Quickstart: Intenties herkennen met conversationele Language Understanding
Referentiedocumentatie | Pakket (NuGet) | Aanvullende voorbeelden op GitHub
In deze quickstart gebruikt u spraak- en taalservices om intenties te herkennen van audiogegevens die zijn vastgelegd met een microfoon. U gebruikt met name de Speech-service om spraak te herkennen en een CLU-model (Conversational Language Understanding) om intenties te identificeren.
Belangrijk
Conversational Language Understanding (CLU) is beschikbaar voor C# en C++ met de Speech SDK versie 1.25 of hoger.
Vereisten
- Azure-abonnement: Krijg een gratis abonnement
- Maak een taalresource in de Azure Portal.
- Haal de taalresourcesleutel en het eindpunt op. Nadat uw taalresource is geïmplementeerd, selecteert u Ga naar resource om sleutels weer te geven en te beheren. Zie De sleutels voor uw resource ophalen voor meer informatie over azure AI-servicesresources.
- Maak een Spraak-resource in de Azure Portal.
- Haal de spraakresourcesleutel en -regio op. Nadat uw Spraak-resource is geïmplementeerd, selecteert u Ga naar resource om sleutels weer te geven en te beheren. Zie De sleutels voor uw resource ophalen voor meer informatie over azure AI-servicesresources.
De omgeving instellen
De Speech SDK is beschikbaar als een NuGet-pakket en implementeert .NET Standard 2.0. U installeert de Speech SDK verderop in deze handleiding, maar controleer eerst de SDK-installatiehandleiding voor meer vereisten.
Omgevingsvariabelen instellen
In dit voorbeeld zijn omgevingsvariabelen met de naam LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYen SPEECH_REGIONvereist.
Uw toepassing moet worden geverifieerd om toegang te krijgen tot azure AI-servicesresources. Gebruik voor productie een veilige manier om uw referenties op te slaan en te openen. Nadat u bijvoorbeeld een sleutel voor de hebt opgegeven, schrijft u deze naar een nieuwe omgevingsvariabele op de lokale computer waarop de toepassing wordt uitgevoerd.
Tip
Neem de sleutel niet rechtstreeks op in uw code en publiceer deze nooit openbaar. Zie het artikel Beveiliging van Azure AI-services voor meer verificatieopties, zoals Azure Key Vault.
Als u de omgevingsvariabelen wilt instellen, opent u een consolevenster en volgt u de instructies voor uw besturingssysteem en ontwikkelomgeving.
- Als u de
LANGUAGE_KEYomgevingsvariabele wilt instellen, vervangt u dooryour-language-keyeen van de sleutels voor uw resource. - Als u de
LANGUAGE_ENDPOINTomgevingsvariabele wilt instellen, vervangt u dooryour-language-endpointeen van de regio's voor uw resource. - Als u de
SPEECH_KEYomgevingsvariabele wilt instellen, vervangt u dooryour-speech-keyeen van de sleutels voor uw resource. - Als u de
SPEECH_REGIONomgevingsvariabele wilt instellen, vervangt u dooryour-speech-regioneen van de regio's voor uw resource.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Notitie
Als u alleen toegang nodig hebt tot de omgevingsvariabele in de huidige console die wordt uitgevoerd, kunt u de omgevingsvariabele instellen met set in plaats van setx.
Nadat u de omgevingsvariabelen hebt toegevoegd, moet u mogelijk alle actieve programma's opnieuw starten die de omgevingsvariabele moeten lezen, inclusief het consolevenster. Als u bijvoorbeeld Visual Studio als editor gebruikt, start u Visual Studio opnieuw voordat u het voorbeeld uitvoert.
Een conversational Language Understanding-project maken
Zodra u een taalresource hebt gemaakt, maakt u een gespreksproject voor taalkennis in Language Studio. Een project is een werkgebied voor het bouwen van uw aangepaste ML-modellen op basis van uw gegevens. Uw project kan alleen worden geopend door u en anderen die toegang hebben tot de taalresource die wordt gebruikt.
Ga naar Language Studio en meld u aan met uw Azure-account.
