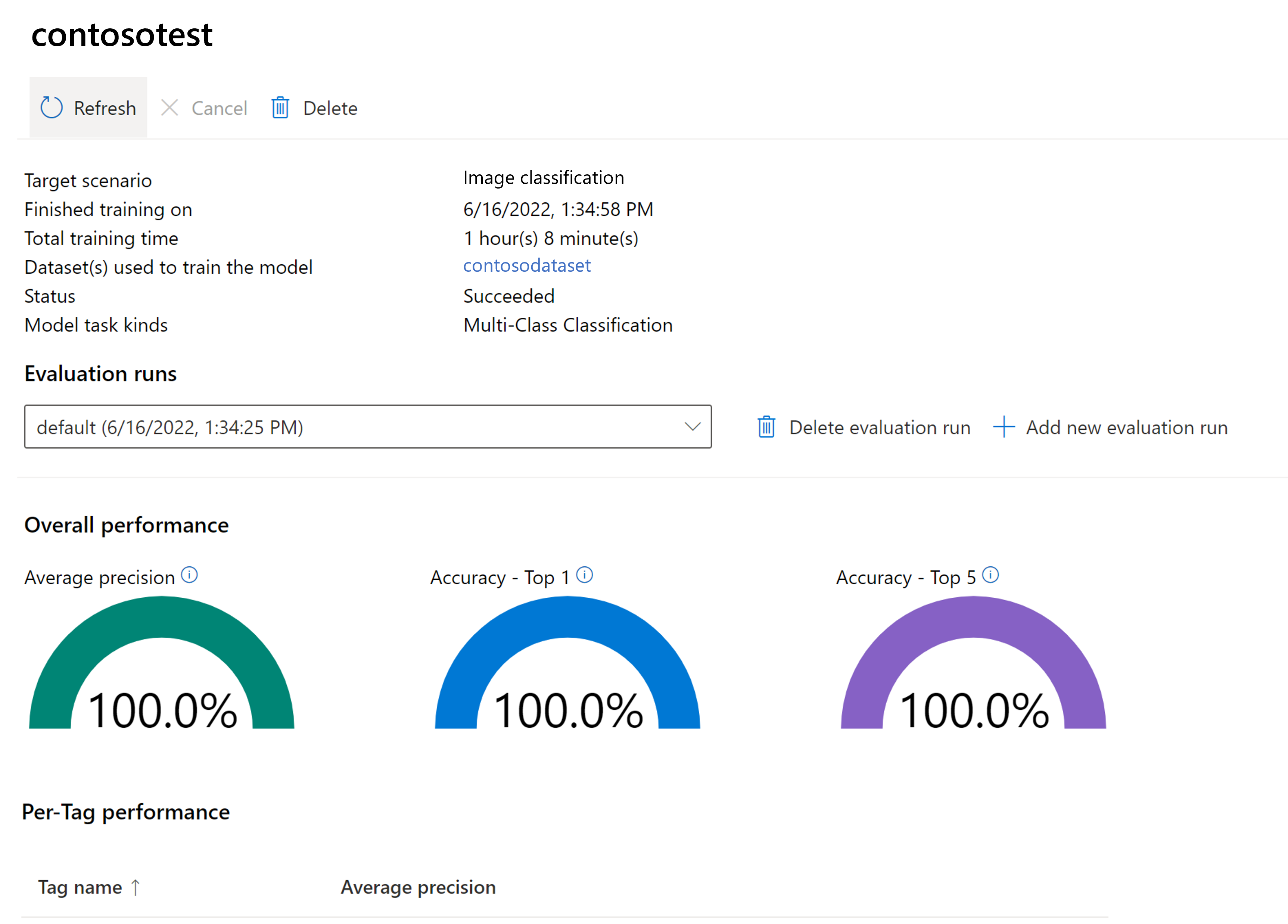
Aangepast model testen in Vision Studio
Zodra u een aangepast model hebt gemaakt, kunt u testen door de knop Uitproberen te selecteren op het modelevaluatiescherm.
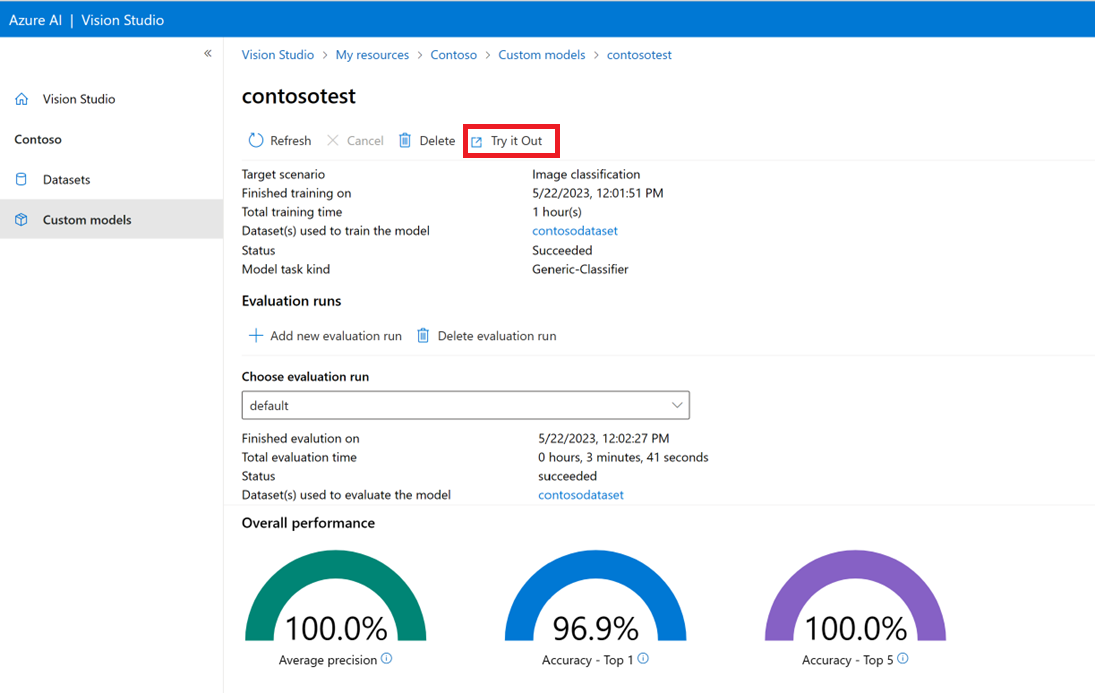
Hiermee gaat u naar de pagina Algemene tags extraheren van afbeeldingen . Kies uw aangepaste model in de vervolgkeuzelijst en upload een testafbeelding.