Een project voor het begrijpen van gesprekstalen maken
Voor deze quickstart kunt u dit voorbeeldproject voor domotica downloaden en importeren. Dit project kan de beoogde opdrachten voorspellen op basis van gebruikersinvoer, zoals het in- en uitschakelen van lichten.
Selecteer in de sectie Vragen en gesprekstaal begrijpen van Language Studio de optie Conversatietaal begrijpen.

Hiermee gaat u naar de pagina Conversational Language Understanding-projecten . Selecteer importeren naast de knop Nieuw project maken.

Upload in het venster dat wordt weergegeven het JSON-bestand dat u wilt importeren. Zorg ervoor dat uw bestand de ondersteunde JSON-indeling volgt.


Zodra het uploaden is voltooid, komt u terecht op de pagina Schemadefinitie . Voor deze quickstart is het schema al gemaakt en zijn uitingen al gelabeld met intenties en entiteiten.
Uw model trainen
Nadat u een project hebt gemaakt, moet u doorgaans een schema en label-utterances maken. Voor deze quickstart hebben we al een kant-en-klaar project geïmporteerd met een ingebouwd schema en gelabelde utterances.
Als u een model wilt trainen, moet u een trainingstaak starten. De uitvoer van een geslaagde trainingstaak is uw getrainde model.
Ga als volgende te werk om uw model te trainen vanuit Language Studio:
Selecteer Model trainen in het menu aan de linkerkant.
Selecteer Een trainingstaak starten in het bovenste menu.
Selecteer Een nieuw model trainen en voer een nieuwe modelnaam in het tekstvak in. Als u een bestaand model wilt vervangen door een model dat is getraind op de nieuwe gegevens, selecteert u Een bestaand model overschrijven en selecteert u vervolgens een bestaand model. Het overschrijven van een getraind model kan niet ongedaan worden gemaakt, maar dit heeft geen invloed op uw geïmplementeerde modellen totdat u het nieuwe model implementeert.
Selecteer de trainingsmodus. U kunt Standaardtraining kiezen voor een snellere training, maar deze is alleen beschikbaar voor Engels. Of u kunt kiezen voor Geavanceerde training die wordt ondersteund voor andere talen en meertalige projecten, maar het gaat om langere trainingstijden. Meer informatie over trainingsmodi.
Selecteer een methode voor het splitsen van gegevens . U kunt de testset automatisch splitsen uit trainingsgegevens kiezen, waarbij het systeem uw uitingen splitst tussen de trainings- en testsets, op basis van de opgegeven percentages. Of u kunt Een handmatige splitsing van training- en testgegevens gebruiken. Deze optie is alleen ingeschakeld als u utterances hebt toegevoegd aan uw testset toen u uw utterances hebt gelabeld.
Selecteer de knop Trainen .

Selecteer de id van de trainingstaak in de lijst. Er wordt een deelvenster weergegeven waarin u de voortgang van de training, de taakstatus en andere details voor deze taak kunt controleren.
Notitie
- Alleen voltooide trainingstaken genereren modellen.
- Training kan enkele minuten tot enkele uren duren op basis van het aantal utterances.
- U kunt slechts één trainingstaak tegelijk uitvoeren. U kunt geen andere trainingstaken binnen hetzelfde project starten totdat de actieve taak is voltooid.
- De machine learning die wordt gebruikt om modellen te trainen, wordt regelmatig bijgewerkt. Als u wilt trainen op een eerdere configuratieversie, selecteert u Hier selecteren om te wijzigen op de pagina Een trainingstaak starten en kiest u een eerdere versie.

Uw model implementeren
Over het algemeen controleert u na het trainen van een model de evaluatiedetails. In deze quickstart implementeert u gewoon uw model en maakt u het beschikbaar voor u om het uit te proberen in Language Studio, of u kunt de voorspellings-API aanroepen.
Uw model implementeren vanuit Language Studio:
Selecteer Een model implementeren in het menu aan de linkerkant.
Selecteer Implementatie toevoegen om de wizard Implementatie toevoegen te starten.

Selecteer Een nieuwe implementatienaam maken om een nieuwe implementatie te maken en een getraind model toe te wijzen in de vervolgkeuzelijst hieronder. U kunt anders een bestaande implementatienaam overschrijven selecteren om het model dat door een bestaande implementatie wordt gebruikt effectief te vervangen.
Notitie
Voor het overschrijven van een bestaande implementatie zijn geen wijzigingen in uw voorspellings-API-aanroep vereist, maar de resultaten die u krijgt, zijn gebaseerd op het zojuist toegewezen model.
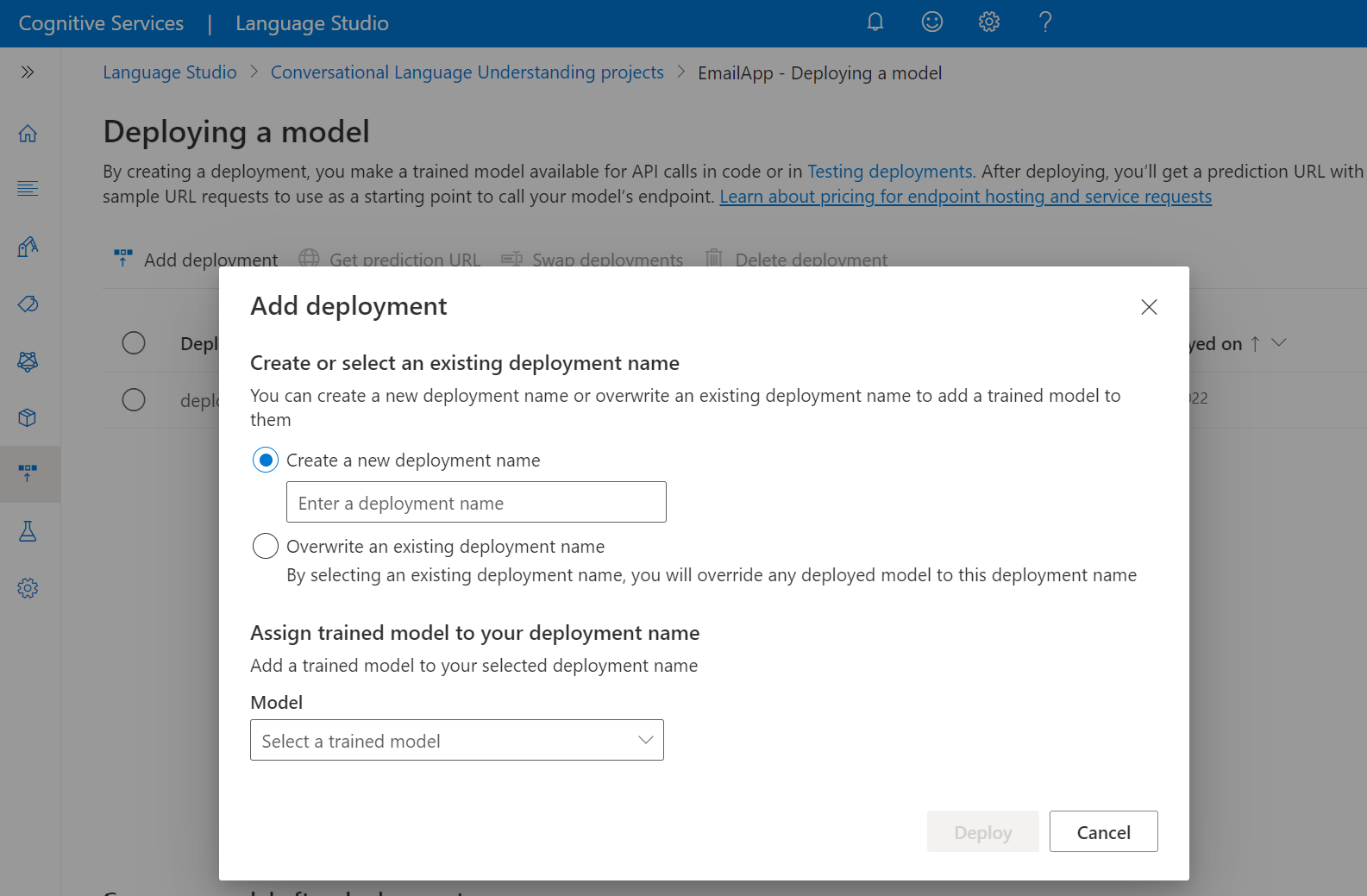
Selecteer een getraind model in de vervolgkeuzelijst Model .