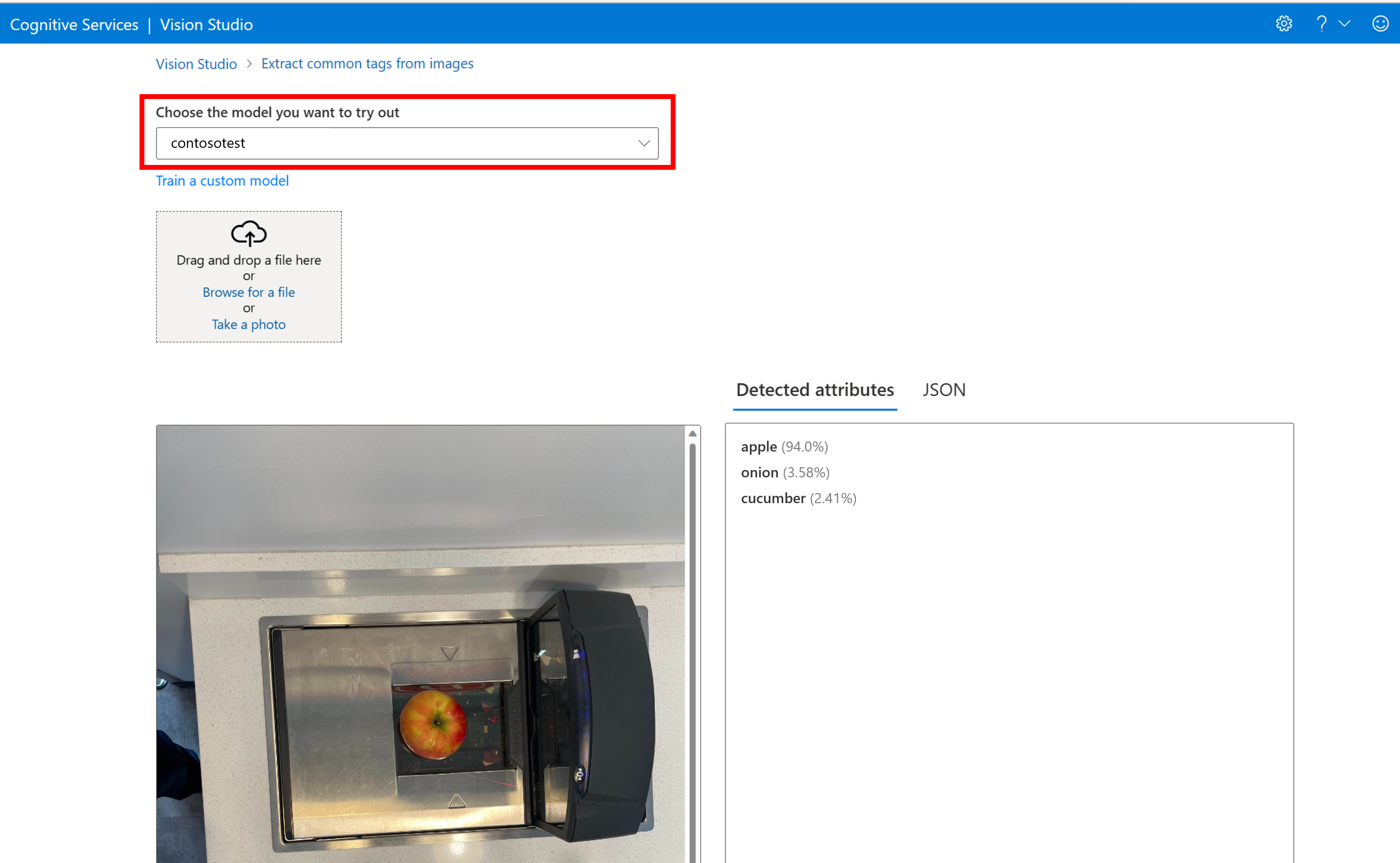
De voorspellingsresultaten worden weergegeven in de rechterkolom.
Volgende stappen
In deze handleiding hebt u een aangepast afbeeldingsclassificatiemodel gemaakt en getraind met behulp van afbeeldingsanalyse. Lees vervolgens meer over de Analyze Image 4.0 API, zodat u uw aangepaste model kunt aanroepen vanuit een toepassing met behulp van REST- of bibliotheek-SDK's.
- Zie de handleiding voor modelaanpassingsconcepten voor een breed overzicht van deze functie en een lijst met veelgestelde vragen.
- Roep de Afbeeldings-API analyseren aan.