Selecteer Implementeren om de implementatietaak te starten.
Nadat de implementatie is geslaagd, wordt ernaast een vervaldatum weergegeven. Het verlopen van de implementatie is wanneer uw geïmplementeerde model niet beschikbaar is om te worden gebruikt voor voorspellingen. Dit gebeurt meestal twaalf maanden nadat een trainingsconfiguratie verloopt.


In de volgende sectie gebruikt u de projectnaam en implementatienaam.
Intenties herkennen vanaf een microfoon
Volg deze stappen om een nieuwe consoletoepassing te maken en de Speech SDK te installeren.
Open een opdrachtprompt waar u het nieuwe project wilt en maak een consoletoepassing met de .NET CLI. Het
Program.csbestand moet worden gemaakt in de projectmap.dotnet new consoleInstalleer de Speech SDK in uw nieuwe project met de .NET CLI.
dotnet add package Microsoft.CognitiveServices.SpeechVervang de inhoud van
Program.csdoor de volgende code.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Stel
Program.csdecluProjectNamevariabelen encluDeploymentNamein op de namen van uw project en implementatie. Zie Een gespreks-Language Understanding-project maken voor meer informatie over het maken van een CLU-project en implementatie.Als u de taal voor spraakherkenning wilt wijzigen, vervangt u door
en-USeen andere ondersteunde taal. Bijvoorbeeldes-ESvoor Spaans (Spanje). De standaardtaal isen-USals u geen taal opgeeft. Zie Taalidentificatie voor meer informatie over het identificeren van een van meerdere talen die mogelijk worden gesproken.
Voer de nieuwe consoletoepassing uit om spraakherkenning te starten vanaf een microfoon:
dotnet run
Belangrijk
Zorg ervoor dat u de LANGUAGE_KEYomgevingsvariabelen , LANGUAGE_ENDPOINT, SPEECH_KEYen SPEECH_REGION instelt zoals hierboven wordt beschreven. Als u deze variabelen niet instelt, mislukt het voorbeeld met een foutbericht.
Spreek in uw microfoon wanneer u hierom wordt gevraagd. Wat u spreekt, moet worden uitgevoerd als tekst:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Notitie
Ondersteuning voor het JSON-antwoord voor CLU via de eigenschap LanguageUnderstandingServiceResponse_JsonResult is toegevoegd in speech-SDK versie 1.26.
De intenties worden geretourneerd in de waarschijnlijkheidsvolgorde van hoogstwaarschijnlijk tot minst waarschijnlijk. Hier volgt een opgemaakte versie van de JSON-uitvoer waarbij de topIntent is HomeAutomation.TurnOn met een betrouwbaarheidsscore van 0,97712576 (97,71%). De tweede meest waarschijnlijke intentie kan HomeAutomation.TurnOff zijn met een betrouwbaarheidsscore van 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Opmerkingen
Nu u de quickstart hebt voltooid, volgen hier enkele aanvullende overwegingen:
- In dit voorbeeld wordt de
RecognizeOnceAsyncbewerking gebruikt om uitingen van maximaal 30 seconden te transcriberen, of totdat stilte wordt gedetecteerd. Zie Spraak herkennen voor informatie over continue herkenning voor langere audio, inclusief meertalige gesprekken. - Als u spraak uit een audiobestand wilt herkennen, gebruikt
FromWavFileInputu in plaats vanFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Voor gecomprimeerde audiobestanden zoals MP4 installeert u GStreamer en gebruikt u
PullAudioInputStreamofPushAudioInputStream. Zie Gecomprimeerde invoeraudio gebruiken voor meer informatie.
Resources opschonen
U kunt de Azure Portal of Azure Cli (Opdrachtregelinterface) gebruiken om de taal- en spraakresources die u hebt gemaakt, te verwijderen.
Referentiedocumentatie | Pakket (NuGet) | Aanvullende voorbeelden op GitHub
In deze quickstart gebruikt u spraak- en taalservices om intenties te herkennen van audiogegevens die zijn vastgelegd met een microfoon. U gebruikt met name de Speech-service om spraak te herkennen en een CLU-model (Conversational Language Understanding) om intenties te identificeren.
Belangrijk
Conversational Language Understanding (CLU) is beschikbaar voor C# en C++ met de Speech SDK versie 1.25 of hoger.
Vereisten
- Azure-abonnement: Krijg een gratis abonnement
- Maak een taalresource in de Azure Portal.
- Haal de taalresourcesleutel en het eindpunt op. Nadat uw taalresource is geïmplementeerd, selecteert u Ga naar resource om sleutels weer te geven en te beheren. Zie De sleutels voor uw resource ophalen voor meer informatie over azure AI-servicesresources.
- Maak een Spraak-resource in de Azure Portal.
- Haal de spraakresourcesleutel en -regio op. Nadat uw Spraak-resource is geïmplementeerd, selecteert u Ga naar resource om sleutels weer te geven en te beheren. Zie De sleutels voor uw resource ophalen voor meer informatie over azure AI-servicesresources.
De omgeving instellen
De Speech SDK is beschikbaar als een NuGet-pakket en implementeert .NET Standard 2.0. U installeert de Speech SDK verderop in deze handleiding, maar controleer eerst de SDK-installatiehandleiding voor meer vereisten.
Omgevingsvariabelen instellen
In dit voorbeeld zijn omgevingsvariabelen met de naam LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYen SPEECH_REGIONvereist.
Uw toepassing moet worden geverifieerd om toegang te krijgen tot azure AI-servicesresources. Gebruik voor productie een veilige manier om uw referenties op te slaan en te openen. Nadat u bijvoorbeeld een sleutel voor de hebt opgegeven, schrijft u deze naar een nieuwe omgevingsvariabele op de lokale computer waarop de toepassing wordt uitgevoerd.
Tip
Neem de sleutel niet rechtstreeks op in uw code en publiceer deze nooit openbaar. Zie het artikel Beveiliging van Azure AI-services voor meer verificatieopties, zoals Azure Key Vault.
Als u de omgevingsvariabelen wilt instellen, opent u een consolevenster en volgt u de instructies voor uw besturingssysteem en ontwikkelomgeving.
- Als u de
LANGUAGE_KEYomgevingsvariabele wilt instellen, vervangt u dooryour-language-keyeen van de sleutels voor uw resource. - Als u de
LANGUAGE_ENDPOINTomgevingsvariabele wilt instellen, vervangt u dooryour-language-endpointeen van de regio's voor uw resource. - Als u de
SPEECH_KEYomgevingsvariabele wilt instellen, vervangt u dooryour-speech-keyeen van de sleutels voor uw resource. - Als u de
SPEECH_REGIONomgevingsvariabele wilt instellen, vervangt u dooryour-speech-regioneen van de regio's voor uw resource.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Notitie
Als u alleen toegang nodig hebt tot de omgevingsvariabele in de huidige console die wordt uitgevoerd, kunt u de omgevingsvariabele instellen met set in plaats van setx.
Nadat u de omgevingsvariabelen hebt toegevoegd, moet u mogelijk alle actieve programma's opnieuw starten die de omgevingsvariabele moeten lezen, inclusief het consolevenster. Als u bijvoorbeeld Visual Studio als editor gebruikt, start u Visual Studio opnieuw voordat u het voorbeeld uitvoert.
Een conversational Language Understanding-project maken
Zodra u een taalresource hebt gemaakt, maakt u een gespreksproject voor taalkennis in Language Studio. Een project is een werkgebied voor het bouwen van uw aangepaste ML-modellen op basis van uw gegevens. Uw project kan alleen worden geopend door u en anderen die toegang hebben tot de taalresource die wordt gebruikt.
Ga naar Language Studio en meld u aan met uw Azure-account.
Een project voor het begrijpen van gesprekstalen maken
Voor deze quickstart kunt u dit voorbeeldproject voor domotica downloaden en importeren. Dit project kan de beoogde opdrachten voorspellen op basis van gebruikersinvoer, zoals het in- en uitschakelen van lichten.
Selecteer in de sectie Vragen en gesprekstaal begrijpen van Language Studio de optie Conversatietaal begrijpen.
Hiermee gaat u naar de pagina Conversational Language Understanding-projecten . Selecteer importeren naast de knop Nieuw project maken.
Upload in het venster dat wordt weergegeven het JSON-bestand dat u wilt importeren. Zorg ervoor dat uw bestand de ondersteunde JSON-indeling volgt.
Zodra het uploaden is voltooid, komt u terecht op de pagina Schemadefinitie . Voor deze quickstart is het schema al gemaakt en zijn uitingen al gelabeld met intenties en entiteiten.
Uw model trainen
Nadat u een project hebt gemaakt, moet u doorgaans een schema en label-utterances maken. Voor deze quickstart hebben we al een kant-en-klaar project geïmporteerd met een ingebouwd schema en gelabelde utterances.
Als u een model wilt trainen, moet u een trainingstaak starten. De uitvoer van een geslaagde trainingstaak is uw getrainde model.
Ga als volgende te werk om uw model te trainen vanuit Language Studio:
Selecteer Model trainen in het menu aan de linkerkant.
Selecteer Een trainingstaak starten in het bovenste menu.
Selecteer Een nieuw model trainen en voer een nieuwe modelnaam in het tekstvak in. Als u een bestaand model wilt vervangen door een model dat is getraind op de nieuwe gegevens, selecteert u Een bestaand model overschrijven en selecteert u vervolgens een bestaand model. Het overschrijven van een getraind model kan niet ongedaan worden gemaakt, maar dit heeft geen invloed op uw geïmplementeerde modellen totdat u het nieuwe model implementeert.
Selecteer de trainingsmodus. U kunt Standaardtraining kiezen voor een snellere training, maar deze is alleen beschikbaar voor Engels. Of u kunt kiezen voor Geavanceerde training die wordt ondersteund voor andere talen en meertalige projecten, maar het gaat om langere trainingstijden. Meer informatie over trainingsmodi.
Selecteer een methode voor het splitsen van gegevens . U kunt de testset automatisch splitsen uit trainingsgegevens kiezen, waarbij het systeem uw uitingen splitst tussen de trainings- en testsets, op basis van de opgegeven percentages. Of u kunt Een handmatige splitsing van training- en testgegevens gebruiken. Deze optie is alleen ingeschakeld als u utterances hebt toegevoegd aan uw testset toen u uw utterances hebt gelabeld.
Selecteer de knop Trainen .
Selecteer de id van de trainingstaak in de lijst. Er wordt een deelvenster weergegeven waarin u de voortgang van de training, de taakstatus en andere details voor deze taak kunt controleren.
Notitie
- Alleen voltooide trainingstaken genereren modellen.
- Training kan enkele minuten tot enkele uren duren op basis van het aantal utterances.
- U kunt slechts één trainingstaak tegelijk uitvoeren. U kunt geen andere trainingstaken binnen hetzelfde project starten totdat de actieve taak is voltooid.
- De machine learning die wordt gebruikt om modellen te trainen, wordt regelmatig bijgewerkt. Als u wilt trainen op een eerdere configuratieversie, selecteert u Hier selecteren om te wijzigen op de pagina Een trainingstaak starten en kiest u een eerdere versie.
Uw model implementeren
Over het algemeen controleert u na het trainen van een model de evaluatiedetails. In deze quickstart implementeert u gewoon uw model en maakt u het beschikbaar voor u om het uit te proberen in Language Studio, of u kunt de voorspellings-API aanroepen.
Uw model implementeren vanuit Language Studio:
Selecteer Een model implementeren in het menu aan de linkerkant.
Selecteer Implementatie toevoegen om de wizard Implementatie toevoegen te starten.
Selecteer Een nieuwe implementatienaam maken om een nieuwe implementatie te maken en een getraind model toe te wijzen in de vervolgkeuzelijst hieronder. U kunt anders een bestaande implementatienaam overschrijven selecteren om het model dat door een bestaande implementatie wordt gebruikt effectief te vervangen.
Notitie
Voor het overschrijven van een bestaande implementatie zijn geen wijzigingen in uw voorspellings-API-aanroep vereist, maar de resultaten die u krijgt, zijn gebaseerd op het zojuist toegewezen model.
Selecteer een getraind model in de vervolgkeuzelijst Model .
Selecteer Implementeren om de implementatietaak te starten.
Nadat de implementatie is geslaagd, wordt ernaast een vervaldatum weergegeven. Het verlopen van de implementatie is wanneer uw geïmplementeerde model niet beschikbaar is om te worden gebruikt voor voorspellingen. Dit gebeurt meestal twaalf maanden nadat een trainingsconfiguratie verloopt.
In de volgende sectie gebruikt u de projectnaam en implementatienaam.
Intenties herkennen vanaf een microfoon
Volg deze stappen om een nieuwe consoletoepassing te maken en de Speech SDK te installeren.
Maak een nieuw C++-consoleproject in Visual Studio Community 2022 met de naam
SpeechRecognition.Installeer de Speech SDK in uw nieuwe project met NuGet-pakketbeheer.
Install-Package Microsoft.CognitiveServices.SpeechVervang de inhoud van
SpeechRecognition.cppdoor de volgende code:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Stel
SpeechRecognition.cppdecluProjectNamevariabelen encluDeploymentNamein op de namen van uw project en implementatie. Zie Een gespreks-Language Understanding-project maken voor meer informatie over het maken van een CLU-project en implementatie.Als u de taal voor spraakherkenning wilt wijzigen, vervangt u door
en-USeen andere ondersteunde taal. Bijvoorbeeldes-ESvoor Spaans (Spanje). De standaardtaal isen-USals u geen taal opgeeft. Zie Taalidentificatie voor meer informatie over het identificeren van een van meerdere talen die mogelijk worden gesproken.
Bouw uw nieuwe consoletoepassing en voer deze uit om spraakherkenning vanaf een microfoon te starten.
Belangrijk
Zorg ervoor dat u de LANGUAGE_KEYomgevingsvariabelen , LANGUAGE_ENDPOINT, SPEECH_KEYen SPEECH_REGION instelt zoals hierboven wordt beschreven. Als u deze variabelen niet instelt, mislukt het voorbeeld met een foutbericht.
Spreek in uw microfoon wanneer u hierom wordt gevraagd. Wat u spreekt, moet worden uitgevoerd als tekst:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Notitie
Ondersteuning voor het JSON-antwoord voor CLU via de eigenschap LanguageUnderstandingServiceResponse_JsonResult is toegevoegd in speech-SDK versie 1.26.
De intenties worden geretourneerd in de waarschijnlijkheidsvolgorde van hoogstwaarschijnlijk tot minst waarschijnlijk. Hier volgt een opgemaakte versie van de JSON-uitvoer waarbij de topIntent is HomeAutomation.TurnOn met een betrouwbaarheidsscore van 0,97712576 (97,71%). De tweede meest waarschijnlijke intentie kan HomeAutomation.TurnOff zijn met een betrouwbaarheidsscore van 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Opmerkingen
Nu u de quickstart hebt voltooid, volgen hier enkele aanvullende overwegingen:
- In dit voorbeeld wordt de
RecognizeOnceAsyncbewerking gebruikt om uitingen van maximaal 30 seconden te transcriberen, of totdat stilte wordt gedetecteerd. Zie Spraak herkennen voor informatie over continue herkenning voor langere audio, inclusief meertalige gesprekken. - Als u spraak uit een audiobestand wilt herkennen, gebruikt
FromWavFileInputu in plaats vanFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Voor gecomprimeerde audiobestanden zoals MP4 installeert u GStreamer en gebruikt u
PullAudioInputStreamofPushAudioInputStream. Zie Gecomprimeerde invoeraudio gebruiken voor meer informatie.
Resources opschonen
U kunt de Azure Portal of Azure Cli (Opdrachtregelinterface) gebruiken om de taal- en spraakresources die u hebt gemaakt, te verwijderen.
Referentiedocumentatie | Aanvullende voorbeelden op GitHub
De Speech SDK voor Java biedt geen ondersteuning voor intentieherkenning met CLU (Conversational Language Understanding). Selecteer een andere programmeertaal of de Java-verwijzing en voorbeelden die zijn gekoppeld aan het begin van dit artikel.